How to teach a machine to understand invoices and extract data from them
 Hello, Habr! My name is Stanislav Semenov, I am working on technologies for extracting data from documents in R&D ABBYY. In this article I will talk about the basic approaches to the processing of semi-structured documents (invoices, cash receipts, etc.) that we used recently and which we are using right now. And we’ll talk about how machine learning methods are applicable to solve this problem.
Hello, Habr! My name is Stanislav Semenov, I am working on technologies for extracting data from documents in R&D ABBYY. In this article I will talk about the basic approaches to the processing of semi-structured documents (invoices, cash receipts, etc.) that we used recently and which we are using right now. And we’ll talk about how machine learning methods are applicable to solve this problem. We will consider invoices as documents, because in the world they are very widespread and most in demand in terms of data extraction. By the way, automatic processing of invoices is one of the most popular scenarios among our foreign customers. For example, with ABBYY FlexiCapture, American PepsiCo Imaging Technology reducedinvoice processing time and the number of errors due to manual entry, and the European Sportina retailer began to enter data from accounts into accounting systems 2 times faster .
Invoices are documents that are used in international commercial practice and are of great importance for business. Something similar to an invoice in Russia is, for example, a waybill. Data from such documents fall into various accounting systems, and errors there, to put it mildly, are not welcome.
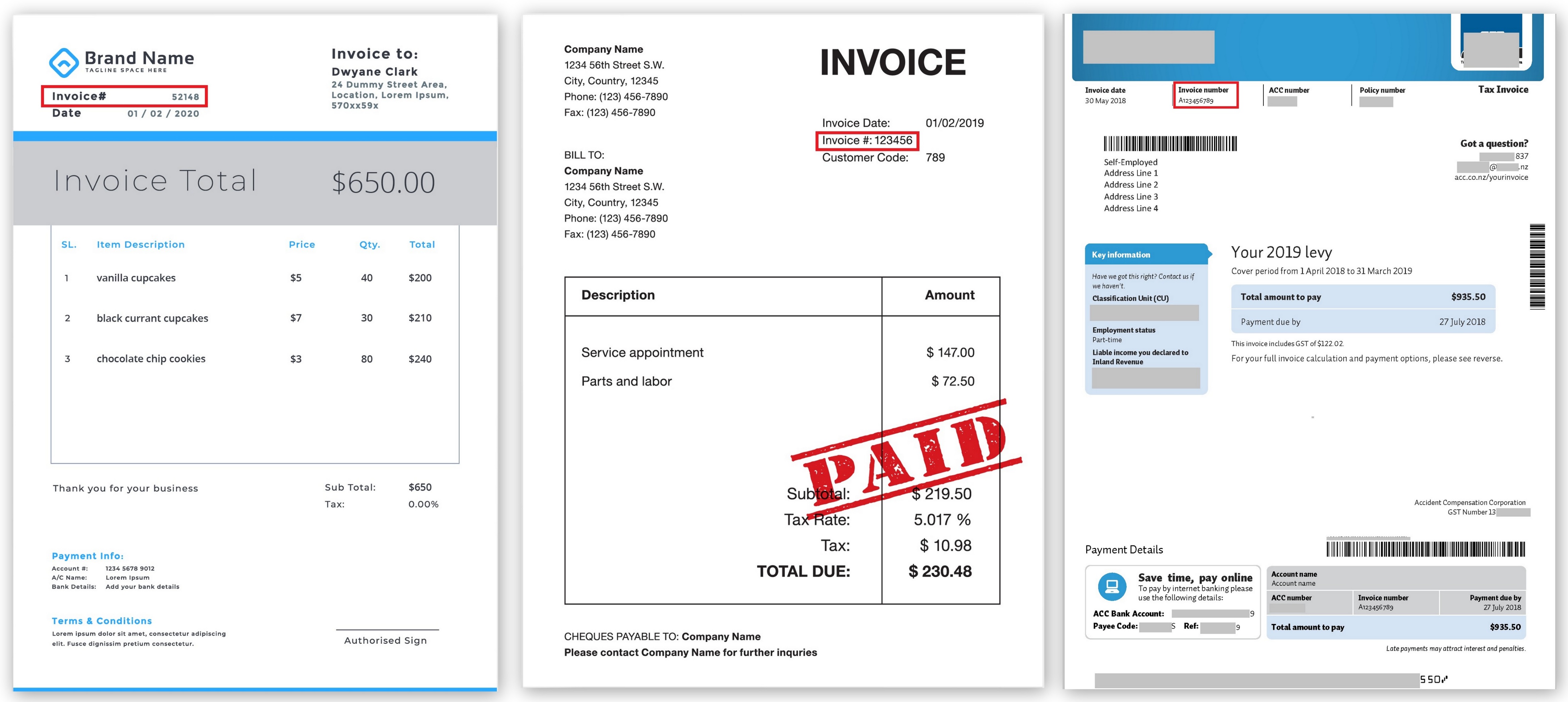
An ordinary invoice can be considered quite structured; it contains two main classes of objects:
- various fields from the header (document number, date, sender, recipient, total, etc.),
- tabular data is a list of goods and services (quantity, price, description, etc.).
This is what it looks like:

Millions of man-hours are spent annually on processing invoices. And it is very expensive. According to various estimates, for a company the processing of one paper invoice costs from $ 10 to $ 40, where a significant part of these costs is manual labor for entering and reconciling data.
There are companies that process millions of invoices per month. To do this, they contain a whole staff of hundreds, and sometimes thousands of people. It is easy to estimate that an increase in recognition accuracy or data extraction efficiency of only 1% can reduce the costs of large companies by hundreds of thousands and even millions of dollars annually.
On the other hand, there is a catastrophic amount of documents. In 2017, Billentis ratedthe total number of invoices / invoices generated per year in the world is 400 billion. Of these, only about 10% were electronic, and the rest require fully manual entry or intensive human participation. If you print 400 billion documents on standard A4 paper, then it’s thousands of paper trucks per day, or a stack of paper about a human height every second!
A few words about how technology developed

Many companies are developing specialized software that can recognize documents and extract data from them. But the quality of invoice processing is still not perfect. “What is the problem?” You ask.
It's all about a huge variety of invoices. There are no standards for invoices, and each company is free to create its own version of the document: the type, structure and location of the fields.
Find fields by keywords
The first attempts to extract data came down to finding special key words among all recognized words, such as, for example, Invoice Number or Total, and then in the small neighborhood of these words, for example, to the right or bottom, to find the meanings themselves.
The location of the Invoice Number in different invoices (clickable): The whole logic was programmed, that there are such and such fields, they are in such and such a place in the document, around them there are other fields at some distances. And this somehow worked until some other company appeared, which began to send its documents in a completely different form. Or the previous company suddenly changed the format, and everything stopped working.
Patterns
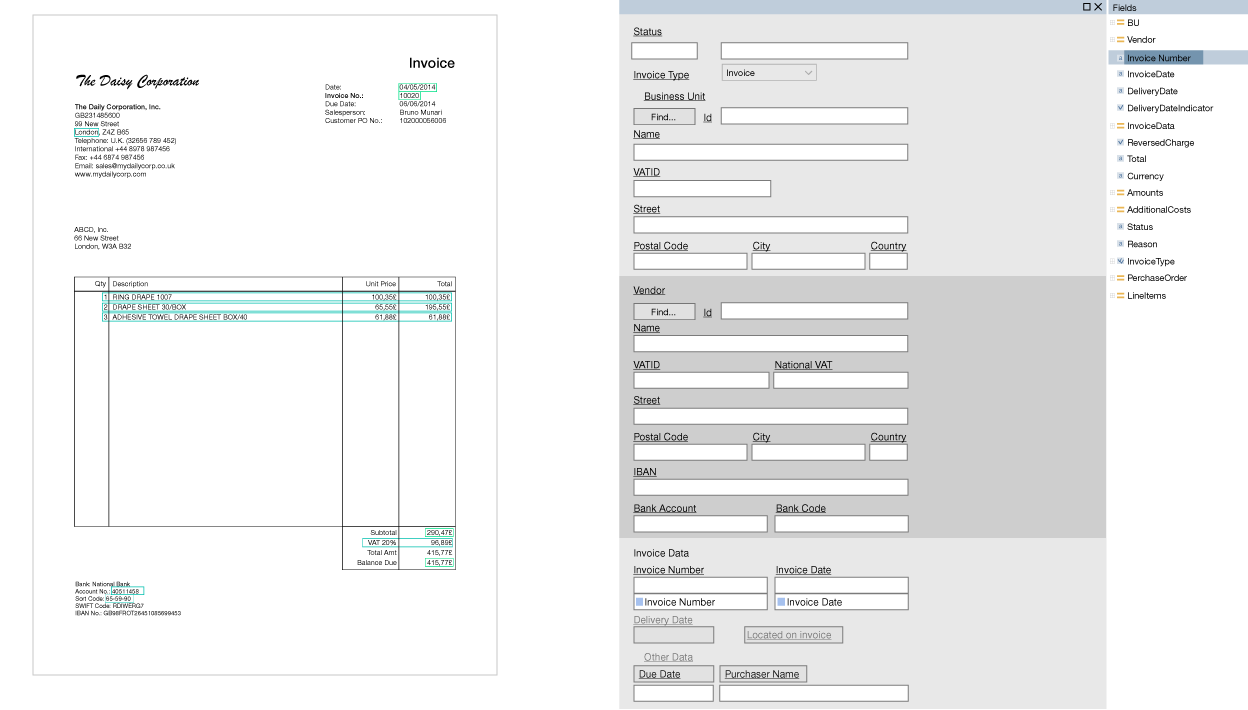
Fighting this, each time reprogramming something, was irrational. Therefore, a new paradigm came to the rescue - the use of templates. A template is a set of fields that need to be found in a document, and a set of rules on how to find these fields. The main advantage here is that templates are created visually. For example, we want to search for the Invoice Number and Total, select these fields and configure the parameters that such and such a field comes immediately after such and such a keyword, it is located at the top of the document and contains numbers and punctuation marks.
Specialized tools were developed, the so-called template editors, where already advanced users without the help of programmers could quickly manually set some kind of logic. As soon as a document of a new form arrived, a template was created for it and everything began to work more or less.
Sample template (clickable): But to make one template is not enough, you need to make hundreds or even thousands of them. And therefore, setting up a product for each client can sometimes take a lot of time. It is impossible to create “universal” templates in advance, which will cover the whole variety of invoices.
Using templates, you can significantly improve the quality of table retrieval. But often complex table structures are found, with non-standard data representation, several levels of nesting, and templates in these cases do not always do well. So again, you have to write some scripts that contain many manually selected parameters, conditions, exceptions, etc.
Using Machine Learning
Technology today does not stand still, and with the development of machine learning, it became possible to transfer the task of extracting data from documents to neural networks.
Today, there are several basic approaches that are used in practice:
- The first approach is to work directly with the input image of the document. That is, an image (picture) or fragment is fed to the network input, and the network learns to find small areas where the necessary fields are located, and then the text in these areas is recognized using the classic OCR (Optical Character Recognition) technologies. This is an end-to-end solution that can be quickly implemented. You can take a ready-made network for searching for objects in images, for example, YOLO or Faster R-CNN and train it in marked-up pictures of documents.
The disadvantage of this approach is not the best quality of the extracted data and the difficulty of extracting tables. In fact, this approach is in some way similar to the task of finding the right words in the image (word spotting), a fundamental problem from the field of computer vision, only here we are looking for not the words, but the necessary fields. - The second approach is to process the text extracted from the document. This can be either text from a PDF, or a full-page OCR document. It uses Natural Language Processing (NLP) technology . Lines are assembled from individual words, various fragments of text, paragraphs or columns are formed from lines, and in them the network is already learning to distinguish various named entities NER (Named-Entity Recognition).
Various ways of forming text fragments are possible. You can combine the first and second approaches, train one network to find large blocks with certain information in the images, for example, data about the sender or data about the recipient, which immediately contains the name, address, details, etc., and then transfer the text of each such block to the second NER network.
The quality of this approach may turn out to be higher than just in the first approach, but it is rather difficult to build an effective model. Today, there are quite advanced models, for example, LSTM-CRF for NER, which can tag words in the text and define entities. - The third approach is to build a semantic representation of the document without reference to the type of document, i.e. when we don’t know what the document is in front of us, but we try to understand it during the processing. A set of document words with their various attributes (for example, does the word contain only letters or is it a number), the geometrical arrangement of words (coordinates, indents) and with various delimiters and connections identified during image analysis, is fed to the network input and the output is obtained for Each word has its own specific set of characteristics. Based on the obtained characteristics, various sets of hypotheses of possible fields or tables are formed, which are further sorted and evaluated by an additional classifier. Then the most reliable hypothesis of the structure and content of the document is selected.
This is already technically the most difficult solution, but you can solve the problem of extracting data from documents in a general way.
How do we use neural networks
We at ABBYY not only closely monitor the achievements of science and technology, but also create our own advanced technologies and implement them in various products.
The figure below shows the general architecture of our solution using neural networks.
The image is clickable. The entire document page is fed to the network input. Using convolutional layers (CNN), various geometric features are formed, for example, the relative position of words relative to each other. Further, these signs are combined with the vector representation of recognized words (word embeddings) and served on recurrent (LSTM) and fully connected layers. There are several different output layers (multi-task learning), each output solves its own problem:
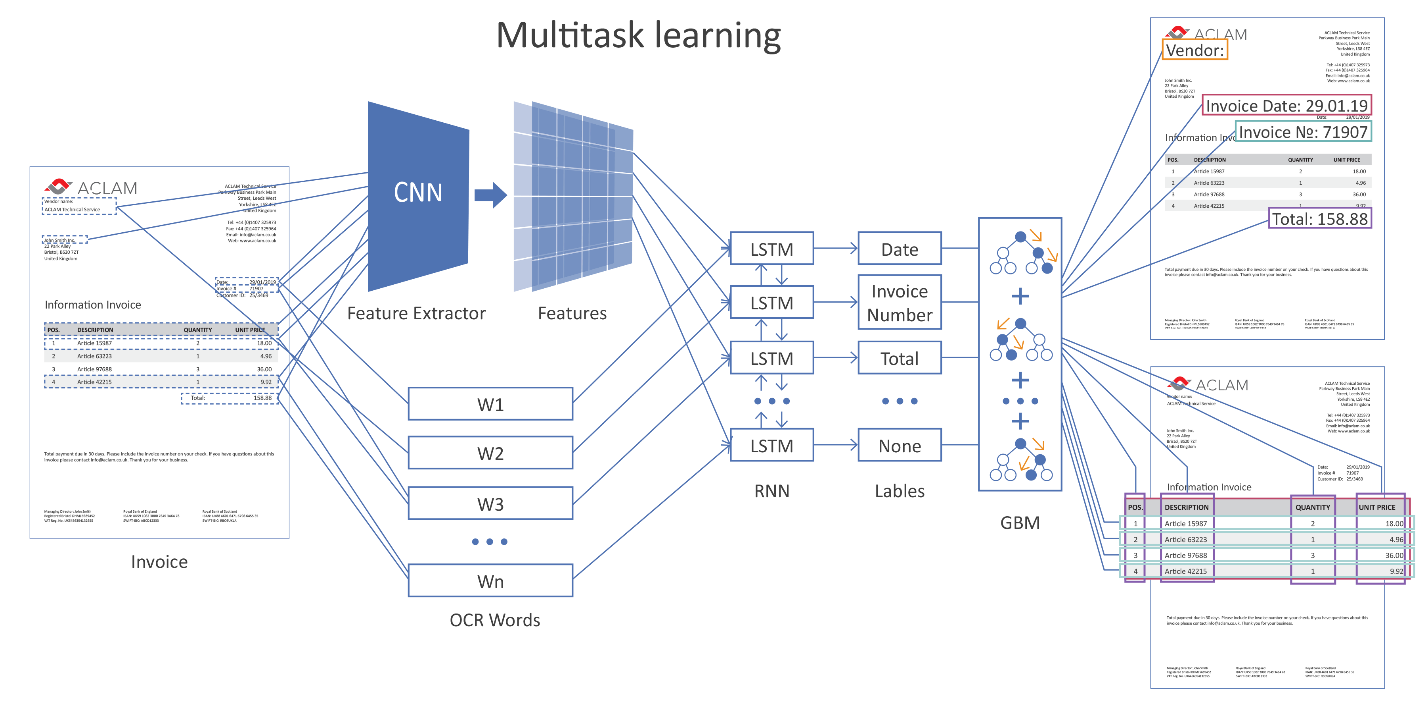
- determination of the type of field to which the word can correspond,
- hypotheses of table boundaries,
- hypotheses of table rows, column boundaries, etc.
If the document is multi-page, then the network makes its prediction for each individual page, then the results are combined.
Next, hypotheses are formed of the possible arrangement of fields and tables, with the help of a separately trained regression function, they are evaluated, and the most confident hypothesis wins.
In order to increase the accuracy of data extraction, in addition to separating documents by type (check, invoice, contract, etc.), additional clustering occurs inside its type according to additional characteristics.
For example, for invoices it can be a vendor or just an appearance (according to the degree of similarity of the location of the fields). And then, depending on a particular group (cluster), specific algorithm settings are applied. Technically, having examples of correctly marked invoices for different groups, it is possible on the user side to retrain the mechanisms for evaluating and choosing the right hypotheses.
To configure all kinds of parameters of our algorithms and neural networks, we use the differential evolution method, which has proven itself very well in practice.
Our Machine Learning Results

- The developed method for extracting data from structured documents using machine learning in many cases shows better results than programmed solutions based on heuristics. The quality gain in various metrics ranges from several units to tens of percent on various extractable entities.
- There is an undeniable advantage over the classical approach - the ability to retrain the network on new data. In the case of a variety of forms of documents, now this is not a problem, but rather a need. The more of them, the better; the stronger the network’s ability to generalize and the higher the quality.
- There was an opportunity to release the so-called solution “out of the box”, when the user simply installs the product (in fact, a trained network), and everything immediately starts working with an acceptable result. There is no need to program anything, long and painfully customize the templates, select all sorts of parameters.
An important detail that I would also like to mention is data. No machine learning can happen without quality data. Machine learning gives better results than knowledge engineering, only if there is a sufficient amount of tagged data. In the case of invoices, these are tens of thousands of manually labeled documents, and this figure is constantly growing.
In addition, we use advanced data augmentation mechanisms, change the names of organizations, addresses, lists of goods and types of services in tables, dates, various quantitative characteristics, such as price, quantity, cost, etc. We also change the sequence of various entities in documents, which allows us to ultimately generate millions of completely different documents for training.
Instead of a conclusion
In conclusion, we can say that programming has, of course, not disappeared, but is gradually changing its role. With each new day, machine learning begins to cope with the tasks assigned to it better and better in a variety of industries, crowding out classical approaches. The undeniable advantage of machine learning in efficiency: dozens of man-years of intellectual work now cost dozens of machine-hours of learning. Therefore, in the near future we see even greater development and applicability of networks in all of our developments. And if you are interested, we are always open to suggestions and cooperation .