Speeding up C / C ++ file I / O without really straining

Foreword
There is such a simple and very useful utility in the world - BDelta , and it so happened that it took root in our production process for a long time (although its version could not be installed, but it was certainly not the last available). We use it for its intended purpose - the construction of binary patches. If you look at what is in the repository, it becomes a little sad: in fact, it was abandoned a long time ago and much was very outdated there (once my former colleague made several corrections there, but it was a long time ago). In general, I decided to resurrect this business: I forked, threw out what I do not plan to use, overtook the project on cmake, added “hot” microfunctions, removed large arrays from the stack (and variable-length arrays, from which I frankly “bombed”), drove out the profiler again - and found out that about 40% of the time is spent on fwrite ...
So what's up with fwrite?
In this code, fwrite (in my specific test case: building a patch between close 300 MB files, the input data is completely in memory) is called millions of times with a small buffer. Obviously, this thing will slow down, and therefore I would like to somehow influence this disgrace. There is no desire to implement any kind of data sources, asynchronous input-output, I wanted to find a solution easier. The first thing that came to mind was to increase the size of the buffer
setvbuf(file, nullptr, _IOFBF, 64* 1024)but I did not get a significant improvement in the result (now fwrite accounted for about 37% of the time) - it means the matter is still not in the frequent data recording to disk. Looking fwrite “under the hood”, you can see that the lock / unlock FILE structure is happening inside like this (pseudo-code, all analysis was done under Visual Studio 2017):
size_t fwrite (const void *buffer, size_t size, size_t count, FILE *stream)
{
size_t retval = 0;
_lock_str(stream); /* lock stream */
__try
{
retval = _fwrite_nolock(buffer, size, count, stream);
}
__finally
{
_unlock_str(stream); /* unlock stream */
}
return retval;
}
According to the profiler, _fwrite_nolock accounts for only 6% of the time, the rest is overhead. In my particular case, thread safety is an obvious excess, I’ll sacrifice it by replacing the fwrite call with _fwrite_nolock - even with arguments I don’t need to be smart . Total: this simple manipulation at times reduced the cost of recording the result, which in the original version amounted to almost half the time cost. By the way, in the POSIX world there is a similar function - fwrite_unlocked . Generally speaking, the same goes for fread. Thus, with the help of the #define pair, you can get yourself a cross-platform solution without unnecessary locks if they are not necessary (and this happens quite often).
fwrite, _fwrite_nolock, setvbuf
Let's abstract from the original project and start testing a specific case: recording a large file (512 MB) in extremely small portions - 1 byte. Test system: AMD Ryzen 7 1700, 16 GB RAM, HDD 3.5 "7200 rpm 64 MB cache, Windows 10 1809, the binar was built in 32-bit, optimizations are enabled, the library is statically linked.
Sample for the experiment:
#include
#include
#include
#include
#ifdef _MSC_VER
#define fwrite_unlocked _fwrite_nolock
#endif
using namespace std::chrono;
int main()
{
std::unique_ptr file(fopen("test.bin", "wb"), fclose);
if (!file)
return 1;
constexpr size_t TEST_BUFFER_SIZE = 256 * 1024;
if (setvbuf(file.get(), nullptr, _IOFBF, TEST_BUFFER_SIZE) != 0)
return 2;
auto start = steady_clock::now();
const uint8_t b = 77;
constexpr size_t TEST_FILE_SIZE = 512 * 1024 * 1024;
for (size_t i = 0; i < TEST_FILE_SIZE; ++i)
fwrite_unlocked(&b, sizeof(b), 1, file.get());
auto end = steady_clock::now();
auto interval = duration_cast(end - start);
printf("Time: %lld\n", interval.count());
return 0;
}
The variables will be TEST_BUFFER_SIZE, and for a couple of cases we’ll replace fwrite_unlocked with fwrite. Let's start with the case of fwrite without explicitly setting the buffer size (comment out setvbuf and the associated code): time 27048906 μs, write speed - 18.93 Mb / s. Now set the buffer size to 64 Kb: time - 25037111 μs, speed - 20.44 Mb / s. Now we test the operation of _fwrite_nolock without calling setvbuf: 7262221 ms, the speed is 70.5 Mb / s!
Next, experiment with the size of the buffer (setvbuf):
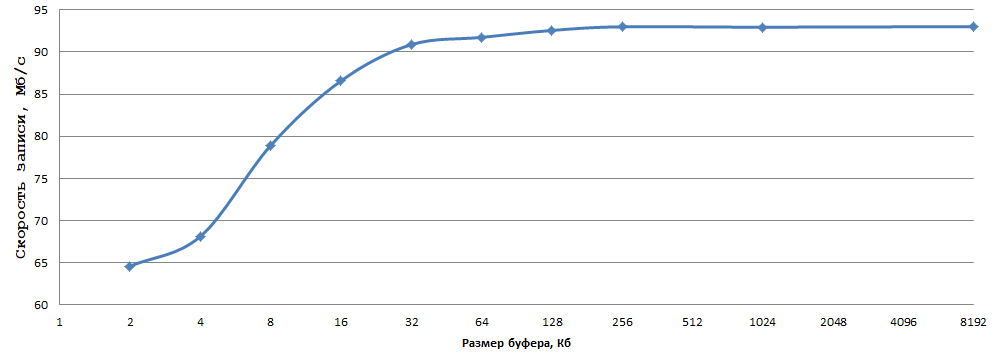
The data were obtained by averaging 5 experiments; I was too lazy to consider the errors. As for me, 93 MB / s when writing 1 byte to a regular HDD is a very good result, just select the optimal buffer size (in my case 256 KB - just right) and replace fwrite with _fwrite_nolock / fwrite_unlocked (in if thread safety is not needed, of course).
Similarly with fread in similar conditions. Now let's see how things are on Linux, the test configuration is as follows: AMD Ryzen 7 1700X, 16 GB RAM, HDD 3.5 "7200 rpm 64 MB cache, OpenSUSE 15 OS, GCC 8.3.1, we will test x86-64 binar, file system on ext4 test section The result of fwrite without explicitly setting the buffer size in this test is 67.6 Mb / s, when setting the buffer to 256 Kb the speed increased to 69.7 Mb / s. Now we will carry out similar measurements for fwrite_unlocked - the results are 93.5 and 94.6 Mb / s, respectively. Varying the buffer size from 1 KB to 8 MB led me to the following conclusions: increasing the buffer increases the write speed, but the difference in my case was only 3 Mb / s, I did not notice any difference in speed between the 64 Kb and 8 Mb buffer at all. From the data received on this Linux machine, we can draw the following conclusions:
- fwrite_unlocked is faster than fwrite, but the difference in write speed is not as great as on Windows
- Buffer size on Linux does not have as significant an effect on write speed through fwrite / fwrite_unlocked as on Windows
In total, the proposed method is effective both on Windows, but also on Linux (albeit to a much lesser extent).
Afterword
The purpose of this article was to describe a simple and effective technique in many cases (I didn’t come across the _fwrite_nolock / fwrite_unlocked functions earlier, they are not very popular - but in vain). I do not pretend to be new to the material, but I hope that the article will be useful to the community.