How to become a GPU engineer in an hour
Does a non-gaming iOS developer need to be able to work with a GPU? Does he even need to know that there is a GPU in the iPhone? Many successfully work in iOS development, never thinking about this topic. But the GPU can be useful both for 3D-graphics, and for other tasks, in some cases leaving the CPU behind.
When Andrei Volodin (Prisma AI) talked about using the GPU in iOS at the Mobius 2017 Moscow conference, his report became one of the conference’s favorites, receiving high marks from the audience. And now, on the basis of this report, we have prepared a hubrapost, which allows you to get all the same information in text. It will be interesting even to those who do not work with iOS: the report begins with things that are not specifically tied to this platform.
The plan is this. First, let's look at the history of computer graphics: how it all began and how we came to what is now. Then we’ll figure out how rendering is done on modern video cards. What Apple offers us as an iron vendor. What is GPGPU. Why Metal Compute Shaders is a cool technology that has changed everything. And at the very end, let's talk about hype train, that is, popular now: Metal Performance Shaders, CoreML and the like.

The first known system with a separate hardware for video was the Atari 2600. This is a fairly well-known classic game console, released in 1977. Its feature was that the amount of RAM was only 128 bytes, and not only available to the developer: it was for the game, and for the operating system of the console itself, and for the entire call stack.
On average, games were rendered at a resolution of 160x192, and the palette had 128 colors. It is easy to calculate that storing one frame of the game required many times more RAM. Therefore, this console went down in history as one big hack: all the graphics in it were generated in real time (in the literal sense of the word).

At that time, TVs worked with beam guns, through electronic heads. The image was scanned line by line, and the developers should, as the TV scanned the image through an analog cable, tell him what color of the current pixel to draw. Thus, the image appeared on the screen completely.

Another feature of this console was that at the iron level it supported only five sprites at a time. Two sprites for the player, two for the so-called "rockets" and one sprite for the ball. It’s clear that for most games this is not enough, because there are usually more interactive objects on the screen.

Therefore, the technique was used there, which later went down in history under the name "race with the beam." As the beam scanned the image from the set-top box, those pixels that were already drawn remained on the screen until the next frame. Therefore, the developers moved the sprites while the beam was moving, and thus could draw more than five objects on the screen.
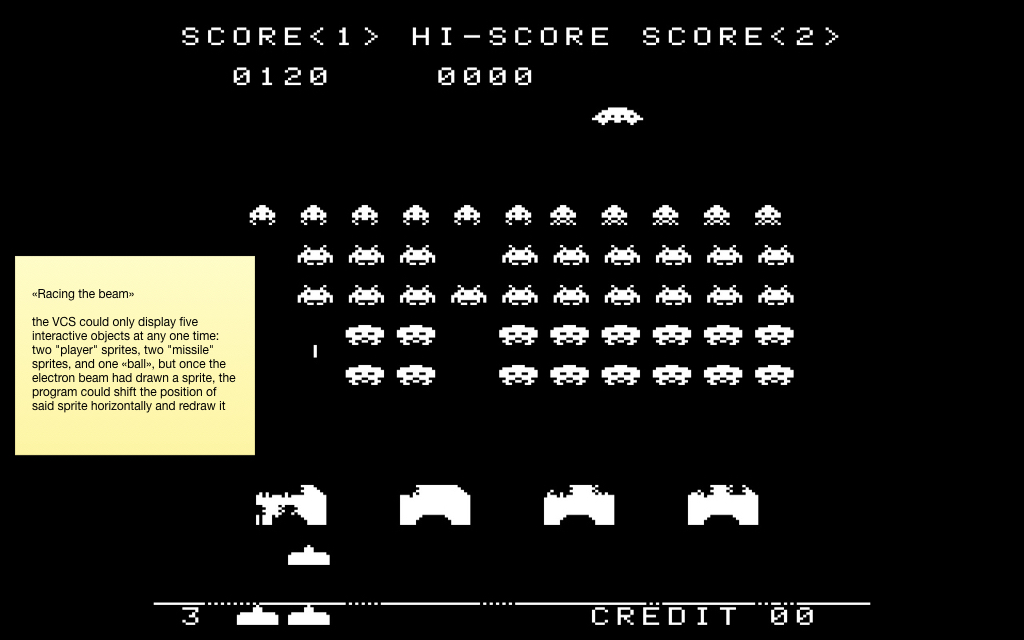
This is a screenshot from the famous Space Invaders game, in which there are more than five interactive objects. In exactly the same way effects like parallax (with wave-like animations) and others were drawn. The book Racing the Beam was written based on all this fever . And from it I took this curious illustration:

The fact is that the TV scanned the image non-stop, and the developers did not have time to read the click on the joystick, to calculate some kind of game logic, etc. Therefore, the resolution was made higher than on the screen. And the “vertical blank”, “overscan” and “horizontal blank” zones are a fake resolution that the TV scanned, but at that time there was no video signal, and the developers considered the game logic. And in Activision's Pitfall game, the logic was so complicated at the time that they had to draw more tree crowns at the top and black earth at the bottom all the time to have more time to calculate it.

The next stage of development was the Nintendo Entertainment System in 1983, and there were similar problems: there was already an 8-bit palette, but still there was no frame buffer. But there was PPU (picture processing unit) - a separate chip that was responsible for the video sequence, and tile graphics were used there. Tiles are such pieces of pixels, most often they were 8x8 or 8x16. Therefore, all the games of that period look a little square:

The system scanned the frame with such blocks and analyzed which parts of the image should be drawn. This allowed us to seriously save video memory, and collision detection “out of the box” was an additional plus. Gravity appeared in games, because it was possible to understand which squares intersected with which ones, it was possible to collect coins, take lives when we were in contact with enemies, and so on.

Subsequently, 3D graphics began, but at first it was insanely expensive, mainly used in flight simulators and some enterprise solutions. It was considered on such terrible, huge chips and it didn’t reach ordinary consumers.

The well-known company NVidia in 1999 with the release of a new device introduced the term GPU (graphics processing unit). At that time, it was a very highly specialized chip: it solved a number of tasks that made it possible to slightly accelerate 3D graphics, but it could not be programmed. You could only say what to do, and he returned the answer using some pre-built algorithms.

In 2001, the same NVidia released GeForce 3 with the GeForceFX package, in which shaders first appeared. We will definitely talk about them today. It was this concept that turned all computer graphics upside down, although at that time it was still programmed in assembler and it was quite complicated.
The main thing that happened after that was a trend. You have probably heard about such a metric of iron performance as flops. And it became clear that over time, video cards, as compared to central processors, simply fly into space in terms of performance:
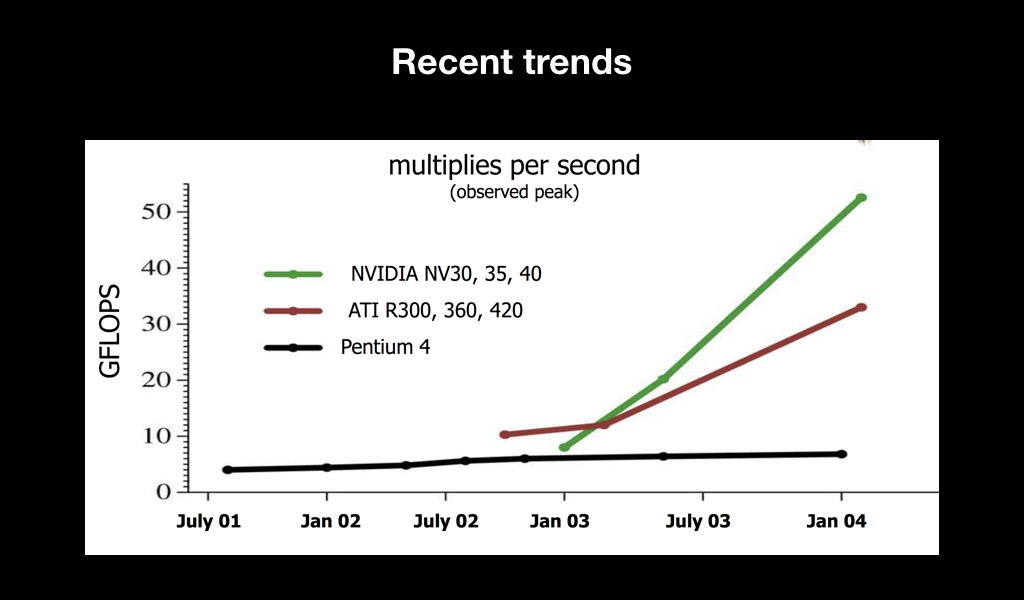
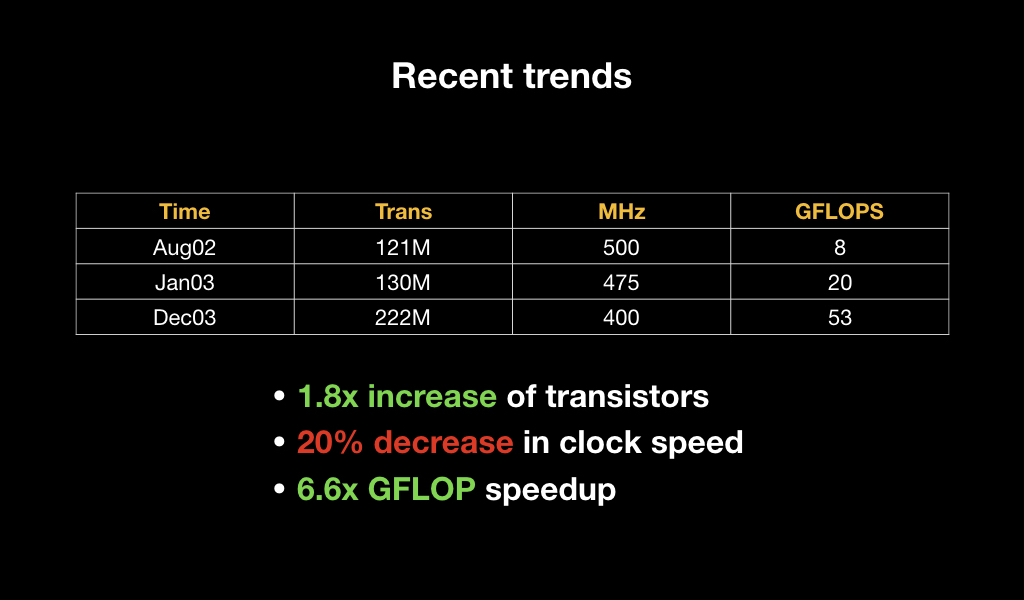
Moreover, if we look at their specifications, we will see that literally in a year the number of transistors increased by 2 times, while the clock frequency of each of them decreased, but the overall performance increased by almost 7 times. This suggests that a bet was made on parallel computing.
To understand why the GPU needs to be counted so much in parallel, let's see how rendering is now on most video cards - both desktop and mobile.
For many of you, it can be a major disappointment that the GPU is a very dumb piece of hardware. She can only draw triangles, lines and points, nothing else. And it is very optimized for working with floating point numbers. It does not know how to count double and, as a rule, works very poorly with int. There are no abstractions on it in the form of an operating system and other things. It is as close to iron as possible.

For this reason, all 3D objects are stored as a set of triangles, on which the texture is most often stretched. These triangles are often called polygons (those who play games are familiar with words like “there are twice as many polygons in the Kratos model”).
In order to render this all, these triangles are first placed in the game world. The game world is an ordinary three-dimensional coordinate system, where we put them, and each object has, as a rule, its own position, rotation, distortion, etc.

Often there is such a concept as a camera, when we can look at the game world from different angles. But it’s clear that in fact there is no camera there, and in reality it’s not the camera that moves, but the whole game world: it turns to the monitor so that you see it from the right angle.
And the last stage is the projection, when these triangles get on your screen.

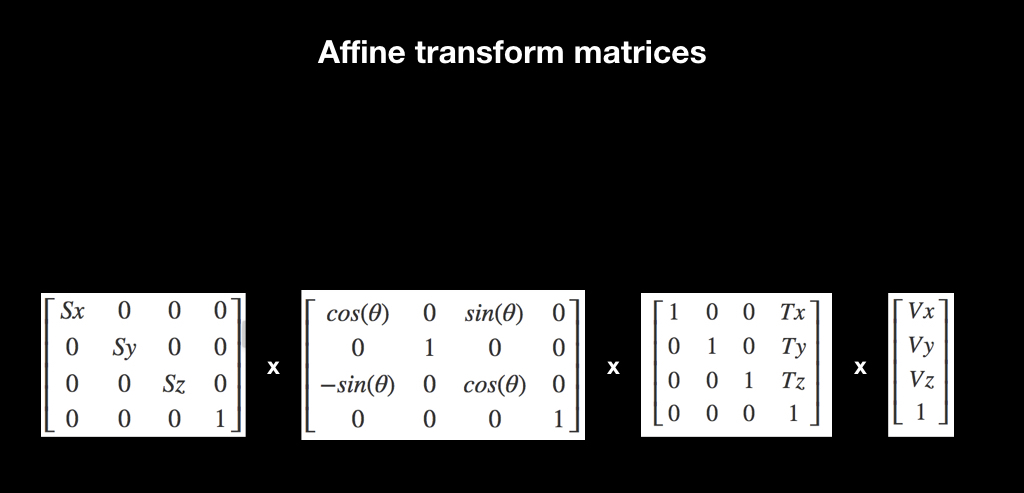
For all this, there is a wonderful mathematical abstraction in the form of affine transformations. Whoever worked with UIKit is familiar with this concept thanks to CGAffineTransform, all animations are made through it. There are different matrices of affine transformations, here for scale, for rotation and for transfer:
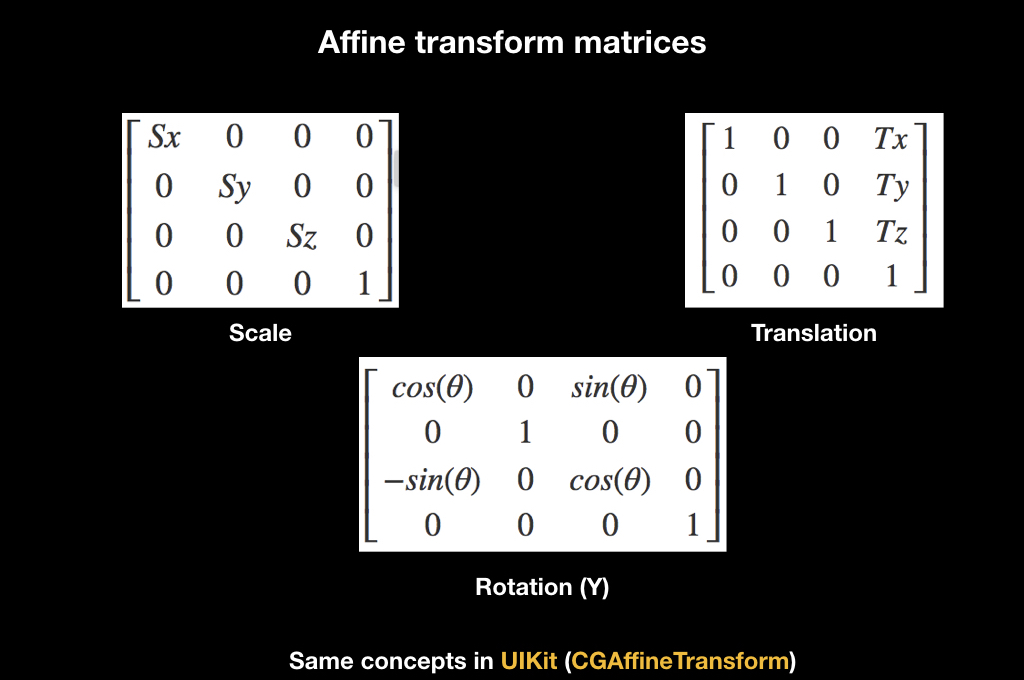
They work like this: if you multiply the matrix by some vector, then the transformation will apply to it. For example, when translating, the translation matrix shifts the vector.
And another interesting fact associated with them: if you multiply several such matrices, and then multiply them by a vector, then the effect accumulates. If at first there is a scale, then a rotation, and then a transfer, then when applying all this to the vector, all this is done immediately.
In order to do this efficiently, vertex shaders were invented. Vertex shaders are such a small program that runs for every point in your 3D model. You have triangles, each with three points. And for each of them, a vertex shader is launched, which takes the input position of the vector in the coordinate system of the 3D model, and returns it in the coordinate system of the screen.
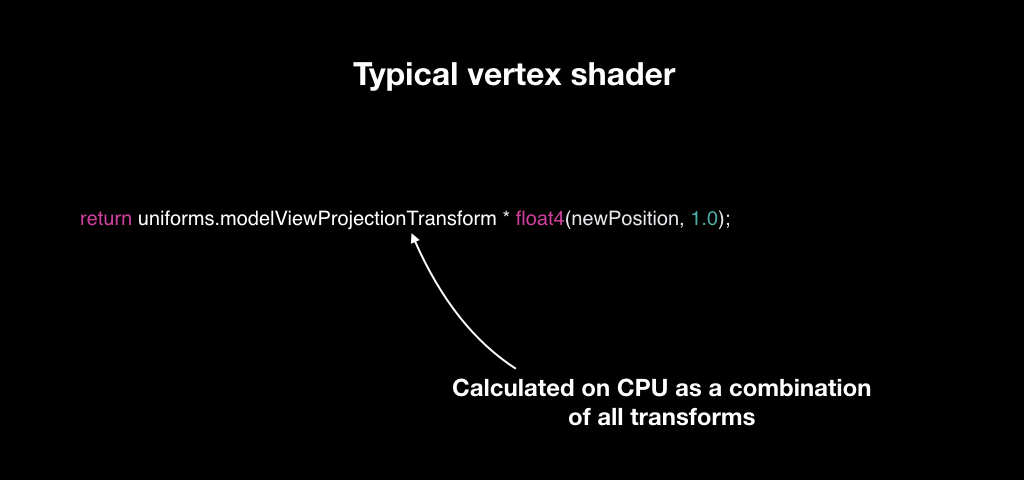
Most often, this works as follows: for each object, we calculate a unique transformation matrix. We have a camera matrix, a world matrix and an object matrix, we multiply them all and give them to the vertex shader. And for each vector he takes, multiplies it and returns a new one.
Our triangles appear on the screen, but this is still a vector graphic. And then the rasterizer is included in the game. It does a very simple thing: it takes pixels on the screen and superimposes a pixel grid on your vector geometry, choosing those pixels that intersect with your geometry.
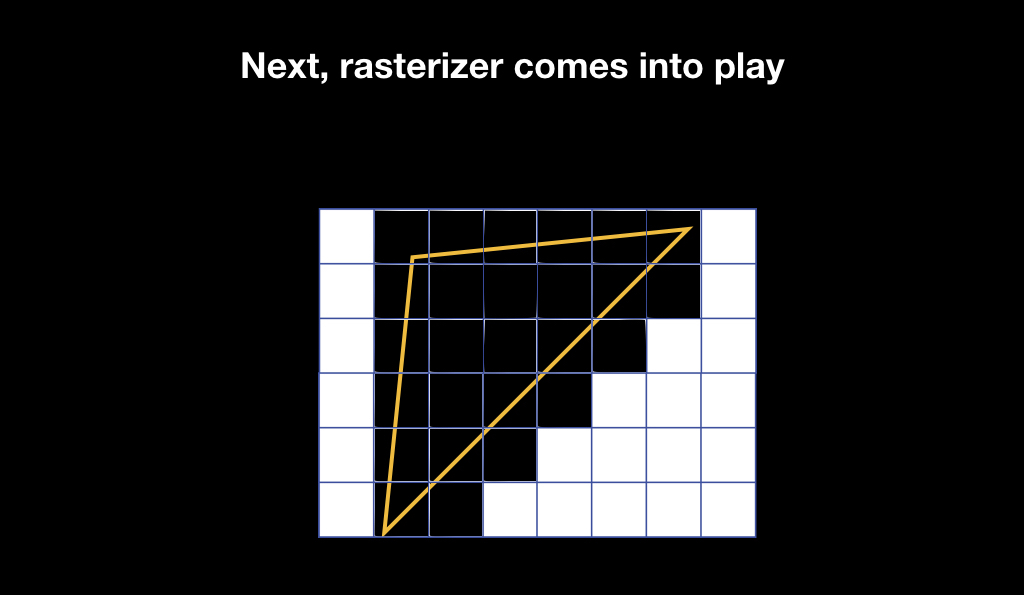
After that, fragment shaders are launched. Fragment shaders are also a small program, it starts already for each pixel that falls into the area of your geometry, and returns the color, which will subsequently be displayed on the screen.
In order to explain how this works, imagine that we will draw two triangles that cover the entire screen (just for clarity).

The simplest fragment shader that you can write is a shader that returns a constant. For example, the color is red and the entire screen turns red. But this is boring enough.
Fragment shaders take the pixel coordinate as input, so we can, for example, calculate the distance to the center of the screen, and use this distance as a red channel. Thus, a gradient appears on the screen: the pixels close to the center will be black, because the distance will tend to zero, and at the edges of the screen will be red.

Further we can add, for example, a uniform. A uniform is a constant that we pass to the fragment shader, and it applies it the same for each pixel. More often than not, time becomes such a uniform. As you know, time is stored in the form of the number of seconds from a certain moment, so we can count the sine from it, getting some value.

And if we multiply our red channel by this value, we get a dynamic animation: when the sine of time goes to zero, everything turns black, when one - returns to its place.
Shader writing itself has grown into a whole culture. These images are drawn using mathematical functions:

They do not use 3D models or textures. This is all pure math.
In 1984, someone Paul Hackbert even launched a challenge, when he handed out business cards with a code, by running which you could get this picture:

And this challenge is still alive at SIGGRAPH, CVPR, major conferences in California. You can still see business cards that print something.
But it is unlikely that all of this has entered the masses only because it is beautiful. And in order to understand what opportunities this all opens up, we will see what can be done with the ordinary sphere. Suppose we have a 3D model of a sphere (it’s clear that this is actually not a sphere, but many triangles that form a ball with some degree of approximation). We’ll take such a texture, which is often called smooth noise:

These are just some random pixels that gradually flow from white to black. We will pull this texture onto our ball, and in the vertex shader we will do the following: the points that fall on the darker pixels will be shifted weaker, and the points on the white pixels will be shifted more.
And about the same we will do in the fragment shader, only a little differently. We take the gradient texture shown on the right:

And the whiter the pixel, the higher we read, and the darker the pixel that hits, the lower.
And each frame will slightly shift the reading zone and loop it. As a result, an animated fireball will turn out from the usual sphere:

The use of these shaders has turned the world of computer graphics, because it has opened up great opportunities for creating cool effects by writing 30-40 lines of code.
This whole process is repeated several times, for each object on the screen. In the following example, you can note that the GPU does not know how to draw fonts, because it lacks accuracy, and each character is represented using two triangles that stretch the texture of the letter:

After that, a frame is obtained.
Now let's talk about what Apple provides us as a vendor not only software, but also hardware.

In general, everything was always good with us: from the very first iPhone, the OpenGL ES standard is supported, this is a subset of the desktop OpenGL for mobile platforms. Already on the first iPhones appeared 3D-games, which in terms of graphics were comparable to the PlayStation 2, and everyone began to talk about the revolution.

In 2010, iPhone 4 was released. There was already the second version of the standard, and Epic Games really boasted of their Infinity Blade game, which caused a lot of noise.
And in 2016, the third version of the standard was released, which turned out to be not particularly interesting to anyone.

Why? During this time, a lot of frameworks for the ecosystem have been released, low-level, open-source - engines from Apple itself, engines from large vendors:

In 2015, Khronos, which certifies the OpenGL standard, announced Vulkan, the next generation of graphics APIs. And initially, Apple was part of the working group for this API, but left it. Mainly due to the fact that OpenGL, contrary to a common misconception, is not a library, but a standard. That is, roughly speaking, this is a large protocol or interface that says that there should be such functions on the device that do this and that with iron. And the vendor must implement them himself.
And since Apple is famous for its tight integration of software and hardware, any standardization causes certain difficulties. Therefore, instead of supporting Vulkan, the company in 2014 announced Metal, as if hinting at its name "very close to iron."

It was a graphics API made exclusively for Apple's hardware. Now it’s clear that this was done to release their own GPUs, but at that time there were only rumors about it. Now there are no devices left that do not support Metal.
The diagram from Apple itself shows a comparison of the overhead - even compared to OpenGL, Metal's performance is much better, access to the GPU is much faster:
there were all the latest features like tessellations, we won’t examine them in detail now. The main idea was to shift most of the work to the initialization phase of the application and not do many repetitive things. Another important feature is that this API is very careful about the CPU time you have.

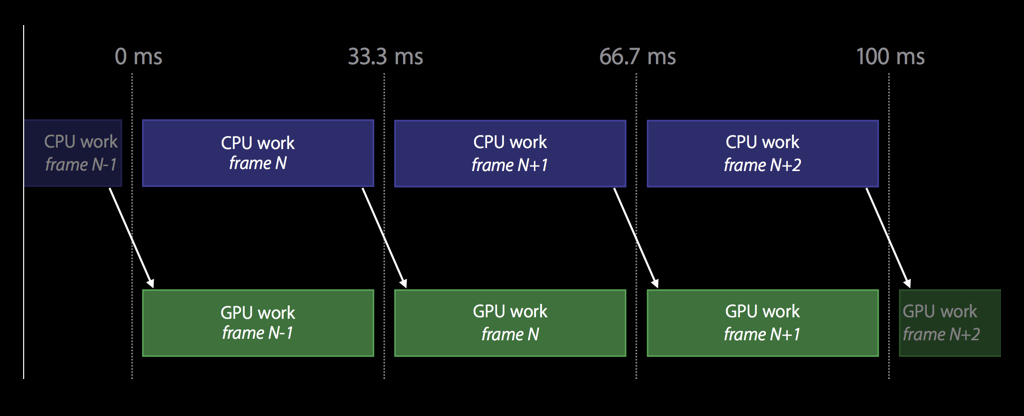
Therefore, unlike OpenGL, the work here is arranged so that the CPU and GPU work in parallel with each other. While the CPU is reading frame number N, at that time the GPU renders the previous frame N-1, and so on: you don’t need to synchronize, and while the GPU is rendering something, you can continue to work on something useful.
Metal has a fairly thin API, and this is the only graphical API that is object-oriented.
And just by API we will go through now. At its heart lies the MTLDevice class, which is a single GPU. Most often on iOS, it can be obtained using the MTLCreateSystemDefaultDevice function.

Despite the fact that it is received through a global function, you do not need to treat this class as a singleton. On iOS, there is really only one video card, but on the Mac there is also Metal, and there can be several video cards, and you want to use some specific one: for example, integrated, to save the user's battery.
Keep in mind that Metal is very different in architecture from all other Apple frameworks. It has a cross-cutting dependency injection, that is, all objects are created in the context of other objects, and it is very important to follow this ideology.
Each device has its own MTLCommandQueue program queue, which can be obtained using the makeCommandQueue method.
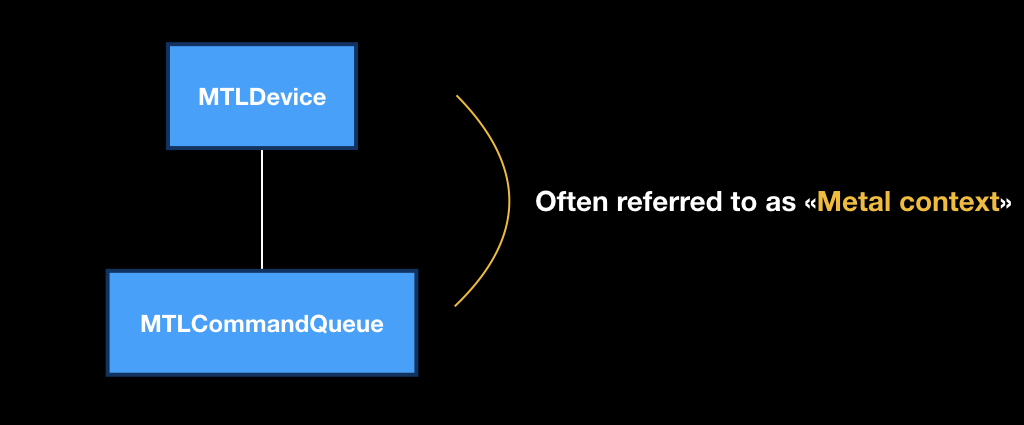
This pair from the device and the software queue is very often called the “Metal context", that is, in the context of these two objects we will do all our operations.
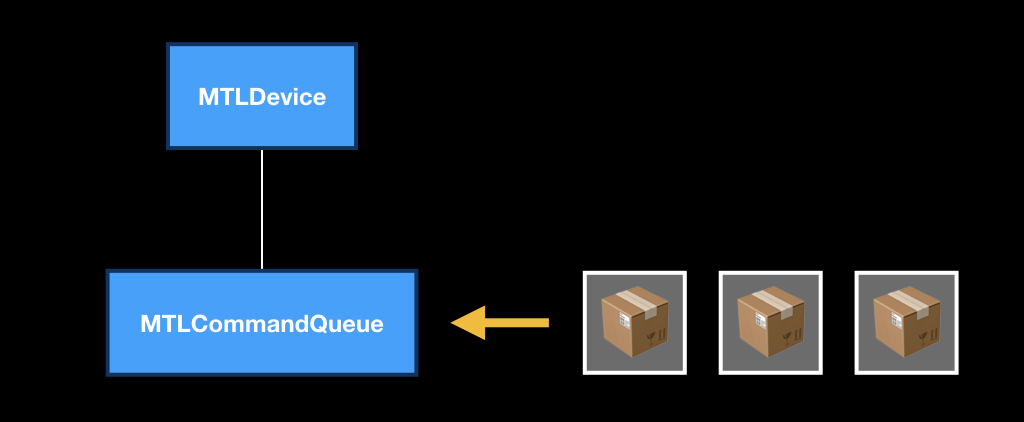
MTLCommandQueue itself works like a regular queue. “Boxes” come into it, in which there are instructions “what to do with the GPU”. As soon as the device is released, the next box is taken, and the rest are pushed. At the same time, not only you from your stream are putting commands in this queue: iOS itself, some UIKit frameworks, MapKit, and so on are also putting them.
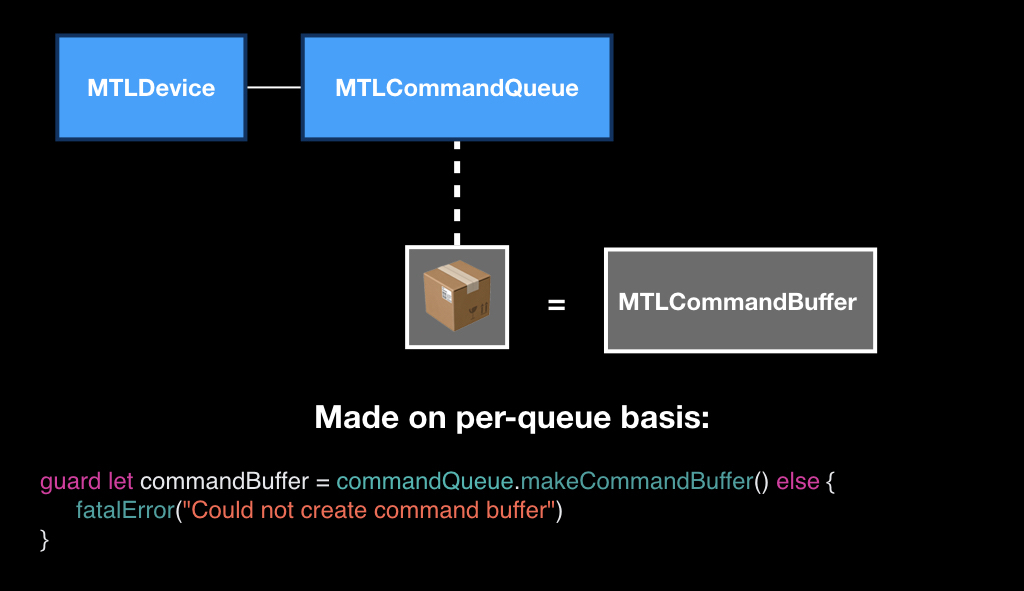
These boxes themselves represent the MTLCommandBuffer class, and they are also created in the context of the queue, that is, each queue has its own empty boxes. You call a special method, as if to say: "give us an empty box, we will fill it."
You can fill this box with three types of commands. Render commands for rendering primitives. Blit commands are commands for streaming data when we need to transfer part of the pixels from one texture to another. And with compute-commands, we'll talk about them a little later.
In order to put these commands in a box, there are special objects, each type of command has its own:
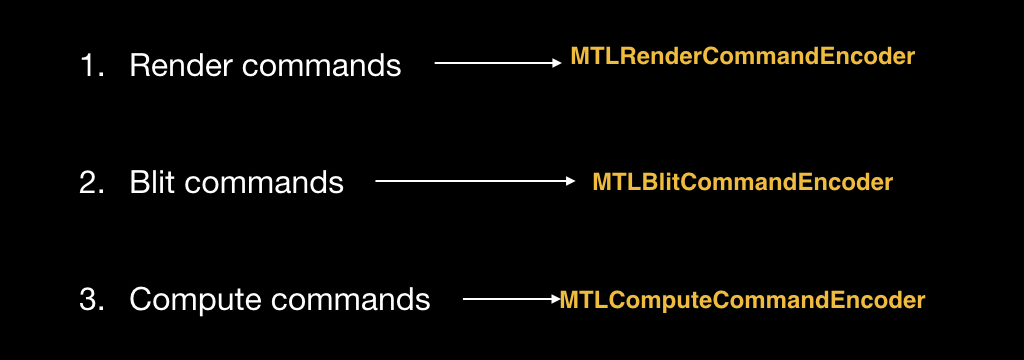
Objects are also created in the context of the box. That is, we get a box from the queue, and in the context of this box we create a special object called Encoder. In this example, we will create an Encoder for the render team, because it is the most classic.
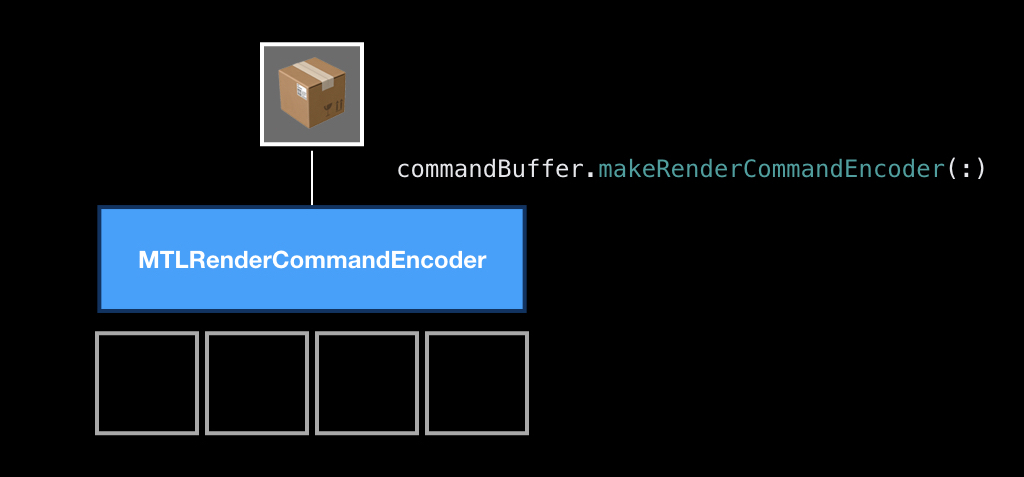
The process of encoding teams in itself is very similar to the process of crafting in games. That is, when you encode, you have slots, you put something there and craft a command from them.
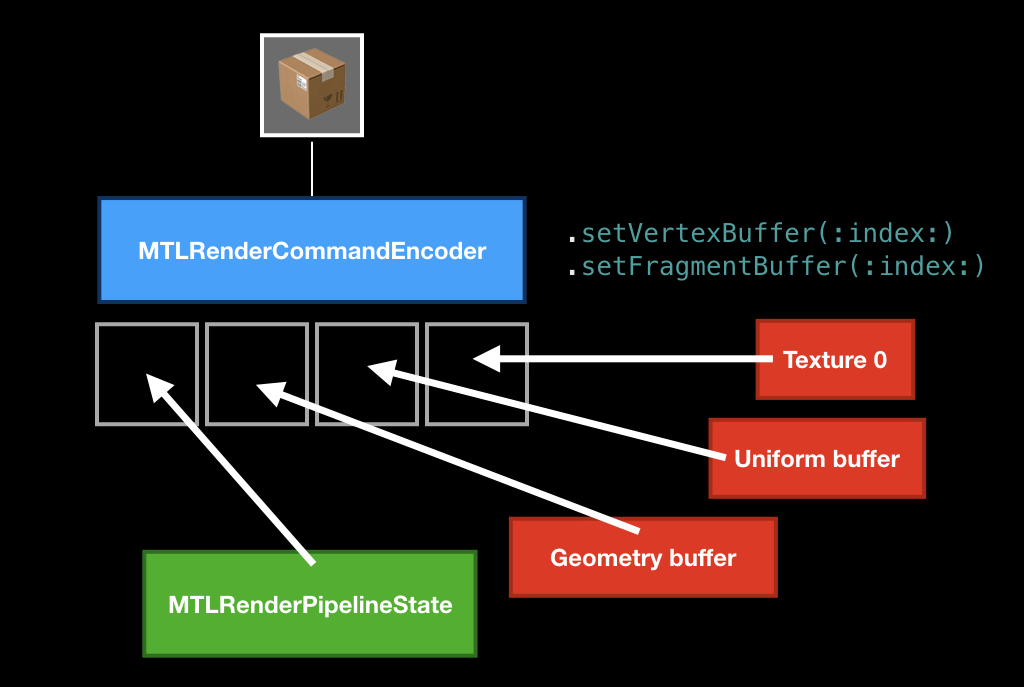
The main ingredient that must be required is the pipeline state, an object that describes the state of the video card in which it needs to be converted to draw your primitives.

The main characteristic of this state is a unique pair of vertex shaders and fragment shaders, but there are still some parameters that can be changed, or not changed. More often than not (and Apple recommends doing this) you should cache this pipeline state somewhere at the beginning of the application, and then just reuse it.
It is created using a descriptor - this is a simple object in which you write the necessary parameters into fields.

And then with the help of the device you create this pipeline state:

We put it, then most often we put some kind of geometry that we want to draw using special methods, and optionally we can put some uniforms (for example, in the form of the same time, about which we talked about today), convey textures and more.
After that, we call the drawPrimitives method, and the command is put in our box.
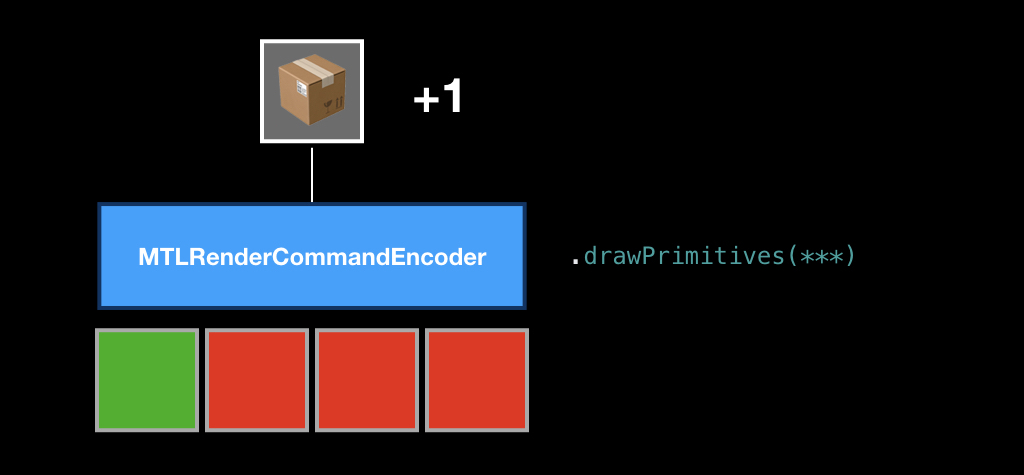
Then we can replace some ingredients, put another geometry or another pipeline state, call this method again, and another command appears in our box.
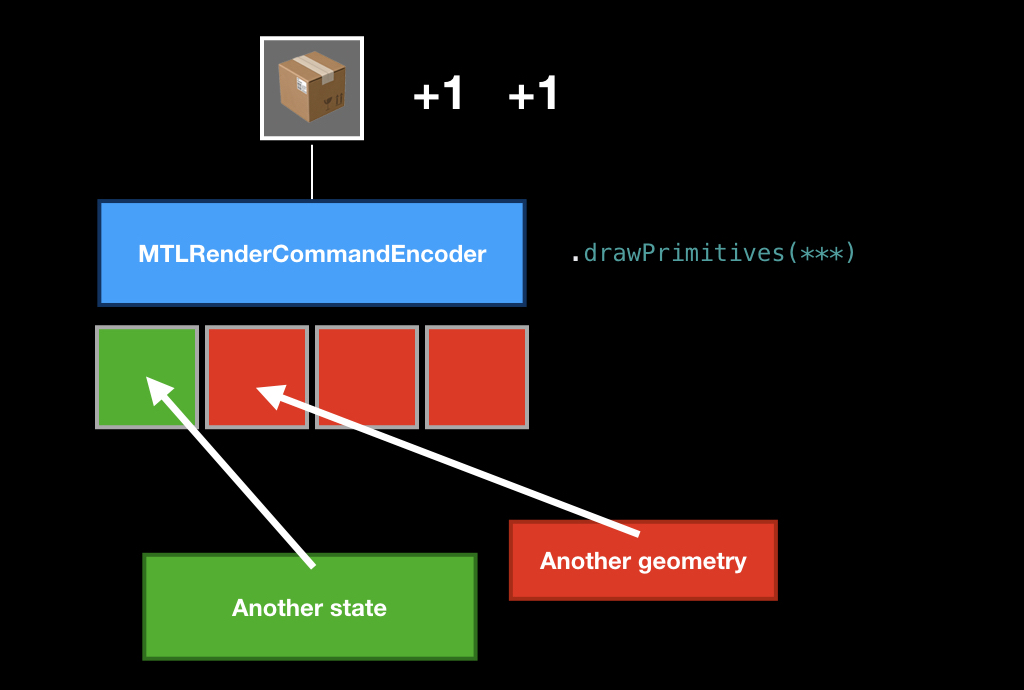
Once we have encoded all the commands in our frame, we call the endEncoding method, and this box closes.
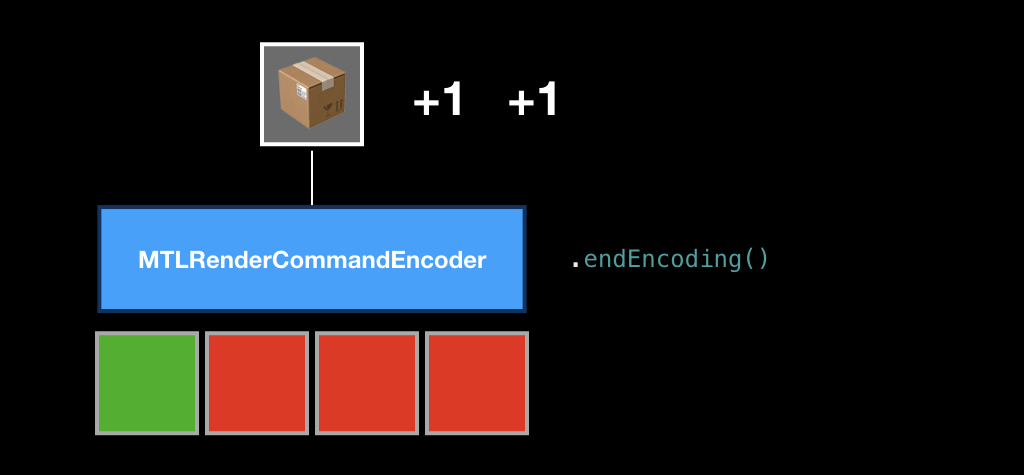
After that, we send the box to our turn using the commit method, and from that moment on, its fate is unknown to us. We don’t know when it will start to run, because we don’t know how much the GPU is loaded now and how many teams are in the queue. In principle, you can call the synchronous method, which will make the CPU wait until all the commands inside the box are executed. But this is a very bad practice, therefore, as a rule, you need to subscribe to addCompletionHandler, which will be called asynchronously at the moment when each of the commands in this box is executed.
I think it is unlikely that many in the audience came to this report for the sake of rendering. Therefore, we will look at a technology such as Metal Compute Shaders.

To understand what it is, you need to understand where it all came from. Already in 1999, as soon as the first GPUs appeared, scientific studies began to appear on how video cards can be used for general tasks (that is, for tasks not related to computer graphics).

You have to understand that then it was hard: you had to have a PhD in computer graphics in order to do this. Then, financial companies hired game developers to analyze data, because only they could figure out what was going on.
In 2002, Stanford graduate Mark Harris founded the GPGPU website and invented the term General Purpose GPU, that is, a general purpose GPU.
At that time, it was mainly scientists who were interested in shifting tasks from chemistry, biology and physics to something that could be represented in the form of graphics: for example, some chemical reactions that could be represented in the form of textures and somehow considered progressively.
It worked a little clumsy. All data was written to textures and then somehow interpreted in a fragment shader.
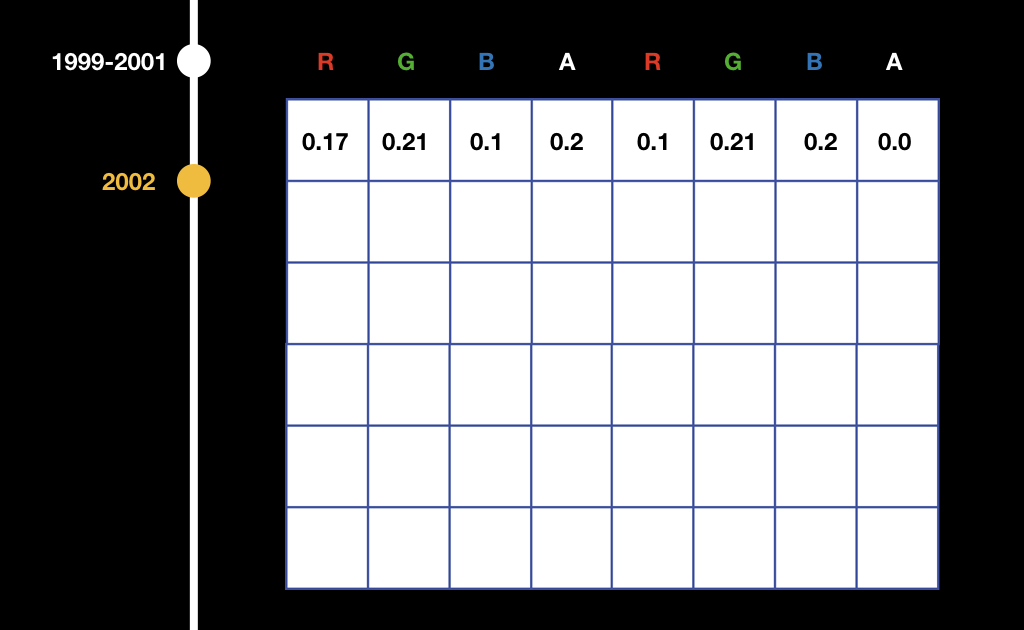
That is, for example, if we have an array from float, we write it to the texture per channel: we write the first number in the red channel of the first pixel, we write the second in the green channel of the first pixel, and so on. Then in the fragment shader it was necessary to read and watch this: if we render the leftmost upper pixel, then we do one thing, if we render the rightmost upper pixel, another, etc.
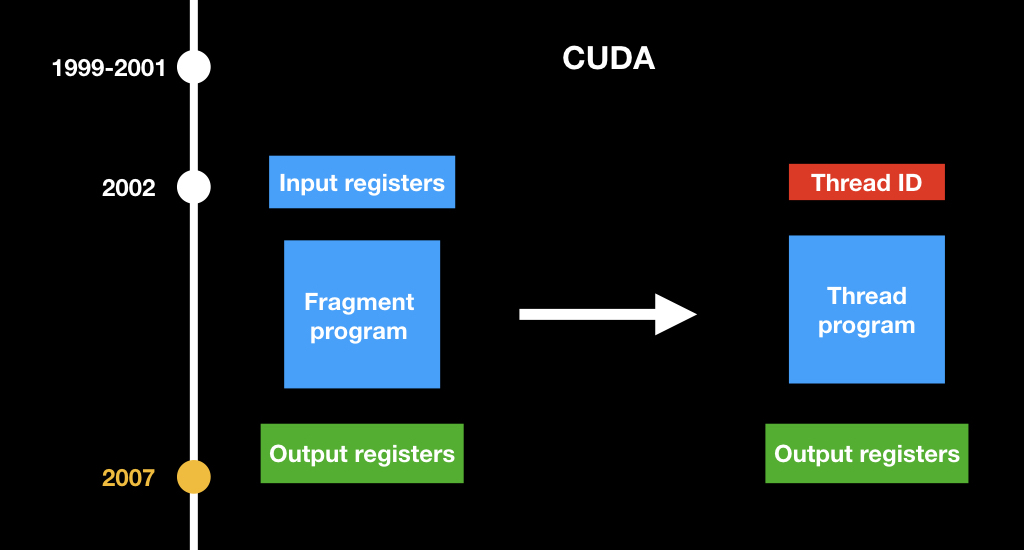
All this was difficult until CUDA appeared. Surely many of you have come across this abbreviation. CUDA is also a NVidia project introduced in 2007. This is such a C ++-like language that allowed the GPU to write general-purpose programs and do some calculations that are not related to computer graphics.

The most important concept that they changed: they invented a new kind of program. If there used to be fragment shaders that take the pixel coordinate as an input, now there is just some kind of abstract program that takes just the index of its stream and considers a certain part of the data.
Actually, the same technology is implemented in Metal Compute Shaders. These are the same shaders that are on the desktop GPU, they work the same as fragment and vertex ones, that is, they run in parallel. There is a special kernel keyword for them. They are suitable only for tasks that at the level of the algorithm lend themselves very much to parallelization and can lie in the same command buffer, that is, in the same box with other commands. You may first have a render command, then a compute command, and then a render command that uses the results of the compute command.

In order to show how Metal Compute Shaders work, we will make a small demo. The scenario is pretty close to reality. I work in an AI company and it often happens that R&D people come and say that something needs to be done with this buffer. We will simply multiply it by a number, but in real life you need to apply some function. This task is very suitable for parallelization: we have a buffer, and we need to multiply each number independently from each other by a constant.
We will write our class in the Metal paradigm, so it will accept a link to either MTLDevice or MTLCommandQueue in the constructor as an dependency injection.

In our constructor, we will cache all this and create at the beginning of the initialization of the pipeline state with our kernel, which we will write later.

After that, prepare the types. We need only one type of Uniforms - it will be a structure that stores the constant by which we will multiply, and a count field that stores the number of elements that we need to count.

You have to be very careful with this. Many, especially C ++ programmers, know what data alignment is when the compiler changes the sequence of your fields in a structure or class, or, for example, changes the markup in order to read them byte most efficiently. And Swift does the same, so when you declare your types in Swift, you need to be very careful. Metal uses C ++ type markup, and it may not coincide with Swift, so it’s good practice when you describe these types somewhere in the same C / C ++ header, and then fiddle these descriptions between the teams.

We just need to implement one method, which will take our array as input and the number by which we will need to multiply. At the same time, we have already cached our device, queue and pipeline state.
The first thing we will do is take our device and use it to create two buffers that we will transmit to the GPU.
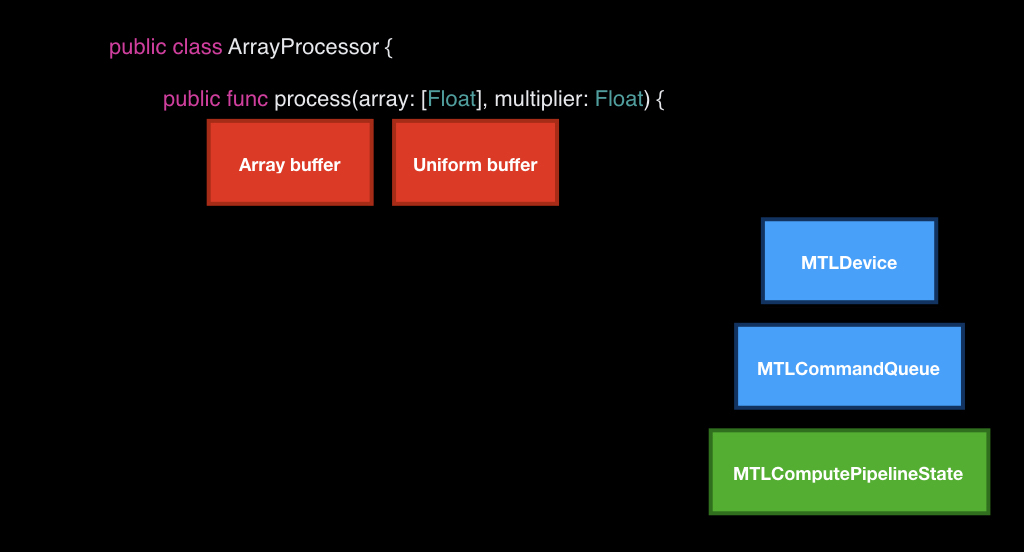
We cannot just transfer data; we need to create special objects using the device. We put bytes from our array and create a structure from the uniform, where we put the count field from the array and our arrived constant.
After that, in the queue we take an empty box. We take a special encoder for the compute-command and load it all there.

The question is what we will do next. If we called drawPrimitives in render commands, then everything was clear, but how to create a command for Сompute Shader? To do this, you need to get acquainted with such a concept as threads and thread groups.
All Compute Shaders run on top of such a grid, it can be one-dimensional, two-dimensional and three-dimensional, it looks like arrays to make it easier to represent. Each element of this grid is an instance of your function, which takes an input coordinate in this grid. That is, if the grid is one-dimensional, then this is just an index, if it is two-dimensional, then, of course, it is two-dimensional. Such an instance is called thread, that is, "thread." But, as a rule, there is a lot of data, and the GPU cannot run them all at once in parallel, so most often they are organized into groups and run in groups.

For example, we want to start one thread for each pixel in our picture, and we will make a thread group of 32x16 threads that will process the image in such rectangles, where for each pixel our own thread will be launched:

Subsequently, in the shader code, we can get the current index our stream, and process either the necessary pixel (as in this case), or some part of the data, depending on your business logic.

There are two ways to split a thread group. The first is to entrust it to Apple. This is a bad idea, because more often it is inefficient, and sometimes it does not even allow the algorithm. Often, algorithms, such as blur, require exactly 3x3 thread groups. Many algorithms require all thread groups to be the same size. And Apple independently splits the trade groups so that they completely contain the data, and if the amount of your data is not completely divided, the size of the trade groups will vary:
Therefore, most often you choose the size of the trade group yourself, and make it so that if it is impossible to divide there were more threads than your data:

It is also important to know how thread groups work. Inside, they are launched according to the SIMD principle, that is, Single Instruction Multiple Data. All threads synchronously execute the same set of machine instructions, only they accept different data at the input, that is, they take a step synchronously. And the problems begin if one of your threads has a branch.

If the GPU figured out which branch was correct, everyone else would have to wait. Instead, the GPU executes both branches: no matter how much if there is, all the code is executed so that all this works in parallel. Therefore, branching in the SIMD code is very bad, and it is important to minimize it. There are mathematical techniques that, in certain cases, help to avoid this.
The very partition into SIMD groups is beyond our control, we can only know the so-called computation width, that is, how many threads can be contained in a SIMD group at a time. This is necessary for cases when we need to split data as efficiently as possible. Sometimes we break into streams according to the algorithm, as in the above example with blur, and sometimes we just need to do it as efficiently as possible, and we use the width for this.

We take it from the pipeline state, count the number of thread groups, that is, take the count of our buffer, add a minus 1 width to it, and divide by that width. This is a simple formula to make sure it comes with a margin. And we count the number of threads in one group.

We call this dispatchThreadgroups method, in which we transfer the number of thread groups and the number of threads in each group.

After that, our box flies to the GPU. And the last step is to write the shader itself. It receives a buffer at the input, a pointer to the beginning of the float of our uniform in the form of a structure, and the thread index is the index of the thread that is now starting.

The first thing we must do is to check that we are not going beyond our buffer (if so, then we will return immediately). Otherwise, we read the desired element, that is, each stream reads only one element. We read it and write back already multiplied.
Benchmark what happened. We will have an array with a million elements, each of which contains a unit, and a constant by which we will multiply. We will compare here with how the same task would be solved on the CPU (this would be solved in three lines):

Let's hope it's faster. And indeed it is: Metal performs on average in 0.006 seconds, and CPU in 0.1. That is, the CPU is about 17 times slower, which should please us.

But the results will change slightly if we replace a million elements with a thousand. In this case, Metal finished twice as fast as with a million. But the CPU finished exactly 1000 times faster, because the elements became exactly 1000 times smaller. And now the CPU is 30 times faster than the GPU.

This factor must be taken into account: even your algorithm is perfectly parallel, but it is not labor-intensive enough, the overhead costs when transferring work from the CPU to the GPU can be so great that all this will not make sense. And it will not be necessary to write so much code, it will be enough to write three lines on the CPU. But you will never know until you try. Assessing this in advance is very difficult.
In general, the tips are:

Based on Metal Compute Shaders, the Metal Performance Shaders framework was created. It was announced back in iOS 9, and initially it was a set of some general-purpose tasks - for example, transfer your picture to grayscale. They were super-optimized, each iPhone had its own shader, Metal has private APIs, and everything worked super-fast.

In iOS 10, they added support for neural networks. It so happened that now all artificial intelligence and all machine learning is just a multiplication of matrices. And the inference of neural networks is just perfect for doing this on the GPU.

Therefore, this framework is now often called MPSCNN: it is used for the inference of neural networks, and allowed companies, including ours, to use computing on the device, and not in the cloud.
But the code was very scary. Not complicated, but very cumbersome. For example, to encode some kind of mesh in the style of Inception-v3, you need about 1000 lines of the same type of code:

That is, ideologically it is not complicated, but it is very easy to get confused in it. Therefore, in iOS 11, in addition to the second Metal, several new frameworks were launched.
One of them is the NN Graph API, which allows you to very conveniently build a graph of your neural network calculations and then simply transfer the ready-made box, that is, the command buffer, directly to the GPU.

After that they announced CoreML, which made a lot of noise and with which you probably already heard all your ears, but I’ll say a few words anyway.
Its main drawback and advantage at the same time is that it is proprietary. It works quite quickly, that is, with an implementation that you can write yourself using MPS, the speed is approximately comparable. But CoreML uses its internal analytics to understand where to run the code - on the GPU or CPU. He evaluates overhead by some heuristics and sometimes, when he realizes that it is inexpedient to send work to the GPU, he believes on the CPU. And this is both cool and not, because you do not have control over this, you do not know what will happen and where your grid will be considered in the end.

The advantage is that it is very easy to use. A lot of desktop frameworks are supported. If your company is engaged in machine learning, most often you have an R&D team that teaches your grids on some accessible framework in the style of TensorFlow, Torch or something similar. And before the Apple solutions appeared, everyone had their own approaches - for example, there was some kind of encoder that takes JSON and collects your neuron in Metal in runtime. And now CoreML does it.
Another advantage is that it works fast enough. But at the same time, it does not lend itself to customization. If you need to implement some kind of custom operator in your neuron, you will not be able to do this. Therefore, CoreML is suitable only for a narrow class of tasks, mainly for long-solved problems - in the style of classification and other things, that is, neural networks that can already be found on the Internet for a long time. Sometimes he bugs, and seriously. It's raw enough, at least judging by our experience, and we will report a lot of bugs. And you have no control over what is happening under the hood. In general, the final conclusions are as follows:

When Andrei Volodin (Prisma AI) talked about using the GPU in iOS at the Mobius 2017 Moscow conference, his report became one of the conference’s favorites, receiving high marks from the audience. And now, on the basis of this report, we have prepared a hubrapost, which allows you to get all the same information in text. It will be interesting even to those who do not work with iOS: the report begins with things that are not specifically tied to this platform.
Caution, traffic: there are a lot of images from slides under the cut.
The plan is this. First, let's look at the history of computer graphics: how it all began and how we came to what is now. Then we’ll figure out how rendering is done on modern video cards. What Apple offers us as an iron vendor. What is GPGPU. Why Metal Compute Shaders is a cool technology that has changed everything. And at the very end, let's talk about hype train, that is, popular now: Metal Performance Shaders, CoreML and the like.
Let's start with the story
The first known system with a separate hardware for video was the Atari 2600. This is a fairly well-known classic game console, released in 1977. Its feature was that the amount of RAM was only 128 bytes, and not only available to the developer: it was for the game, and for the operating system of the console itself, and for the entire call stack.
On average, games were rendered at a resolution of 160x192, and the palette had 128 colors. It is easy to calculate that storing one frame of the game required many times more RAM. Therefore, this console went down in history as one big hack: all the graphics in it were generated in real time (in the literal sense of the word).
At that time, TVs worked with beam guns, through electronic heads. The image was scanned line by line, and the developers should, as the TV scanned the image through an analog cable, tell him what color of the current pixel to draw. Thus, the image appeared on the screen completely.
Another feature of this console was that at the iron level it supported only five sprites at a time. Two sprites for the player, two for the so-called "rockets" and one sprite for the ball. It’s clear that for most games this is not enough, because there are usually more interactive objects on the screen.
Therefore, the technique was used there, which later went down in history under the name "race with the beam." As the beam scanned the image from the set-top box, those pixels that were already drawn remained on the screen until the next frame. Therefore, the developers moved the sprites while the beam was moving, and thus could draw more than five objects on the screen.
This is a screenshot from the famous Space Invaders game, in which there are more than five interactive objects. In exactly the same way effects like parallax (with wave-like animations) and others were drawn. The book Racing the Beam was written based on all this fever . And from it I took this curious illustration:
The fact is that the TV scanned the image non-stop, and the developers did not have time to read the click on the joystick, to calculate some kind of game logic, etc. Therefore, the resolution was made higher than on the screen. And the “vertical blank”, “overscan” and “horizontal blank” zones are a fake resolution that the TV scanned, but at that time there was no video signal, and the developers considered the game logic. And in Activision's Pitfall game, the logic was so complicated at the time that they had to draw more tree crowns at the top and black earth at the bottom all the time to have more time to calculate it.
The next stage of development was the Nintendo Entertainment System in 1983, and there were similar problems: there was already an 8-bit palette, but still there was no frame buffer. But there was PPU (picture processing unit) - a separate chip that was responsible for the video sequence, and tile graphics were used there. Tiles are such pieces of pixels, most often they were 8x8 or 8x16. Therefore, all the games of that period look a little square:
The system scanned the frame with such blocks and analyzed which parts of the image should be drawn. This allowed us to seriously save video memory, and collision detection “out of the box” was an additional plus. Gravity appeared in games, because it was possible to understand which squares intersected with which ones, it was possible to collect coins, take lives when we were in contact with enemies, and so on.
Subsequently, 3D graphics began, but at first it was insanely expensive, mainly used in flight simulators and some enterprise solutions. It was considered on such terrible, huge chips and it didn’t reach ordinary consumers.
The well-known company NVidia in 1999 with the release of a new device introduced the term GPU (graphics processing unit). At that time, it was a very highly specialized chip: it solved a number of tasks that made it possible to slightly accelerate 3D graphics, but it could not be programmed. You could only say what to do, and he returned the answer using some pre-built algorithms.
In 2001, the same NVidia released GeForce 3 with the GeForceFX package, in which shaders first appeared. We will definitely talk about them today. It was this concept that turned all computer graphics upside down, although at that time it was still programmed in assembler and it was quite complicated.
The main thing that happened after that was a trend. You have probably heard about such a metric of iron performance as flops. And it became clear that over time, video cards, as compared to central processors, simply fly into space in terms of performance:
Moreover, if we look at their specifications, we will see that literally in a year the number of transistors increased by 2 times, while the clock frequency of each of them decreased, but the overall performance increased by almost 7 times. This suggests that a bet was made on parallel computing.
Rendering today
To understand why the GPU needs to be counted so much in parallel, let's see how rendering is now on most video cards - both desktop and mobile.
For many of you, it can be a major disappointment that the GPU is a very dumb piece of hardware. She can only draw triangles, lines and points, nothing else. And it is very optimized for working with floating point numbers. It does not know how to count double and, as a rule, works very poorly with int. There are no abstractions on it in the form of an operating system and other things. It is as close to iron as possible.
For this reason, all 3D objects are stored as a set of triangles, on which the texture is most often stretched. These triangles are often called polygons (those who play games are familiar with words like “there are twice as many polygons in the Kratos model”).
In order to render this all, these triangles are first placed in the game world. The game world is an ordinary three-dimensional coordinate system, where we put them, and each object has, as a rule, its own position, rotation, distortion, etc.
Often there is such a concept as a camera, when we can look at the game world from different angles. But it’s clear that in fact there is no camera there, and in reality it’s not the camera that moves, but the whole game world: it turns to the monitor so that you see it from the right angle.
And the last stage is the projection, when these triangles get on your screen.
For all this, there is a wonderful mathematical abstraction in the form of affine transformations. Whoever worked with UIKit is familiar with this concept thanks to CGAffineTransform, all animations are made through it. There are different matrices of affine transformations, here for scale, for rotation and for transfer:
They work like this: if you multiply the matrix by some vector, then the transformation will apply to it. For example, when translating, the translation matrix shifts the vector.
And another interesting fact associated with them: if you multiply several such matrices, and then multiply them by a vector, then the effect accumulates. If at first there is a scale, then a rotation, and then a transfer, then when applying all this to the vector, all this is done immediately.
In order to do this efficiently, vertex shaders were invented. Vertex shaders are such a small program that runs for every point in your 3D model. You have triangles, each with three points. And for each of them, a vertex shader is launched, which takes the input position of the vector in the coordinate system of the 3D model, and returns it in the coordinate system of the screen.
Most often, this works as follows: for each object, we calculate a unique transformation matrix. We have a camera matrix, a world matrix and an object matrix, we multiply them all and give them to the vertex shader. And for each vector he takes, multiplies it and returns a new one.
Our triangles appear on the screen, but this is still a vector graphic. And then the rasterizer is included in the game. It does a very simple thing: it takes pixels on the screen and superimposes a pixel grid on your vector geometry, choosing those pixels that intersect with your geometry.
After that, fragment shaders are launched. Fragment shaders are also a small program, it starts already for each pixel that falls into the area of your geometry, and returns the color, which will subsequently be displayed on the screen.
In order to explain how this works, imagine that we will draw two triangles that cover the entire screen (just for clarity).
The simplest fragment shader that you can write is a shader that returns a constant. For example, the color is red and the entire screen turns red. But this is boring enough.
Fragment shaders take the pixel coordinate as input, so we can, for example, calculate the distance to the center of the screen, and use this distance as a red channel. Thus, a gradient appears on the screen: the pixels close to the center will be black, because the distance will tend to zero, and at the edges of the screen will be red.
Further we can add, for example, a uniform. A uniform is a constant that we pass to the fragment shader, and it applies it the same for each pixel. More often than not, time becomes such a uniform. As you know, time is stored in the form of the number of seconds from a certain moment, so we can count the sine from it, getting some value.
And if we multiply our red channel by this value, we get a dynamic animation: when the sine of time goes to zero, everything turns black, when one - returns to its place.
Shader writing itself has grown into a whole culture. These images are drawn using mathematical functions:
They do not use 3D models or textures. This is all pure math.
In 1984, someone Paul Hackbert even launched a challenge, when he handed out business cards with a code, by running which you could get this picture:
And this challenge is still alive at SIGGRAPH, CVPR, major conferences in California. You can still see business cards that print something.
But it is unlikely that all of this has entered the masses only because it is beautiful. And in order to understand what opportunities this all opens up, we will see what can be done with the ordinary sphere. Suppose we have a 3D model of a sphere (it’s clear that this is actually not a sphere, but many triangles that form a ball with some degree of approximation). We’ll take such a texture, which is often called smooth noise:
These are just some random pixels that gradually flow from white to black. We will pull this texture onto our ball, and in the vertex shader we will do the following: the points that fall on the darker pixels will be shifted weaker, and the points on the white pixels will be shifted more.
And about the same we will do in the fragment shader, only a little differently. We take the gradient texture shown on the right:
And the whiter the pixel, the higher we read, and the darker the pixel that hits, the lower.
And each frame will slightly shift the reading zone and loop it. As a result, an animated fireball will turn out from the usual sphere:
The use of these shaders has turned the world of computer graphics, because it has opened up great opportunities for creating cool effects by writing 30-40 lines of code.
This whole process is repeated several times, for each object on the screen. In the following example, you can note that the GPU does not know how to draw fonts, because it lacks accuracy, and each character is represented using two triangles that stretch the texture of the letter:
After that, a frame is obtained.
What Apple provides
Now let's talk about what Apple provides us as a vendor not only software, but also hardware.
In general, everything was always good with us: from the very first iPhone, the OpenGL ES standard is supported, this is a subset of the desktop OpenGL for mobile platforms. Already on the first iPhones appeared 3D-games, which in terms of graphics were comparable to the PlayStation 2, and everyone began to talk about the revolution.
In 2010, iPhone 4 was released. There was already the second version of the standard, and Epic Games really boasted of their Infinity Blade game, which caused a lot of noise.
And in 2016, the third version of the standard was released, which turned out to be not particularly interesting to anyone.
Why? During this time, a lot of frameworks for the ecosystem have been released, low-level, open-source - engines from Apple itself, engines from large vendors:
In 2015, Khronos, which certifies the OpenGL standard, announced Vulkan, the next generation of graphics APIs. And initially, Apple was part of the working group for this API, but left it. Mainly due to the fact that OpenGL, contrary to a common misconception, is not a library, but a standard. That is, roughly speaking, this is a large protocol or interface that says that there should be such functions on the device that do this and that with iron. And the vendor must implement them himself.
And since Apple is famous for its tight integration of software and hardware, any standardization causes certain difficulties. Therefore, instead of supporting Vulkan, the company in 2014 announced Metal, as if hinting at its name "very close to iron."
It was a graphics API made exclusively for Apple's hardware. Now it’s clear that this was done to release their own GPUs, but at that time there were only rumors about it. Now there are no devices left that do not support Metal.
The diagram from Apple itself shows a comparison of the overhead - even compared to OpenGL, Metal's performance is much better, access to the GPU is much faster:
there were all the latest features like tessellations, we won’t examine them in detail now. The main idea was to shift most of the work to the initialization phase of the application and not do many repetitive things. Another important feature is that this API is very careful about the CPU time you have.
Therefore, unlike OpenGL, the work here is arranged so that the CPU and GPU work in parallel with each other. While the CPU is reading frame number N, at that time the GPU renders the previous frame N-1, and so on: you don’t need to synchronize, and while the GPU is rendering something, you can continue to work on something useful.
Metal has a fairly thin API, and this is the only graphical API that is object-oriented.
Metal API
And just by API we will go through now. At its heart lies the MTLDevice class, which is a single GPU. Most often on iOS, it can be obtained using the MTLCreateSystemDefaultDevice function.
Despite the fact that it is received through a global function, you do not need to treat this class as a singleton. On iOS, there is really only one video card, but on the Mac there is also Metal, and there can be several video cards, and you want to use some specific one: for example, integrated, to save the user's battery.
Keep in mind that Metal is very different in architecture from all other Apple frameworks. It has a cross-cutting dependency injection, that is, all objects are created in the context of other objects, and it is very important to follow this ideology.
Each device has its own MTLCommandQueue program queue, which can be obtained using the makeCommandQueue method.
This pair from the device and the software queue is very often called the “Metal context", that is, in the context of these two objects we will do all our operations.
MTLCommandQueue itself works like a regular queue. “Boxes” come into it, in which there are instructions “what to do with the GPU”. As soon as the device is released, the next box is taken, and the rest are pushed. At the same time, not only you from your stream are putting commands in this queue: iOS itself, some UIKit frameworks, MapKit, and so on are also putting them.
These boxes themselves represent the MTLCommandBuffer class, and they are also created in the context of the queue, that is, each queue has its own empty boxes. You call a special method, as if to say: "give us an empty box, we will fill it."
You can fill this box with three types of commands. Render commands for rendering primitives. Blit commands are commands for streaming data when we need to transfer part of the pixels from one texture to another. And with compute-commands, we'll talk about them a little later.
In order to put these commands in a box, there are special objects, each type of command has its own:
Objects are also created in the context of the box. That is, we get a box from the queue, and in the context of this box we create a special object called Encoder. In this example, we will create an Encoder for the render team, because it is the most classic.
The process of encoding teams in itself is very similar to the process of crafting in games. That is, when you encode, you have slots, you put something there and craft a command from them.
The main ingredient that must be required is the pipeline state, an object that describes the state of the video card in which it needs to be converted to draw your primitives.
The main characteristic of this state is a unique pair of vertex shaders and fragment shaders, but there are still some parameters that can be changed, or not changed. More often than not (and Apple recommends doing this) you should cache this pipeline state somewhere at the beginning of the application, and then just reuse it.
It is created using a descriptor - this is a simple object in which you write the necessary parameters into fields.
And then with the help of the device you create this pipeline state:
We put it, then most often we put some kind of geometry that we want to draw using special methods, and optionally we can put some uniforms (for example, in the form of the same time, about which we talked about today), convey textures and more.
After that, we call the drawPrimitives method, and the command is put in our box.
Then we can replace some ingredients, put another geometry or another pipeline state, call this method again, and another command appears in our box.
Once we have encoded all the commands in our frame, we call the endEncoding method, and this box closes.
After that, we send the box to our turn using the commit method, and from that moment on, its fate is unknown to us. We don’t know when it will start to run, because we don’t know how much the GPU is loaded now and how many teams are in the queue. In principle, you can call the synchronous method, which will make the CPU wait until all the commands inside the box are executed. But this is a very bad practice, therefore, as a rule, you need to subscribe to addCompletionHandler, which will be called asynchronously at the moment when each of the commands in this box is executed.
In addition to rendering
I think it is unlikely that many in the audience came to this report for the sake of rendering. Therefore, we will look at a technology such as Metal Compute Shaders.
To understand what it is, you need to understand where it all came from. Already in 1999, as soon as the first GPUs appeared, scientific studies began to appear on how video cards can be used for general tasks (that is, for tasks not related to computer graphics).
You have to understand that then it was hard: you had to have a PhD in computer graphics in order to do this. Then, financial companies hired game developers to analyze data, because only they could figure out what was going on.
In 2002, Stanford graduate Mark Harris founded the GPGPU website and invented the term General Purpose GPU, that is, a general purpose GPU.
At that time, it was mainly scientists who were interested in shifting tasks from chemistry, biology and physics to something that could be represented in the form of graphics: for example, some chemical reactions that could be represented in the form of textures and somehow considered progressively.
It worked a little clumsy. All data was written to textures and then somehow interpreted in a fragment shader.
That is, for example, if we have an array from float, we write it to the texture per channel: we write the first number in the red channel of the first pixel, we write the second in the green channel of the first pixel, and so on. Then in the fragment shader it was necessary to read and watch this: if we render the leftmost upper pixel, then we do one thing, if we render the rightmost upper pixel, another, etc.
All this was difficult until CUDA appeared. Surely many of you have come across this abbreviation. CUDA is also a NVidia project introduced in 2007. This is such a C ++-like language that allowed the GPU to write general-purpose programs and do some calculations that are not related to computer graphics.
The most important concept that they changed: they invented a new kind of program. If there used to be fragment shaders that take the pixel coordinate as an input, now there is just some kind of abstract program that takes just the index of its stream and considers a certain part of the data.
Actually, the same technology is implemented in Metal Compute Shaders. These are the same shaders that are on the desktop GPU, they work the same as fragment and vertex ones, that is, they run in parallel. There is a special kernel keyword for them. They are suitable only for tasks that at the level of the algorithm lend themselves very much to parallelization and can lie in the same command buffer, that is, in the same box with other commands. You may first have a render command, then a compute command, and then a render command that uses the results of the compute command.
Code time
In order to show how Metal Compute Shaders work, we will make a small demo. The scenario is pretty close to reality. I work in an AI company and it often happens that R&D people come and say that something needs to be done with this buffer. We will simply multiply it by a number, but in real life you need to apply some function. This task is very suitable for parallelization: we have a buffer, and we need to multiply each number independently from each other by a constant.
We will write our class in the Metal paradigm, so it will accept a link to either MTLDevice or MTLCommandQueue in the constructor as an dependency injection.
In our constructor, we will cache all this and create at the beginning of the initialization of the pipeline state with our kernel, which we will write later.
After that, prepare the types. We need only one type of Uniforms - it will be a structure that stores the constant by which we will multiply, and a count field that stores the number of elements that we need to count.
You have to be very careful with this. Many, especially C ++ programmers, know what data alignment is when the compiler changes the sequence of your fields in a structure or class, or, for example, changes the markup in order to read them byte most efficiently. And Swift does the same, so when you declare your types in Swift, you need to be very careful. Metal uses C ++ type markup, and it may not coincide with Swift, so it’s good practice when you describe these types somewhere in the same C / C ++ header, and then fiddle these descriptions between the teams.
We just need to implement one method, which will take our array as input and the number by which we will need to multiply. At the same time, we have already cached our device, queue and pipeline state.
The first thing we will do is take our device and use it to create two buffers that we will transmit to the GPU.
We cannot just transfer data; we need to create special objects using the device. We put bytes from our array and create a structure from the uniform, where we put the count field from the array and our arrived constant.
After that, in the queue we take an empty box. We take a special encoder for the compute-command and load it all there.
The question is what we will do next. If we called drawPrimitives in render commands, then everything was clear, but how to create a command for Сompute Shader? To do this, you need to get acquainted with such a concept as threads and thread groups.
All Compute Shaders run on top of such a grid, it can be one-dimensional, two-dimensional and three-dimensional, it looks like arrays to make it easier to represent. Each element of this grid is an instance of your function, which takes an input coordinate in this grid. That is, if the grid is one-dimensional, then this is just an index, if it is two-dimensional, then, of course, it is two-dimensional. Such an instance is called thread, that is, "thread." But, as a rule, there is a lot of data, and the GPU cannot run them all at once in parallel, so most often they are organized into groups and run in groups.
For example, we want to start one thread for each pixel in our picture, and we will make a thread group of 32x16 threads that will process the image in such rectangles, where for each pixel our own thread will be launched:
Subsequently, in the shader code, we can get the current index our stream, and process either the necessary pixel (as in this case), or some part of the data, depending on your business logic.
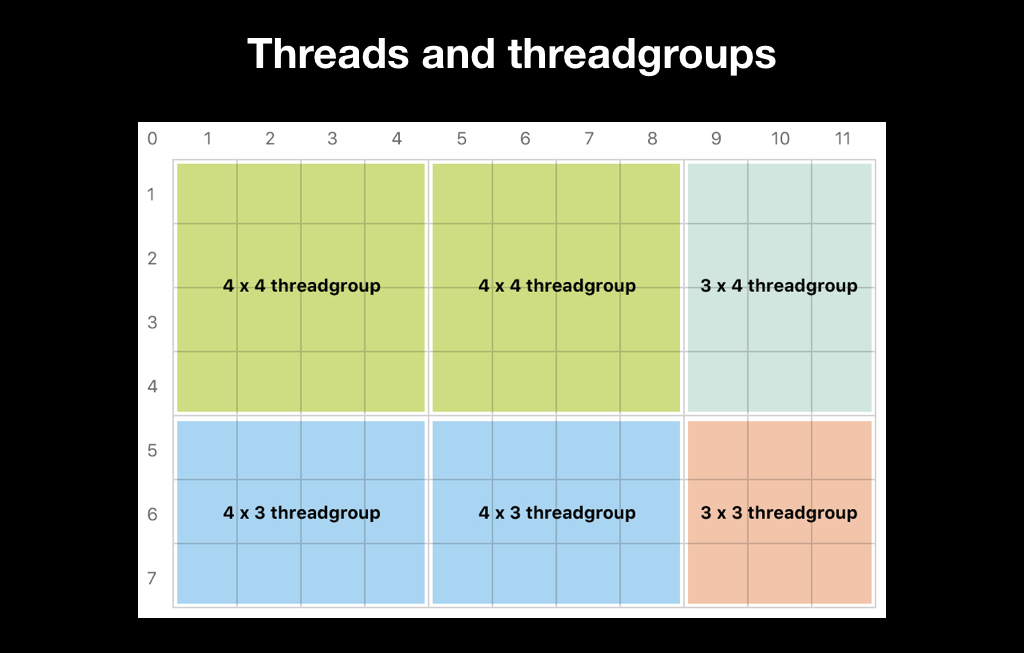
There are two ways to split a thread group. The first is to entrust it to Apple. This is a bad idea, because more often it is inefficient, and sometimes it does not even allow the algorithm. Often, algorithms, such as blur, require exactly 3x3 thread groups. Many algorithms require all thread groups to be the same size. And Apple independently splits the trade groups so that they completely contain the data, and if the amount of your data is not completely divided, the size of the trade groups will vary:
Therefore, most often you choose the size of the trade group yourself, and make it so that if it is impossible to divide there were more threads than your data:
It is also important to know how thread groups work. Inside, they are launched according to the SIMD principle, that is, Single Instruction Multiple Data. All threads synchronously execute the same set of machine instructions, only they accept different data at the input, that is, they take a step synchronously. And the problems begin if one of your threads has a branch.
If the GPU figured out which branch was correct, everyone else would have to wait. Instead, the GPU executes both branches: no matter how much if there is, all the code is executed so that all this works in parallel. Therefore, branching in the SIMD code is very bad, and it is important to minimize it. There are mathematical techniques that, in certain cases, help to avoid this.
The very partition into SIMD groups is beyond our control, we can only know the so-called computation width, that is, how many threads can be contained in a SIMD group at a time. This is necessary for cases when we need to split data as efficiently as possible. Sometimes we break into streams according to the algorithm, as in the above example with blur, and sometimes we just need to do it as efficiently as possible, and we use the width for this.
We take it from the pipeline state, count the number of thread groups, that is, take the count of our buffer, add a minus 1 width to it, and divide by that width. This is a simple formula to make sure it comes with a margin. And we count the number of threads in one group.
We call this dispatchThreadgroups method, in which we transfer the number of thread groups and the number of threads in each group.
After that, our box flies to the GPU. And the last step is to write the shader itself. It receives a buffer at the input, a pointer to the beginning of the float of our uniform in the form of a structure, and the thread index is the index of the thread that is now starting.
The first thing we must do is to check that we are not going beyond our buffer (if so, then we will return immediately). Otherwise, we read the desired element, that is, each stream reads only one element. We read it and write back already multiplied.
Benchmark what happened. We will have an array with a million elements, each of which contains a unit, and a constant by which we will multiply. We will compare here with how the same task would be solved on the CPU (this would be solved in three lines):
Let's hope it's faster. And indeed it is: Metal performs on average in 0.006 seconds, and CPU in 0.1. That is, the CPU is about 17 times slower, which should please us.
But the results will change slightly if we replace a million elements with a thousand. In this case, Metal finished twice as fast as with a million. But the CPU finished exactly 1000 times faster, because the elements became exactly 1000 times smaller. And now the CPU is 30 times faster than the GPU.
This factor must be taken into account: even your algorithm is perfectly parallel, but it is not labor-intensive enough, the overhead costs when transferring work from the CPU to the GPU can be so great that all this will not make sense. And it will not be necessary to write so much code, it will be enough to write three lines on the CPU. But you will never know until you try. Assessing this in advance is very difficult.
In general, the tips are:
- remember memory layout
- remember the overhead, which is always from transferring work to the GPU and getting results back
- avoid branching
- use a 16-bit float, if possible (there is a special type of half on the GPU for this)
- if possible we don’t use ints (GPUs are very difficult with them, it counts them through magic)
- correctly consider the size of the trade groups
- on the CPU side we cache everything correctly
- and never wait
Based on Metal Compute Shaders, the Metal Performance Shaders framework was created. It was announced back in iOS 9, and initially it was a set of some general-purpose tasks - for example, transfer your picture to grayscale. They were super-optimized, each iPhone had its own shader, Metal has private APIs, and everything worked super-fast.
In iOS 10, they added support for neural networks. It so happened that now all artificial intelligence and all machine learning is just a multiplication of matrices. And the inference of neural networks is just perfect for doing this on the GPU.
Therefore, this framework is now often called MPSCNN: it is used for the inference of neural networks, and allowed companies, including ours, to use computing on the device, and not in the cloud.
But the code was very scary. Not complicated, but very cumbersome. For example, to encode some kind of mesh in the style of Inception-v3, you need about 1000 lines of the same type of code:
That is, ideologically it is not complicated, but it is very easy to get confused in it. Therefore, in iOS 11, in addition to the second Metal, several new frameworks were launched.
One of them is the NN Graph API, which allows you to very conveniently build a graph of your neural network calculations and then simply transfer the ready-made box, that is, the command buffer, directly to the GPU.
After that they announced CoreML, which made a lot of noise and with which you probably already heard all your ears, but I’ll say a few words anyway.
Its main drawback and advantage at the same time is that it is proprietary. It works quite quickly, that is, with an implementation that you can write yourself using MPS, the speed is approximately comparable. But CoreML uses its internal analytics to understand where to run the code - on the GPU or CPU. He evaluates overhead by some heuristics and sometimes, when he realizes that it is inexpedient to send work to the GPU, he believes on the CPU. And this is both cool and not, because you do not have control over this, you do not know what will happen and where your grid will be considered in the end.
The advantage is that it is very easy to use. A lot of desktop frameworks are supported. If your company is engaged in machine learning, most often you have an R&D team that teaches your grids on some accessible framework in the style of TensorFlow, Torch or something similar. And before the Apple solutions appeared, everyone had their own approaches - for example, there was some kind of encoder that takes JSON and collects your neuron in Metal in runtime. And now CoreML does it.
Another advantage is that it works fast enough. But at the same time, it does not lend itself to customization. If you need to implement some kind of custom operator in your neuron, you will not be able to do this. Therefore, CoreML is suitable only for a narrow class of tasks, mainly for long-solved problems - in the style of classification and other things, that is, neural networks that can already be found on the Internet for a long time. Sometimes he bugs, and seriously. It's raw enough, at least judging by our experience, and we will report a lot of bugs. And you have no control over what is happening under the hood. In general, the final conclusions are as follows:
Minute of advertising. If you liked this report from last year's Mobius - note that Mobius 2018 Piter will be held in April . His program is already known, and there is also a lot of interesting things - both about iOS and Android.