Monolith for hundreds of client versions: how we write and support tests

Hello!
I am a backend developer in the Badoo server team. At last year’s HighLoad conference, I made a presentation , a text version of which I want to share with you. This post will be most useful to those who write tests for the backend themselves and experience problems with testing legacy-code, as well as those who want to test complex business logic.
What will we talk about? First, I will briefly talk about our development process and how it affects our need for tests and the desire to write these tests. Then we will go up and down the pyramid of test automation, discuss the types of tests we use, talk about the tools inside each of them and what problems we solve with their help. In the end, consider how to maintain and run all this stuff.
Our development process
We have illustrated our development process:

A golfer is a backend developer. At some point, a development task arrives at him, usually in the form of two documents: requirements from the business side and a technical document that describes the changes in our protocol of interaction between the backend and clients (mobile applications and the site).
The developer writes the code and puts it into operation, and earlier than all client applications. All functionality is protected by some feature flags or A / B tests, this is prescribed in a technical document. After that, in accordance with current priorities and the product roadmap, client applications are released. For us, backend developers, it is completely unpredictable when a particular feature will be implemented on clients. The release cycle for client applications is somewhat more complicated and longer than ours, so our product managers literally juggle priorities.
The development culture adopted by the company is of great importance: the backend developer is responsible for the feature from the moment of its implementation on the backend to the last integration on the last platform on which it was originally planned to implement this feature.
This situation is quite possible: six months ago, you rolled out some feature, client teams did not implement it for a long time, because the priorities of the company have changed, you are already busy working on other tasks, you have new deadlines, priorities - and here your colleagues come running and they say: “Do you remember this thing that you washed down six months ago? It does not work". And instead of engaging in new tasks, you put out the fires.

Therefore, our developers have a motivation unusual for PHP programmers - to make sure that there are as few problems as possible during the integration phase.
What do you want to do first of all to make sure that the feature works?
Of course, the first thing that comes to mind is to conduct manual testing. You pick up the application, but it does not know how - because the feature is new, customers will take care of it in six months. Well, manual testing does not give any guarantee that for the time that elapses from the release of the backend to the start of integration, no one will break anything on the clients.
And here automated tests come to our aid.
Unit tests
The simplest tests we write are Unit tests. We use PHP as the main language for the backend, and PHPUnit as the framework for unit testing. Looking ahead, I’ll say that all our backend tests are written on the basis of this framework.
Unit tests we most often cover some small isolated pieces of code, check the performance of methods or functions, that is, we are talking about tiny units of business logic. Our unit tests should not interact with anything, access databases or services.
Softmocks
The main difficulty that developers face when writing unit tests is untestable code, and this is usually legacy code.
A simple example. Badoo is 12 years old, once it was a very small startup, which was developed by several people. The startup quite successfully existed without any tests at all. Then we got big enough and realized that you can't live without tests. But by this time a lot of code had been written that worked. Do not rewrite it just for the sake of testing! That would not be very reasonable from a business point of view.
Therefore, we developed a small open source library SoftMockswhich makes our test writing process cheaper and faster. It intercepts all include / require PHP files and on-the-fly replaces the source file with modified content, that is, rewritten code. This allows us to create stubs for any code. It details how the library functions.
This is what it looks like for a developer:
//mock константы
\Badoo\SoftMocks::redefineConstant($constantName, $newValue);
//mock любых методов: статических, приватных, финальных
\Badoo\SoftMocks::redefineMethod(
$class,
$method,
$method_args,
$fake_code
);
//mock функций
\Badoo\SoftMocks::redefineFunction(
$function,
$function_args,
$fake_code
);
With the help of such simple constructions, we can globally redefine everything we want. In particular, they allow us to circumvent the limitations of the standard PHPUnit maker. That is, we can mock static and private methods, redefine constants and do much more, which is impossible in ordinary PHPUnit.
However, we ran into a problem: it seems to developers that if there are SoftMocks, there is no need to write the tested code - you can always “comb” the code with our global mocks, and everything will work well. But this approach leads to more complex code and the accumulation of "crutches." Therefore, we adopted several rules that allow us to keep the situation under control:
- All new code should be easily tested with standard PHPUnit mocks. If this condition is met, then the code is testable and you can easily select a small piece and test only it.
- SoftMocks can be used with old code that is written in a way that is not suitable for unit testing, as well as in cases where it is too expensive / long / difficult to do otherwise (emphasize the necessary).
Compliance with these rules is carefully monitored at the code review stage.
Mutation Testing
Separately, I want to say about the quality of unit tests. I think many of you use metrics like code coverage. But she, unfortunately, does not answer one question: "Have I written a good unit test?" It is possible that you wrote such a test, which actually does not check anything, does not contain a single assert, but it generates excellent code coverage. Of course, the example is exaggerated, but the situation is not so far from reality.
Recently, we began to introduce mutational testing. This is a rather old, but not very well-known concept. The algorithm for such testing is quite simple:
- take the code and code coverage;
- parsim and begin to change the code: true to false,> to> =, + to - (in general, harm in every way);
- for each such mutation change, run test suites that cover the changed string;
- if the tests fall, then they are good and really do not allow us to break the code;
- if the tests have passed, most likely, they are not effective enough, despite the coverage, and it may be worth looking at them more closely, to give some assert (or there is an area not covered by the test).
There are several ready-made frameworks for PHP, such as Humbug and Infection. Unfortunately, they did not suit us, because they are incompatible with SoftMocks. Therefore, we wrote our own little console utility, which does the same, but uses our internal code coverage format and is friends with SoftMocks. Now the developer starts it manually and analyzes the tests written by him, but we are working on introducing the tool into our development process.
Integration testing
With the help of integration tests, we check the interaction with various services and databases.
To further understand the story, let's develop a fictional promo and cover it with tests. Imagine that our product managers decided to distribute conference tickets to our most dedicated users:

Promo should be shown if:
- the user in the field "Work" indicates "programmer",
- the user participates in the A / B test HL18_promo,
- The user is registered more than two years ago.
By clicking on the “Get a Ticket” button, we must save this user's data to some list in order to transfer it to our managers who distribute tickets.
Even in this rather simple example, there is a thing that cannot be verified using unit tests - interaction with the database. To do this, we need to use integration tests.
Consider the standard way to test database interaction offered by PHPUnit:
- Raise the test database.
- We prepare DataTables and DataSets.
- Run the test.
- We clear the test database.
What difficulties lie in wait with such an approach?
- You need to support the structures of DataTables and DataSets. If we changed the table layout, then it is necessary to reflect these changes in the test, which is not always convenient and requires additional time.
- It takes time to prepare the database. Each time when setting up the test, we need to upload something there, create some tables, and this is long and troublesome if there are a lot of tests.
- And the most important drawback: running these tests in parallel makes them unstable. We started test A, he began to write to the test table, which he created. At the same time, we launched test B, which wants to work with the same test table. As a result, mutual blockages and other unforeseen situations arise.
To avoid these problems, we developed our own small library DBMocks.
DBMocks
The principle of operation is as follows:
- With the help of SoftMocks we intercept all the wrappers through which we work with databases.
- When the
request passes through mock, parse the SQL query and pull DB + TableName from it, and get the host from connection. - On the same host in tmpfs we create a temporary table with the same structure as the original one (we copy the structure using SHOW CREATE TABLE).
- After that, we will redirect all requests that will come through mock to this table to a freshly created temporary one.
What does this give us:
- no need to constantly take care of the structures;
- tests can no longer corrupt data in source tables, because we redirect them to temporary tables on the fly;
- we are still testing compatibility with the version of MySQL we are working with, and if the request suddenly ceases to be compatible with the new version, then our test will see and crash it.
- and most importantly, the tests are now isolated, and even if you run them in parallel, the threads will disperse to different temporary tables, since we add a key unique to each test in the names of the test tables.
API testing
The difference between unit and API tests is well illustrated by this gif:

The lock works fine, but it is attached to the wrong door.
Our tests simulate a client session, are able to send requests to the backend, following our protocol, and the backend responds to them as a real client.
Test User Pool
What do we need to successfully write such tests? Let us return to the conditions of the show of our promo:
- the user in the field "Work" indicates "programmer",
- the user participates in the A / B test HL18_promo,
- The user is registered more than two years ago.
Apparently, here everything is about the user. And in reality, 99% of API tests require an authorized registered user, which is present in all services and databases.
Where to get it? You can try to register it at the time of testing, but:
- it is long and resource consuming;
- after completing the test, this user needs to be removed somehow, which is a rather non-trivial task if we are talking about large projects;
- finally, as in many other highly loaded projects, we perform many operations in the background (adding a user to various services, replication to other data centers, etc.); tests do not know anything about such processes, but if they implicitly rely on the results of their execution, there is a risk of instability.
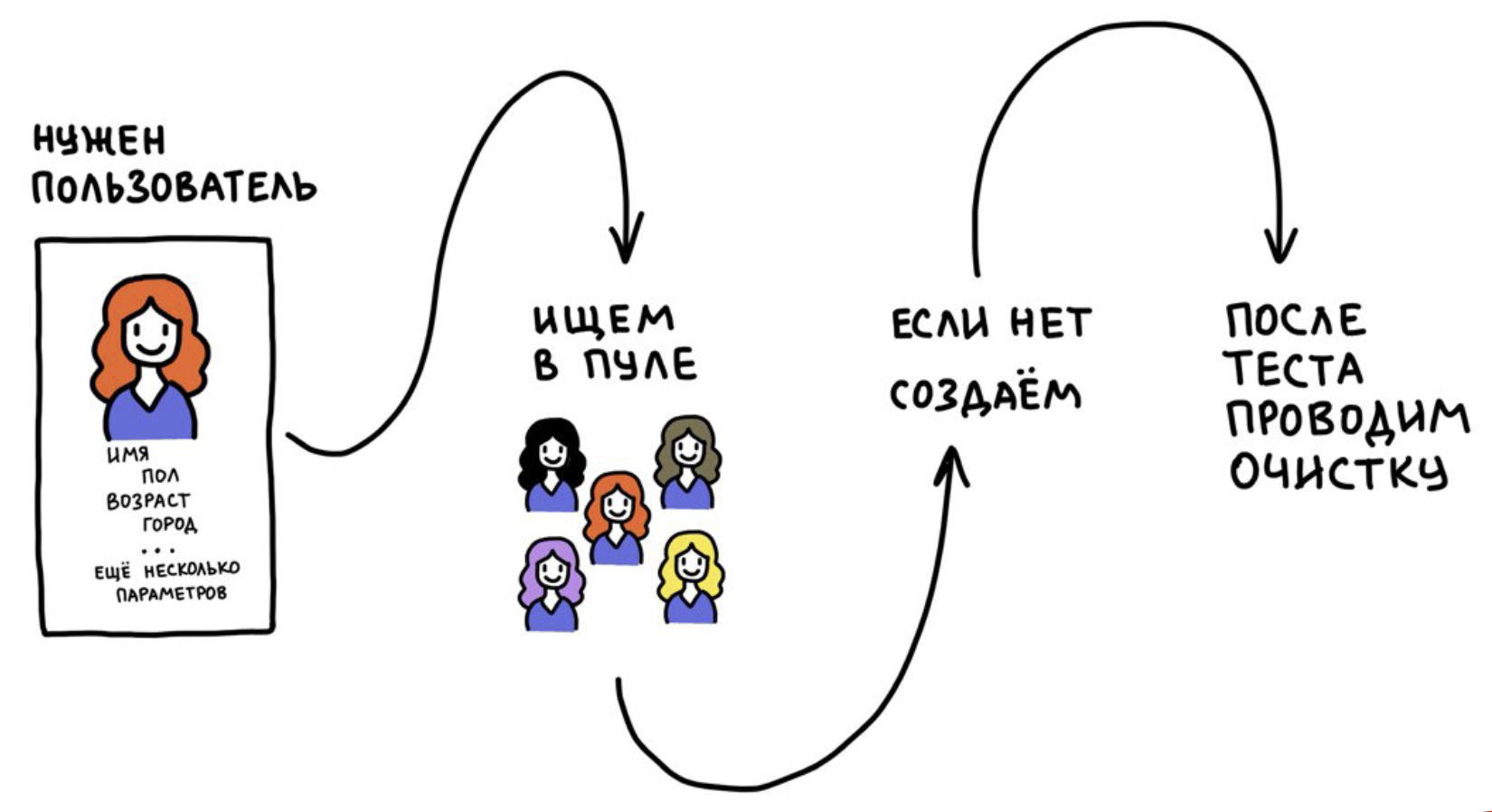
We developed a tool called the Test Users Pool. It is based on two ideas:
- We do not register users every time, but use it many times.
- After the test, we reset the user data to its original state (at the time of registration). If this is not done, the tests will become unstable over time, because users will be “polluted” with information from other tests.
It works something like this:
At some point, we wanted to run our API tests in a production environment. Why do we even want this? Because the devel infrastructure is not the same as production.
Although we are trying to constantly repeat the production infrastructure at a reduced size, devel will never be a full copy of it. To be absolutely sure that the new build meets expectations and there are no problems, we upload the new code to the preproduction cluster, which works with production data and services, and run our API tests there.
In this case, it is very important to think about how to isolate test users from real ones.
What will happen if test users start to appear real in our application.
How to isolate? Each of our users has a flag
is_test_user. At the registration stage, it becomes yesor no, and no longer changes. By this flag, we isolate users in all services. It is also important that we exclude test users from business analytics and the results of A / B testing so as not to distort statistics. You can go in a simpler way: we started with the fact that all test users were “relocated” to Antarctica. If you have a geoservice, this is a completely working way.
QA API
We do not just need a user - we need it with certain parameters: to work as a programmer, participate in a certain A / B test and was registered more than two years ago. For test users, we can easily assign a profession using our backend API, but getting into A / B tests is probabilistic. And the condition of registration more than two years ago is generally difficult to fulfill, because we do not know when the user appeared in the pool.
To solve these problems, we have a QA API. This, in fact, is a backdoor for testing, which is a well-documented API methods that allow you to quickly and easily manage user data and change their state bypassing the main protocol of our communication with clients. The methods are written by backend developers for QA engineers and for use in UI and API tests.
QA API can be applied only in the case of test users: if there is no corresponding flag, the test will immediately fall. Here is one of our QA API methods that allows you to change the user registration date to an arbitrary one:
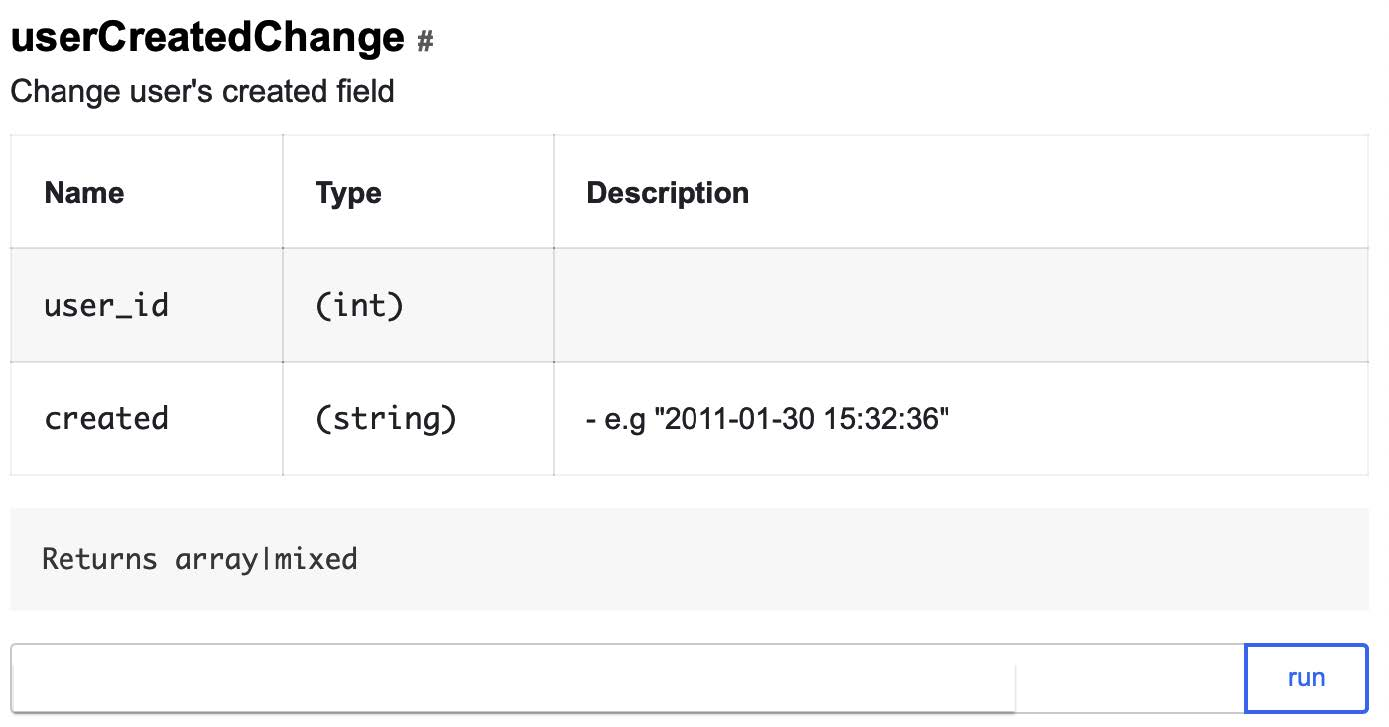
And it will look like three calls that will allow you to quickly change the test user data so that they satisfy the conditions for displaying the promo:
- In the field “Work” the “programmer” is indicated:
addUserWorkEducation?user_id=ID&works[]=Badoo,
программист - The user participates in the A / B test HL18_promo:
forceSplitTest?user_id=ID&test=HL18_promo - Registered more than two years ago:
userCreatedChange?user_id=ID&created=2016-09-01
Since this is a backdoor, it is imperative to think about security. We protected our service in several ways:
- isolated at the network level: services can be accessed only from the office network;
- with each request we pass a secret, without which it is impossible to access the QA API even from the office network;
- methods work only with test users.
Remotemocks
To work with the remote backend of API tests, we may need mocks. For what? For example, if the API test in the production environment starts to access the database, we need to make sure that the data in it is cleared of the test data. In addition, mocks help make the test response more suitable for testing.
We have three texts:
Badoo is a multilingual application, we have a complex localization component that allows you to quickly translate and receive translations for the user's current location. Our localizers are constantly working to improve translations, conduct A / B tests with tokens, and look for more successful formulations. And, while conducting the test, we cannot know which text will be returned by the server - it can change at any time. But we can use RemoteMocks to check whether the localization component is accessed correctly.
How do RemoteMocks work? The test asks the backend to initialize them for its session, and upon receipt of all subsequent requests the backend checks for mocks for the current session. If they are, it simply initializes them using SoftMocks.
If we want to create a remote mock, we indicate which class or method needs to be replaced and with what. All subsequent backend requests will be executed taking into account this mock:
$this->remoteInterceptMethod(
\Promo\HighLoadConference::class,
'saveUserEmailToDb',
true
);
Well, now let's collect our API test:
//получаем эмулятор клиента с уже авторизованным пользователем
$app_startup = [
'supported_promo_blocks' => [\Mobile\Proto\Enum\PromoBlockType::GENERIC_PROMO]
];
$Client = $this->getLoginedConnection(BmaFunctionalConfig::USER_TYPE_NEW, $app_startup);
//подстраиваем пользователя
$Client->getQaApiClient()->addUserWorkEducation(['Badoo, программист']);
$Client->getQaApiClient()->forceSplitTest('HL18_promo');
$Client->getQaApiClient()->userCreatedChange('2016-09-01');
//мокаем запись в базу данных
$this->remoteInterceptMethod(\Promo\HighLoadConference::class, 'saveUserEmail', true);
//проверяем, что вернулся промоблок, согласно протоколу
$Resp = $Client->ServerGetPromoBlocks([]);
$this->assertTrue($Resp->hasMessageType('CLIENT_NEXT_PROMO_BLOCKS'));
$PromoBlock = $Resp->CLIENT_NEXT_PROMO_BLOCKS;
…
//пользователь жмёт на CTA, проверяем, что вернулся ответ, согласно протоколу
$Resp = $Client->ServerPromoAccepted($PromoBlock->getPromoId());
$this->assertTrue($Resp->hasMessageType('CLIENT_ACKNOWLEDGE_COMMAND'));
In such a simple way, we can test any functionality that comes to development in the backend and requires changes in the mobile protocol.
API Test Usage Rules
Everything seems to be fine, but we again encountered a problem: the API tests turned out to be too convenient for development and there was a temptation to use them everywhere. As a result, once we realized that we were starting to solve problems with the help of API tests for which they were not intended.
Why is that bad? Because API tests are very slow. They go on the network, turn to the backend, which picks up the session, goes to the database and a bunch of services. Therefore, we developed a set of rules for using API tests:
- The purpose of the API tests is to check the protocol of interaction between the client and the server, as well as the correct integration of the new code;
- it is permissible to cover complex processes with them, for example, chains of actions;
- they cannot be used to test the small variability of the server response - this is the task of unit tests;
- during the code review, we check including tests.
UI tests
Since we are considering a pyramid of automation, I will tell you a little about UI tests.
Backend developers at Badoo do not write UI tests - for this we have a dedicated team in the QA department. We cover the feature with UI tests when it is already brought to mind and stabilized, because we believe that it is unreasonable to spend resources on rather expensive automation of the feature, which, perhaps, will not go beyond the A / B test.
We use Calabash for mobile auto tests, and Selenium for the web. It talks about our platform for automation and testing.
Test run
We now have 100,000 unit tests, 6,000 - integration tests and 14,000 API tests. If you try to run them in one thread, then even on our most powerful machine, a full run of all will take: modular - 40 minutes, integration - 90 minutes, API tests - ten hours. This is too long.
Parallelization
We talked about our experience of parallelizing unit tests in this article .
The first solution, which seems obvious, is to run tests in multiple threads. But we went further and made a cloud for parallel launch to be able to scale hardware resources. Simplified, his work looks like this:
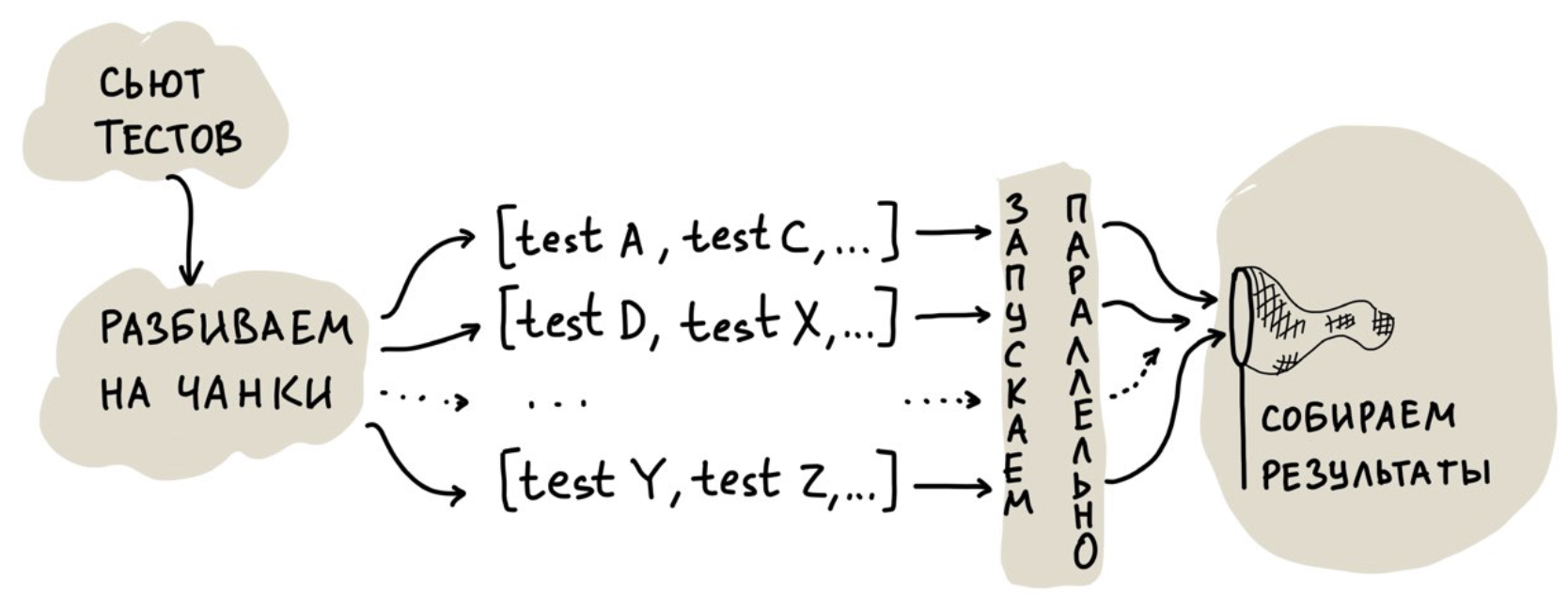
The most interesting task here is the distribution of tests between threads, that is, their breakdown into chunks.
You can divide them equally, but all tests are different, so there may be a strong bias in the execution time of a thread: all threads have already reached, and one hangs for half an hour, as it was “lucky” with very slow tests.
You can start several threads and feed them tests one at a time. In this case, the drawback is less obvious: there are overhead costs for initializing the environment, which, with a large number of tests and this approach, begin to play an important role.
What have we done? We started collecting statistics on the time taken to run each test, and then began to compose chunks in such a way that, according to the statistics, one thread would run for no longer than 30 seconds. At the same time, we pack the tests quite tightly in chunks to make them smaller.
However, our approach also has a drawback. It is associated with API tests: they are very slow and consume a lot of resources, preventing fast tests from being executed.
Therefore, we divided the cloud into two parts: in the first, only fast tests are launched, and in the second, both fast and slow can be launched. With this approach, we always have a piece of the cloud that can handle quick tests.
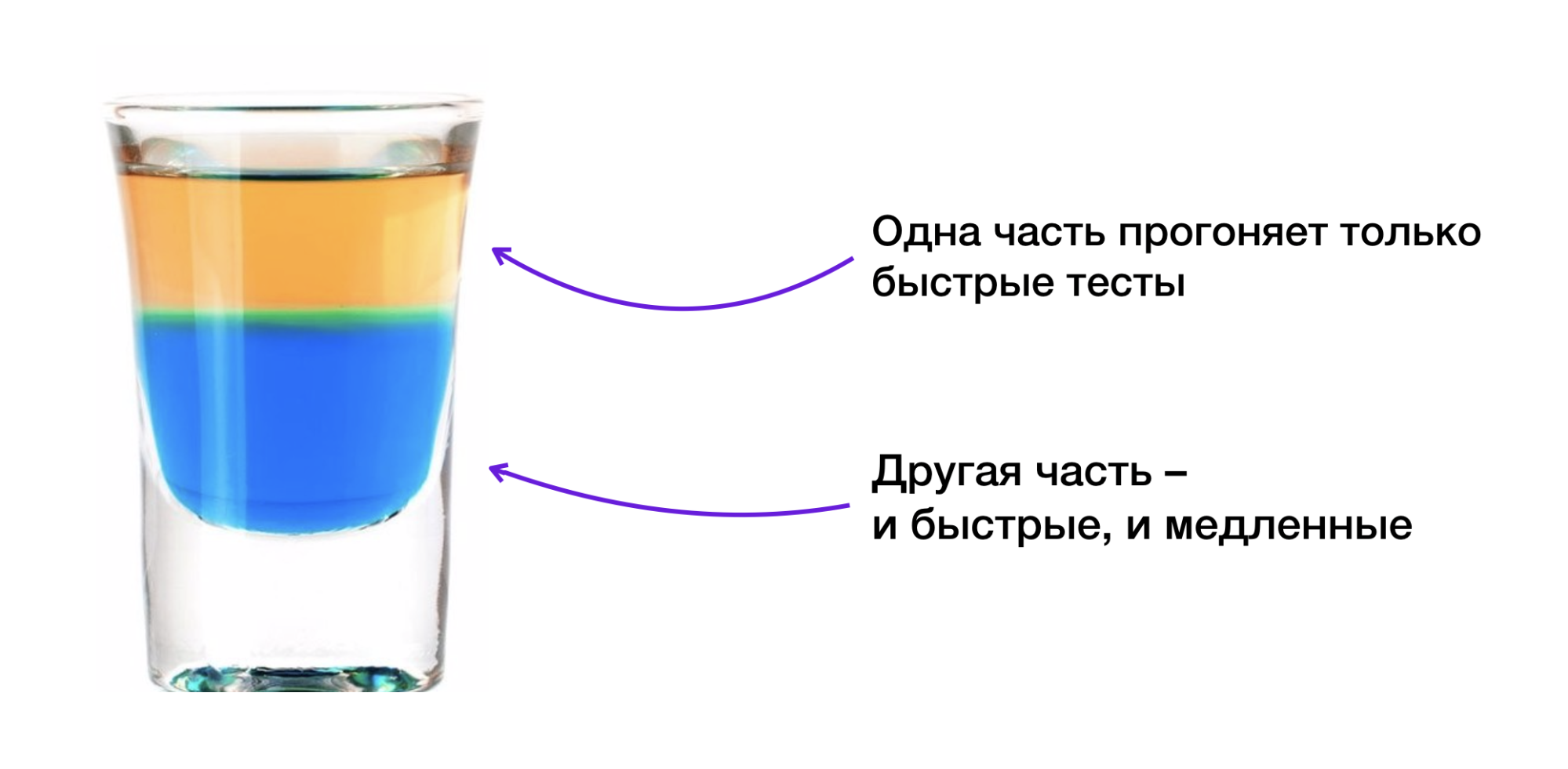
As a result, unit tests began to run in a minute, integration tests in five minutes, and API tests in 15 minutes. That is, a full run instead of 12 hours takes no more than 22 minutes.
Code coverage test run
We have a big complex monolith, and, in a good way, we need to constantly run all the tests, since a change in one place can break something in another. This is one of the main disadvantages of monolithic architecture.
At some point, we came to the conclusion that you do not need to run all the tests every time - you can make runs based on code coverage:
- Take our branch diff.
- Формируем список изменённых файлов.
- По каждому файлу получаем список тестов,
которые его покрывают. - Из этих тестов создаём набор и запускаем его в тестовом облаке.
Where to get coverage? We collect data once a day when the development environment infrastructure is idle. The number of tests run has decreased markedly, the speed of receiving feedback from them, on the contrary, has increased significantly. Profit!
An additional bonus was the ability to run tests for patches. Despite the fact that Badoo has not been a startup for a long time, we can still quickly implement changes in production, quickly pour hot fix, roll out features, and change the configuration. As a rule, the speed of rolling out patches is very important to us. The new approach gave a big increase in the feedback speed from the tests, because now we do not need to wait long for a full run.
But without the flaws, nowhere. We will release the backend twice a day, and coverage is relevant only for the first release, until the first build, after which it starts to lag behind by one build. Therefore, for builds, we run a full test suite. For us, this is a guarantee that code coverage is not far behind and that all the necessary tests have been completed. The worst that can happen is that we will catch some fallen tests at the build stage of the build, and not at the previous stages. But this happens very rarely.
However, the approach is not very effective in the case of API tests, since they generate very extensive code coverage. In the course of testing logic, they raise a bunch of different files, go to sessions, databases, and so on. If you change something in one of the affected files, all API tests will fall into the test suite and the advantages of the approach will be leveled.
Conclusion
- Вам нужны все уровни пирамиды автоматизации тестирования, чтобы быть уверенными в корректной работе функциональности. Если вы пропустили какой-то уровень, вероятно, какая-то из проблем остаётся непокрытой.
- Количество тестов ≠ качество. Выделяйте время на code review тестов и мутационное тестирование, это полезный инструмент.
- Если вы планируете работать с тестовыми пользователями, подумайте, как их изолировать от реальных. И не забудьте исключить их из статистики и аналитики.
- Не бойтесь бэкдоров. Они действительно упрощают и ускоряют написание тестов и очень сильно помогают в ручном тестировании.
- Статистика, и ещё раз статистика! Имея статистические данные по тестам, можно улучшать распараллеливание прогонов и уменьшать количество прогоняемых тестов.
I take this opportunity to remind you of the second Badoo PHP Meetup on March 16th . It will be entirely devoted to autotests for the PHP developer. Seats in the hall are over, but there will be a broadcast. I invite you to participate online! We start at 12:00, stream - on our YouTube channel .