Database Infrastructure Evolution: From Database and Application on One Server to Streaming Replication
Hello, Habr!
My name is Anton Markelov, I am an ops engineer at United Traders. We are engaged in projects in one way or another connected with investments, exchanges and other financial matters. We are not a very large company, about 30 development engineers, the scales are appropriate - a little less than a hundred servers. During the quantitative and qualitative growth of our infrastructure, the classic solution “we keep both the application and its database on the same server” ceased to suit us both in terms of reliability and speed. On the part of analysts, there was a need to create cross-database queries, the operation department was tired of messing around with backup and monitoring a large number of database servers. On top of that, storing the state on the same machine as the application itself greatly reduced the flexibility of resource planning and the resiliency of the infrastructure.
The process of transition to the current architecture was evolutionary, various solutions were tested both to provide a convenient interface for developers and analysts, and to increase the reliability and manageability of this entire economy. I want to talk about the main stages of the modernization of our DBMS, what rake we have come to and what decisions we have come to, as a result, a fault-tolerant independent environment that provides convenient ways of interaction for operation engineers, developers and analysts. I hope our experience will be useful to engineers from companies of our scale.
This article is a summary of my report at the UPTIMEDAY conference, maybe the video format will be more comfortable for someone, although the writer is a little better with my hands than a mouth speaker.
The “Snowflake Man” with KDPV was shamelessly borrowed from Maxim Dorofeev.
Growth diseases
We have a microservice architecture, services are written mainly in Java or Kotlin using the Spring framework. Next to each microservice is a PostgreSQL base, everything is covered by nginx on top to provide access. A typical microservice is an application on Spring Boot that writes its data to PostgreSQL (part of the applications at the same time and to ClickHouse), communicates with neighbors through Kafka and has some REST or GraphQL endpoints for communication with the outside world.
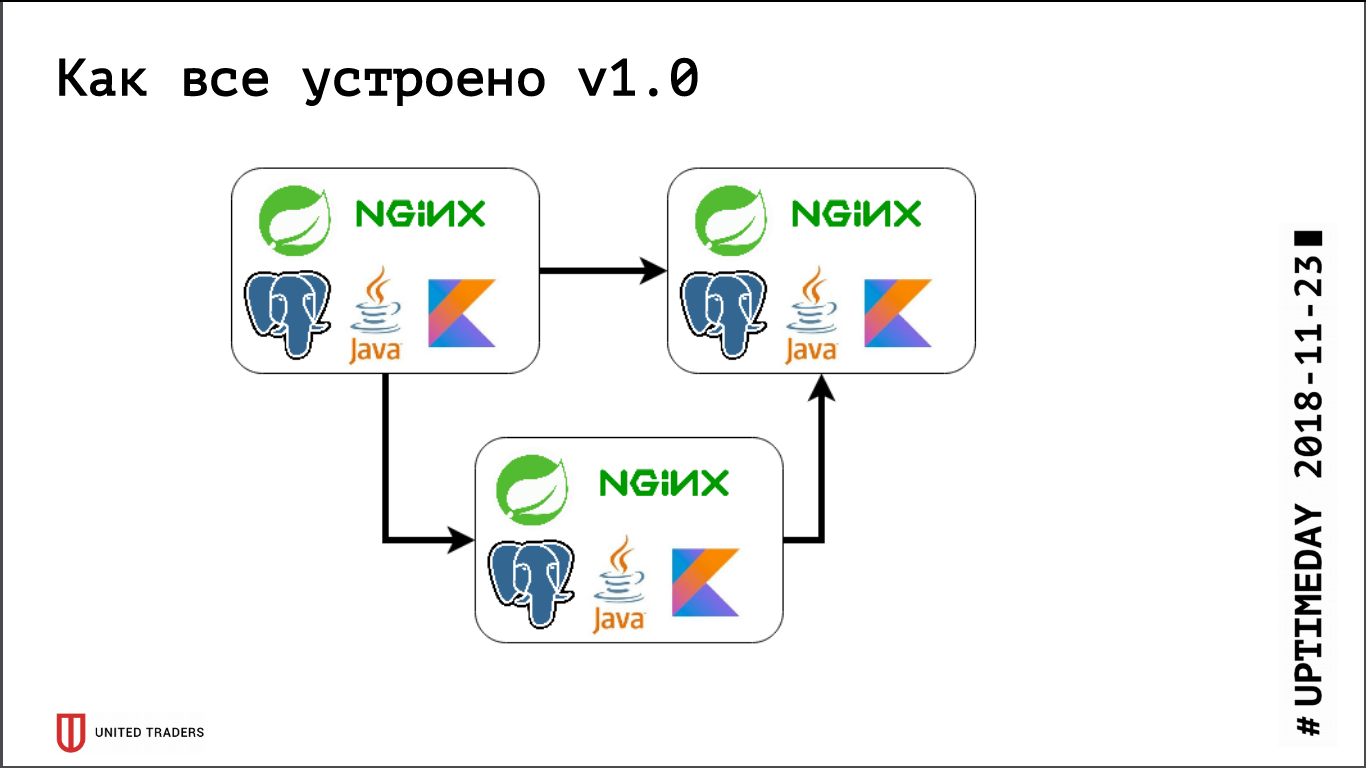
Previously, when we were very small, we just kept several servers in DigitalOcean, Kafka was not there yet, all communication was through REST. That is, we took a droplet, installed Java, PostgreSQL, nginx there, launched Zabbix there so that it monitors server resources and the availability of service endpoints. They deployed everything with the help of Ansible, we had standardized playbooks, four to five roles rolled out the entire service. As long as we had, relatively speaking, 6 servers on production and 3 on the test - you could somehow live with it.
Then the active development phase began, the number of applications grew, ten microservices turned into forty, their functionality began to change, plus integration with external systems such as CRM, client sites and the like appeared. We got the first pain. Some applications began to consume more resources, stopped getting into existing servers, we got droplets, dragged applications back and forth, picked a lot of hands. It hurt quite badly - no one likes stupid mechanical work, - I wanted to decide quickly. So we went head-on - we just took 3 large dedicated servers instead of 10 cloud droplets. This closed the problem for a while, but it became obvious that it was time to work out options for some kind of orchestration and server rebalancing. We started looking at solutions like DC / OS and Kubernetes,
Around the same time, we had an analytical department, which needed to regularly make difficult requests, prepare reports, have beautiful dashboards, and this brought us a second pain. Firstly, analysts heavily loaded the base, and secondly, they needed cross-database queries, because each microservice kept a rather narrow data slice. We tested several systems, at first we tried to solve it all through table-level replication (it was back in the ninth PostgreSQL, there was no logical replication out of the box), but the resulting crafts based on pglogical, Presto, Slony-I and Bucardo completely did not arranged. For example, pglogical did not support migration - a new version of the microservice rolled out, the structure of the database changed, Java itself changed the structure using Flyway, and on replicas in pglogical everything needs to be changed manually.
Super slave
As a result of the research, a simple and brutal solution was born called Superslave: we took a separate server, configured on it a slave for each production server on different ports, and created a virtual database that combines the databases from the slaves via postgres_fdw (foreign data wrapper). That is, all this was implemented by standard means of postgres without introducing additional entities, simply and reliably: with a single request it was possible to obtain data from several databases. We gave this virtual crossbase to analysts. An additional plus is that the read-only replica, even with an error with access rights, could not write anything there.
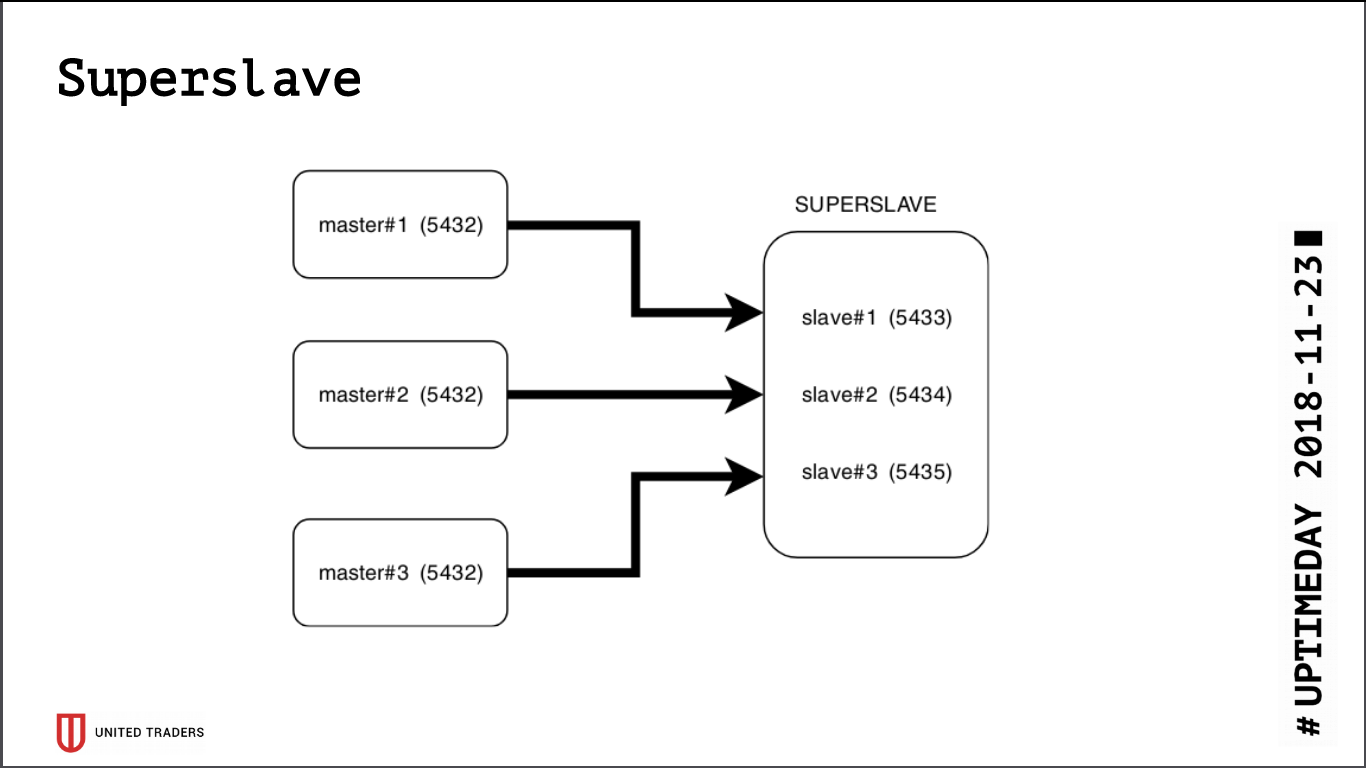
For visualization took Redash, he knows how to draw graphs, perform scheduled tasks, for example once a day, and has a weighty system of rights, so we let analysts and developers go there.

In parallel, growth continued, Kafka appeared in the infrastructure as a bus and ClickHouse for analytics storage. They are easily clustered out of the box, our super slave against their background looked like a clumsy fossil. Plus, PostgreSQL, in fact, remained the only state that needed to be dragged after the application (if it still had to be transferred to another server), and we really wanted to get a stateless application to closely engage in experiments with Kubernetes and him similar platforms.
We started looking for a solution that meets the following requirements:
- fault tolerance: when N servers fall, the cluster continues to work;
- for applications, everything should remain as before, no changes in the code;
- ease of deployment and management;
- fewer layers of abstraction over regular PostgreSQL;
- ideally, load balancing so that not all requests go to one server;
- Ideally, it is written in a familiar language.
There were not many candidates:
- standard streaming replication (repmgr, Patroni, Stolon);
- trigger-based replication (Londiste, Slony);
- middle layer query replication (pgpool-II);
- synchronous replication with multiple core servers (Bucardo).
With a large part, we already had bad experiences during the construction of the crossbase, so Patroni and Stolon remained. Patroni is written in Python, Stolon in Go, we have enough expertise in both languages. Moreover, they have similar architecture and functionality, so the choice was made for subjective reasons: Patroni was developed by Zalando, and we once tried to work with their Nakadi project (REST API for Kafka), where we encountered a severe lack of documentation.
Stolon
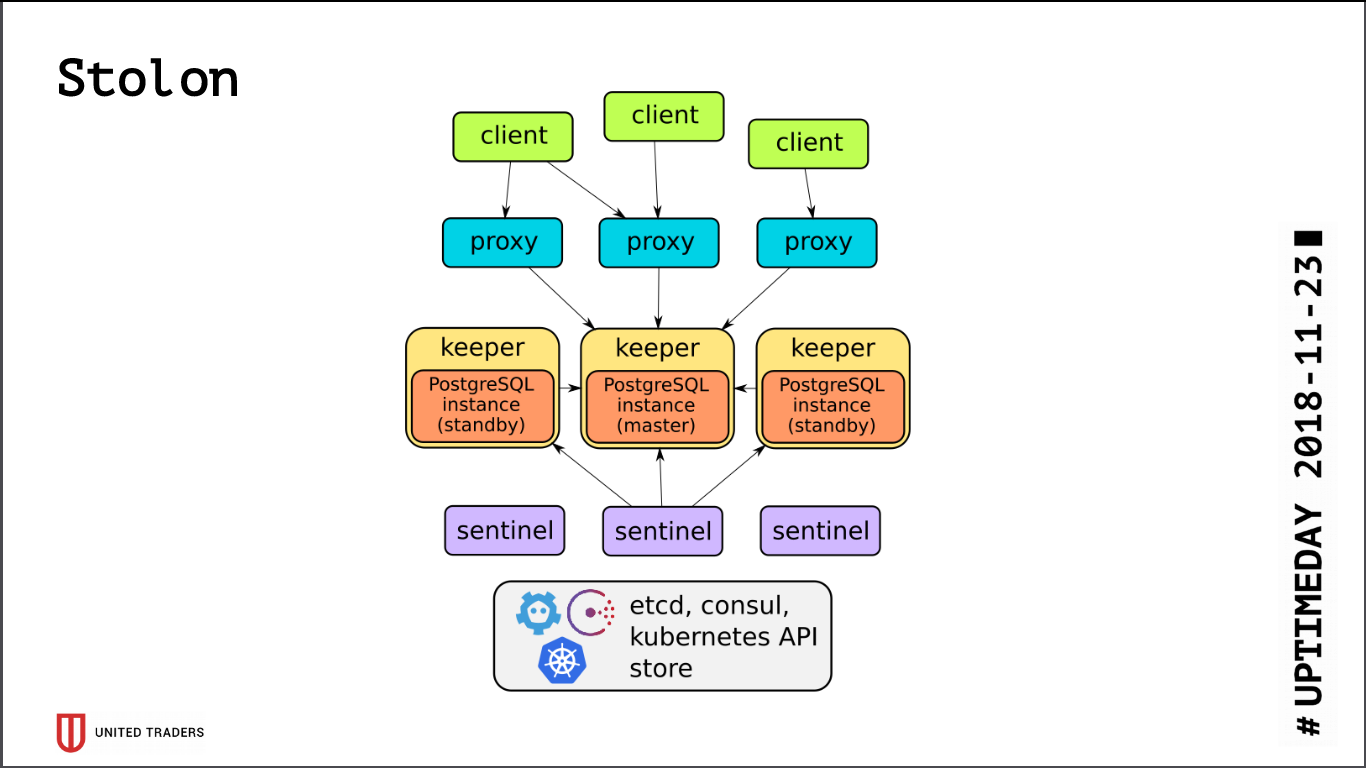
The architecture of Stolon is quite simple: there are N servers, with the help of etcd / consul a leader is selected, PostgreSQL is launched in it in the wizard mode and is replicated to other servers. Then stolon proxies go to this PostgreSQL-master, pretending to be applications with ordinary postgres, and clients go to these proxies. In the event of a master’s disappearance, re-elections take place, someone else becomes a master, the rest become stand-by. There are few layers of abstraction, PostgreSQL is installed as usual, the only caveat is that the PostgreSQL config is stored in etcd, and it is configured somewhat differently.
When testing the cluster, we caught quite a few problems:
- Stolon does not know how to work on top of ZooKeeper, only consul or etcd;
- etcd is very sensitive to IO. If you keep PostgreSQL and etcd on the same server, you definitely need fast SSDs;
- even on SSD it is necessary to configure etcd timeouts, otherwise everything will break under load - the cluster will think that the master has fallen off and constantly break connections;
- By default, max_connections on PostgreSQL is small (200), you need to increase it to your needs;
- a cluster of three etcd will survive the death of only one server, ideally you need to have a configuration, for example 5 etcd + 3 Stolon;
- out of the box, all the connections go to the master, the slaves are not accessible to the connection.
Since all connections to PostgreSQL go to the wizard, we again run into a problem with heavy analytics requests. etcd sometimes painfully reacted to the high load on the master and switched it. And switching the wizard is always breaking the connections. The request was restarted, it all started all over again. For a workaround, a Python script was written that requested stolonctl addresses of live slaves and generated a config for HAProxy, redirecting requests to them.
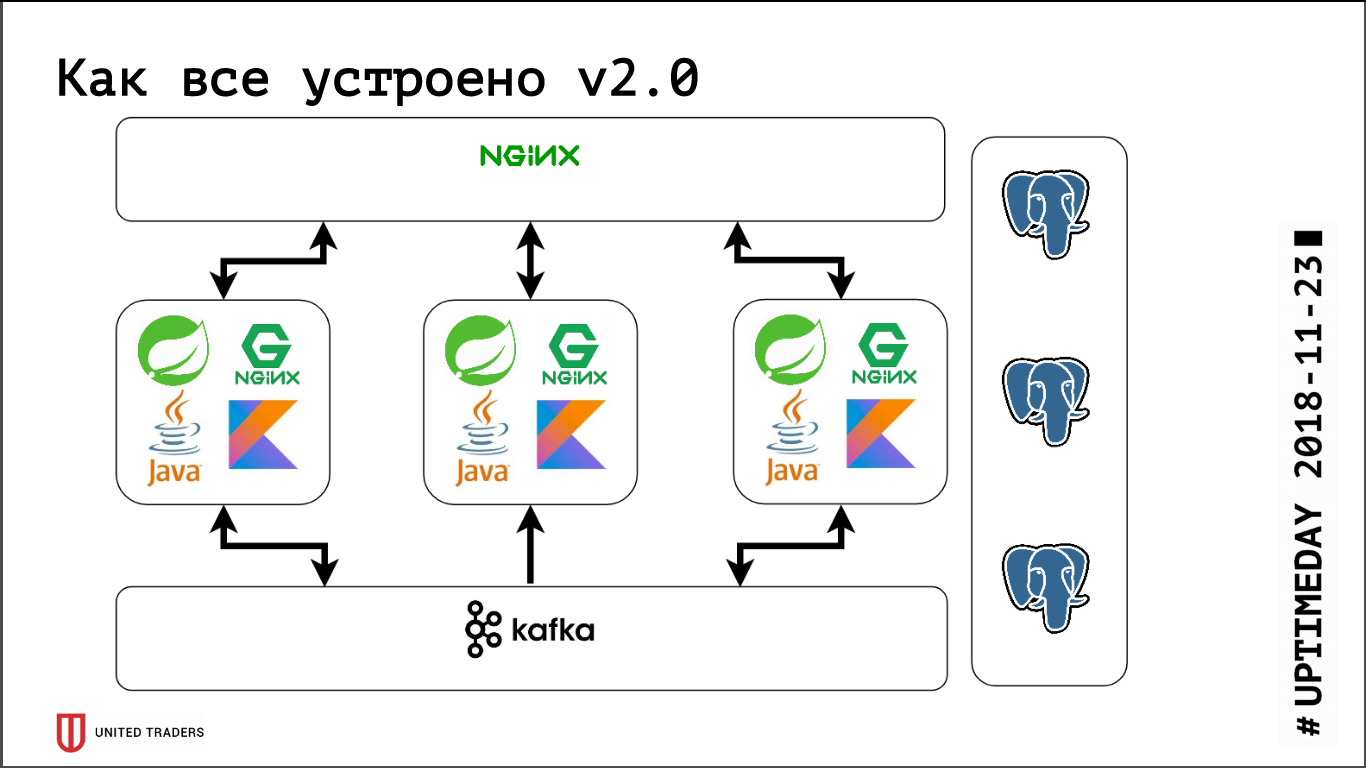
The following picture turned out: requests from applications go to the stolon-proxy port, which redirects them to the master, and requests from analysts (they are always read-only) go to the HAProxy port, which throws them to some slave.
Also, just today, in Stolon was adopted PR, which allowed sending information about Stolon instances to a third-party service discovery.
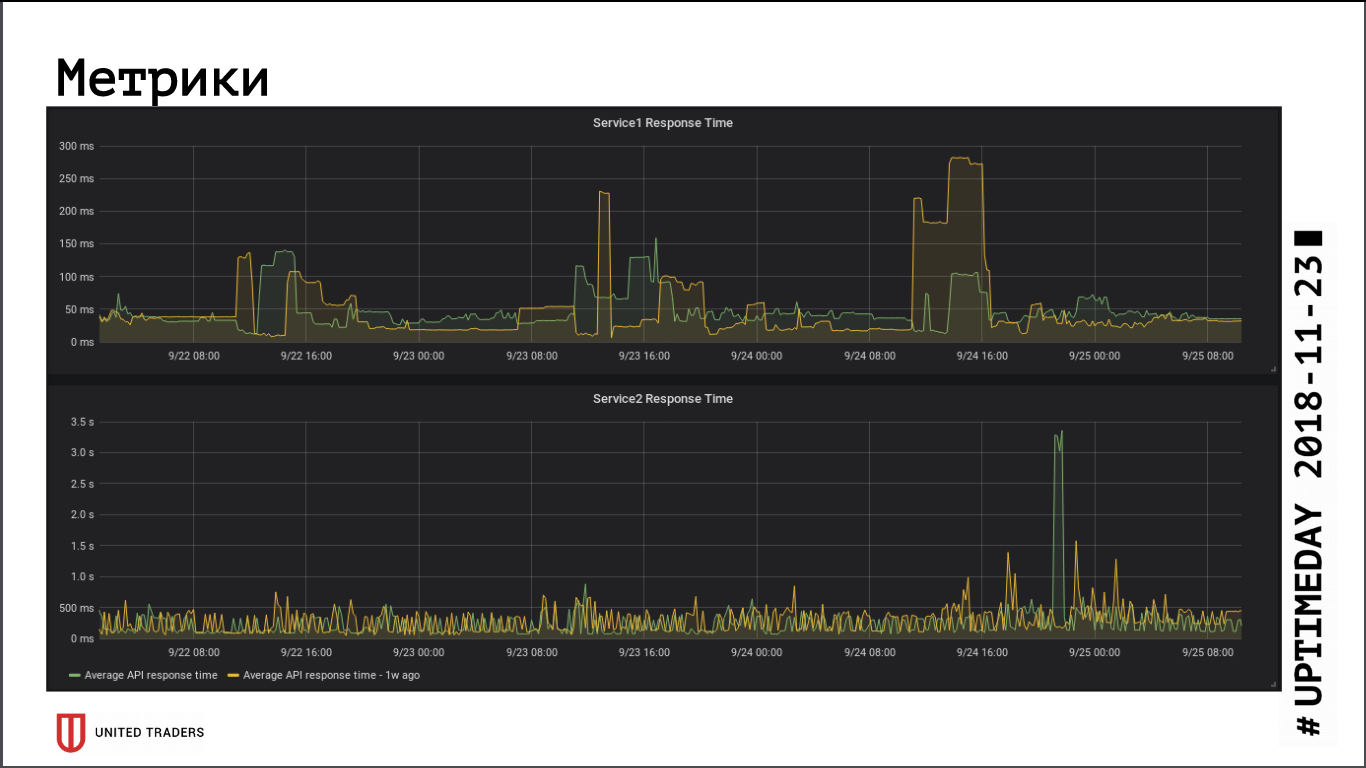
As far as judging by the application response speed metrics, the transition to a remote cluster did not have a significant impact on performance, the average response time has not changed. The resulting network latency, apparently, was compensated by the fact that the database is now on a dedicated server.
Stolon without problems survives a wizard crash (server loss, network loss, disk loss), when the server comes to life - it automatically resets the replica. The weakest point in Stolon is etcd, failures in it put the cluster. We had a typical accident: a cluster of three nodes etcd, two were cut down. Everything, the quorum was broken, etcd went into unhealthy status, the Stolon cluster does not accept any connections, including requests from stolonctl. Recovery scheme: turn etcd on the surviving server into a single-node cluster, then add the members back. Conclusion: in order to survive the death of two servers, you must have at least 5 instances etcd.
Monitoring and catching errors
With the growth of infrastructure and the complexity of microservices, I wanted to collect more information about what is happening inside the application and the Java machine. We were not able to adapt Zabbix to the new environment: it is very inconvenient in the conditions of a changing infrastructure. I had to either grind crutches through its API, or climb inside with my hands, which is even worse. Its database is poorly adapted to heavy loads, and in general it is very inconvenient to put all this into a relational database.
As a result, we chose Prometheus for monitoring. He has an actuator out of the box for Spring applications for providing metrics, for Kafka they screwed JMX Exporter, which also provides metrics in a comfortable way. Those exporters that were not found “in the box”, we wrote ourselves in Python, there are about ten of them. We visualize Grafana, collect the logs with Graylog (since he now supports Beats).
We use Sentry to collect errors . He writes everything in a structured form, draws graphs, shows what happened more often, less often. Usually, developers immediately go to Sentry immediately after the deployment, see if there is any peak, or urgently need to be rolled back. It turns out to quickly catch errors without picking in the logs.
That's all for now, if the format of the articles suits readers, we will continue to talk about our infrastructure further, there is still a lot of fun: Kafka and analytics solutions for events passing through it, CI / CD channel for Windows applications and adventures with Openshift.