Fortune telling on neural networks: whether the author himself noted in the comments on the post

I’ll share a story about a small project: how to find the author’s answers in the comments without knowing who the author of the post is.
I started my project with minimal knowledge on machine learning and I think there will be nothing new for specialists here. This material is, in a sense, a compilation of different articles, in it I will tell how it approached the task, in the code you can find useful little things and tricks with natural language processing.
My initial data was as follows: a database containing 2.5M media materials and 39.5M comments on them. For 1M posts, one way or another, the author of the material was known (this information was either present in the database, or was obtained by analyzing data on indirect grounds). On this basis, a dataset was created from 215K records marked up.
Initially, I used a heuristic-based approach emitted by natural intelligence and translated into sql queries with full-text search or regular expressions. The simplest examples of text to parse: “thank you for the comment” or “thank you for the good ratings” this is the author in 99.99% of cases, and “thank you for the work” or “Thank you!” Send material by mail. Thanks!" - ordinary review. With such an approach, only obvious coincidences could be filtered out, except for cases of banal typos or when the author is in dialogue with commentators. Therefore, it was decided to use neural networks, this idea came not without the help of a friend.
A typical sequence of comments, which of them is the author?
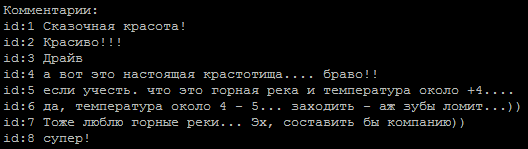
Answer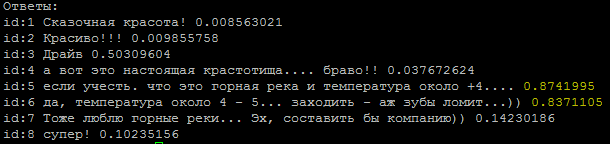
The method for determining the tonality of the text was taken as the basis. The task is simple for us in two classes: the author and not the author. To train models, I used a service from Google that provides virtual machines with a GPU and a Jupiter notebook interface.
Examples of networks found on the Internet:
embed_dim = 128
model = Sequential()
model.add(Embedding(max_fatures, embed_dim,input_length = X_train.shape[1]))
model.add(SpatialDropout1D(0.2))
model.add(LSTM(196, dropout=0.5, recurrent_dropout=0.2))
model.add(Dense(1,activation='softmax'))
model.compile(loss = 'binary_crossentropy', optimizer='adam',metrics = ['accuracy'])on the lines cleared of html tags and special characters, they gave about 65-74% percent of accuracy, which did not differ much from tossing a coin.
An interesting point, alignment of input sequences through
pad_sequences(x_train, maxlen=max_len, padding=’pre’)yielded a significant difference in the results. In my case, the best result was with padding = 'post'. The next step was the use of lemmatization, which immediately gave an increase in accuracy of up to 80% and this could be worked on further. Now the main problem is the correct clearing of the text. For example, typos in the word "thank you" were converted (typos were selected by frequency of use) into such a regular expression (such expressions have accumulated a half to two dozen).
re16 = re.compile(ur"(?:\b:(?:1спасибо|cп(?:асибо|осибо)|м(?:ерси|уррси)|п(?:ас(?:асибо|и(?:б(?:(?:ки|о(?:чки)?|а))?|п(?:ки)?))|осибо)|с(?:а(?:п(?:асибо|сибо)|сибо)|басибо|енкс|ибо|п(?:а(?:асибо|всибо|и(?:бо|сбо)|с(?:бо|и(?:б(?:(?:бо|ки|о(?:(?:за|нька|ч(?:к[ио]|ьки)|[ко]))?|[арсі]))?|ки|ьо|1)|сибо|тбо)|чибо)|всибо|исибо|осиб[ао]|п(?:асибо|сибо)|с(?:(?:а(?:иб[ао]|сибо)|бо?|и(?:б(?:(?:ки|о(?:всм)?))?|п)|с(?:ибо|с)))?)|расибо|спасибо)|тхан(?:кс|x))\b)", re.UNICODE)Here, I would like to express special thanks to overly polite people who consider it necessary to add this word to each of their sentences.
Reducing the proportion of typos was necessary, because at the exit from the lemmatizer they give strange words and we lose useful information.
But there is a silver lining, we’ve got tired of dealing with typos, dealing with complex text cleaning, I used the vector representation of words - word2vec. The method allowed to translate all typos, typos and synonyms into closely spaced vectors.

Words and their relationships in vector space.
The cleaning rules were significantly simplified (aha, storyteller), all messages, user names, were divided into sentences and uploaded to a file. An important point: due to the brevity of our commentators, in order to build high-quality vectors, additional contextual information is needed, for example, from the forum and Wikipedia. Three models were trained on the resulting file: classic word2vec, Glove and FastText. After many experiments, he finally settled on FastText, as the most qualitatively distinguishing word clusters in my case.
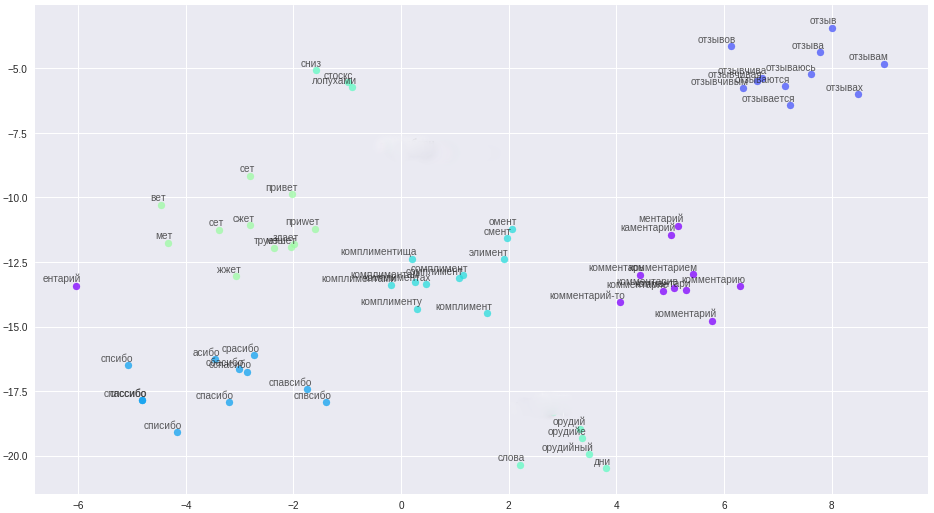
All these changes brought a stable 84-85 percent accuracy.
Model Examples
def model_conv_core(model_input, embd_size = 128):
num_filters = 128
X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input)
X = Conv1D(num_filters, 3, activation='relu', padding='same')(X)
X = Dropout(0.3)(X)
X = MaxPooling1D(2)(X)
X = Conv1D(num_filters, 5, activation='relu', padding='same')(X)
return X
def model_conv1d(model_input, embd_size = 128, num_filters = 64, kernel_size=3):
X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input)
X = Conv1D(num_filters, kernel_size, padding='same', activation='relu', strides=1)(X)
# X = Dropout(0.1)(X)
X = MaxPooling1D(pool_size=2)(X)
X = LSTM(256, kernel_regularizer=regularizers.l2(0.004))(X)
X = Dropout(0.3)(X)
X = Dense(128, kernel_regularizer=regularizers.l2(0.0004))(X)
X = LeakyReLU()(X)
X = BatchNormalization()(X)
X = Dense(1, activation="sigmoid")(X)
model = Model(model_input, X, name='w2v_conv1d')
return model
def model_gru(model_input, embd_size = 128):
X = model_conv_core(model_input, embd_size)
X = MaxPooling1D(2)(X)
X = Dropout(0.2)(X)
X = GRU(256, activation='relu', return_sequences=True, kernel_regularizer=regularizers.l2(0.004))(X)
X = Dropout(0.5)(X)
X = GRU(128, activation='relu', kernel_regularizer=regularizers.l2(0.0004))(X)
X = Dropout(0.5)(X)
X = BatchNormalization()(X)
X = Dense(1, activation="sigmoid")(X)
model = Model(model_input, X, name='w2v_gru')
return model
def model_conv2d(model_input, embd_size = 128):
from keras.layers import MaxPool2D, Conv2D, Reshape
num_filters = 256
filter_sizes = [3, 5, 7]
X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input)
reshape = Reshape((maxSequenceLength, embd_size, 1))(X)
conv_0 = Conv2D(num_filters, kernel_size=(filter_sizes[0], embd_size), padding='valid', kernel_initializer='normal', activation='relu')(reshape)
conv_1 = Conv2D(num_filters, kernel_size=(filter_sizes[1], embd_size), padding='valid', kernel_initializer='normal', activation='relu')(reshape)
conv_2 = Conv2D(num_filters, kernel_size=(filter_sizes[2], embd_size), padding='valid', kernel_initializer='normal', activation='relu')(reshape)
maxpool_0 = MaxPool2D(pool_size=(maxSequenceLength - filter_sizes[0] + 1, 1), strides=(1,1), padding='valid')(conv_0)
maxpool_1 = MaxPool2D(pool_size=(maxSequenceLength - filter_sizes[1] + 1, 1), strides=(1,1), padding='valid')(conv_1)
maxpool_2 = MaxPool2D(pool_size=(maxSequenceLength - filter_sizes[2] + 1, 1), strides=(1,1), padding='valid')(conv_2)
X = concatenate([maxpool_0, maxpool_1, maxpool_2], axis=1)
X = Dropout(0.2)(X)
X = Flatten()(X)
X = Dense(int(embd_size / 2.0), activation='relu', kernel_regularizer=regularizers.l2(0.004))(X)
X = Dropout(0.5)(X)
X = BatchNormalization()(X)
X = Dense(1, activation="sigmoid")(X)
model = Model(model_input, X, name='w2v_conv2d')
return model
and 6 more models in code . Some of the models are taken from the network, some are invented independently.
It was noticed that different comments stood out on different models, this prompted the idea to use ensembles of models. First, I assembled the ensemble manually, choosing the best pairs of models, then I made a generator. In order to optimize the exhaustive search, I took the gray code as a basis.
def gray_code(n):
def gray_code_recurse (g,n):
k = len(g)
if n <= 0:
return
else:
for i in range (k-1, -1, -1):
char='1' + g[i]
g.append(char)
for i in range (k-1, -1, -1):
g[i]='0' + g[i]
gray_code_recurse (g, n-1)
g = ['0','1']
gray_code_recurse(g, n-1)
return g
def gen_list(m):
out = []
g = gray_code(len(m))
for i in range (len(g)):
mask_str = g[i]
idx = 0
v = []
for c in list(mask_str):
if c == '1':
v.append(m[idx])
idx += 1
if len(v) > 1:
out.append(v)
return outWith the ensemble “life has become more fun” and the current percentage of model accuracy is kept at 86-87%, which is associated mainly with poor-quality classification of some authors in the dataset.

The problems I met:
- Unbalanced dataset. The number of comments from the authors was significantly less than other commentators.
- Classes in the sample go in strict order. The bottom line is that the beginning, middle and end differ significantly in the quality of classification. This is clearly visible in the learning process on the schedule of the f1-measure.
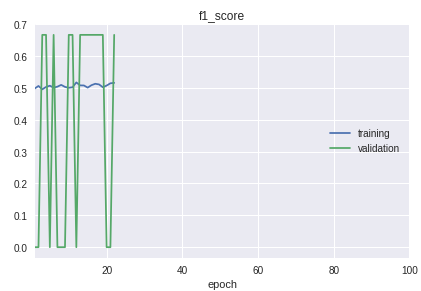
For the solution, a bicycle was made for separation into training and validation samples. Although in practice in most cases the train_test_split procedure from the sklearn library is enough.
Graph of the current working model:

As a result, I got a model with a confident definition of authors from short comments. Further improvement will be associated with cleaning and transferring the results of the classification of real data into the training dataset.
All code with additional explanations is in the repository .
As a postscript: if you need to classify large amounts of text, take a look at the VDCNN “Very Deep Convolutional Neural Network” model ( implementation on keras), this is an analogue of ResNet for texts.
Materials used:
• Overview of machine learning courses
• Analysis of tonality using convolutions
• Convolutional networks in NLP
• Metrics in machine learning
https://ld86.github.io/ml-slides/unbalanced.html
• Look inside the model