Bot generates textbooks from Wikipedia articles
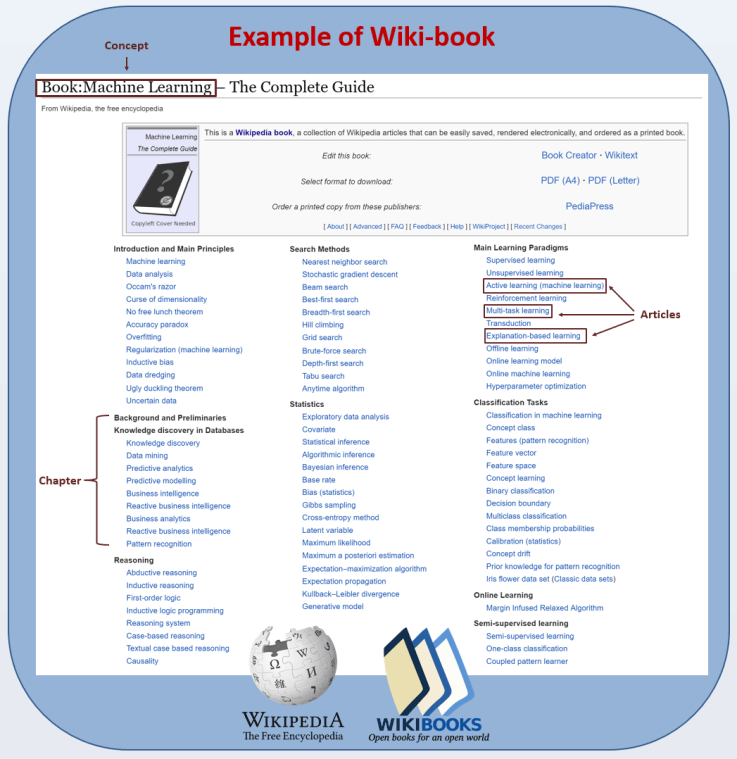
An example of a wikibook (this is an illustration from a scientific article )
Everyone knows that Wikipedia is a valuable information resource. You can spend hours studying the topic, moving from one link to another to get the context of the subject of interest. But it is not always obvious how to collect all the content on any one common topic. For example, how to combine all the articles on inorganic chemistry or the history of the Middle Ages, summarizing the most important? Approximately Shahar Admati and his colleagues from Ben-Gurion in the Negev (Israel), the developers of the machine learning program Wikibook-Bot, tried to do this.
Wikipedia and the textbook are different things. That is why the Wikibooks project was created , where people are jointly trying to summarize the most important thing on a topic. For example, you can find a machine learning tutorial with more than 6,000 pages, with updated sections on neural networks, genetic algorithms, and machine vision.
Wikibook-Bot solves several machine learning problems. First, this is the task of classification , that is, it is necessary to determine whether the article belongs to a particular Wikibooks. Secondly, it is necessary to divide the selected articles into chapters - this is the task of clustering . It was solved by known algorithms. Finally, the task of systematization , which includes two subtasks: the order of the articles in each chapter and the order of the chapters themselves.
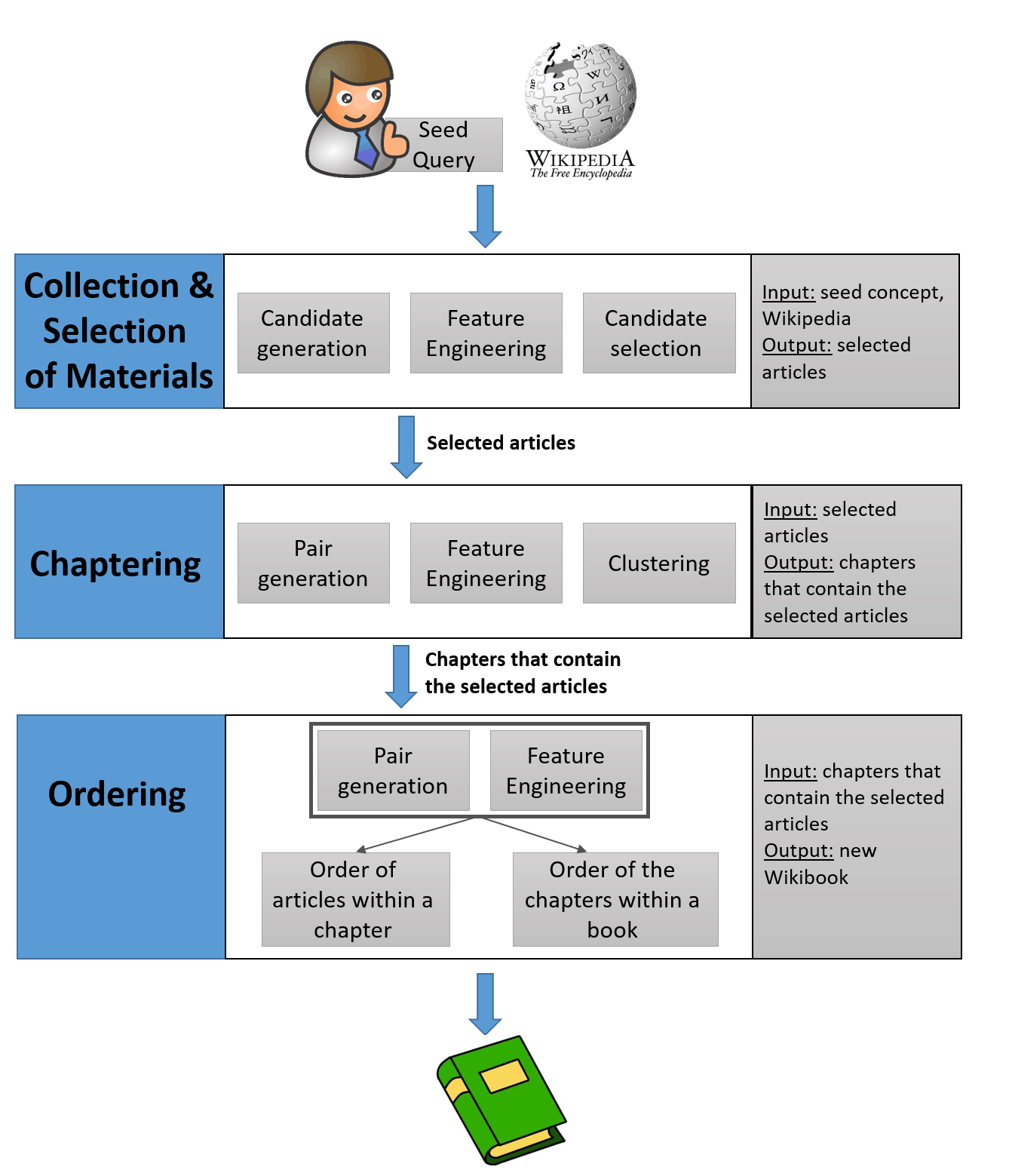
In fact, the program works relatively simply. The principle is clear to all who are faced with the training of neural networks. The first step is to create a training data set. Of approximately 6,700 existing English language books, books with more than 1000 views and 10 or more articles were selected.

Since these wikibooks form a kind of gold standard for both learning and testing, the developers took it as a quality standard. After the neural network was trained, further work was divided into several steps listed above: classification, clustering and systematization. The work begins with the textbook name generated by the person. The name describes any arbitrary concept. For example, "Machine Learning: A Complete Guide."
The first task is to sort the entire set of articles and determine which of them are relevant enough for inclusion in this topic. “This task is difficult because of the huge amount of articles on Wikipedia and the need to choose the most relevant articles from the millions available,” the authors write in a scientific paper. To solve, they used the Wikipedia network structure, because some articles often refer to others. It is reasonable to assume that the related article will also be on the topic.
So, the work begins with a small core of articles, in the title of which the given title is mentioned. Then all articles are determined that are at a distance of up to three transitions from the core. But how many of the articles found are included in the textbook? The answer to this question is given by wikibooks created by people. Automatic analysis of their content allows you to determine how much Wikipedia content in human-created books is included in the textbook.
Each person-created wikibook has a network structure defined by the number of links pointing to other articles, a certain number of links pointing to pages, ranking of the articles included, and so on. The developed algorithm analyzes each automatically selected article for a given topic and answers the question: if you include it in the wikibooks, will its network structure become more similar to human-created books or not. If not, the article is omitted.
Based mainly on learning data and existing methods of machine learning, other problems are solved. Thus, the team was able to automatically generate Wikibooks that have already been created by people. The effectiveness of the proposed method was evaluated by comparing automatically generated books with 407 real wikibooks. It is said that for all the tasks we managed to get high and statistically significant results when comparing. But still, the true efficiency of the algorithm can be assessed after generating wikibooks on other topics, and not only on those on which it was trained.
The description of the bot is published in the form of a scientific article “Wikibook-Bot - automatic generation of books from Wikipedia” on the site of preprints arXiv.org.