Migration from Mongo to Postgres: The Guardian newspaper experience
- Transfer

The Guardian is one of the largest British newspapers, it was founded in 1821. For nearly 200 years of existence, the archive has accumulated a fair amount. Fortunately, not all of it is stored on the site - in just some past couple of decades. In the database, which the British themselves called the "source of truth" for all online content, about 2.3 million items. And at one point, they realized the need to migrate from Mongo to Postgres SQL - after one hot July day in 2015, the emergency transfer procedures were put to a severe test. Migration took almost 3 years! ..
We have translated the article, which describes how the migration process took place and what difficulties administrators faced. The process is long, but the summary is simple: when embarking on a big task, accept that mistakes will be necessary. But in the end, 3 years later, the British colleagues managed to celebrate the end of the migration. And sleep.
Part one: the beginning
In Guardian, much of the content, including articles, blogs, photo galleries and videos, is produced inside our own CMS - Composer. Until recently, Composer interacted with Mongo DB running on AWS. This database was essentially a “source of truth” for all Guardian online content — about 2.3 million items. And we just completed the migration from Mongo to Postgres SQL.
Composer and its database were originally located in the Guardian Cloud - a data center in the basement of our office near Kings Cross, with an emergency switch elsewhere in London. One hot July day in 2015, our emergency transfer procedures were subjected to a rather severe test.

Heat: good for dancing at the fountain, destructive for the data center. Photo: Sarah Lee / Guardian
After that, the Guardian migration to AWS became a matter of life and death. To migrate to the cloud, we decided to purchase OpsManager , the management software for Mongo DB, and signed a contract for Mongo technical support. We used OpsManager to manage backups, orchestration, and monitoring our database cluster.
Due to editorial requirements, we needed to run a database cluster and OpsManager on our own AWS infrastructure, rather than using Mongo's managed solution. We had to sweat, because Mongo did not provide any tools for easy customization on AWS: we manually filled out the entire infrastructure and wrote hundreds of Ruby scriptsto install agents for monitoring / automating and orchestrating new database instances. As a result, we had to organize in the team literacy sessions on database management - what we had hoped OpsManager would take over.
Since the transition to AWS, we have had two significant failures due to problems with the database, each of which did not allow us to publish on theguardian.com for at least an hour. In both cases, neither OpsManager nor the Mongo technical support staff could provide us with sufficient assistance, and we solved the problem ourselves - in one case, thanks to a member of our team who was able to deal with the situation by calling from the desert on the outskirts of Abu Dhabi.
Each of the problematic issues deserves a separate post, but here are the general points:
- Pay close attention to time - do not block access to your VPC to the extent that NTP stops working.
- Automatically creating database indexes when launching an application is a bad idea.
- Database management is extremely important and difficult - and we would not want to do it ourselves.
OpsManager did not keep its promises about simple database management. For example, the actual management of OpsManager itself - in particular, upgrading from OpsManager version 1 to version 2 - took a lot of time and specialized knowledge about our OpsManager setup. He also failed to fulfill his one-click upgrade promise due to changes in the authentication scheme between different versions of Mongo DB. We lost at least two months of engineers time per year on database management.
All these problems, combined with a significant annual fee, which we paid for the support contract and OpsManager, forced us to look for an alternative database with the following characteristics:
- Minimal effort on database management.
- Encryption at rest.
- Acceptable migration path with Mongo.
Since all of our other services run on AWS, Dynamo, Amazon's NoSQL database, was the obvious choice. Unfortunately, at that time Dynamo did not support encryption of data at rest. After waiting for about nine months until this feature is added, we eventually abandoned this idea, deciding to use Postgres on AWS RDS.
“But Postgres is not a document repository!” - you resent ... well, yes, this is not a dock repository, but it has tables that are similar to JSONB columns, with support for indexes in the Blob JSON toolbox. We hoped that using JSONB we could migrate from Mongo to Postgres with minimal changes to our data model. In addition, if we wanted to move to a more relational model in the future, we would have such an opportunity. Another great thing about Postgres is how well it worked out: for every question we had, in most cases it was already answered in Stack Overflow.
In terms of performance, we were confident that Postgres would cope: Composer is a tool for recording content only (it makes a record in the database every time a journalist stops typing), and usually the number of simultaneous users does not exceed a few hundred - which does not require the system super high power!
Part two: two decades of content migration took place without downtime
Plan
Most database migrations involve the same actions, and ours is no exception. Here is what we did:
- Created a new database.
- Created a way to write to the new database (new API).
- Created a proxy server that sends traffic to both the old and the new database, using the old one as the main one.
- Transferred records from an old DB in new.
- Made new DB the main.
- Removed the old DB.
Considering that the database to which we migrated ensured the functioning of our CMS, it was critically important that migration caused the least possible disruption to the work of our journalists. In the end, the news never ends.
New API
Work on a new API based on Postgres began in late July 2017. This was the beginning of our journey. But in order to understand how it was, you must first clarify where we started from.
Our simplified CMS architecture was like this: a database, an API, and several applications associated with it (for example, a user interface). The stack was built and has been operating for 4 years based on Scala , Scalatra Framework and Angular.js .
After some analysis, we came to the conclusion that before we can transfer existing content, we need a way to communicate with the new PostgreSQL database, maintaining the old API in working condition. After all, Mongo DB is our "source of truth". She served us as a lifeline while we were experimenting with a new API.
This is one of the reasons why building on top of the old API was not part of our plans. The separation of functions in the original API was minimal, and the specific methods needed to work with Mongo DB could be found even at the controller level. As a result, the task of adding another type of database to an existing API was too risky.
We took a different path and duplicated the old API. So born APIV2. It was a more or less exact copy of the old Mongo-related API, and included the same endpoints and functionality. We used doobie , a clean functional JDBC layer for Scala, added Docker for local launch and testing, and also improved logging of operations and separation of responsibilities. APIV2 was supposed to be a fast and modern version of the API.
By the end of August 2017, we had a new API deployed, which used PostgreSQL as its database. But that was only the beginning. There are articles in Mongo DB that were first created more than two decades ago, and they all had to migrate to the Postgres database.
Migration
We should be able to edit any article on the site, regardless of when it was published, so all articles exist in our database as a single “source of truth”.
Although all articles live in the Guardian's Content API (CAPI) , which serves applications and the site, it was extremely important for us to migrate without any failures, since our database is our “source of truth”. If something happened to the Elasticsearch CAPI cluster, we would reindex it from the Composer database.
Therefore, before disabling Mongo, we had to make sure that the same request for an API running on Postgres and on an API running on Mongo would return identical responses.
To do this, we had to copy all the content into the new Postgres database. This was done using a script that directly interacted with the old and new APIs. The advantage of this method was that both APIs already provided a well-tested interface for reading and writing articles to and from databases, unlike writing something that directly addressed the relevant databases.
The main migration procedure was as follows:
- Get content from Mongo.
- Post content to Postgres.
- Get content from Postgres.
- Make sure the answers from them are identical.
Database migration can be considered successful only if end users have not noticed that this has happened, and a good migration script will always be the key to such success. We needed a script that could:
- Execute HTTP requests.
- Ensure that after migrating some content, the response of both APIs is the same.
- Stop when an error occurs.
- Create a detailed log of operations to diagnose problems.
- Restart after the error from the correct point.
We started by using Ammonite . It allows you to write scripts in the Scala language, which is the main one in our team. It was a good opportunity to experiment with what we didn’t use before to see if it would be useful for us. Although Ammonite allowed us to use a familiar language, we found several flaws in our work on it. Now Intellij supports Ammonite, but during our migration he did not do it - and we lost auto-completion and auto-import. In addition, for a long period of time, it was not possible to run the Ammonite script.
Ultimately, Ammonite was not the right tool for this job, and instead we used the sbt project to do the migration. This allowed us to work in a language in which we were confident, as well as perform several 'test migrations' before running in the main working environment.
The unexpected was how useful it was when checking the version of the API running on Postgres. We found several hard-to-find errors and limiting cases that we had not previously discovered.
Fast forward to January 2018, when it is time to test the full-scale migration in our pre-prod environment CODE.
Like most of our systems, the only similarity between CODE and PROD is the version of the application being run. The AWS infrastructure supporting the CODE environment was much less powerful than PROD, simply because it receives much less workload.
We hoped that the test migration in the CODE environment would help us:
- Estimate how long the migration in the PROD environment will take.
- Assess how (if at all) migration will affect performance.
In order to obtain accurate measurements of these indicators, we had to bring the two environments into complete mutual correspondence. This included restoring a Mongo DB backup from PROD to CODE and updating the infrastructure supported by AWS.
Migration of just over 2 million items of data should have taken much longer than the standard working day allowed. Therefore, we run the script in the screen at night.
To measure the migration, we sent structured requests (using markers) to our ELK stack (Elasticsearch, Logstash, and Kibana). From there, we could create detailed dashboards, tracking the number of articles successfully transferred, the number of failures and overall progress. In addition, all indicators were displayed on a large screen, so that the whole team could see the details.
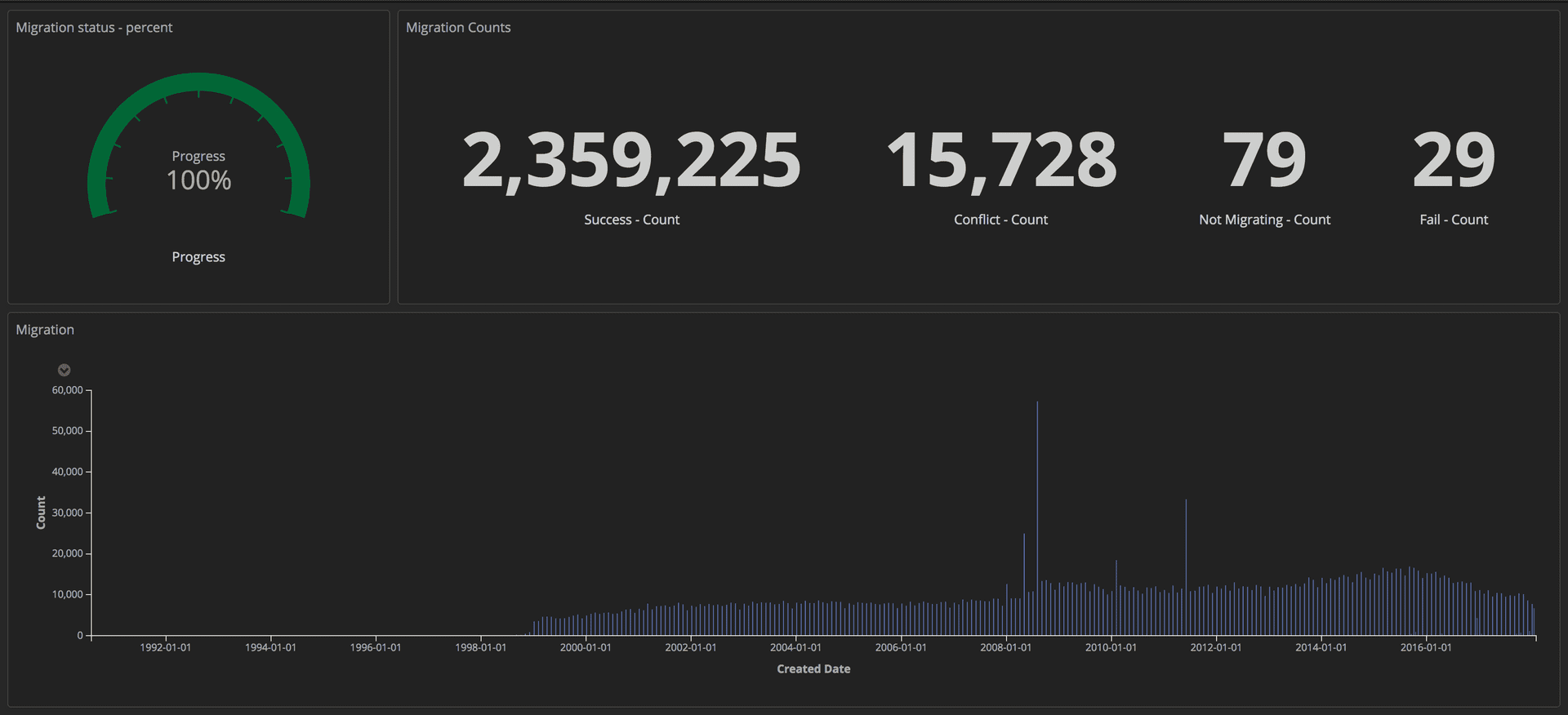
Dashboard showing the progress of the migration: Editorial Tools / Guardian
Once the migration was completed, we checked the coincidence of each document in Postgres and in Mongo.
Part three: Proxy and launch on sale
Proxy
Now that the new API running on Postgres has been launched, we needed to test it with real traffic and data access patterns to make sure it is reliable and stable. There were two possible ways to do this: upgrade every client that accesses the Mongo API so that it accesses both APIs; or run a proxy that does it for us. We wrote a proxy on Scala using Akka Streams .
The work of the proxy was quite simple:
- Accept traffic from load balancer.
- Redirect traffic to the main API and back.
- Asynchronously forward the same traffic to an additional API.
- Calculate the discrepancies between the two answers and log them.
Initially, the proxy registered many discrepancies, including some difficult but important behavioral differences in the two APIs that needed to be corrected.
Structured logging
In Guardian, we are logging using the ELK stack (Elasticsearch, Logstash and Kibana). Using Kibana gave us the opportunity to visualize the magazine in the most convenient way for us. Kibana uses Lucene query syntax , which is fairly easy to learn. But we soon realized that it was impossible to filter or group the log entries in the current setup. For example, we were unable to filter those that were sent as a result of GET requests.
We decided to send more structured data to Kibana, not just messages. One journal entry contains several fields, for example, a timestamp and the name of the stack or application that sent the request. Adding new fields is very easy. These structured fields are called markers and can be implemented using the logstash-logback-encoder library . For each request, we extracted useful information (for example, route, method, status code) and created a map with additional information needed for the log. Here is an example:
import akka.http.scaladsl.model.HttpRequest
import ch.qos.logback.classic.{Logger => LogbackLogger}
import net.logstash.logback.marker.Markers
import org.slf4j.{LoggerFactory, Logger => SLFLogger}
import scala.collection.JavaConverters._
object Logging {
val rootLogger: LogbackLogger = LoggerFactory.getLogger(SLFLogger.ROOT_LOGGER_NAME).asInstanceOf[LogbackLogger]
private def setMarkers(request: HttpRequest) = {
val markers = Map(
"path" -> request.uri.path.toString(),
"method" -> request.method.value
)
Markers.appendEntries(markers.asJava)
}
def infoWithMarkers(message: String, akkaRequest: HttpRequest) =
rootLogger.info(setMarkers(akkaRequest), message)
}
Additional fields in our journals allowed us to create informative dashboards and add more context regarding discrepancies, which helped us identify some minor inconsistencies between the two APIs.
Traffic replication and proxy refactoring
After transferring the contents to the CODE database, we received an almost exact copy of the PROD database. The main difference was that CODE had no traffic. For replicating real traffic to the CODE environment, we used the GoReplay open source tool (hereinafter - gor). It is very easy to install and flexible to customize to your requirements.
Since all the traffic that came to our API, first got on the proxy, it made sense to install gor on proxy containers. See below how to load gor into your container and how to start tracking traffic on port 80 and send it to another server.
с wget https://github.com/buger/goreplay/releases/download/v0.16.0.2/gor_0.16.0_x64.tar.gz
tar -xzf gor_0.16.0_x64.tar.gz gor
sudo gor --input-raw :80 --output-http http://apiv2.code.co.uk
For a while, everything worked fine, but very soon a malfunction occurred when the proxy became unavailable for several minutes. In the analysis, we found that all three proxy containers periodically hung at the same time. At first we thought that the proxy server was down because gor was using too many resources. Upon further analysis of the AWS console, we found that proxy containers hung regularly, but not simultaneously.
Before going into the problem further, we tried to find a way to run gor, but this time without additional load on the proxy. The solution came from our secondary stack for Composer. This stack is used only in case of emergency, and our working monitoring toolconstantly testing it. This time the replay of traffic from this stack in CODE with double speed worked without any problems.
New findings raised many questions. The proxy was built as a temporary tool, so it may not have been as carefully designed as other applications. In addition, it was built using Akka Http , with which none of our team was familiar. The code was chaotic and full of quick fixes. We decided to start a great work on refactoring to improve readability. This time we used for-generators instead of the growing nested logic that we used before. And added even more logging markers.
We hoped that we would be able to prevent the proxy containers from hanging, if we examine in detail what is happening inside the system and simplify the logic of its operation. But it did not work. After two weeks of trying to make the proxy more reliable, we felt trapped. It was necessary to make a decision. We decided to take the risk and leave the proxy as it is, since it is better to spend time on the migration itself than to try to fix a piece of software that will become unnecessary in a month. We paid for this decision with two more failures — almost two minutes each — but this had to be done.
Fast forward to March 2018, when we have already finished migrating to CODE without sacrificing API performance or client experience in CMS. Now we could start thinking about retiring proxies from CODE.
The first step was to change the API priorities, so that the proxy first interacts with Postgres. As we said above, this was solved by changing the settings. However, there was one difficulty.
Composer sends messages to the Kinesis stream after updating the document. Only one API was supposed to send messages to prevent duplication. For this API, they have a flag in the configuration: true for the API supported by Mongo, and false for the supported Postgres. Simply changing the proxy so that it first interacts with Postgres was not enough, since the message would not be sent to the Kinesis stream until the request reached Mongo. It's been too long.
To solve this problem, we created HTTP endpoints to instantly reconfigure all instances of the load balancer on the fly. This allowed us to very quickly connect the main API without the need to edit the configuration file and redeploy. In addition, it can be automated, thereby reducing human interaction and the likelihood of errors.
Now all requests were first sent to Postgres, and API2 interacted with Kinesis. A substitution could be made permanent with the configuration change and re-laying.
The next step was to completely remove the proxy and force clients to contact the Postgres API exclusively. Since we have a lot of customers, updating each of them individually was not possible. Therefore, we raised this task to the DNS level. That is, we created a CNAME in DNS that first pointed to the ELB proxy and would be modified to point to the ELB API. This allowed only one change to be made instead of updating each individual API client.
It's time to move the PROD. Although it was a bit scary, well, because it is the main working environment. The process was relatively simple, since everything was decided by changing the settings. In addition, as the stage marker was added to the logs, it became possible to repurpose previously built dashboards by simply updating the Kibana filter.
Disabling the proxy and Mongo DB.
After 10 months and 2.4 million transferred articles, we were finally able to disable all the infrastructure related to Mongo. But first, we had to do what we all expected: kill the proxy.
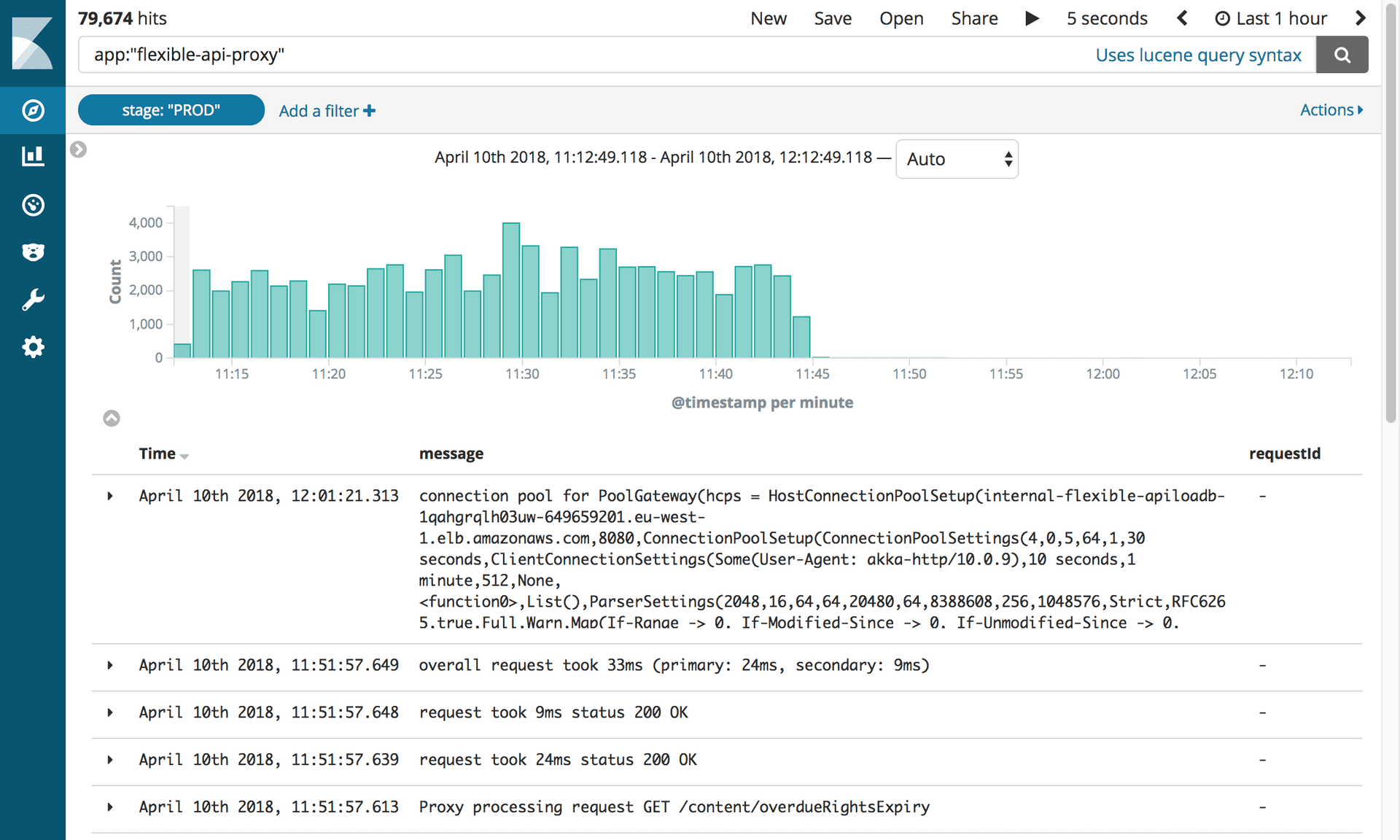
Logs showing disabled Flexible API Proxy. Photography: Editorial Tools / Guardian
This small piece of software caused us so many problems that we were eager to turn it off as soon as possible! All we had to do was update the CNAME record to point directly to the APIV2 load balancer.
The whole team gathered around one computer. It was necessary to make only one keystroke. Breath held for all! Complete silence ... Click! It is done. And nothing flew off! We all happily exhaled.
However, deleting the old Mongo DB API hid another test. Desperately removing the old code, we found that our integration tests were never adjusted to use the new API. Everything quickly became red. Fortunately, most of the problems were related to the configuration and we fixed them easily. There were several issues with PostgreSQL queries that were caught by the tests. Thinking about what could have been done to avoid this error, we learned one lesson: when embarking on a big task, accept that mistakes will be necessary.
After that, everything worked smoothly. We disconnected all instances of Mongo from OpsManager, and then disconnected them. The only thing left to do was to celebrate. And sleep.