Cluster storage for small web-clusters based on drbd + ocfs2
- Tutorial
What we will talk about:
How to quickly deploy shared storage for two servers based on drbd + ocfs2 solutions.
For whom it will be useful: The
tutorial will be useful to system administrators and anyone who chooses a method of implementing a repository or wants to try a solution.
Often we are faced with a situation where we need to implement a common storage on a small web-cluster with good read-write performance. We tried various options for implementing a common repository for our projects, but little was able to satisfy us immediately for several indicators. Now let's explain why.
One of the most convenient solutions for us was a bunch of ocfs2 + drbd . Now we’ll show you how to quickly deploy shared storage for two servers based on a database of solutions. But first, a little about the components:
DRBD is the storage system from the standard Linux distribution, which allows you to replicate data between server blocks. The main application is building fault tolerant storage.
OCFS2 is a file system that provides shared use of the same storage by multiple systems. Included in the distribution of Linux and is a kernel module and userspace tools for working with FS. OCFS2 can be used not only on top of DRBD, but also on top of iSCSI with multiple connections. In our example, we use DRBD.
All actions are performed on ubuntu server 18.04 in a minimal configuration.
Step 1. Configure DRBD:
In the file /etc/drbd.d/drbd0.res we describe our virtual block device / dev / drbd0:
meta-disk internal - use the same block devices for storing metadata
device / dev / drbd0 - use / dev / drbd0 as the path to drbd volume.
disk / dev / vdb1 - use / dev / vdb1
syncer {rate 1000M; } - use gigabit of bandwidth
allow-two-primaries - an important option that allows the adoption of changes on two primary servers
after-sb-0pri, after-sb-1pri, after-sb-2pri - options that are responsible for the actions of the node when splitbrain is detected . See the documentation for more details.
become-primary-on both - sets both nodes to primary.
In our case, we have two absolutely identical VMs, with a dedicated virtual network bandwidth of 10 gigabits.
In our example, the network names of two cluster nodes are drbd1 and drbd2. For proper operation, you must map the names and ip addresses of the nodes in / etc / hosts.
Step 2. Configure the nodes:
On both servers, execute:
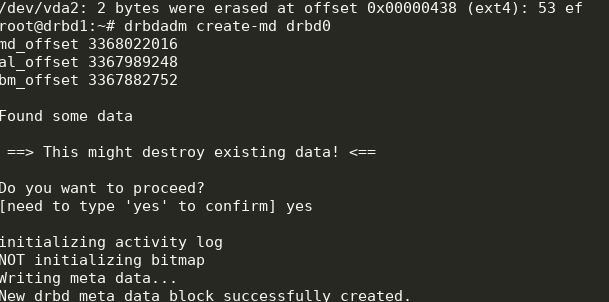
We get the following:

You can start synchronization. On the first node you need to do:
We look at the status:

Great, the synchronization has begun. We wait for the end and see the picture:

Step 3. We start synchronization on the second node:
We

get the following: Now we can write to drbd from two servers.
Step 4. Install and configure ocfs2.
We will use a fairly trivial configuration:
It needs to be written in /etc/ocfs2/cluster.conf on both nodes.
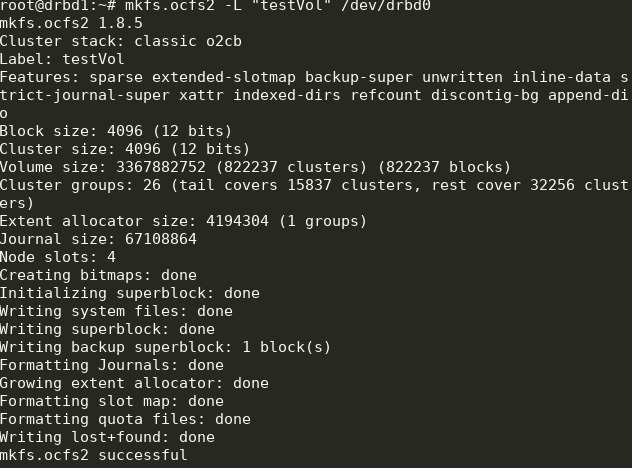
Create FS on drbd0 on any node:
Here we created a file system labeled testVol on drbd0 using the default settings.
In / etc / default / o2cb must be set (as in our configuration file)
and execute on each node:
After that, turn on and add to the startup all the units we need:
Part of this will already be running during the setup process.
Step 5. Add mount points to fstab on both nodes:
The / media / shared directory must be created in advance.
Here we use the noauto options, which means that the FS will not be mounted at startup (I prefer to mount network FS via systemd) and heartbeat = local, which means using the heartbeat service on each node. There is also a global heartbeat, which is more suitable for large clusters.
Next, you can mount / media / shared and check the synchronization of the content.
Done! As a result, we get a more or less fault-tolerant storage with scalability and decent performance.
How to quickly deploy shared storage for two servers based on drbd + ocfs2 solutions.
For whom it will be useful: The
tutorial will be useful to system administrators and anyone who chooses a method of implementing a repository or wants to try a solution.
What decisions have we refused and why
Often we are faced with a situation where we need to implement a common storage on a small web-cluster with good read-write performance. We tried various options for implementing a common repository for our projects, but little was able to satisfy us immediately for several indicators. Now let's explain why.
- Glusterfs did not suit us with read and write performance, there were problems with the simultaneous reading of a large number of files, there was a high CPU load. The problem with reading files could be solved by applying for them directly in the brick, but this is not always applicable and generally incorrect.
- Ceph did not like the excessive complexity, which can be harmful on projects with 2-4 servers, especially if the project is subsequently serviced. Again, there are serious performance limitations that force you to build separate storage clusters, as with glusterfs.
- Using one nfs server to implement shared storage raises fault tolerance issues.
- s3 is an excellent popular solution for a certain range of tasks, but it is not a file system, which narrows the scope.
- lsyncd. If we already started talking about “non-file systems”, then it’s worth going over this popular solution. Not only is it not suitable for two-way exchange (but if you really want to, then you can), it also does not work stably on a large number of files. A nice addition to everything will be that it is single-threaded. The reason is in the architecture of the program: it uses inotify to monitor the objects of work that it hangs at startup and during rescan. Rsync is used as the transmission medium.
Tutorial: how to deploy shared storage based on drbd + ocfs2
One of the most convenient solutions for us was a bunch of ocfs2 + drbd . Now we’ll show you how to quickly deploy shared storage for two servers based on a database of solutions. But first, a little about the components:
DRBD is the storage system from the standard Linux distribution, which allows you to replicate data between server blocks. The main application is building fault tolerant storage.
OCFS2 is a file system that provides shared use of the same storage by multiple systems. Included in the distribution of Linux and is a kernel module and userspace tools for working with FS. OCFS2 can be used not only on top of DRBD, but also on top of iSCSI with multiple connections. In our example, we use DRBD.
All actions are performed on ubuntu server 18.04 in a minimal configuration.
Step 1. Configure DRBD:
In the file /etc/drbd.d/drbd0.res we describe our virtual block device / dev / drbd0:
resource drbd0 {
syncer { rate 1000M; }
net {
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
}
startup { become-primary-on both; }
on drbd1 {
meta-disk internal;
device /dev/drbd0;
disk /dev/vdb1;
address 10.10.10.192:7789;
}
on drbd2 {
meta-disk internal;
device /dev/drbd0;
disk /dev/vdb1;
address 10.10.10.193:7789;
}
}meta-disk internal - use the same block devices for storing metadata
device / dev / drbd0 - use / dev / drbd0 as the path to drbd volume.
disk / dev / vdb1 - use / dev / vdb1
syncer {rate 1000M; } - use gigabit of bandwidth
allow-two-primaries - an important option that allows the adoption of changes on two primary servers
after-sb-0pri, after-sb-1pri, after-sb-2pri - options that are responsible for the actions of the node when splitbrain is detected . See the documentation for more details.
become-primary-on both - sets both nodes to primary.
In our case, we have two absolutely identical VMs, with a dedicated virtual network bandwidth of 10 gigabits.
In our example, the network names of two cluster nodes are drbd1 and drbd2. For proper operation, you must map the names and ip addresses of the nodes in / etc / hosts.
10.10.10.192 drbd1
10.10.10.193 drbd2Step 2. Configure the nodes:
On both servers, execute:
drbdadm create-md drbd0modprobe drbd
drbdadm up drbd0
cat /proc/drbdWe get the following:
You can start synchronization. On the first node you need to do:
drbdadm primary --force drbd0We look at the status:
cat /proc/drbdGreat, the synchronization has begun. We wait for the end and see the picture:
Step 3. We start synchronization on the second node:
drbdadm primary --force drbd0
We
get the following: Now we can write to drbd from two servers.
Step 4. Install and configure ocfs2.
We will use a fairly trivial configuration:
cluster:
node_count = 2
name = ocfs2cluster
node:
number = 1
cluster = ocfs2cluster
ip_port = 7777
ip_address = 10.10.10.192
name = drbd1
node:
number = 2
cluster = ocfs2cluster
ip_port = 7777
ip_address = 10.10.10.193
name = drbd2
It needs to be written in /etc/ocfs2/cluster.conf on both nodes.
Create FS on drbd0 on any node:
mkfs.ocfs2 -L "testVol" /dev/drbd0
Here we created a file system labeled testVol on drbd0 using the default settings.
In / etc / default / o2cb must be set (as in our configuration file)
O2CB_ENABLED=true
O2CB_BOOTCLUSTER=ocfs2cluster and execute on each node:
o2cb register-cluster ocfs2clusterAfter that, turn on and add to the startup all the units we need:
systemctl enable drbd o2cb ocfs2
systemctl start drbd o2cb ocfs2Part of this will already be running during the setup process.
Step 5. Add mount points to fstab on both nodes:
/dev/drbd0 /media/shared ocfs2 defaults,noauto,heartbeat=local 0 0The / media / shared directory must be created in advance.
Here we use the noauto options, which means that the FS will not be mounted at startup (I prefer to mount network FS via systemd) and heartbeat = local, which means using the heartbeat service on each node. There is also a global heartbeat, which is more suitable for large clusters.
Next, you can mount / media / shared and check the synchronization of the content.
Done! As a result, we get a more or less fault-tolerant storage with scalability and decent performance.