Search at 1 TB / s
- Transfer
TL; DR: Four years ago, I left Google with the idea of a new tool for monitoring servers. The idea was to combine the usually isolated functions of collecting and analyzing logs, collecting metrics, alerts, and a dashboard into one service . One of the principles - the service should be really fast , providing the devs with an easy, interactive, enjoyable job. This requires processing data sets of several gigabytes in a split second, without going beyond the budget. Existing tools for working with logs are often slow and clumsy, so we faced a good task: to correctly develop a tool to give users new sensations from work.
This article describes how we at Scalyr solved this problem by applying the old-school methods, brute force approach, eliminating redundant layers and avoiding complex data structures. You can apply these lessons to your own engineering tasks.
Log analysis usually begins with a search: find all messages matching a certain template. In Scalyr, these are tens or hundreds of gigabytes of logs from many servers. Modern approaches, as a rule, involve the construction of some complex data structure optimized for search. Of course, I saw this on Google, where they are pretty good at such things. But we settled on a much rougher approach: linear scanning of logs. And it worked - we provide an interface with search an order of magnitude faster than that of competitors (see animation at the end).
The key insight is that modern processors are really very fast in simple, straightforward operations. This is easily overlooked in complex, multi-layered systems that depend on I / O speed and network operations, and such systems are very common today. Thus, we have developed a design that minimizes the number of layers and excess garbage. With multiple processors and servers in parallel, the search speed reaches 1 TB per second.
Key findings from this article:
(This article describes how to search for data in memory. In most cases, when a user searches for logs, Scalyr servers have already cached them. In the next article, we discuss search by uncached logs. The same principles apply: efficient code, brute force method with large computational resources).
Traditionally, a search in a large dataset is done using a keyword index. As applied to server logs, this means searching for each unique word in the log. For each word, you need to make a list of all inclusions. This makes it easy to find all messages with this word, for example, 'error', 'firefox' or 'transaction_16851951' - just look in the index.
I used this approach on Google and it worked well. But in Scalyr, we look in the logs for byte by byte.
Why? From an abstract algorithmic point of view, keyword indexes are much more effective than a crude search. However, we do not sell algorithms; we sell performance. And performance is not only algorithms, but also systems engineering. We must consider everything: the amount of data, the type of search, the available hardware and the software context. We decided that for our particular problem, an option like 'grep' is better than an index.
Indexes are great, but they have limitations. One word is easy to find. But finding messages with a few words, such as 'googlebot' and '404', is already much more complicated. Searching for phrases like 'uncaught exception' requires a more cumbersome index that not only records all messages with that word, but also the specific location of the word.
The real difficulty comes when you are not looking for words. Suppose you want to see how much traffic comes from bots. The first thought is to search the logs for the word 'bot'. So you will find some bots: Googlebot, Bingbot and many others. But here 'bot' is not a word, but part of it. If we search for 'bot' in the index, we will not find messages with the word 'Googlebot'. If you check each word in the index and then scan the index for the keywords found, the search will slow down greatly. As a result, some programs for working with logs do not allow searching in parts of a word or (at best) allow using special syntax with lower performance. We want to avoid this.
Another problem is punctuation. Want to find all queries from
Finally, engineers love powerful tools, and sometimes a problem can only be solved with a regular expression. The keyword index is not very suitable for this.
In addition, indexes are complex . Each message must be added to several keyword lists. These lists should always be kept in a search-friendly format. Queries with phrases, word fragments, or regular expressions must be translated into operations with multiple lists, and the results scanned and combined to obtain a result set. In the context of a large-scale multi-user service, this complexity creates performance problems that are not visible when analyzing the algorithms.
Keyword indexes also take up a lot of space, and storage is the main cost item in the log management system.
On the other hand, a lot of computing power can be spent on each search. Our users value high-speed searches for unique queries, but such queries are relatively rare. For typical search queries, for example, for the dashboard, we use special techniques (we will describe them in the next article). Other queries are quite rare, so you rarely need to process more than one at a time. But this does not mean that our servers are not busy: they are busy with the work of receiving, analyzing and compressing new messages, evaluating alerts, compressing old data and so on. Thus, we have a fairly substantial supply of processors that can be used to fulfill requests.
Brute force works best on simple tasks with small internal loops. Often you can optimize the inner loop to work at very high speeds. If the code is complex, it is much more difficult to optimize it.
Initially, our search code had a rather large inner loop. We store messages on 4K pages; each page contains some messages (in UTF-8) and metadata for each message. Metadata is a structure in which the length of the value, the internal message ID, and other fields are encoded. The search loop looked like this:

This is a simplified option compared to the actual code. But even here you can see several object placements, data copies and function calls. The JVM pretty well optimizes function calls and allocates ephemeral objects, so this code worked better than we deserved. During testing, clients used it quite successfully. But in the end we moved to a new level.
(You may ask why we store messages in this format with 4K pages, text and metadata, rather than working directly with the logs. There are many reasons why the internal Scalyr engine is more like a distributed database than file system Text search is often combined with DBMS style filters in the fields after log parsing We can search many thousands of logs at the same time, and simple text files are not suitable for our transactional, replicated, distributed control data).
Initially, it seemed that such code was not very suitable for optimization under the brute force method. The “real job” in
It so happened that we store metadata at the beginning of each page, and the text of all messages in UTF-8 is packed at the other end. Taking advantage of this, we rewrote the search cycle across the entire page:
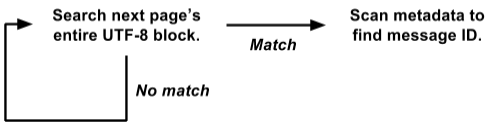
This version works directly on the view
This is much easier to optimize for brute force. The internal search cycle is called simultaneously for the entire 4K page, and not separately for each message. There is no data copying, no selection of objects. And more complex operations with metadata are called only with a positive result, and not for each message. Thus, we eliminated a ton of overhead, and the rest of the load is concentrated in a small internal search cycle, which is well suited for further optimization.
Our actual search algorithm is based on the great idea of Leonid Volnitsky . It is similar to the Boyer-Moore algorithm with skipping about the length of the search string at each step. The main difference is that it checks two bytes at a time to minimize false matches.
Our implementation requires creating a 64K lookup table for each search, but this is nonsense compared to the gigabytes of data we are looking for. The inner loop processes several gigabytes per second on a single core. In practice, stable performance is around 1.25 GB per second on each core, and there is potential for improvement. You can eliminate some of the overhead outside the inner loop, and we plan to experiment with the inner loop in C instead of Java.
We discussed that log searches can be implemented “roughly”, but how much “power” do we have? A lot.
1 core : when used correctly, one core of a modern processor is quite powerful in itself.
8 cores : we are currently working on Amazon hi1.4xlarge and i2.4xlarge SSD servers, each of which has 8 cores (16 threads). As mentioned above, usually these kernels are busy with background operations. When the user performs a search, the background operations are paused, freeing all 8 cores for the search. The search usually completes in a split second, after which the background work resumes (the controller program ensures that a barrage of search queries will not interfere with important background work).
16 cores: for reliability, we organize the servers into master / slave groups. Each master has one SSD server and one EBS subordinate. If the main server crashes, the server on the SSD immediately takes its place. Almost all the time, master and slave work fine, so each data block is searchable on two different servers (the slave EBS server has a weak processor, so we don’t consider it). We divide the task between them, so that we have a total of 16 cores available.
Many cores : in the near future we will distribute the data among the servers so that they all participate in the processing of each non-trivial request. Each core will work. [Note: we implemented the plan and increased the search speed to 1 TB / s, see the note at the end of the article ].
Another advantage of brute force is its relatively stable performance. As a rule, the search is not too sensitive to the details of the task and data set (I think that’s why it is called “rude”).
The keyword index sometimes produces incredibly fast results, but in other cases it doesn't. Suppose you have 50 GB of logs in which the term 'customer_5987235982' occurs exactly three times. A search by this term counts three locations directly from the index and ends instantly. But a complex wildcard search can scan thousands of keywords and take a lot of time.
On the other hand, brute force searches for any query are performed at more or less the same speed. The search for long words is better, but even the search for a single character is fast enough.
The simplicity of the brute force method means that its productivity is close to the theoretical maximum. There are fewer options for unexpected disk overload, lock conflict, pointer chases, and thousands of other reasons for failures. I just looked at the requests made by Scalyr users last week on our busiest server. There were 14,000 requests. Exactly eight of them took more than one second; 99% performed within 111 milliseconds (if you have not used the log analysis tools, believe me: this is fast ).
Stable, reliable performance is important for the convenience of using the service. If it periodically slows down, users will perceive it as unreliable and are reluctant to use it.
Here's a little animation that shows Scalyr searching in action. We have a demo account where we import every event in every public Github repository. In this demo, I study the data for the week: approximately 600 MB of raw logs.
The video was recorded live, without special preparation, on my desktop (about 5000 kilometers from the server). The performance that you will see is largely due to the optimization of the web client , as well as to the fast and reliable backend. Whenever there is a pause without the 'loading' indicator, I pause it so that you can read what I'm going to click.

When processing large amounts of data, it is important to choose a good algorithm, but “good” does not mean “fancy”. Think about how your code will work in practice. Some factors that can be of great importance in the real world fall out of the theoretical analysis of algorithms. Simpler algorithms are easier to optimize and are more stable in borderline situations.
Also think about the context in which the code will execute. In our case, we need powerful enough servers to manage background tasks. Users relatively rarely initiate a search, so we can borrow a whole group of servers for the short period necessary to complete each search.
Using brute force, we implemented a quick, reliable, flexible search on a set of logs. We hope that these ideas will be useful for your projects.
Edit: The title and text changed from “Search at 20 GB per second” to “Search at 1 TB per second” to reflect the increase in performance over the past few years. This increase in speed is primarily due to a change in the type and number of EC2 servers that we are raising today to serve the increased client base. In the near future, changes are expected that will provide another sharp increase in work efficiency, and we look forward to the opportunity to tell about it.
This article describes how we at Scalyr solved this problem by applying the old-school methods, brute force approach, eliminating redundant layers and avoiding complex data structures. You can apply these lessons to your own engineering tasks.
The strength of the old school
Log analysis usually begins with a search: find all messages matching a certain template. In Scalyr, these are tens or hundreds of gigabytes of logs from many servers. Modern approaches, as a rule, involve the construction of some complex data structure optimized for search. Of course, I saw this on Google, where they are pretty good at such things. But we settled on a much rougher approach: linear scanning of logs. And it worked - we provide an interface with search an order of magnitude faster than that of competitors (see animation at the end).
The key insight is that modern processors are really very fast in simple, straightforward operations. This is easily overlooked in complex, multi-layered systems that depend on I / O speed and network operations, and such systems are very common today. Thus, we have developed a design that minimizes the number of layers and excess garbage. With multiple processors and servers in parallel, the search speed reaches 1 TB per second.
Key findings from this article:
- Rough search is a viable approach to solving real, large-scale problems.
- Brute force is a design technique, not liberation from work. Like any technique, it is better suited for some problems than for others, and it can be implemented poorly or well.
- Brute force is especially good for stable performance.
- The effective use of brute force requires code optimization and the timely use of sufficient resources. It is suitable if your servers are under heavy non-user workloads and user operations remain a priority.
- Performance depends on the design of the entire system, and not just on the internal loop algorithm.
(This article describes how to search for data in memory. In most cases, when a user searches for logs, Scalyr servers have already cached them. In the next article, we discuss search by uncached logs. The same principles apply: efficient code, brute force method with large computational resources).
Brute force method
Traditionally, a search in a large dataset is done using a keyword index. As applied to server logs, this means searching for each unique word in the log. For each word, you need to make a list of all inclusions. This makes it easy to find all messages with this word, for example, 'error', 'firefox' or 'transaction_16851951' - just look in the index.
I used this approach on Google and it worked well. But in Scalyr, we look in the logs for byte by byte.
Why? From an abstract algorithmic point of view, keyword indexes are much more effective than a crude search. However, we do not sell algorithms; we sell performance. And performance is not only algorithms, but also systems engineering. We must consider everything: the amount of data, the type of search, the available hardware and the software context. We decided that for our particular problem, an option like 'grep' is better than an index.
Indexes are great, but they have limitations. One word is easy to find. But finding messages with a few words, such as 'googlebot' and '404', is already much more complicated. Searching for phrases like 'uncaught exception' requires a more cumbersome index that not only records all messages with that word, but also the specific location of the word.
The real difficulty comes when you are not looking for words. Suppose you want to see how much traffic comes from bots. The first thought is to search the logs for the word 'bot'. So you will find some bots: Googlebot, Bingbot and many others. But here 'bot' is not a word, but part of it. If we search for 'bot' in the index, we will not find messages with the word 'Googlebot'. If you check each word in the index and then scan the index for the keywords found, the search will slow down greatly. As a result, some programs for working with logs do not allow searching in parts of a word or (at best) allow using special syntax with lower performance. We want to avoid this.
Another problem is punctuation. Want to find all queries from
50.168.29.7? What about debugging logs containing[error]? Indexes usually skip punctuation. Finally, engineers love powerful tools, and sometimes a problem can only be solved with a regular expression. The keyword index is not very suitable for this.
In addition, indexes are complex . Each message must be added to several keyword lists. These lists should always be kept in a search-friendly format. Queries with phrases, word fragments, or regular expressions must be translated into operations with multiple lists, and the results scanned and combined to obtain a result set. In the context of a large-scale multi-user service, this complexity creates performance problems that are not visible when analyzing the algorithms.
Keyword indexes also take up a lot of space, and storage is the main cost item in the log management system.
On the other hand, a lot of computing power can be spent on each search. Our users value high-speed searches for unique queries, but such queries are relatively rare. For typical search queries, for example, for the dashboard, we use special techniques (we will describe them in the next article). Other queries are quite rare, so you rarely need to process more than one at a time. But this does not mean that our servers are not busy: they are busy with the work of receiving, analyzing and compressing new messages, evaluating alerts, compressing old data and so on. Thus, we have a fairly substantial supply of processors that can be used to fulfill requests.
Brute force works if you have a brute force problem (and a lot of force)
Brute force works best on simple tasks with small internal loops. Often you can optimize the inner loop to work at very high speeds. If the code is complex, it is much more difficult to optimize it.
Initially, our search code had a rather large inner loop. We store messages on 4K pages; each page contains some messages (in UTF-8) and metadata for each message. Metadata is a structure in which the length of the value, the internal message ID, and other fields are encoded. The search loop looked like this:
This is a simplified option compared to the actual code. But even here you can see several object placements, data copies and function calls. The JVM pretty well optimizes function calls and allocates ephemeral objects, so this code worked better than we deserved. During testing, clients used it quite successfully. But in the end we moved to a new level.
(You may ask why we store messages in this format with 4K pages, text and metadata, rather than working directly with the logs. There are many reasons why the internal Scalyr engine is more like a distributed database than file system Text search is often combined with DBMS style filters in the fields after log parsing We can search many thousands of logs at the same time, and simple text files are not suitable for our transactional, replicated, distributed control data).
Initially, it seemed that such code was not very suitable for optimization under the brute force method. The “real job” in
String.indexOf()did not even dominate the CPU profile. That is, optimization of only this method would not bring a significant effect.It so happened that we store metadata at the beginning of each page, and the text of all messages in UTF-8 is packed at the other end. Taking advantage of this, we rewrote the search cycle across the entire page:
This version works directly on the view
raw byte[]and searches for all messages on the entire 4K page at once.This is much easier to optimize for brute force. The internal search cycle is called simultaneously for the entire 4K page, and not separately for each message. There is no data copying, no selection of objects. And more complex operations with metadata are called only with a positive result, and not for each message. Thus, we eliminated a ton of overhead, and the rest of the load is concentrated in a small internal search cycle, which is well suited for further optimization.
Our actual search algorithm is based on the great idea of Leonid Volnitsky . It is similar to the Boyer-Moore algorithm with skipping about the length of the search string at each step. The main difference is that it checks two bytes at a time to minimize false matches.
Our implementation requires creating a 64K lookup table for each search, but this is nonsense compared to the gigabytes of data we are looking for. The inner loop processes several gigabytes per second on a single core. In practice, stable performance is around 1.25 GB per second on each core, and there is potential for improvement. You can eliminate some of the overhead outside the inner loop, and we plan to experiment with the inner loop in C instead of Java.
Apply force
We discussed that log searches can be implemented “roughly”, but how much “power” do we have? A lot.
1 core : when used correctly, one core of a modern processor is quite powerful in itself.
8 cores : we are currently working on Amazon hi1.4xlarge and i2.4xlarge SSD servers, each of which has 8 cores (16 threads). As mentioned above, usually these kernels are busy with background operations. When the user performs a search, the background operations are paused, freeing all 8 cores for the search. The search usually completes in a split second, after which the background work resumes (the controller program ensures that a barrage of search queries will not interfere with important background work).
16 cores: for reliability, we organize the servers into master / slave groups. Each master has one SSD server and one EBS subordinate. If the main server crashes, the server on the SSD immediately takes its place. Almost all the time, master and slave work fine, so each data block is searchable on two different servers (the slave EBS server has a weak processor, so we don’t consider it). We divide the task between them, so that we have a total of 16 cores available.
Many cores : in the near future we will distribute the data among the servers so that they all participate in the processing of each non-trivial request. Each core will work. [Note: we implemented the plan and increased the search speed to 1 TB / s, see the note at the end of the article ].
Simplicity Provides Reliability
Another advantage of brute force is its relatively stable performance. As a rule, the search is not too sensitive to the details of the task and data set (I think that’s why it is called “rude”).
The keyword index sometimes produces incredibly fast results, but in other cases it doesn't. Suppose you have 50 GB of logs in which the term 'customer_5987235982' occurs exactly three times. A search by this term counts three locations directly from the index and ends instantly. But a complex wildcard search can scan thousands of keywords and take a lot of time.
On the other hand, brute force searches for any query are performed at more or less the same speed. The search for long words is better, but even the search for a single character is fast enough.
The simplicity of the brute force method means that its productivity is close to the theoretical maximum. There are fewer options for unexpected disk overload, lock conflict, pointer chases, and thousands of other reasons for failures. I just looked at the requests made by Scalyr users last week on our busiest server. There were 14,000 requests. Exactly eight of them took more than one second; 99% performed within 111 milliseconds (if you have not used the log analysis tools, believe me: this is fast ).
Stable, reliable performance is important for the convenience of using the service. If it periodically slows down, users will perceive it as unreliable and are reluctant to use it.
Log Search in Action
Here's a little animation that shows Scalyr searching in action. We have a demo account where we import every event in every public Github repository. In this demo, I study the data for the week: approximately 600 MB of raw logs.
The video was recorded live, without special preparation, on my desktop (about 5000 kilometers from the server). The performance that you will see is largely due to the optimization of the web client , as well as to the fast and reliable backend. Whenever there is a pause without the 'loading' indicator, I pause it so that you can read what I'm going to click.
Finally
When processing large amounts of data, it is important to choose a good algorithm, but “good” does not mean “fancy”. Think about how your code will work in practice. Some factors that can be of great importance in the real world fall out of the theoretical analysis of algorithms. Simpler algorithms are easier to optimize and are more stable in borderline situations.
Also think about the context in which the code will execute. In our case, we need powerful enough servers to manage background tasks. Users relatively rarely initiate a search, so we can borrow a whole group of servers for the short period necessary to complete each search.
Using brute force, we implemented a quick, reliable, flexible search on a set of logs. We hope that these ideas will be useful for your projects.
Edit: The title and text changed from “Search at 20 GB per second” to “Search at 1 TB per second” to reflect the increase in performance over the past few years. This increase in speed is primarily due to a change in the type and number of EC2 servers that we are raising today to serve the increased client base. In the near future, changes are expected that will provide another sharp increase in work efficiency, and we look forward to the opportunity to tell about it.