How to learn using machine learning from Dota 2 experts
In the previous article from the Petersburg Tower, we showed how using machine learning you can search for bugs in the program code. In this post we will talk about how, together with JetBrains Research, we are trying to use one of the most interesting, modern and rapidly developing sections of machine learning - reinforcement learning - both in real practical problems and in model examples.

About myself
My name is Nikita Sazanovich. Until June 2018, I studied for three years at SPbAU, and then, together with the rest of my group mates, I transferred to HSE St. Petersburg, where I now finish my undergraduate degree. Recently, I also work as a researcher at JetBrains Research. Before entering university, I was fond of sports programming and played for the national team of Belarus.
Reinforcement training
Reinforcement training is such a machine learning branch in which an agent, interacting with the environment, receives reinforcement (hence the name) in the form of a positive or negative reward. Depending on these prompts, the agent changes its behavior. The ultimate goal of this process is to get as much reward as possible, or, in another way, to achieve those actions that have been set for the agent.
Agents operate on states and select actions. For example, in the task of leaving the labyrinth, our states will be the coordinates x and y, and the actions of moving up / down / left / right. The general scheme looks like this:
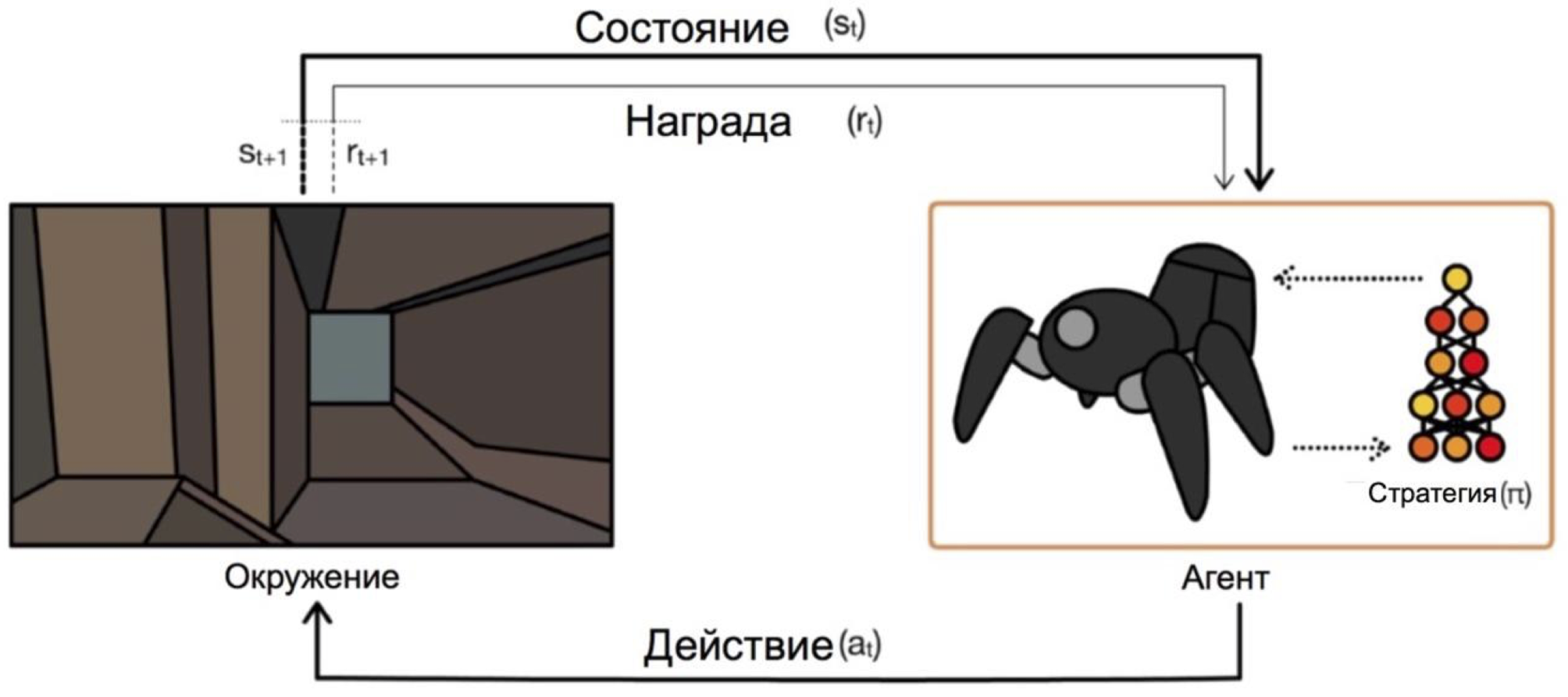
The main problem in the transition from fictional / simple tasks (like the same maze) to real / practical tasks is this: rewards in such tasks are usually very rare. If we want an agent, for example, to deliver pizza on a map of a city, he will understand that he did something good only by delivering an order to the door, and this will happen only if you complete a long and correct sequence of actions.
This problem can be solved by giving the agent at the start examples of how to “play” - the so-called expert demonstrations.
Task for learning
The model problem that will be discussed in the article is Dota 2.
Dota 2 is a popular MOBA game in which a team of five heroes must defeat the opposing team, destroying their “fortress”. Dota 2 is considered a rather difficult game, it has esports with prizes in the main tournament of $ 25000000 .
You could hear about the recent successes of OpenAI in Dota 2. First, they created a one-on-one bot and defeated professional players , and then moved on to playing 5x5 and showed impressive results this summer , although they lost to professional teams.

The only problem is that they trained the one-on-one agent, according to their own words , on 60,000 CPUs and a 256 K80 GPU on the Azure cloud. They, of course, have the opportunity to order so much power. But if you have less power, you have to use tricks. One of such tricks is the use of games already played by people.
Demonstrations in the game
In most cases, the demonstrations are recorded artificially: you just perform a task / play a game and somehow collect the actions you have taken. So you will collect some data that can be embedded in training in various ways. I have done so far, but how exactly it will be clear after the part about the scheme of interaction with the client of the game.
A more ambitious and adventurous goal is to get more data from open access. One of the reasons for choosing Dota 2 to speed up learning was a resource such as dotabuff . There are collected different statistics on the game, but more importantly, there are complete replays of games. And they can be sorted by rating.
So far I have not tried out how much a gigabyte of such data will help in comparison with several episodes. Implementing the same data collection was quite simple: you get links to games on dotabuff, download games and use the Dota 2 games parser .
Bundle with game client for training
We have Dota 2 game, the client of which exists for Windows, Linux and macOS platforms. But still, learning usually happens in some kind of python script, and in it you create an environment, be it a labyrinth, climb a car on a hill or something like that. But there is no environment for Dota 2. Therefore, I myself had to create this wrapper, which was quite interesting technically. It turned out to do this:
{kind=link}
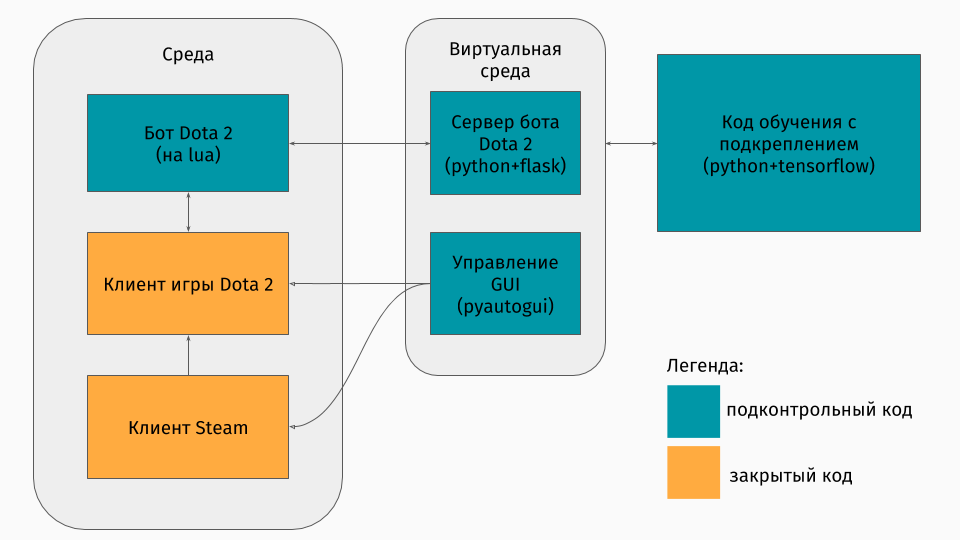
The first part is a script for communicating with the game client. Fortunately, for Dota 2 there is an official API for creating bots: Dota Bot Scripting . It is implemented as insertions in the Lua language, which, as it turned out, is popular in game development. The bot script, interacting with the game client, pulls out the information we need at the right moment (for example, coordinates on the map, positions of opponents) and sends json with it to the server.
The second part is the actual wrapper itself. This is designed in the form of a server that processes all the logic of launching Steam, Dota-s and getting json-s from the script inside the game. Managing the launch of games and clients is arranged through pyautogui , and communication with the lua-insert in the game is done via the Flask server.
The third part consists of the learning algorithm itself. This algorithm selects actions, receives the following states and rewards from the server, behind which all communication with the game is hidden, and improves its behavior.
Learning from the experts
The algorithm itself is not particularly important in this article, because these techniques can be used with any algorithm. We used DQN (about which it is possible to esteem on Habré ). In fact, this is a deep neural network + Q-learning algorithm . Yes, this is exactly the DQN that DeepMind created to play Atari games.
It is also more interesting to talk about how to use previous games. I experienced two approaches: potential-based reward shaping and action advice.
The general idea of the approaches is that the agent will receive the reward not only for the objectives of the task (for example, after completing the maze or climbing the mountain), but also during the training at each step. This additional reward will show how well the agent is acting to achieve the final goal. I would like to ask it, of course, automatically, and not select rules / conditions. The following approaches help to achieve this.
The essence of the potential-based reward shaping is that some states initially seem to us more promising than others, and on the basis of this we modify the real rewards that the algorithm receives. We do it like this: where
where  - modified award
- modified award  - a real reward
- a real reward  - discount factor from the learning algorithm (not very important to us), but
- discount factor from the learning algorithm (not very important to us), but  and there is our potential for the state we visited during
and there is our potential for the state we visited during  . A simple example is overcoming the maze.
. A simple example is overcoming the maze.
Suppose there is a labyrinth in which we want to come from a cell (0,0) into a cell (5.5). Then our potential for the state (x, y) can be minus the Euclidean distance from (x, y) to our goal (5.5): . That is, the closer we are to the finish line, the greater the potential of the state (for example,
. That is, the closer we are to the finish line, the greater the potential of the state (for example, ,
,  ,
,  ). So we motivate the agent by any means to approach the goal.
). So we motivate the agent by any means to approach the goal.
For Dota 2, the idea is the same, but the potentials are a little more complicated:

Imagine that we just want to go through the same states as the demonstrator. Then the more states we pass, the higher the potential. We put the potential of the state on the percentage of completion of the replay, if there is a state close to ours. It has a different meaning in different tasks. But in Dota 2, this means that at first we want the bot to reach the center (after all, at the beginning of the demonstrations, there are only steps to the center), and then to keep the player’s states (great health, safe distance to opponents, etc.). ).
The second method, action advice, was taken from this article . Its essence is that now we advise the agent not the usefulness of states, but the usefulness of actions. For example, in our game Dota 2 there can be such tips: if you have an enemy minion near you, then attack it; if you have not reached the center, then go in his direction; if you lose health, then retreat to your tower. And this article describes the method of setting such tips without any hesitation by the programmer himself - automatically.
Potentials generated by this principle: action potential  capable of
capable of increases in the presence of close states
increases in the presence of close states  with the same
with the same
actionin demonstrations. The reward for action on the chart above
changes as .
.
It is worth noting here that we are already setting the potentials for actions in states.
results
To begin, I note that the purpose of the game was slightly simplified, because I taught it all on my laptop. The agent’s goal was to inflict as many attacks as possible, which seems to be a real target in some approximation. To do this, you first need to get to the center of the map and then attack the opponents, trying not to die. To speed up the training, only a few (from 1 to 3) two-minute demonstrations recorded by myself were used.
Training an agent using any of the approaches takes only 20 hours on a personal computer (most of the time it takes to draw the game Dota 2), and judging by the OpenAI schedules, training on their servers goes for weeks.
A short excerpt of the game when using the potential-reward shaping approach:
And for the action advice approach:
These recordings were made at a training speed of x10. Inaccuracies in the behavior of the agent when moving to the center are still visible, but the struggle in the center still shows the learned maneuvers. For example, retreat back with low health.
You can also see the differences of approaches: when a potential-based reward shaping agent moves smoothly, because "goes by potential"; with action advice, the bot plays more aggressively in the center, as it receives hints on the attack.
Results
Immediately, I note that some points were deliberately omitted: what was the algorithm exactly, how the state appeared, and whether it is possible to train an agent to play with real players, etc.
First of all, I wanted to show in this article that in the case of training with reinforcements, you do not always have to choose between a very simple environment (escape from a maze) or a very large cost of training (according to my cursory calculations, OpenAI managed those Azure training servers for $ 4715 at one o'clock). There are techniques that allow you to speed up the training, and I told only about one of them - the use of demonstrations. It is important to note that in this way you do not just repeat the demonstrator, but only “repelled” from it. It is important that with further training the agent has the opportunity to surpass the experts.
If you are interested in the details, the learning process code can be found on GitHub .