First Steps in Machine Learning
Hi dear friend, have you always wanted to try machine learning, but the area looked mysterious and difficult? I would like to share with you my story about how I took the first steps in machine learning, with zero knowledge of Python and higher mathematics with a small example.
First, I went to the official TensorFlow website and read ML for Beginners and TensorFlow for beginners . Materials in English.
TensorFlow is a work of the Google team and the most popular machine learning library that supports Python, Java, C ++, Go, as well as the ability to use the computing power of a graphics card to calculate complex neural networks.
In my searches, I found another Python- oriented Scikit-learn machine learning library . Plus this library, in a large number of algorithms for machine learning right out of the box, which was an undoubted plus in my case, since the presentation was on Friday, and I really wanted to demonstrate the working model.
In search of ready-made examples, I came across a tutorial on determining the language in which the text is written using Scikit-learn.
So, my task was to train the model to determine the presence of SQL injection in a text string. (Of course, you can solve this problem with the help of regular expressions, but for educational purposes you canshoot guns at sparrows )
The type of problem that I am trying to solve is classification, that is, the algorithm should, in response to the fed data, give me to which of the categories this data belongs.
The data in which the algorithm will look for patterns are called features .
The category to which this or that feature belongs is called label . It is important to note that the input may have several features, but only one label.
In the classic example of machine learning, determining the varieties of iris flowers by the length of the pistils and stamens, each individual column with size information is a feature , and the last column, which means which of the subspecies of the iris, has a flower with such values, is label
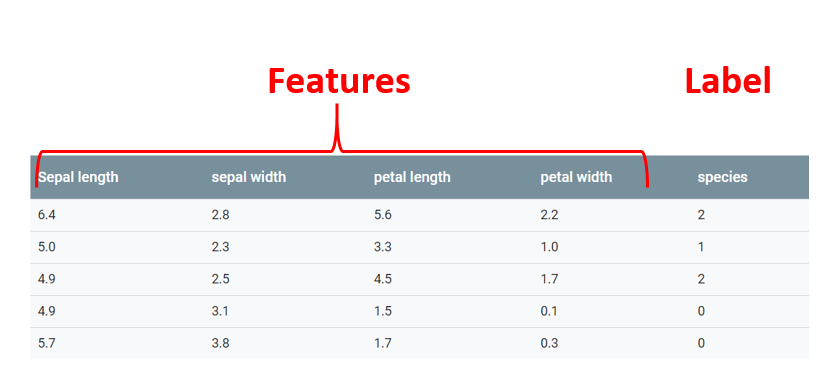
The way I will solve the classification problem is called supervised learning, or supervised learning. This means that in the learning process, the algorithm will receive both features and labels.
The number one step in solving any problem with the help of machine learning is the collection of data on which this machine will learn. In an ideal world, this should be real data, but, unfortunately, I could not find anything on the Internet that would satisfy me. It was decided to generate data independently.
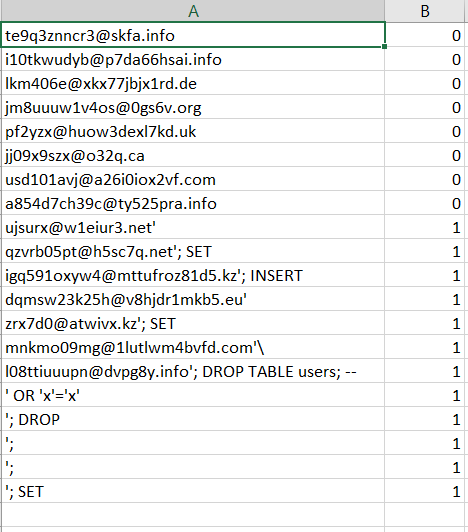
I wrote a script that generated random email addresses and SQL injections. As a result, there were three types of data in my csv file: random emails (20 thousand), random emails with SQL injection (20 thousand) and pure SQL injection (10 thousand). It looked something like this:
Now you need to read the source data. The function returns a sheet X, which contains features, a sheet Y, which contains labels for each feature, and a sheet label_names, which simply contains a text definition for labels, for convenience when displaying results.
Further, these data must be divided into a training set and a test set. The cross_validation.train_test_split () function, carefully written for us, will help us with this, which will shuffle the records and return us four data sets - two training and two test sets for features and labels.
Then we initialize the vectorizer object, which will read the data transmitted into it one character at a time, combine them into N-grams and translate them into numerical vectors, which the machine learning algorithm is capable of perceiving.
The next step, we initialize the pipeline and pass into it the previously created vectorizer and the algorithm with which we want to analyze our date set. In this, we will use the logistic regression algorithm .
The model is ready for digesting data. Now we just transfer the training sets of features and labels to our pipeline and the model starts training. The next line, we pass the features test set through the pipeline, but now we use predict to get the number of correctly guessed data.
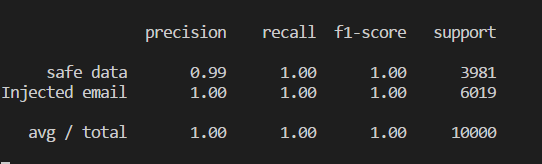
If you want to know how accurate the model is in predictions, you can compare the guessed data and the test sheet labels.
The accuracy of the model is determined by a value from 0 to 1, and can be converted to percent. This model gives the correct answer in 100% of cases. Of course, using real data, such a result will not be so simple, and the task is quite simple.
The final finishing touch is to save the model in a trained form so that it can be used in any other python program without repeated training. We serialize the model into a pickle file using the built-in function in Scikit-learn:
A small demonstration of how to use a serialized model in another program.
At the output, we get this result:
As you can see, the model determines the SQL injection quite confidently.
As a result, we have a trained model for determining SQL injections, in theory, we can plug it into the server side, and in the case of determining an injection, redirect all requests to a fake database in order to look away from other possible vulnerabilities. To demonstrate at the end of the week, I wrote a small REST API in Flask.
These were my first steps in machine learning. I hope that I can inspire those who, like me for a long time, looked with interest at machine learning, but were afraid to touch it.
Оставляю список полезных ресурсов, которые помогли мне с данным проектом (почти все они на английском)
Tensorflow for begginers
Scikit-Learn Tutorials
Building Language Detector via Scikit-Learn
Нашел несколько отличных статей на Medium включая серию из восьми статей, которые дают хорошее представление, о машинном обучении на простых примерах. (UPD: русский перевод этих же статей)
Preamble
I work as a web developer in a consulting company, and sometimes there comes a time when one project has already ended, and the next has not yet been appointed. Everyone who is on the bench, so as not just to sit out his pants, must contribute to the intellectual property of the company. As a rule, this is either the creation of training materials on a topic that the author owns, or the study of new technology and the subsequent demonstration or presentation at the end of the week.
I decided, if there is such an opportunity, then try to touch on the topic of Machine Learning, because it is stylish, fashionable and youth. From previous knowledge in this topic, I had only a couple of presentations from a leading developer, which had more of a popularizing rather than an informative connotation.
I identified a specific problem to solve with machine learning and started digging. I want to note that having an ultimate goal was easier to navigate in the flow of information.
I decided, if there is such an opportunity, then try to touch on the topic of Machine Learning, because it is stylish, fashionable and youth. From previous knowledge in this topic, I had only a couple of presentations from a leading developer, which had more of a popularizing rather than an informative connotation.
I identified a specific problem to solve with machine learning and started digging. I want to note that having an ultimate goal was easier to navigate in the flow of information.
Stick a shovel
First, I went to the official TensorFlow website and read ML for Beginners and TensorFlow for beginners . Materials in English.
TensorFlow is a work of the Google team and the most popular machine learning library that supports Python, Java, C ++, Go, as well as the ability to use the computing power of a graphics card to calculate complex neural networks.
In my searches, I found another Python- oriented Scikit-learn machine learning library . Plus this library, in a large number of algorithms for machine learning right out of the box, which was an undoubted plus in my case, since the presentation was on Friday, and I really wanted to demonstrate the working model.
In search of ready-made examples, I came across a tutorial on determining the language in which the text is written using Scikit-learn.
So, my task was to train the model to determine the presence of SQL injection in a text string. (Of course, you can solve this problem with the help of regular expressions, but for educational purposes you can
First of all, first thing about datasets ...
The type of problem that I am trying to solve is classification, that is, the algorithm should, in response to the fed data, give me to which of the categories this data belongs.
The data in which the algorithm will look for patterns are called features .
The category to which this or that feature belongs is called label . It is important to note that the input may have several features, but only one label.
In the classic example of machine learning, determining the varieties of iris flowers by the length of the pistils and stamens, each individual column with size information is a feature , and the last column, which means which of the subspecies of the iris, has a flower with such values, is label
The way I will solve the classification problem is called supervised learning, or supervised learning. This means that in the learning process, the algorithm will receive both features and labels.
The number one step in solving any problem with the help of machine learning is the collection of data on which this machine will learn. In an ideal world, this should be real data, but, unfortunately, I could not find anything on the Internet that would satisfy me. It was decided to generate data independently.
I wrote a script that generated random email addresses and SQL injections. As a result, there were three types of data in my csv file: random emails (20 thousand), random emails with SQL injection (20 thousand) and pure SQL injection (10 thousand). It looked something like this:
Now you need to read the source data. The function returns a sheet X, which contains features, a sheet Y, which contains labels for each feature, and a sheet label_names, which simply contains a text definition for labels, for convenience when displaying results.
import csv
def get_dataset():
X = []
y = []
label_names = ["safe data","Injected email"]
with open('trainingSet.csv') as csvfile:
readCSV = csv.reader(csvfile, delimiter='\n')
for row in readCSV:
splitted = row[0].split(',')
X.append(splitted[0])
y.append(splitted[1])
print("\n\nData set features {0}". format(len(X)))
print("Data set labels {0}\n". format(len(y)))
print(X)
return X, y, label_names
Further, these data must be divided into a training set and a test set. The cross_validation.train_test_split () function, carefully written for us, will help us with this, which will shuffle the records and return us four data sets - two training and two test sets for features and labels.
# Split the dataset on training and testing sets
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,y,test_size=0.2,random_state=0)Then we initialize the vectorizer object, which will read the data transmitted into it one character at a time, combine them into N-grams and translate them into numerical vectors, which the machine learning algorithm is capable of perceiving.
#Setting up vectorizer that will convert dataset into vectors using n-gram
vectorizer = feature_extraction.text.TfidfVectorizer(ngram_range=(1, 4), analyzer='char')
Feed data
The next step, we initialize the pipeline and pass into it the previously created vectorizer and the algorithm with which we want to analyze our date set. In this, we will use the logistic regression algorithm .
#Setting up pipeline to flow data though vectorizer to the liner model implementation
pipe = pipeline.Pipeline([('vectorizer', vectorizer), ('clf', linear_model.LogisticRegression())])
The model is ready for digesting data. Now we just transfer the training sets of features and labels to our pipeline and the model starts training. The next line, we pass the features test set through the pipeline, but now we use predict to get the number of correctly guessed data.
#Pass training set of features and labels though pipe.
pipe.fit(X_train, y_train)
#Test model accuracy by running feature test set
y_predicted = pipe.predict(X_test)
If you want to know how accurate the model is in predictions, you can compare the guessed data and the test sheet labels.
print(metrics.classification_report(y_test, y_predicted,target_names=label_names))The accuracy of the model is determined by a value from 0 to 1, and can be converted to percent. This model gives the correct answer in 100% of cases. Of course, using real data, such a result will not be so simple, and the task is quite simple.
The final finishing touch is to save the model in a trained form so that it can be used in any other python program without repeated training. We serialize the model into a pickle file using the built-in function in Scikit-learn:
#Save model into pickle. Built in serializing tool
joblib.dump(pipe, 'injection_model.pkl')
A small demonstration of how to use a serialized model in another program.
import numpy as np
from sklearn.externals import joblib
#Load classifier from the pickle file
clf = joblib.load('injection_model.pkl')
#Set of test data
input_data = ["aselectndwdpyrey@gmail.com",
"andrew@microsoft.com'",
"a.johns@deloite.com",
"'",
"select@mail.jp",
"update11@nebuzar.com",
"' OR 1=1",
"asdasd@sick.com'",
"andrew@mail' OR 1=1",
"an'drew@bark.1ov111.com",
"andrew@gmail.com'"]
predicted_attacks = clf.predict(input_data).astype(np.int)
label_names = ["Safe Data", "SQL Injection"]
for email, item in zip(input_data, predicted_attacks):
print(u'\n{} ----> {}'.format(label_names[item], email))
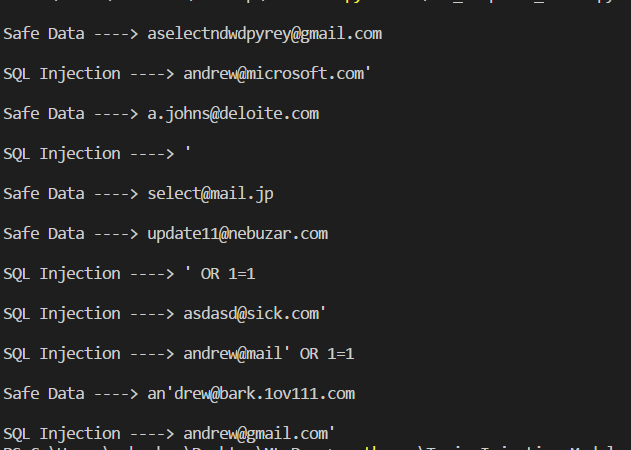
At the output, we get this result:
As you can see, the model determines the SQL injection quite confidently.
Conclusion
As a result, we have a trained model for determining SQL injections, in theory, we can plug it into the server side, and in the case of determining an injection, redirect all requests to a fake database in order to look away from other possible vulnerabilities. To demonstrate at the end of the week, I wrote a small REST API in Flask.
These were my first steps in machine learning. I hope that I can inspire those who, like me for a long time, looked with interest at machine learning, but were afraid to touch it.
Full code
from sklearn import ensemble
from sklearn import feature_extraction
from sklearn import linear_model
from sklearn import pipeline
from sklearn import cross_validation
from sklearn import metrics
from sklearn.externals import joblib
import load_data
import pickle
# Load the dataset from the csv file. Handled by load_data.py. Each email is split in characters and each one has label assigned
X, y, label_names = load_data.get_dataset()
# Split the dataset on training and testing sets
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,y,test_size=0.2,random_state=0)
#Setting up vectorizer that will convert dataset into vectors using n-gram
vectorizer = feature_extraction.text.TfidfVectorizer(ngram_range=(1, 4), analyzer='char')
#Setting up pipeline to flow data though vectorizer to the liner model implementation
pipe = pipeline.Pipeline([('vectorizer', vectorizer), ('clf', linear_model.LogisticRegression())])
#Pass training set of features and labels though pipe.
pipe.fit(X_train, y_train)
#Test model accuracy by running feature test set
y_predicted = pipe.predict(X_test)
print(metrics.classification_report(y_test, y_predicted,target_names=label_names))
#Save model into pickle. Built in serializing tool
joblib.dump(pipe, 'injection_model.pkl')
Reference materials
Оставляю список полезных ресурсов, которые помогли мне с данным проектом (почти все они на английском)
Tensorflow for begginers
Scikit-Learn Tutorials
Building Language Detector via Scikit-Learn
Нашел несколько отличных статей на Medium включая серию из восьми статей, которые дают хорошее представление, о машинном обучении на простых примерах. (UPD: русский перевод этих же статей)