Raspberry Pi3 vs DragonBoard. We respond to criticism

Posted by Nikolai Khabarov, Embedded Expert DataArt, Smart Home Technology Evangelist.
The test results in the article on comparing the performance of Raspberry Pi3 and DragonBoard boards with Python applications have raised doubts among some colleagues.
In particular, comments appeared under the material:
“... I did benchmarks between 32-bit ARMs, between 64-bit and between Intel x86_64 and all the numbers were comparable. at least between 32-bit and 64-bit ARMs, the difference was tens of percent, and not at times. well, or you just simply different --cpu-max-prime indicated. "
“Amazing results usually mean experiment error.”
“There is a suspicion that there is some kind of error in the CPU test. I personally tested different ARMs with sysbench, but the difference was 25 times not even close. in principle, good ARM media in a CPU test can be several times more effective than BCM2837, but not as much as 25 times. I suspect that the test for pi was done in one thread, and for DragonBoard in 4 threads (4 cores). "
This is a cpu test from the sysbench test suite. The answer to these assumptions turned out to be so voluminous that I decided to publish it in a separate post, at the same time explaining why in some tasks the difference can be so enormous.
To begin with, the teams with all the arguments for the test were listed in the table of the original article. Of course, there is no argument --cpu-max-prime or other arguments that force the use of multiple processor cores. In the part on the 10-20% difference, perhaps this meant a test of the overall system performance, which on real applications (not always, of course, but most likely) will show 10-20% of the difference between 32-bit and 64 -bit modes of the same processor.
In principle, one can read how mathematical operations with the capacity of a higher capacity of a machine word are implemented, for example, here. Rewriting algorithms makes no sense. Say, multiplication will take about 4 times more processor cycles (three multiplications + addition operations). Naturally, this value can vary from processor to processor and depending on the compiler optimization. For example, for an ordinary x86 processor, there may not be any difference, since even with the advent of the MMX instruction set, it became possible to use 64-bit registers and 64-bit calculations on 32-bit processor. And with the advent of SSE, 128-bit registers appeared. If a program is compiled using such instructions, then it can be executed even faster than 32-bit calculations, a difference of 10-20% or even more can be observed in the other direction, since the same set of MMX instructions can perform several operations at the same time.
But we are still talking about a synthetic test that explicitly uses 64-bit numbers (source codes are available here ), and since the package is taken from the official repository, it is not a fact that all possible optimizations were included in the package assembly (all because of the same compatibility with other ARM processors). For example, ARM processors starting with v6 support SIMD, which, like MMX / SSE on x86, can work with 64-bit and 128-bit arithmetic. We did not aim to squeeze as many “parrots” out of the tests as possible, we are interested in the real situation when installing applications “out of the box”, because we do not want to mine another half of the operating system.
Still do not believe that even out of the box the speed on the same processor cannot differ ten times depending on the processor mode?
Well, let's take the same DragonBoard.
sysbench --test=cpu runThis time with screenshots:
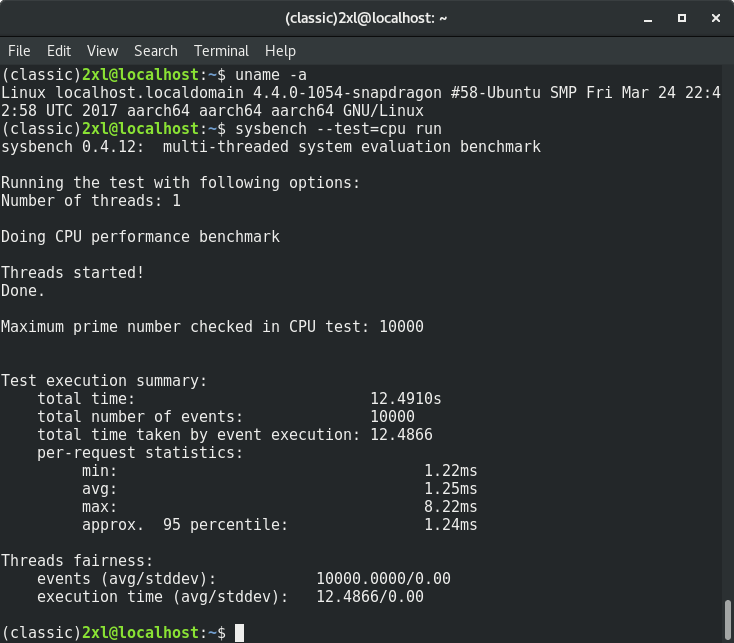
12.4910 seconds. Ok, now on the same board:
sudo dpkg --add-architecture armhf
sudo apt update
sudo apt install sysbench:armhfWith these commands we installed the 32-bit version of the sysbench package on the same DragonBoard.
And again:
sysbench --test=cpu runAnd here is a screenshot (the output of apt install is visible at the top):

156.4920 seconds. The difference is more than 10 times. Since we are talking about such cases, let's look at why in more detail. Let's write such a simple program in C:
#include
#include
int main(int argc, char **argv) {
volatile uint64_t a = 0x123;
volatile uint64_t b = 0x456;
volatile uint64_t c = a * b;
printf("%lu\n", c);
return 0;
} We use the volatile keyword so that the compiler does not calculate everything in advance, namely, assigns variables and makes an honest multiplication of two arbitrary 64-bit numbers. Let's build a program for both architectures:
arm-linux-gnueabihf-gcc -O2 -g main.c -o main-armhf
aarch64-linux-gnu-gcc -O2 -g main.c -o main-arm64Now let's see the disassembler for arm64:
$ aarch64-linux-gnu-objdump -d main-arm64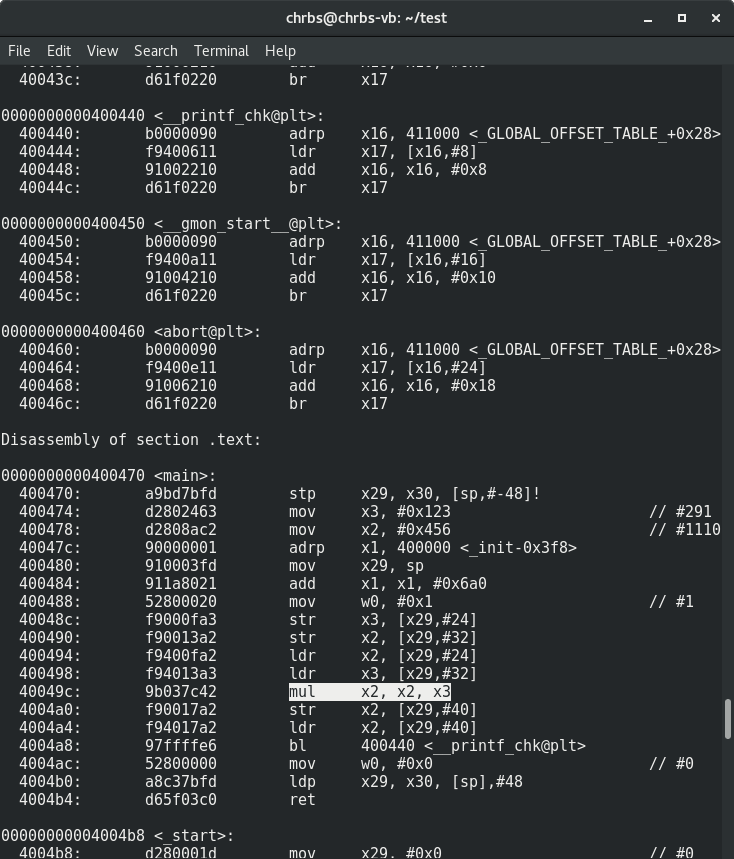
The mul instruction is pretty predictable. And now for armhf:
$ arm-linux-gnueabihf-objdump -d main-armhf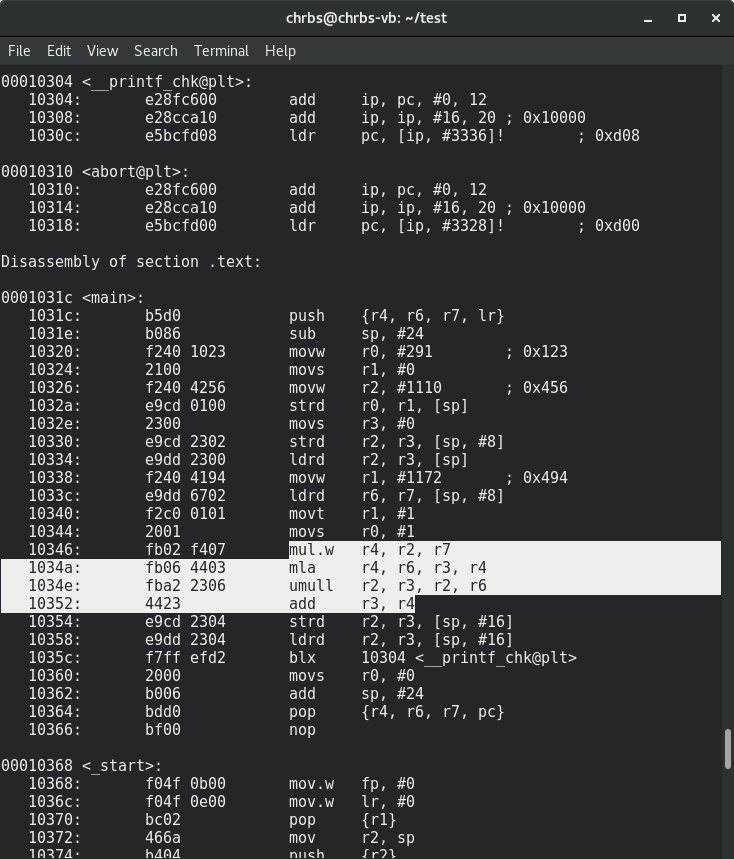
As you can see, the compiler used one of the methods of long arithmetic. And as a result, we observe a whole footcloth that uses quite heavy instructions of mul, mla, umull, among others. Hence the multiple difference in performance.
Yes, you can still try to compile by including some set of instructions, but then we may lose compatibility with some processor. Once again, we were interested in the real speed of the entire board with real binary packages. We hope this justification, why such a difference was obtained on a specific cpu test , is sufficient. And you will not be confused by such gaps in some tests and, possibly, some application programs.