How to log in NodeJS so that the boys in the yard respect
- Transfer

What infuriates you the most when you try to organize readable logs in your NodeJS application? Personally, I am extremely annoyed by the lack of any sane mature standards for creating trace IDs. In this article, we’ll talk about the options for creating a trace ID , let’s take a look at how continuation-local storage or CLS works on our fingers and call on the strength of Proxy to get it all with absolutely any logger.
Why is there any problem in NodeJS with creating a trace ID for each request?
In the old, old, old days, when mammoths still walked the earth, all-all-all servers were multi-threaded and created a new thread for a request. Within the framework of this paradigm, creating a trace ID is trivial, because there is such a thing as thread-local storage or TLS , which allows you to put in the memory some data that is available to any function in this stream. At the beginning of processing the request, you can redeem the random trace ID, put it in TLS and then read it in any service and do something with it. The trouble is that in NodeJS this will not work.
NodeJS is single-threaded (not quite, given the appearance of workers, but within the framework of the problem with trace ID, workers do not play any role), so you can forget about TLS. Here the paradigm is different - to juggle a bunch of different callbacks within the same thread, and as soon as the function wants to do something asynchronous, send this asynchronous request, and give the processor time to another function in the queue (if you are interested in how this thing, proudly called Event Loop works under the hood, I recommend reading this series of articles ). If you think about how NodeJS understands which callback to call when, you can assume that each of them must correspond to some ID. Moreover, NodeJS even has an API that provides access to these IDs. We will use it.
In ancient times, when mammoths became extinct, but people still did not know the benefits of central sewage, (NodeJS v0.11.11) we had addAsyncListener . Based on it, Forrest Norvell created the first implementation of continuation-local storage or CLS . But we won’t talk about how it worked then, since this API (I'm talking about addAsyncLustener) ordered a long life. He died already in NodeJS v0.12.
Prior to NodeJS 8, there was no official way to keep track of the queue of asynchronous events. And finally, in version 8, NodeJS developers restored justice and presented us with async_hooks API . If you want to learn more about async_hooks, I recommend that you read this article . Based on async_hooks, refactoring of the previous CLS implementation was done. The library is called cls-hooked .
CLS under the hood
In general terms, the CLS operation scheme can be represented as follows:
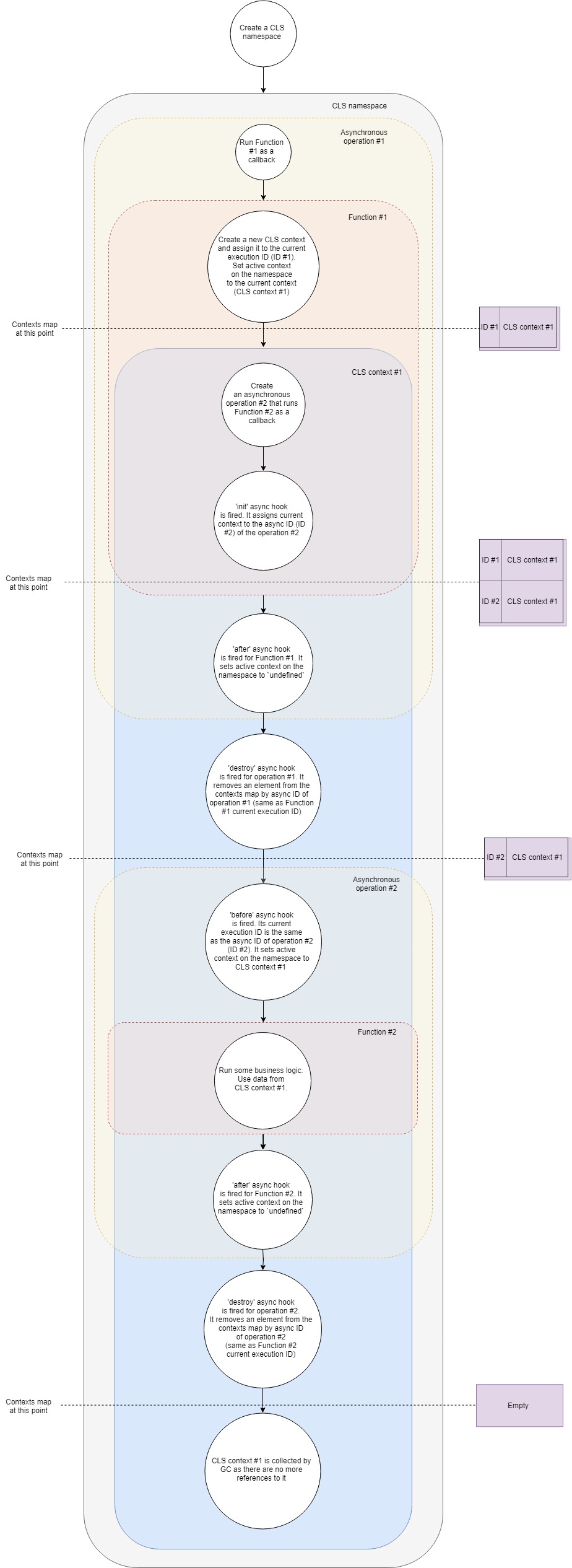
Let's analyze it a little more in detail:
- Suppose we have a typical Express web server. First, create a new CLS namespace. Once and for the entire lifetime of the application.
- Secondly, we will make middleware, which we will create our own CLS context for each request.
- When a new request arrives, this middleware (Function # 1) is called.
- In this function, create a new CLS context (as one option, you can use Namespace.run ). In Namespace.run we pass a function that will be executed in the scope of our context.
- CLS adds a freshly created context to Map with contexts with the current execution ID key .
- Each CLS namespace has a property
active. CLS assigns this property a reference to our context. - In the context scope, we make some kind of asynchronous query, say, to the database. We pass the callback to the database driver, which will be called when the request completes.
- The asynchronous init hook fires . It adds the current context to the Map with contexts by async ID (ID of the new asynchronous operation).
- Because our function no longer has any additional instructions; it completes the execution.
- An asynchronous after hook fires for her. It assigns a property
activeto namespaceundefined(in fact, not always, because we can have several nested contexts, but for the simplest case it is). - The destroy asynchronous hook fires for our first asynchronous operation. It removes the context from the Map with contexts by the async ID of this operation (it is the same as the current execution ID of the first callback).
- The query in the database ends and the second callback is called.
- Asynchronous hook before . Its current execution ID is the same as the async ID of the second operation (database query). The
activenamespace property is assigned a context found in Map with contexts by current execution ID. This is the context that we created before. - Now the second callback is executed. Some kind of business logic is working out, the devils are dancing, vodka is pouring. Inside this, we can get any value from the context by key . CLS will try to find the given key in the current context or return
undefined. - The asynchronous after hook for this callback is triggered when it is completed. It assigns a property
activeto namespaceundefined. - The destroy asynchronous hook fires for this operation. It removes the context from the Map with contexts by the async ID of this operation (it is the same as the current execution ID of the second callback).
- The garbage collector (GC) frees memory associated with the context object, because in our application there are no more links to it.
This is a simplified view of what is happening under the hood, but it covers the main phases and steps. If you have a desire to dig a little deeper, I recommend that you familiarize yourself with the sorts . There are only 500 lines of code.
Create trace ID
So, having dealt with the CLS, we’ll try to use this thing for the benefit of humanity. Let's create middleware, which for each request creates its own CLS context, creates a random trace ID and adds it to the context by key traceID. Then inside the ofigilliard of our controllers and services we get this trace ID.
For express, a similar middleware might look like this:
const cls = require('cls-hooked')
const uuidv4 = require('uuid/v4')
const clsNamespace = cls.createNamespace('app')
const clsMiddleware = (req, res, next) => {
// req и res - это event emitters. Мы хотим иметь доступ к CLS контексту внутри их коллбеков
clsNamespace.bind(req)
clsNamespace.bind(res)
const traceID = uuidv4()
clsNamespace.run(() => {
clsNamespace.set('traceID', traceID)
next()
})
}And in our controller or service, we can get this traceID in just one line of code:
const controller = (req, res, next) => {
const traceID = clsNamespace.get('traceID')
}True, without adding this trace ID to the logs, it benefits from it, like from a snow blower in the summer.
Let's make a simple winston formatter that will add trace ID automatically.
const { createLogger, format, transports } = require('winston')
const addTraceId = printf((info) => {
let message = info.message
const traceID = clsNamespace.get('taceID')
if (traceID) {
message = `[TraceID: ${traceID}]: ${message}`
}
return message
})
const logger = createLogger({
format: addTraceId,
transports: [new transports.Console()],
})And if all the loggers supported custom formatter in the form of functions (many of them have reasons not to do this), then this article probably would not have been. So how could you add trace ID to the logs of the adored pino ?
We call on Proxy in order to make friends ANY logger and CLS
A few words about Proxy itself: this is such a thing that wraps our original object and allows us to redefine its behavior in certain situations. In a strictly defined limited list of situations (in science they are called traps). You can find the full list here , we are only interested in trap get . It gives us the opportunity to override the return value when accessing the property of the object, i.e. if we take the object const a = { prop: 1 }and wrap it in Proxy, then with the help of trap getwe can return everything that we want, when accessing a.prop.
In the case of the pinofollowing thought: we create a random trace ID for each request, create a pino child instance , into which we pass this trace ID, and put this child instance in the CLS. Then we wrap our source logger in Proxy, which will use this same child instance for logging, if there is an active context and there is a child logger in it, or use the original logger.
For such a case, the proxy will look like this:
const pino = require('pino')
const logger = pino()
const loggerCls = newProxy(logger, {
get(target, property, receiver) {
// Если логер в CLS не найдем, использум оригинал
target = clsNamespace.get('loggerCls') || target
returnReflect.get(target, property, receiver)
},
})Our middleware will look like this:
const cls = require('cls-hooked')
const uuidv4 = require('uuid/v4')
const clsMiddleware = (req, res, next) => {
// req и res - это event emitters. Мы хотим иметь доступ к CLS контексту внутри их коллбеков
clsNamespace.bind(req)
clsNamespace.bind(res)
const traceID = uuidv4()
const loggerWithTraceId = logger.child({ traceID })
clsNamespace.run(() => {
clsNamespace.set('loggerCls', loggerWithTraceId)
next()
})
}And we can use the logger like this:
const controller = (req, res, next) => {
loggerCls.info('Long live rocknroll!')
// Выводит// {"level":30,"time":1551385666046,"msg":"Long live rocknroll!","pid":25,"hostname":"eb6a6c70f5c4","traceID":"9ba393f0-ec8c-4396-8092-b7e4b6f375b5","v":1}
}cls-proxify
Based on the above idea, a small cls-proxify library was created . She works out of the box with express , koa and fastify . In addition to creating trap for get, it creates other traps to give the developer more freedom. Because of this, we can use Proxy to wrap functions, classes, and more. There is a live demo on how to integrate pino and fastify, pino and express .
I hope you did not waste your time, and the article was at least a little useful to you. Please kick and criticize. We will learn to code better together.