We load terabytes with barrels or SparkStreaming vs Spring + YARN + Java

As part of the project of integration of GridGain and storage based on Hadoop (HDFS + HBASE), we were faced with the task of obtaining and processing a significant amount of data, up to about 80 Tb per day. This is necessary for building storefronts and for recovering data deleted in GridGain after they are uploaded to our long-term storage. In general terms, we can say that we transfer data between two distributed data processing systems using a distributed data transmission system. Accordingly, we want to talk about the problems that our team encountered in implementing this task and how they were resolved.
Since the integration tool is kafka (it is described in great detail in the articleMikhail Golovanov), a natural and easy solution here is to use SparkStreaming. Easy because you don’t have to worry much about crashes, reconnections, commits, etc. Spark is known as a quick alternative to the classic MapReduce, thanks to numerous optimizations. You just need to tune in to the topic, process the batch and save it to a file, which was implemented. However, during the development and testing, the instability of the data receiving module was noticed. In order to exclude the influence of potential errors in the code, the following experiment was performed. All the message processing functionality was cut and only direct saving was left immediately in avro:
JavaRDD> map = rdd.map(messageTuple ->
{
SeekableByteArrayInput sin = new SeekableByteArrayInput(messageTuple.value());
DataFileReader dataFileReader = new DataFileReader<>(sin, new GenericDatumReader<>());
GenericRecord record = (GenericRecord) dataFileReader.next();
return new AvroWrapper<>(record);
});
Timestamp ts = new Timestamp(System.currentTimeMillis());
map.mapToPair(recordAvroWrapper ->
new Tuple2, NullWritable>(recordAvroWrapper, NullWritable.get()))
.saveAsHadoopFile("/tmp/SSTest/" + ts.getTime(),
AvroWrapper.class, NullWritable.class,
AvroOutputFormat.class, jobConf);
All tests took place on such a bench:

As it turned out, everything works fine on a cluster free from other people's tasks, and you can get pretty good speed. However, it turned out that when working simultaneously with other applications, very large delays are observed. Moreover, problems arise even at ridiculous speeds, about 150 MB / s. Sometimes the spark comes out of depression and catches up with what was lost, but sometimes it happens like this:
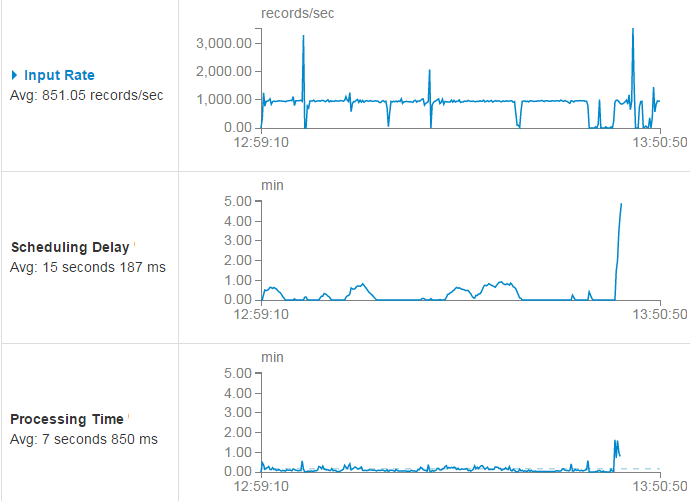
It can be seen that at a reception rate of about 1000 messages per second (input rate), after several drawdowns, the delay in starting the processing of the batch (scheduling delay) still returned to normal ( middle part of the graph). However, at some point, the processing time went beyond the permissible limits and the soul of the spark did not pass the earthly tests and rushed to the sky.
It is clear that this is the norm for the Indian guru, but our PROM is not in the ashram, so this is not particularly acceptable. In order to make sure that the problem is not in the data storage function, you can use the Dataset wrapper - it seems to be well optimized. Therefore, we try this code:
JavaRDD rows = rdd.map(messageTuple -> {
try (SeekableByteArrayInput sin = new SeekableByteArrayInput(messageTuple.value());
DataFileReader dataFileReader = new DataFileReader<>(sin, new GenericDatumReader<>())) {
GenericRecord record = (GenericRecord) dataFileReader.next();
Object[] values = new Object[]{
record.get("field_1"),
…
record.get("field_N")};
return new GenericRowWithSchema(values, getSparkSchema(ReflectData.get().getSchema(SnapshotContainer.class)));
}
});
StructType st = (StructType) SchemaConverters.toSqlType(schm).dataType();
Dataset batchDs = spark.createDataFrame(rows, st);
Timestamp ts = new Timestamp(System.currentTimeMillis());
batchDs
.write()
.mode(SaveMode.Overwrite)
.format("com.databricks.spark.avro")
.save("/tmp/SSTestDF/" + ts.getTime());
And we get exactly the same problems. And if you run two versions at the same time, on different clusters, then the problems occurred only for the one that works on a more loaded one. This meant that the problem was not in kafka and not in the specifics of the data storage function. Testing also showed that if you read the same topic with which SS worked with the flume on the same cluster at the same time, you get the same slowdown in data extraction:
Topic1, Cluster1, SparkSreaming - slowdowns
Topic2, Cluster1, Flume - slowdowns
Topic2, Cluster2, SparkSreaming - No Slowdowns
In other words, the problem was precisely the background load on the cluster. Thus, the task was to write an application that would work reliably in a highly loaded environment, and all this was complicated by the fact that the tests above do not contain any data processing logic at all. Whereas the real process looks something like this:
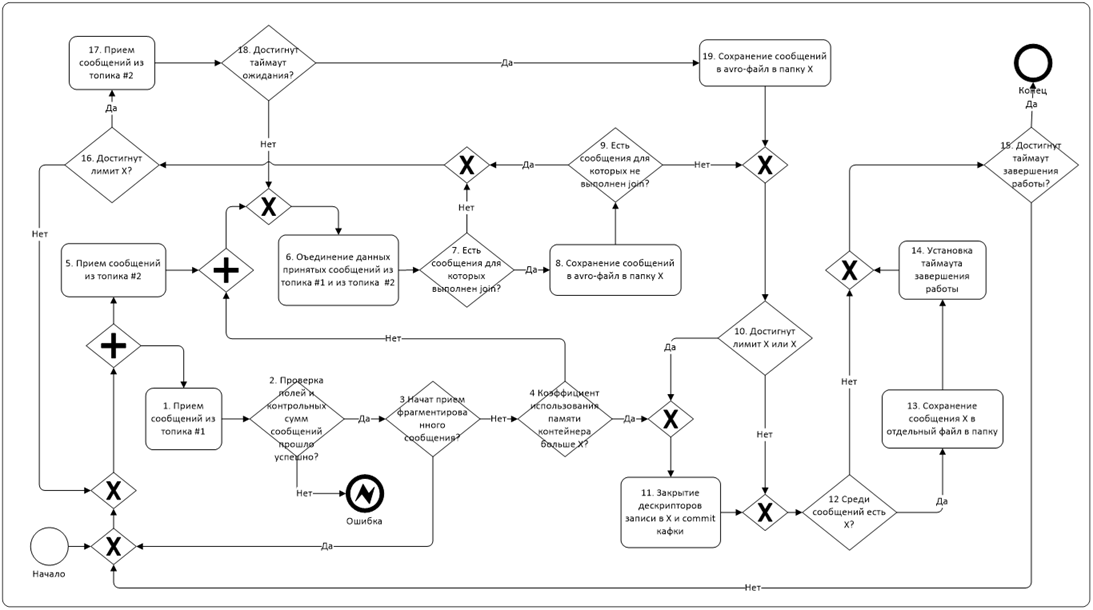
The main difficulty here is the task of collecting data simultaneously from two topics (from one small data stream, and from the second large) and their join on the fly. There was also a need to write data from one batch to different files at the same time. In a spark, this was implemented using a serializable class and calling its methods from the message reception map. Sometimes the spark fell, trying to read rotten messages from the topic, and we began to store offsets in hbase. At some point, we began to gaze at the resulting monster with some kind of longing and stifled torment.
Therefore, we decided to turn to the bright side of the force - warm, tube java. Fortunately, we have aggile, and it is not at all necessary to

However, for this it is necessary to solve the problem of distributed reception of messages from several nodes at once. For this, the Spring for Apache Hadoop framework was chosen, which allows you to run the required number of Yarn containers and execute your code inside each.
The general logic of his work is as follows. AppMaster is launched, which is the coordinator of the YARN containers. That is, he launches them, passing the necessary parameters to them as an input, and monitors the status of execution. If the container crashes (for example, due to OutOfMemory), it can restart it or shut down.
Directly in the container, the logic of working with kafa and data processing is implemented. Since YARN launches containers by distributing the cluster nodes approximately uniformly, there are no bottlenecks for network traffic or disk access. Each container clings to a dedicated partition and works only with it, this helps to avoid rebalancing consumers.
Below is a very simplified description of the logic of the module, a more detailed description of what happens under the hood of the spring, colleagues plan to do in a separate article. An original example can be downloaded here .
So, to run the wizard, the client module is used:
@EnableAutoConfiguration
public class ClientApplication {
public static void main(String[] args) {
ConfigurableApplicationContext applicationContext = SpringApplication.run(ClientApplication.class, args);
YarnClient yarnClient = applicationContext.getBean(YarnClient.class);
yarnClient.submitApplication();
}
}After the submit wizard is completed, the client exits. Next is the class CustomAppMaster prescribed in application.yml
spring:
hadoop:
fsUri: hdfs://namespace:port/
resourceManagerHost: hostname
resources:
- "file:/path/hdfs-site.xml"
yarn:
appName: some-name
applicationDir: /path/to/app/
appmaster:
resource:
memory: 10240
virtualCores: 1
appmaster-class: enter.appmaster.CustomAppMaster
containerCount: 10
launchcontext:
archiveFile: container.jar
container:
container-class: enter.appmaster.FailingContextContainer
The preLaunch function is most interesting in it. Here we manage the containers and parameters passed to the input:
@Override
public ContainerLaunchContext preLaunch(Container container, ContainerLaunchContext context) {
Integer attempt = 1; // Счетчик попыток запуска
ContainerId containerId = container.getId();
ContainerId failedContainerId = failed.poll();
if (failedContainerId == null) {
// Логика подготовки к запуску контейнера
}
else {
// Логика обработки случая падения контейнера (перезапуск и т.д.)
}
Object assignedData = (failedContainerId != null ? getContainerAssign().getAssignedData(failedContainerId) : null);
if (assignedData != null) {
attempt = (Integer) assignedData;
attempt += 1;
}
getContainerAssign().assign(containerId, attempt);
Map env = new HashMap(context.getEnvironment());
env.put("some.param", "param1");
context.setEnvironment(env);
return context;
}
And the fall handler:
@Override
protected boolean onContainerFailed(ContainerStatus status) {
ContainerId containerId = status.getContainerId();
if (status.getExitStatus() > 0) {
failed.add(containerId);
getAllocator().allocateContainers(1);
}
return true;
}In the container class ContainerApplication.java, the necessary beans are connected, for example:
@Bean
public WorkClass workClass() {
return new WorkClass();
}In the working class, we use the @OnContainerStart annotation to indicate the method that will be called automatically when the container starts:
@OnContainerStart
public void doWorkOnStart() throws Exception {
// Получаем текущий контейнер и выясняем текуший containerId
DefaultYarnContainer yarnContainer = (DefaultYarnContainer) containerConfiguration.yarnContainer();
Map environment = yarnContainer.getEnvironment();
ContainerId containerId = getContainerId(environment);
// Получаем параметр на вход
String param = environment.get("some.param");
SimpleConsumer simpleConsumer = new SimpleConsumer<>();
// Начинаем работать
simpleConsumer.kafkaConsumer(param);
}
In reality, the logic of implementation is, of course, much more complicated. In particular, there is a message exchange between the container and AppMaster via REST, which allows coordinating the process of receiving data, etc.
As a result, we got an application that needs to be tested in a loaded cluster. To do this, during the day, during a high background load, we launched a stripped-down version on SparkStreaming, which does nothing but save to a file, and at the same time the “full stuffing” version in java. They were allocated the same resources, each 30 containers with 2 cores.

Now it’s interesting to conduct an experiment in pure conditions in order to understand the performance limit of a solution in java. To do this, a download of 1.2 TB of data, 65 containers of 1 core was launched and it completed in 10 minutes:

Those. speed was 2 GB / sec. The higher values in the picture above are explained by the fact that the factor of data replication on HDFS is equal to 3. CPU of the data receiving cluster cluster E5-2680v4 @ 2.40GHz. The remaining parameters do not make much sense, because all the same, the utilization of resources is significantly lower than 50%. The current solution makes it easy to scale further, but it does not make sense, because At the moment, the bottleneck is the kafka itself (more precisely, its network interfaces, there are only three brokers and at the same time triple replication for reliability).
In fact, it should not seem that we have anything against spark in principle. This is a very good tool in certain conditions and we also use it for further processing. However, a high level of abstraction, which allows you to quickly and easily work with any data, has a price. It always happens when something goes wrong. We had experience with Hbase patching and picking in Hive code, however, this is not the most encouraging activity, actually. In the case of spark, of course, it is also possible to find some acceptable solution, but at the cost of quite a lot of effort. And in our application, we can always quickly find the cause of the problems and fix it, as well as implement very complex logic and this will work quickly. In general, as the old Latin saying goes:
