Hessian-Free optimization with TensorFlow
Good afternoon! I want to talk about the optimization method known as Hessian-Free or Truncated Newton (Truncated Newton Method) and about its implementation using the deep learning library - TensorFlow. It takes advantage of second-order optimization methods and there is no need to read the matrix of second derivatives. This article describes the HF algorithm itself, as well as its work for training the direct distribution network on MNIST and XOR datasets.

Learning a neural network involves minimizing a loss function in relation to its weights, which can be a lot. Therefore, there are many optimization methods to solve this problem.
Gradient descent is the simplest method for sequentially finding the minimum of a differentiable function. (in the case of neural networks, this is a function of cost). Having a few options
(in the case of neural networks, this is a function of cost). Having a few options (network weights) and differentiating a function with respect to them, we obtain a vector of partial derivatives or a gradient vector:
(network weights) and differentiating a function with respect to them, we obtain a vector of partial derivatives or a gradient vector: ) then over time we will come to a minimum, which is what we needed. The simplest gradient descent algorithm:
) then over time we will come to a minimum, which is what we needed. The simplest gradient descent algorithm:
Gradient descent is a fairly simple and well-proven optimization method, but there is also a minus - it is of the first order, which means that the first derivative with respect to the cost function is taken. This in turn imposes some limitations: we mean that our cost function locally looks like a plane and does not take into account its curvature.
But what if we take and use the information that the second derivatives of the cost function give us? The best known optimization method using second derivatives is the Newton method. The main idea of this method is to minimize the quadratic approximation of the cost function. What does this mean? Let's figure it out.
Take the one-dimensional case. Suppose we have a function: . To find the minimum point, we need to find the zero of its derivative, because we know:
. To find the minimum point, we need to find the zero of its derivative, because we know: is at a minimum
is at a minimum  . We approximate the function Taylor expansion of the second order:
. We approximate the function Taylor expansion of the second order: , what
, what  will be the minimum. To do this, we take the derivative with respect to and equate to zero:quadratic function this will be an absolute minimum. If we want to find the minimum iteratively, then we take the initial
will be the minimum. To do this, we take the derivative with respect to and equate to zero:quadratic function this will be an absolute minimum. If we want to find the minimum iteratively, then we take the initial and update it according to this rule:
and update it according to this rule:
Consider the multidimensional case. Suppose we have a multidimensional function then:
then: - Hessian (Hessian) or a matrix of second derivatives. Based on this, to update the parameters we have the following formula:
- Hessian (Hessian) or a matrix of second derivatives. Based on this, to update the parameters we have the following formula:
As we can see, the Newton method is a second-order method and will work better than a normal gradient descent, because instead of moving to a local minimum at each step, it moves to a global minimum if we assume that the functionquadratic and the expansion of the second order in a Taylor series is its good approximation.
But this method has one big minus . To optimize the cost function, you must find the Hessian matrix or Hessian . Put
. Put Is the vector of parameters, then:
Is the vector of parameters, then: and what would it take to calculate
and what would it take to calculate  computing operations, which can be very critical for networks with hundreds or thousands of parameters. In addition, to solve the optimization problem using the Newton method, it is necessary to find the inverse Hessian matrix
computing operations, which can be very critical for networks with hundreds or thousands of parameters. In addition, to solve the optimization problem using the Newton method, it is necessary to find the inverse Hessian matrix , for this it should be positively defined for all
, for this it should be positively defined for all  .
.
The main idea of HF optimization is that we take Newton's method as the basis, but use a more suitable way to minimize the quadratic function. But first, we introduce the basic concepts that will be needed in the future.
Let be - network parameters, where
- network parameters, where  - matrix of weights (weights),
- matrix of weights (weights),  biases vector, then we call the network output:
biases vector, then we call the network output:  where - input vector.
where - input vector.  - loss function
- loss function  - target value. And we will define the function that we will minimize as the average of losses for all training examples (training batch)
- target value. And we will define the function that we will minimize as the average of losses for all training examples (training batch) : from the formula above and equating it to zero we get: we will use the conjugate gradient method.
: from the formula above and equating it to zero we get: we will use the conjugate gradient method.
The conjugate gradient method (CG) is an iterative method for solving systems of linear equations of the type: .
.
Brief CG Algorithm:
Input:,  ,
,  ,
,  - CG algorithm step
- CG algorithm step
Initialization:
We repeat until the stop condition is satisfied:
Now, using the conjugate gradient method, we can solve equation (2) and findwhich will minimize (1). In our case: .
.
Stop the CG algorithm. You can stop the conjugate gradient method based on various criteria. We will do this based on relative progress in optimizing the quadratic function :
: - the size of the "window" by which we will consider the value of progress,
- the size of the "window" by which we will consider the value of progress,  . The stop condition is:
. The stop condition is: .
.
And now you can see that the main feature of HF optimization is that we do not need to find the Hessian directly, but just find the result of its product by a vector.
As mentioned earlier, the charm of this method is that we do not need to count the Hessians directly. It is only necessary to calculate the result of the product of the matrix of second derivatives by a vector. You can imagine as a derivative of
as a derivative of  towards
towards  :
: . Therefore, there is a method for calculating the exact product of a matrix by a vector. We introduce the differential operator
. Therefore, there is a method for calculating the exact product of a matrix by a vector. We introduce the differential operator . It denotes a derivative of some magnitudedependent
. It denotes a derivative of some magnitudedependent  , towards :
, towards :
1. Generalized Newton-Gauss matrix (generalized Gauss-Newton matrix).
The uncertainty of the Hessian matrix is a problem for optimizing non-convex (non-convex) functions, it can lead to the absence of a lower bound for a quadratic functionand as a result, the impossibility of finding its minimum. This problem can be solved in many ways. For example, introducing a confidence interval will limit optimization or damping based on a fine that adds a positive semi-definite component to the curvature matrixand makes her positive definite.
Based on practical results, the best way to solve this problem is to use the Newton-Gauss matrix instead of the Hessian matrix:
instead of the Hessian matrix: - Jacobian,
- Jacobian,  - matrix of second derivatives of the loss function .
- matrix of second derivatives of the loss function .
To find the product of the matrix on vector :  , first we find the product of the Jacobian by the vector:
, first we find the product of the Jacobian by the vector: on the matrix and in the end we multiply the matrix on the
on the matrix and in the end we multiply the matrix on the  .
.
2. Damping.
The standard Newton method may poorly optimize strongly nonlinear objective functions. The reason for this may be that in the initial stages of optimization it can be very large and aggressive, since the starting point is far from the minimum point. To solve this problem, dumping is used - a method of changing a quadratic function or minimization restrictions so that the new will lie within such limits that will remain a good approximation  .
.
Regularization of Tikhonov (Tikhonov regularization) or dumping of Tikhonov (Tikhonov damping). (Not to be confused with the term “regularization”, which is commonly used in the context of machine learning) This is the most famous dumping method that adds a quadratic penalty to a function: ,
,  - dump parameter. Calculation
- dump parameter. Calculation is made like this:
is made like this:
3. Heuristics of Levenberg-Marquardt (Levenberg-Marquardt heuristic).
Tikhonov dumping is characterized by dynamic tuning of the parameter . Changewe will follow the Levenberg-Marquardt rule, which is often used in the context of the LM - method (the optimization method is an alternative to the Newton method). To use LM - heuristics, it is necessary to calculate the so-called reduction ratio:
. Changewe will follow the Levenberg-Marquardt rule, which is often used in the context of the LM - method (the optimization method is an alternative to the Newton method). To use LM - heuristics, it is necessary to calculate the so-called reduction ratio: - step number of the HF algorithm,
- step number of the HF algorithm,  - the result of the work of CG minimization.
- the result of the work of CG minimization.
According to the Levenberg-Marquardt heuristic, we get the update rule:
4. The initial condition for the algorithm of conjugate gradients (preconditioning).
In the context of HF optimization, we have some reversible transformation matrix with which we change so that
with which we change so that  and instead minimize
and instead minimize  . The use of this feature in the CG algorithm requires the calculation of the transformed error vector
. The use of this feature in the CG algorithm requires the calculation of the transformed error vector where
where  .
.
Brief PCG (Preconditioned conjugate gradient) algorithm:
Input:, , ,  , - CG algorithm step
, - CG algorithm step
Initialization:
We repeat until the stop condition is satisfied:
Matrix selectionquite a trivial task. Also, in practice, the use of a diagonal matrix (instead of a matrix with a full rank) shows rather good results. One of the options for choosing a matrix - this is the use of the diagonal Fisher matrix (Empirical Fisher Diagonal):
5. Initialization of the CG algorithm.
It’s good practice to initialize the initial , for the conjugate gradient algorithm, value found in the previous step of the HF algorithm. In this case, you can use some decay constant:
, for the conjugate gradient algorithm, value found in the previous step of the HF algorithm. In this case, you can use some decay constant: . It is worth noting that the index refers to the step number of the HF algorithm, in turn, index 0 in refers to the initial step of the CG algorithm.
. It is worth noting that the index refers to the step number of the HF algorithm, in turn, index 0 in refers to the initial step of the CG algorithm.
Complete Hessian-Free Optimization Algorithm:
Input:, - dump parameter - step of the iteration of the algorithm
Initialization:
The main HF optimization cycle:
Thus, the Hessian-Free optimization method allows us to solve the problem of finding the minimum of a large-dimensional function. It does not require finding the Hessian matrix directly.
The theory is certainly good, but let's try to implement this optimization method in practice and see what comes of it. To write the HF algorithm, I used Python and the TensorFlow deep learning library. After that, as a performance check, I trained a direct distribution network with several layers on XOR and MNIST datasets using the HF method for optimization.
Implementation (creating a TensorFlow calculation graph) for the conjugate gradient method.
Code for calculating the matrixto find the initial condition (preconditioning) is given below. At the same time, since Tensorflow summarizes the result of calculating gradients over the entire set of training examples presented, I had to twist a little to get the gradient separately for each example, which affected the numerical stability of the solution. Therefore, the use of preconditioning is possible, as they say, at your own peril and risk.
Calculation of the product of the Hessian by vector (4). In this case, Tikhonov dumping is used (6).
When I wanted to use the generalized Newton-Gauss matrix (5), I came across a small problem. Namely, TensorFlow does not know how to count Jacobian’s product as a vector like the other Theano deep learning framework does (Theano has a Rop function specifically designed for this). I had to do an analog operation in TensorFlow.
And then already realize the product of the generalized Newton-Gauss matrix by a vector.
The function of the main learning process is presented below. First, the quadratic function is minimized using CG / PCG, then the main network weights are updated. The dumping parameter based on the Levenberg-Marquardt heuristic is also adjusted.
We will test the written HF optimizer, for this we will use a simple example with an XOR dataset and a more complex one with MNIST dataset. In order to see the learning outcomes and visualize some information, we will use TesnorBoard. I would also like to note that we got a rather complex graph of TensorFlow calculations.
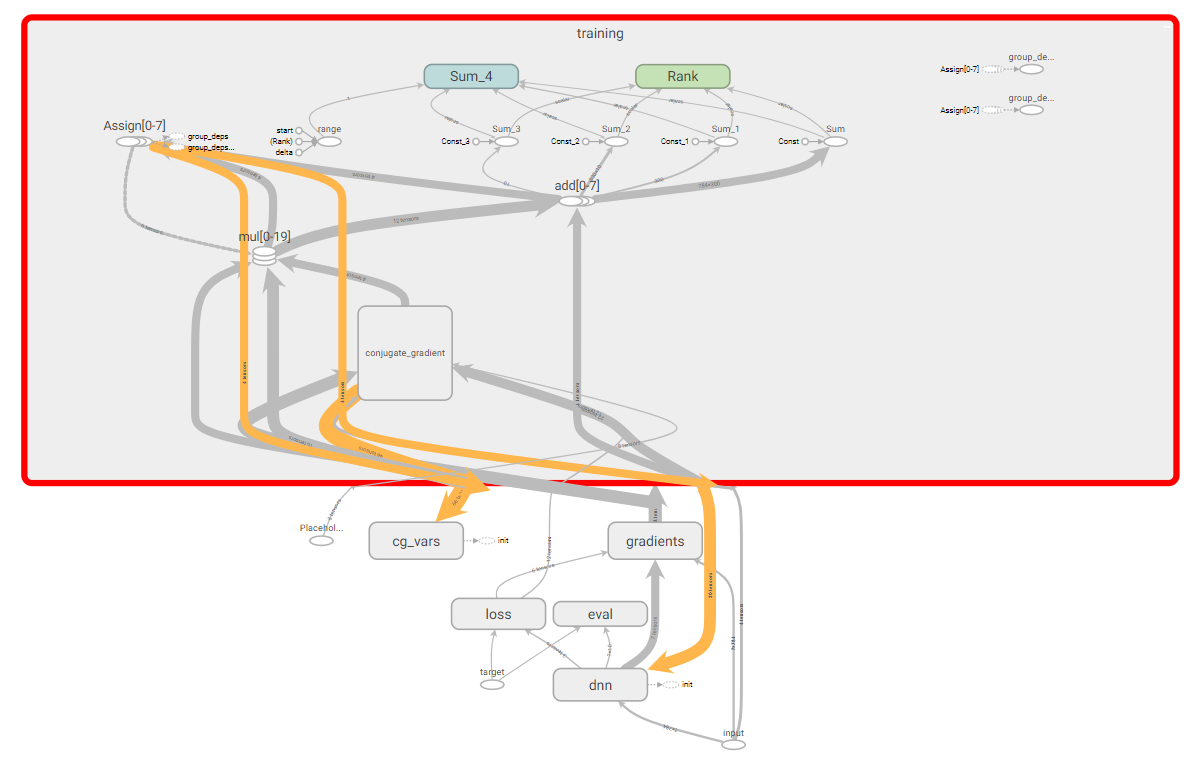
TensorFlow Computing Graph.
Network architecture and training on the XOR dataset.
Let's create a simple network of size: 2 input neurons, 2 hidden and 1 output. As an activation function we will use a sigmoid. As a loss function, we use log-loss.
Now compare the learning results using HF optimization (with the Hessian matrix), HF optimization (with the Newton-Gauss matrix) and the usual gradient descent with the learning speed parameter equal to 0.01. The number of iterations is 100.
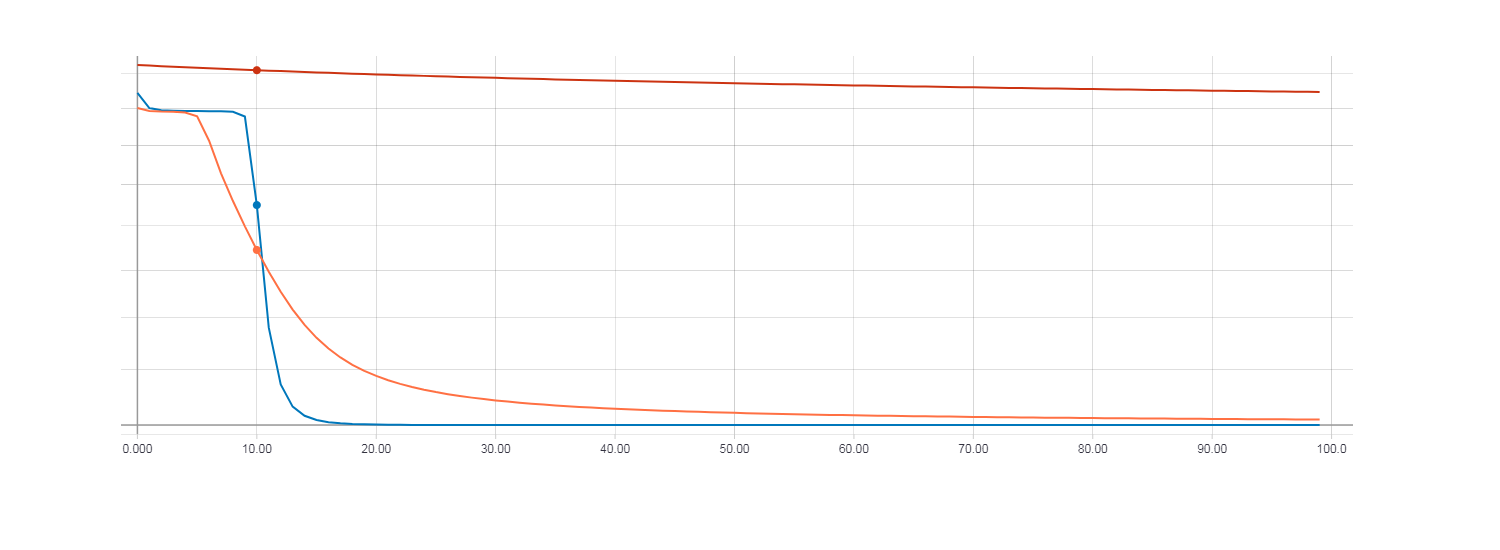
Loss for gradient descent (red line). Loss for HF optimization with Hessian matrix (orange line). Loss for HF optimization with the Newton-Gauss matrix (blue line).
At the same time, it is clear that HF optimization converges most quickly using the Newton-Gaussian matrix, while for the gradient descent 100 iterations turned out to be very small. In order for the loss function during gradient descent to be comparable with the HF optimization, it took about 100,000 iterations .
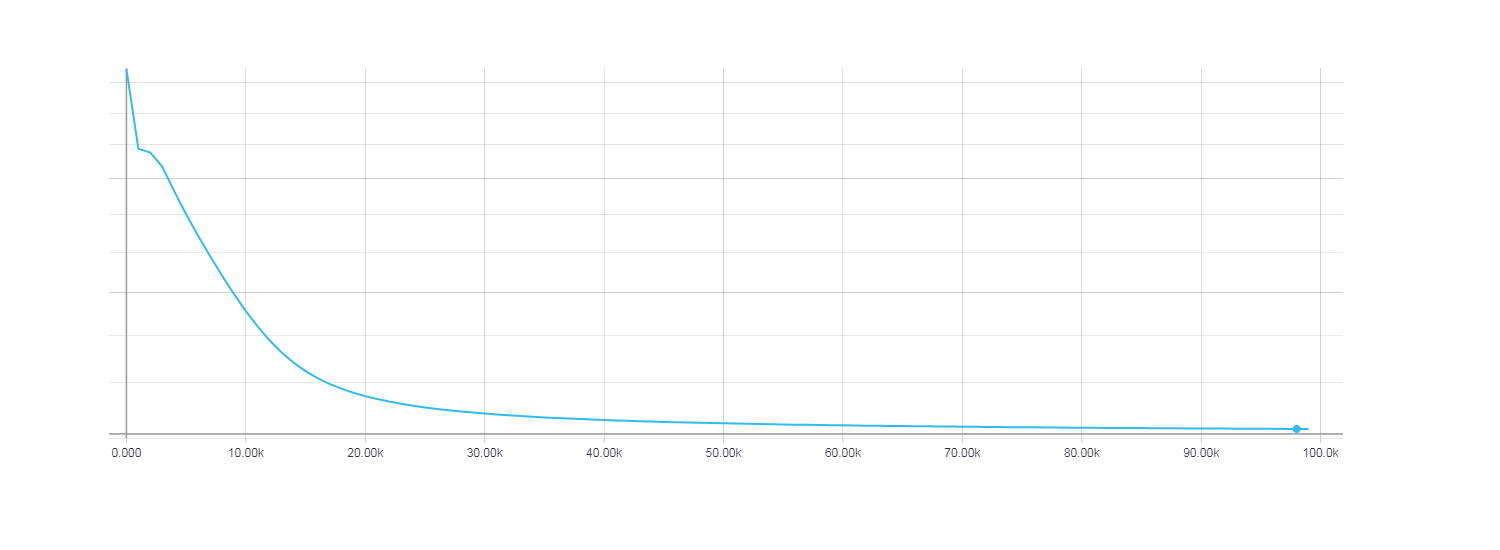
Loss for gradient descent, 100,000 iterations.
Network architecture and training on the MNIST dataset.
To solve the problem of handwritten number recognition, we will create a network of size: 784 input neurons, 300 hidden and 10 output. As a function of losses, we will use cross-entropy. The size of the mini-batch served during training is 50.
As in the case of XOR, we compare the learning results using HF optimization (with the Hessian matrix), HF optimization (with the Newton-Gauss matrix) and the usual gradient descent with the learning speed parameter equal to 0.01. The number of iterations is 200, i.e. if the size of the mini-batch is 50, then 200 is not a complete era (not all examples from the training set are used). I did this in order to test everything faster, but even from this a general trend is visible.
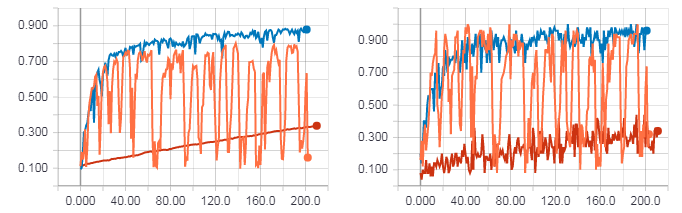
The figure on the left is the accuracy for the test sample. The figure on the right is the accuracy for the training sample. Accuracy for gradient descent (red line). Accuracy for HF optimization with Hessian matrix (orange line). Accuracy for HF optimization with a Newton-Gaussian matrix (blue line).
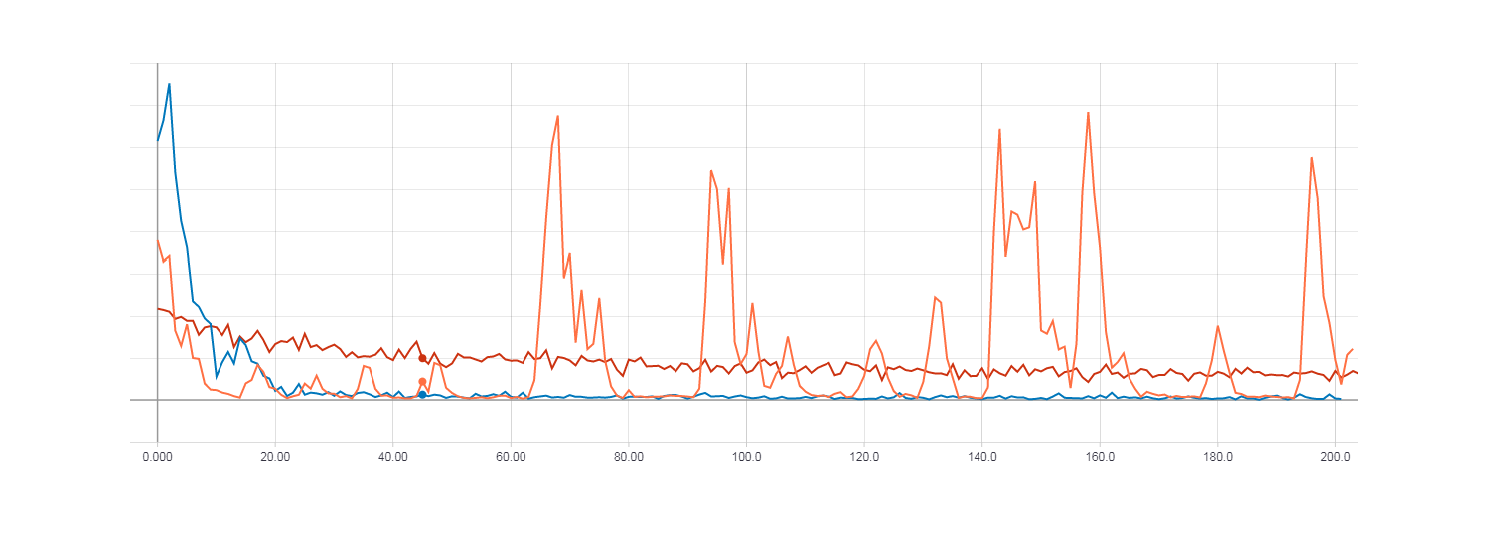
Loss for gradient descent (red line). Loss for HF optimization with Hessian matrix (orange line). Loss for HF optimization with the Newton-Gauss matrix (blue line).
As can be seen from the figures above, HF optimization with the Hessian matrix does not behave very stably, but in the end it will still converge when learning with several eras. The best result is shown by HF optimization with the Newton-Gauss matrix.
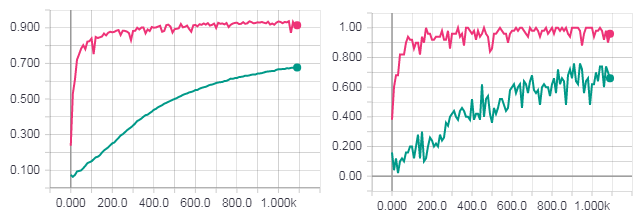
One complete era of learning. The figure on the left is the accuracy for the test sample. The figure on the right is the accuracy for the training sample. Accuracy for gradient descent (turquoise line). Loss for HF optimization with the Newton-Gaussian matrix (pink line).
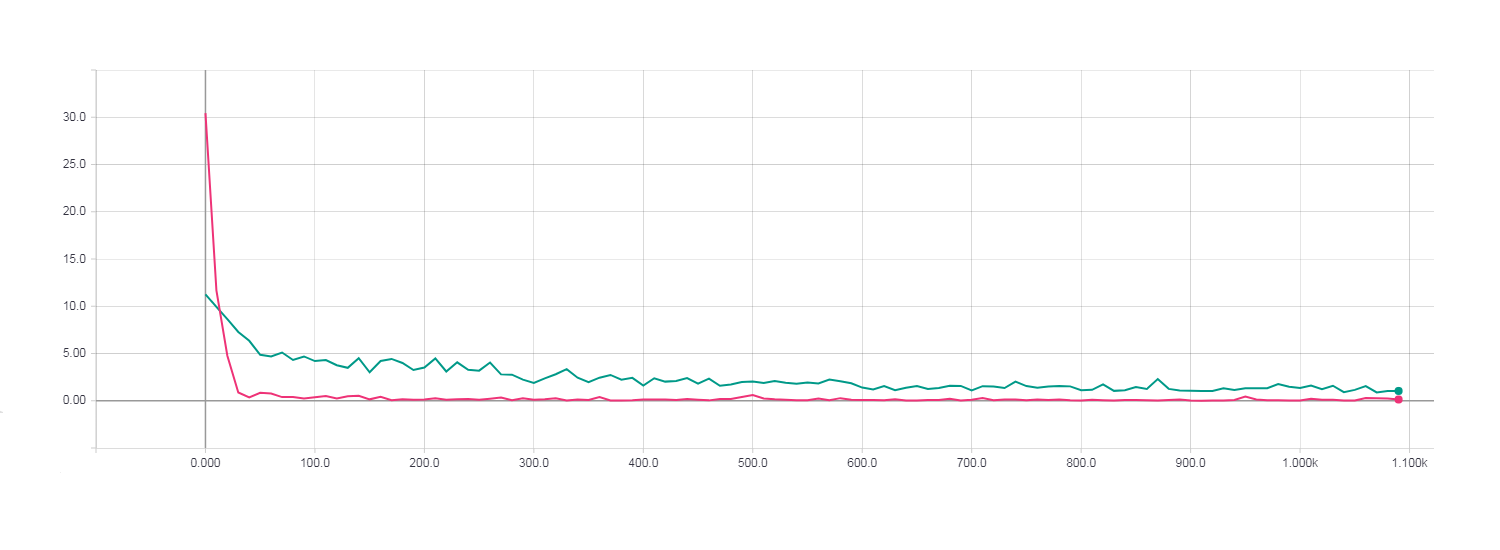
One complete era of learning. Loss for gradient descent (turquoise line). Loss for HF optimization with the Newton-Gaussian matrix (pink line).
When using the method of conjugate gradients with the initial condition for the algorithm of conjugate gradients (preconditioning), the calculations themselves slowed down significantly and converged no faster than with normal CG.

Loss for HF optimization using PCG algorithm.
From all these graphs, you can see that the best result was shown by HF optimization using the Newton-Gauss matrix and the standard conjugate gradient method.
The full code can be viewed on GitHub .
As a result, an implementation of the HF algorithm in Python was created using the TensorFlow library. During the creation, I encountered some problems when implementing the main features of the algorithm, namely: support for the Newton-Gaussian matrix and preconditioning. This was due to the fact that TensorFlow is not as flexible a library as we would like and is not very designed for research. For experimental purposes, it is still better to use Theano, as it gives more freedom. But I initially decided for myself to do all this with TensorFlow. The program was tested and it was possible to see that the HF algorithm using the Newton-Gaussian matrix gives the best results.
In this article, the theoretical aspects of Hessian - Free optimization are described quite briefly so that you can understand the main essence of the algorithms. If a more detailed description of the material is needed, then I quote the sources from where I took the basic theoretical information, on the basis of which Python made the implementation of the HF method.
1) Training Deep and Recurrent Networks with Hessian-Free Optimization (James Martens and Ilya Sutskever, University of Toronto) - a complete description of HF - optimization.
2) Deep learning via Hessian-free optimization (James Martens, University of Toronto) - an article with the results of using HF - optimization.
3) Fast Exact Multiplication by the Hessian (Barak A. Pearlmutter, Siemens Corporate Research)- a detailed description of the multiplication of the Hessian matrix by a vector.
4) An introduction to the Conjugate Gradient Method without the Agonizing Pain (Jonathan Richard Shewchuk, Carnegie Mellon University) - a detailed description of the conjugate gradient method.
A little bit about optimization methods
Learning a neural network involves minimizing a loss function in relation to its weights, which can be a lot. Therefore, there are many optimization methods to solve this problem.
Gradient Descent
Gradient descent is the simplest method for sequentially finding the minimum of a differentiable function.
(in the case of neural networks, this is a function of cost). Having a few options (network weights) and differentiating a function with respect to them, we obtain a vector of partial derivatives or a gradient vector:
) then over time we will come to a minimum, which is what we needed. The simplest gradient descent algorithm:- Initialization: randomly select options
- Calculate the gradient:

- Change the parameters in the direction of a negative gradient:
 where
where  - some parameter of the learning rate
- some parameter of the learning rate - Repeat the previous steps until the gradient is close enough to zero
Gradient descent is a fairly simple and well-proven optimization method, but there is also a minus - it is of the first order, which means that the first derivative with respect to the cost function is taken. This in turn imposes some limitations: we mean that our cost function locally looks like a plane and does not take into account its curvature.
Newton's Method
But what if we take and use the information that the second derivatives of the cost function give us? The best known optimization method using second derivatives is the Newton method. The main idea of this method is to minimize the quadratic approximation of the cost function. What does this mean? Let's figure it out.
Take the one-dimensional case. Suppose we have a function:
. To find the minimum point, we need to find the zero of its derivative, because we know: is at a minimum . We approximate the function Taylor expansion of the second order:
, what will be the minimum. To do this, we take the derivative with respect to and equate to zero:
quadratic function this will be an absolute minimum. If we want to find the minimum iteratively, then we take the initial and update it according to this rule:
Consider the multidimensional case. Suppose we have a multidimensional function
then:

- Hessian (Hessian) or a matrix of second derivatives. Based on this, to update the parameters we have the following formula:
Problems with the Newton Method
As we can see, the Newton method is a second-order method and will work better than a normal gradient descent, because instead of moving to a local minimum at each step, it moves to a global minimum if we assume that the function
quadratic and the expansion of the second order in a Taylor series is its good approximation. But this method has one big minus . To optimize the cost function, you must find the Hessian matrix or Hessian
. Put Is the vector of parameters, then:
and what would it take to calculate computing operations, which can be very critical for networks with hundreds or thousands of parameters. In addition, to solve the optimization problem using the Newton method, it is necessary to find the inverse Hessian matrix, for this it should be positively defined for all .A positive definite matrix.
Matrix dimensions called non-negative definite if it satisfies the condition:  . If, in this case, a strict inequality holds, then the matrix is called positive definite. An important property of such matrices is their nonsingularity, i.e. the existence of an inverse matrix
. If, in this case, a strict inequality holds, then the matrix is called positive definite. An important property of such matrices is their nonsingularity, i.e. the existence of an inverse matrix .
.
dimensions called non-negative definite if it satisfies the condition: . If, in this case, a strict inequality holds, then the matrix is called positive definite. An important property of such matrices is their nonsingularity, i.e. the existence of an inverse matrix.Hessian-Free Optimization
The main idea of HF optimization is that we take Newton's method as the basis, but use a more suitable way to minimize the quadratic function. But first, we introduce the basic concepts that will be needed in the future.
Let be
- network parameters, where - matrix of weights (weights), biases vector, then we call the network output: where - input vector. - loss function - target value. And we will define the function that we will minimize as the average of losses for all training examples (training batch):

from the formula above and equating it to zero we get:
we will use the conjugate gradient method.Conjugate gradient method
The conjugate gradient method (CG) is an iterative method for solving systems of linear equations of the type:
. Brief CG Algorithm:
Input:
, , , - CG algorithm step Initialization:
 - error vector (residual)
- error vector (residual) - vector of search direction
- vector of search direction
We repeat until the stop condition is satisfied:



Now, using the conjugate gradient method, we can solve equation (2) and find
which will minimize (1). In our case:. Stop the CG algorithm. You can stop the conjugate gradient method based on various criteria. We will do this based on relative progress in optimizing the quadratic function
:
- the size of the "window" by which we will consider the value of progress, . The stop condition is:. And now you can see that the main feature of HF optimization is that we do not need to find the Hessian directly, but just find the result of its product by a vector.
Hessian multiplication by vector
As mentioned earlier, the charm of this method is that we do not need to count the Hessians directly. It is only necessary to calculate the result of the product of the matrix of second derivatives by a vector. You can imagine
as a derivative of towards :
. Therefore, there is a method for calculating the exact product of a matrix by a vector. We introduce the differential operator. It denotes a derivative of some magnitudedependent , towards :

Some improvements to HF optimization
1. Generalized Newton-Gauss matrix (generalized Gauss-Newton matrix).
The uncertainty of the Hessian matrix is a problem for optimizing non-convex (non-convex) functions, it can lead to the absence of a lower bound for a quadratic function
and as a result, the impossibility of finding its minimum. This problem can be solved in many ways. For example, introducing a confidence interval will limit optimization or damping based on a fine that adds a positive semi-definite component to the curvature matrixand makes her positive definite. Based on practical results, the best way to solve this problem is to use the Newton-Gauss matrix
instead of the Hessian matrix:
- Jacobian, - matrix of second derivatives of the loss function . To find the product of the matrix
on vector : , first we find the product of the Jacobian by the vector:
on the matrix and in the end we multiply the matrix on the . 2. Damping.
The standard Newton method may poorly optimize strongly nonlinear objective functions. The reason for this may be that in the initial stages of optimization it can be very large and aggressive, since the starting point is far from the minimum point. To solve this problem, dumping is used - a method of changing a quadratic function
or minimization restrictions so that the new will lie within such limits that will remain a good approximation . Regularization of Tikhonov (Tikhonov regularization) or dumping of Tikhonov (Tikhonov damping). (Not to be confused with the term “regularization”, which is commonly used in the context of machine learning) This is the most famous dumping method that adds a quadratic penalty to a function
:
, - dump parameter. Calculation is made like this:
3. Heuristics of Levenberg-Marquardt (Levenberg-Marquardt heuristic).
Tikhonov dumping is characterized by dynamic tuning of the parameter
. Changewe will follow the Levenberg-Marquardt rule, which is often used in the context of the LM - method (the optimization method is an alternative to the Newton method). To use LM - heuristics, it is necessary to calculate the so-called reduction ratio:
- step number of the HF algorithm, - the result of the work of CG minimization. According to the Levenberg-Marquardt heuristic, we get the update rule
:
4. The initial condition for the algorithm of conjugate gradients (preconditioning).
In the context of HF optimization, we have some reversible transformation matrix
with which we change so that and instead minimize . The use of this feature in the CG algorithm requires the calculation of the transformed error vectorwhere . Brief PCG (Preconditioned conjugate gradient) algorithm:
Input:
, , , , - CG algorithm step Initialization:
- - error vector (residual)
 - solution of the equation
- solution of the equation 
 - vector of search direction
- vector of search direction
We repeat until the stop condition is satisfied:



 - solution of the equation
- solution of the equation 



Matrix selection
quite a trivial task. Also, in practice, the use of a diagonal matrix (instead of a matrix with a full rank) shows rather good results. One of the options for choosing a matrix - this is the use of the diagonal Fisher matrix (Empirical Fisher Diagonal):
5. Initialization of the CG algorithm.
It’s good practice to initialize the initial
, for the conjugate gradient algorithm, value found in the previous step of the HF algorithm. In this case, you can use some decay constant:. It is worth noting that the index refers to the step number of the HF algorithm, in turn, index 0 in refers to the initial step of the CG algorithm. Complete Hessian-Free Optimization Algorithm:
Input:
, - dump parameter - step of the iteration of the algorithm Initialization:

The main HF optimization cycle:
- Calculate the matrix
- We find Solving the optimization problem using CG or PCG.

- Updating the dumping parameter using the Levenberg-Marquardt heuristic
 , - learning rate parameter
, - learning rate parameter
Thus, the Hessian-Free optimization method allows us to solve the problem of finding the minimum of a large-dimensional function. It does not require finding the Hessian matrix directly.
Implement HF Optimization on TensorFlow
The theory is certainly good, but let's try to implement this optimization method in practice and see what comes of it. To write the HF algorithm, I used Python and the TensorFlow deep learning library. After that, as a performance check, I trained a direct distribution network with several layers on XOR and MNIST datasets using the HF method for optimization.
Implementation (creating a TensorFlow calculation graph) for the conjugate gradient method.
def __conjugate_gradient(self, gradients):
""" Performs conjugate gradient method to minimze quadratic equation
and find best delta of network parameters.
gradients: list of Tensorflow tensor objects
Network gradients.
return: Tensorflow tensor object
Update operation for delta.
return: Tensorflow tensor object
Residual norm, used to prevent numerical errors.
return: Tensorflow tensor object
Delta loss. """
with tf.name_scope('conjugate_gradient'):
cg_update_ops = []
prec = None
#вычисление матрицы P по формуле (9)
if self.use_prec:
if self.prec_loss is None:
graph = tf.get_default_graph()
lop = self.loss.op.node_def
self.prec_loss = graph.get_tensor_by_name(lop.input[0] + ':0')
batch_size = None
if self.batch_size is None:
self.prec_loss = tf.unstack(self.prec_loss)
batch_size = self.prec_loss.get_shape()[0]
else:
self.prec_loss = [tf.gather(self.prec_loss, i)
for i in range(self.batch_size)]
batch_size = len(self.prec_loss)
prec = [[g**2 for g in tf.gradients(tf.gather(self.prec_loss, i),
self.W)] for i in range(batch_size)]
prec = [(sum(tensor) + self.damping)**(-0.75)
for tensor in np.transpose(np.array(prec))]
#основной алгоритм сопряженных градиентов
Ax = None
if self.use_gnm:
Ax = self.__Gv(self.cg_delta)
else:
Ax = self.__Hv(gradients, self.cg_delta)
b = [-grad for grad in gradients]
bAx = [b - Ax for b, Ax in zip(b, Ax)]
condition = tf.equal(self.cg_step, 0)
r = [tf.cond(condition, lambda: tf.assign(r, bax),
lambda: r) for r, bax in zip(self.residuals, bAx)]
d = None
if self.use_prec:
d = [tf.cond(condition, lambda: tf.assign(d, p * r),
lambda: d) for p, d, r in zip(prec, self.directions, r)]
else:
d = [tf.cond(condition, lambda: tf.assign(d, r),
lambda: d) for d, r in zip(self.directions, r)]
Ad = None
if self.use_gnm:
Ad = self.__Gv(d)
else:
Ad = self.__Hv(gradients, d)
residual_norm = tf.reduce_sum([tf.reduce_sum(r**2) for r in r])
alpha = tf.reduce_sum([tf.reduce_sum(d * ad) for d, ad in zip(d, Ad)])
alpha = residual_norm / alpha
if self.use_prec:
beta = tf.reduce_sum([tf.reduce_sum(p * (r - alpha * ad)**2)
for r, ad, p in zip(r, Ad, prec)])
else:
beta = tf.reduce_sum([tf.reduce_sum((r - alpha * ad)**2) for r, ad
in zip(r, Ad)])
self.beta = beta
beta = beta / residual_norm
for i, delta in reversed(list(enumerate(self.cg_delta))):
update_delta = tf.assign(delta, delta + alpha * d[i],
name='update_delta')
update_residual = tf.assign(self.residuals[i], r[i] - alpha * Ad[i],
name='update_residual')
p = 1.0
if self.use_prec:
p = prec[i]
update_direction = tf.assign(self.directions[i],
p * (r[i] - alpha * Ad[i]) + beta * d[i], name='update_direction')
cg_update_ops.append(update_delta)
cg_update_ops.append(update_residual)
cg_update_ops.append(update_direction)
with tf.control_dependencies(cg_update_ops):
cg_update_ops.append(tf.assign_add(self.cg_step, 1))
cg_op = tf.group(*cg_update_ops)
dl = tf.reduce_sum([tf.reduce_sum(0.5*(delta*ax) + grad*delta)
for delta, grad, ax in zip(self.cg_delta, gradients, Ax)])
return cg_op, residual_norm, dl
Code for calculating the matrix
to find the initial condition (preconditioning) is given below. At the same time, since Tensorflow summarizes the result of calculating gradients over the entire set of training examples presented, I had to twist a little to get the gradient separately for each example, which affected the numerical stability of the solution. Therefore, the use of preconditioning is possible, as they say, at your own peril and risk. prec = [[g**2 for g in tf.gradients(tf.gather(self.prec_loss, i),
self.W)] for i in range(batch_size)]
Calculation of the product of the Hessian by vector (4). In this case, Tikhonov dumping is used (6).
def __Hv(self, grads, vec):
""" Computes Hessian vector product.
grads: list of Tensorflow tensor objects
Network gradients.
vec: list of Tensorflow tensor objects
Vector that is multiplied by the Hessian.
return: list of Tensorflow tensor objects
Result of multiplying Hessian by vec. """
grad_v = [tf.reduce_sum(g * v) for g, v in zip(grads, vec)]
Hv = tf.gradients(grad_v, self.W, stop_gradients=vec)
Hv = [hv + self.damp_pl * v for hv, v in zip(Hv, vec)]
return Hv
When I wanted to use the generalized Newton-Gauss matrix (5), I came across a small problem. Namely, TensorFlow does not know how to count Jacobian’s product as a vector like the other Theano deep learning framework does (Theano has a Rop function specifically designed for this). I had to do an analog operation in TensorFlow.
def __Rop(self, f, x, vec):
""" Computes Jacobian vector product.
f: Tensorflow tensor object
Objective function.
x: list of Tensorflow tensor objects
Parameters with respect to which computes Jacobian matrix.
vec: list of Tensorflow tensor objects
Vector that is multiplied by the Jacobian.
return: list of Tensorflow tensor objects
Result of multiplying Jacobian (df/dx) by vec. """
r = None
if self.batch_size is None:
try:
r = [tf.reduce_sum([tf.reduce_sum(v * tf.gradients(f, x)[i])
for i, v in enumerate(vec)])
for f in tf.unstack(f)]
except ValueError:
assert False, clr.FAIL + clr.BOLD + 'Batch size is None, but used '\
'dynamic shape for network input, set proper batch_size in '\
'HFOptimizer initialization' + clr.ENDC
else:
r = [tf.reduce_sum([tf.reduce_sum(v * tf.gradients(tf.gather(f, i), x)[j])
for j, v in enumerate(vec)])
for i in range(self.batch_size)]
assert r is not None, clr.FAIL + clr.BOLD +\
'Something went wrong in Rop computation' + clr.ENDC
return r
And then already realize the product of the generalized Newton-Gauss matrix by a vector.
def __Gv(self, vec):
""" Computes the product G by vec = JHJv (G is the Gauss-Newton matrix).
vec: list of Tensorflow tensor objects
Vector that is multiplied by the Gauss-Newton matrix.
return: list of Tensorflow tensor objects
Result of multiplying Gauss-Newton matrix by vec. """
Jv = self.__Rop(self.output, self.W, vec)
Jv = tf.reshape(tf.stack(Jv), [-1, 1])
HJv = tf.gradients(tf.matmul(tf.transpose(tf.gradients(self.loss,
self.output)[0]), Jv), self.output, stop_gradients=Jv)[0]
JHJv = tf.gradients(tf.matmul(tf.transpose(HJv), self.output), self.W,
stop_gradients=HJv)
JHJv = [gv + self.damp_pl * v for gv, v in zip(JHJv, vec)]
return JHJv
The function of the main learning process is presented below. First, the quadratic function is minimized using CG / PCG, then the main network weights are updated. The dumping parameter based on the Levenberg-Marquardt heuristic is also adjusted.
def minimize(self, feed_dict, debug_print=False):
""" Performs main training operations.
feed_dict: dictionary
Input training batch.
debug_print: bool
If True prints CG iteration number. """
self.sess.run(tf.assign(self.cg_step, 0))
feed_dict.update({self.damp_pl:self.damping})
if self.adjust_damping:
loss_before_cg = self.sess.run(self.loss, feed_dict)
dl_track = [self.sess.run(self.ops['dl'], feed_dict)]
self.sess.run(self.ops['set_delta_0'])
for i in range(self.cg_max_iters):
if debug_print:
d_info = clr.OKGREEN + '\r[CG iteration: {}]'.format(i) + clr.ENDC
sys.stdout.write(d_info)
sys.stdout.flush()
k = max(self.gap, i // self.gap)
rn = self.sess.run(self.ops['res_norm'], feed_dict)
#ранняя остановка для предотвращения численной ошибки
if rn < self.cg_num_err:
break
self.sess.run(self.ops['cg_update'], feed_dict)
dl_track.append(self.sess.run(self.ops['dl'], feed_dict))
#ранняя остановка алгоритма, основываясь на формуле (3)
if i > k:
stop = (dl_track[i+1] - dl_track[i+1-k]) / dl_track[i+1]
if not np.isnan(stop) and stop < 1e-4:
break
if debug_print:
sys.stdout.write('\n')
sys.stdout.flush()
if self.adjust_damping:
feed_dict.update({self.damp_pl:0})
dl = self.sess.run(self.ops['dl'], feed_dict)
feed_dict.update({self.damp_pl:self.damping})
self.sess.run(self.ops['train'], feed_dict)
if self.adjust_damping:
loss_after_cg = self.sess.run(self.loss, feed_dict)
#коэффициент уменьшения (7)
reduction_ratio = (loss_after_cg - loss_before_cg) / dl
#эвристика Левенберга-Марквардта (8)
if reduction_ratio < 0.25 and self.damping > self.damp_num_err:
self.damping *= 1.5
elif reduction_ratio > 0.75 and self.damping > self.damp_num_err:
self.damping /= 1.5
Testing HF Optimization
We will test the written HF optimizer, for this we will use a simple example with an XOR dataset and a more complex one with MNIST dataset. In order to see the learning outcomes and visualize some information, we will use TesnorBoard. I would also like to note that we got a rather complex graph of TensorFlow calculations.
TensorFlow Computing Graph.
Network architecture and training on the XOR dataset.
Let's create a simple network of size: 2 input neurons, 2 hidden and 1 output. As an activation function we will use a sigmoid. As a loss function, we use log-loss.
#определение функции потерь
""" Log-loss cost function """
loss = tf.reduce_mean(( (y * tf.log(out)) +
((1 - y) * tf.log(1.0 - out)) ) * -1, name='log_loss')
#XOR датасет
XOR_X = [[0,0],[0,1],[1,0],[1,1]]
XOR_Y = [[0],[1],[1],[0]]
#создание оптимизатора
sess = tf.Session()
hf_optimizer = HFOptimizer(sess, loss, y_out,
dtype=tf.float64, use_gauss_newton_matrix=True)
init = tf.initialize_all_variables()
sess.run(init)
#цикл тренировки
max_epoches = 100
print('Begin Training')
for i in range(max_epoches):
feed_dict = {x: XOR_X, y: XOR_Y}
hf_optimizer.minimize(feed_dict=feed_dict)
if i % 10 == 0:
print('Epoch:', i, 'cost:', sess.run(loss, feed_dict=feed_dict))
print('Hypothesis ', sess.run(out, feed_dict=feed_dict))
Now compare the learning results using HF optimization (with the Hessian matrix), HF optimization (with the Newton-Gauss matrix) and the usual gradient descent with the learning speed parameter equal to 0.01. The number of iterations is 100.
Loss for gradient descent (red line). Loss for HF optimization with Hessian matrix (orange line). Loss for HF optimization with the Newton-Gauss matrix (blue line).
At the same time, it is clear that HF optimization converges most quickly using the Newton-Gaussian matrix, while for the gradient descent 100 iterations turned out to be very small. In order for the loss function during gradient descent to be comparable with the HF optimization, it took about 100,000 iterations .
Loss for gradient descent, 100,000 iterations.
Network architecture and training on the MNIST dataset.
To solve the problem of handwritten number recognition, we will create a network of size: 784 input neurons, 300 hidden and 10 output. As a function of losses, we will use cross-entropy. The size of the mini-batch served during training is 50.
with tf.name_scope('loss'):
one_hot = tf.one_hot(t, n_outputs, dtype=tf.float64)
xentropy = tf.nn.softmax_cross_entropy_with_logits(labels=one_hot, logits=y_out)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(tf.cast(y_out, tf.float32), t, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float64))
n_epochs = 10
batch_size = 50
with tf.Session() as sess:
""" Initializing hessian free optimizer """
hf_optimizer = HFOptimizer(sess, loss, y_out, dtype=tf.float64, batch_size=batch_size,
use_gauss_newton_matrix=True)
init = tf.global_variables_initializer()
init.run()
#основной процесс обучения
for epoch in range(n_epochs):
n_batches = mnist.train.num_examples // batch_size
for iteration in range(n_batches):
x_batch, t_batch = mnist.train.next_batch(batch_size)
hf_optimizer.minimize({x: x_batch, t: t_batch})
if iteration%10==0:
print('Batch:', iteration, '/', n_batches)
acc_train = accuracy.eval(feed_dict={x: x_batch, t: t_batch})
acc_test = accuracy.eval(feed_dict={x: mnist.test.images,
t: mnist.test.labels})
print('Loss:', sess.run(loss, {x: x_batch, t: t_batch}))
print('Target', t_batch[0])
print('Out:', sess.run(y_out_sm, {x: x_batch, t: t_batch})[0])
print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test)
acc_train = accuracy.eval(feed_dict={x: x_batch, t: t_batch})
acc_test = accuracy.eval(feed_dict={x: mnist.test.images,
t: mnist.test.labels})
print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test)
As in the case of XOR, we compare the learning results using HF optimization (with the Hessian matrix), HF optimization (with the Newton-Gauss matrix) and the usual gradient descent with the learning speed parameter equal to 0.01. The number of iterations is 200, i.e. if the size of the mini-batch is 50, then 200 is not a complete era (not all examples from the training set are used). I did this in order to test everything faster, but even from this a general trend is visible.
The figure on the left is the accuracy for the test sample. The figure on the right is the accuracy for the training sample. Accuracy for gradient descent (red line). Accuracy for HF optimization with Hessian matrix (orange line). Accuracy for HF optimization with a Newton-Gaussian matrix (blue line).
Loss for gradient descent (red line). Loss for HF optimization with Hessian matrix (orange line). Loss for HF optimization with the Newton-Gauss matrix (blue line).
As can be seen from the figures above, HF optimization with the Hessian matrix does not behave very stably, but in the end it will still converge when learning with several eras. The best result is shown by HF optimization with the Newton-Gauss matrix.
One complete era of learning. The figure on the left is the accuracy for the test sample. The figure on the right is the accuracy for the training sample. Accuracy for gradient descent (turquoise line). Loss for HF optimization with the Newton-Gaussian matrix (pink line).
One complete era of learning. Loss for gradient descent (turquoise line). Loss for HF optimization with the Newton-Gaussian matrix (pink line).
When using the method of conjugate gradients with the initial condition for the algorithm of conjugate gradients (preconditioning), the calculations themselves slowed down significantly and converged no faster than with normal CG.
Loss for HF optimization using PCG algorithm.
From all these graphs, you can see that the best result was shown by HF optimization using the Newton-Gauss matrix and the standard conjugate gradient method.
The full code can be viewed on GitHub .
Summary
As a result, an implementation of the HF algorithm in Python was created using the TensorFlow library. During the creation, I encountered some problems when implementing the main features of the algorithm, namely: support for the Newton-Gaussian matrix and preconditioning. This was due to the fact that TensorFlow is not as flexible a library as we would like and is not very designed for research. For experimental purposes, it is still better to use Theano, as it gives more freedom. But I initially decided for myself to do all this with TensorFlow. The program was tested and it was possible to see that the HF algorithm using the Newton-Gaussian matrix gives the best results.
Sources
In this article, the theoretical aspects of Hessian - Free optimization are described quite briefly so that you can understand the main essence of the algorithms. If a more detailed description of the material is needed, then I quote the sources from where I took the basic theoretical information, on the basis of which Python made the implementation of the HF method.
1) Training Deep and Recurrent Networks with Hessian-Free Optimization (James Martens and Ilya Sutskever, University of Toronto) - a complete description of HF - optimization.
2) Deep learning via Hessian-free optimization (James Martens, University of Toronto) - an article with the results of using HF - optimization.
3) Fast Exact Multiplication by the Hessian (Barak A. Pearlmutter, Siemens Corporate Research)- a detailed description of the multiplication of the Hessian matrix by a vector.
4) An introduction to the Conjugate Gradient Method without the Agonizing Pain (Jonathan Richard Shewchuk, Carnegie Mellon University) - a detailed description of the conjugate gradient method.