Where do the legs of the Java Memory Model grow
Modern hardware and compilers are ready to turn our code upside down so that it works faster. And their manufacturers carefully hide their inner kitchen. And everything is fine, while the code is executed in one thread.
In a multithreaded environment, you can perforce observe interesting things. For example, the execution of program instructions is not in the order as written in the source code. You must admit that it is not pleasant to realize that the execution of the source code line by line is just our imagination.
But everyone has already realized, because it is necessary to live with it somehow. And Java programmers even live quite well. Because Java has a memory model - the Java Memory Model (JMM), which provides fairly simple rules for writing correct multi-threaded code.
And these rules are enough for most programs. If you do not know them, but write or want to write multi-threaded programs in Java, it is better to get acquainted with them as soon as possible . And if you know, but you do not have enough context or it is interesting to find out where your JMM legs grow from, then the article can help you.
In my view, there is a pie, or more appropriately an iceberg. JMM is the tip of the iceberg. Under the water iceberg itself - the theory of multi-threaded programming. Under the iceberg - Hell.

An iceberg is an abstraction, if it leaks, then Hell we will certainly see. Although there is a lot of interesting things going on, in a review article we will not get to that.
In the article I am more interested in the following topics:
The theory of multi-threaded programming allows you to get away from the complexity of modern processors and compilers, it allows you to simulate the execution of multi-threaded programs and study their properties. Roman Elizarov made an excellent report , the purpose of which is to provide a theoretical basis for understanding JMM. I recommend the report to anyone interested in this topic.
Why is it so important to know the theory? In my opinion, I hope only for mine, some programmers have the opinion that JMM is a complication of the language and patching some platform problems with multithreading. The theory shows that in Java they did not complicate, but they simplified and made very complex multi-threaded programming more predictable.
First, let's look at the terminology. Unfortunately, there is no consensus in terminology - by studying different materials, you can meet different definitions of competition and concurrency.
The problem is that even if we get to the bottom of the truth and find exact definitions of these concepts, it’s still hardly necessary to expect that everyone will mean the same thing by these concepts. All there is not find .
Roman Elizarov, in the report on the theory of parallel programming for practitioners, says that sometimes these concepts are confused. Sometimes parallel programming is distinguished as a general concept, which is divided into competitive and distributed.
It seems to me that in the context of JMM, one should still separate competition and concurrency, or rather even understand that there are two different paradigms, whatever they are called.
Often cited by Rob Pike, who distinguishes the concepts as follows:
The opinion of Rob Pike is not a benchmark, but in my opinion, it is convenient to make a start from him to further study the issue. You can read more about the differences here .
Most likely, more understanding in the question will appear if we highlight the main features of a competitive and parallel program. There are a lot of signs, consider the most significant.
Signs of competition.
A parallel program will have a different set of features.
Oddly enough, parallel execution is possible on a single control thread, and even on a single-core architecture. The fact is that parallelism at the level of tasks (or control flows) to which we are used to is not the only way to perform computations in parallel.
Parallelism is possible at the level of:
Parallelism at the instruction level is one of the examples of optimizations that occur with the execution of the code, and which are hidden from the programmer.
It is guaranteed that the optimized code will be equivalent to the source code within a single thread, because it is impossible to write adequate and predictable code if it does not do what the programmer meant.
Not everything that runs in parallel matters to JMM. Parallel execution at the instruction level within a single thread is not covered in the JMM.
The terminology is very shaky, in Roman Elizarov the report is called “Theory of parallel programming for practitioners”, although there it’s more about competitive programming, if we stick to the above.
In the context of JMM in the article, I will stick to the term competition, since competition is often about general condition. But here one must be careful not to cling to the terms, but understand that there are different paradigms.
In his article, Maurice Hurlihi (author of The Art Of Multiprocessor programming) writes that the competitive system contains a collection of sequential processes (in theoretical works means the same thing as a stream), which communicate through common memory.
A shared state model includes computations with message passing, where the shared state is a message queue and shared memory calculations, where the common state is structures in memory.
Each of the calculations can be modeled.
The model is based on a state machine. The model focuses solely on the shared state and completely ignores the local data of each stream. Each action of flows over a shared state is a function of transition to a new state.
For example, if 4 threads write data to a shared variable, then there will be 4 transition functions to the new state. Which of these functions will be used depends on the chronology of events in the system.
Calculations with message passing are modeled in a similar way, only the state and transition functions depend on the sending or receiving of messages.
If the model seemed complicated to you, then in the example we will fix it. It is really very simple and intuitive. So much so that without knowing about the existence of this model, most people will still analyze the program as the model suggests.
This model is called the model of execution through the alternation of operations (the name was heard in the report of Roman Elizarov).
In the advantages of the model, you can safely record intuitiveness and naturalness. In the jungle, you can go on the keyword Sequential consistency and the work of Leslie Lamport.
However, there is an important clarification about this model. The model has a limitation that all actions on the shared state must be instantaneous and at the same time actions cannot occur simultaneously. They say that such a system has a linear order - all actions in the system are ordered.
In practice, this does not happen. The operation does not occur instantly, but is performed in the interval, on multi-core systems, these intervals may overlap. Of course, this does not mean that the model is useless in practice, you just need to create certain conditions for its use.
In the meantime, consider another model - “happened before” , which focuses not on state, but on a set of read and write operations of memory cells during execution (history) and their relationships.
The model says that events in different streams do not pass instantly and atomically, but in parallel, and it is not possible to build order between them. Events (writing and reading shared data) in threads on a multiprocessor or multi-core architecture actually occur in parallel. The system lacks the concept of global time; we cannot understand when one operation ended and another began.
In practice, this means that we can write to a variable in one stream and do it, say in the morning, and read from this variable in another stream in the evening, and we cannot say that we will read the value recorded in the morning for sure. In theory, these operations take place in parallel and it is not clear when one operation will end and another operation will begin.
It is difficult to imagine how it turns out that simple read and write operations done at different times of the day take place simultaneously. But if you think about it, then we really don’t care about the time when the events of writing and reading occur, if we cannot guarantee that we will see the result of the recording.
And we really can not see the result of the recording, i.e. the variable value of which is 0 in the stream Pwe write 1 , and in the stream Q we read this variable. No matter how much physical time passes after the recording, we can still read 0 .
This is how computers work and the model reflects this.
The model is completely abstract and needs visualization for convenient operation. For visualization, and only for it, a model with global time is used, with reservations that the global time is not used when proving program properties. In the visualization, each event is represented as an interval with a start and end.
Events run in parallel, as we found out. But still, the system has a partial order.since there are particular pairs of events that have order, then they say that these events are related to “what happened before.” If for the first time you hear about the “happened before” attitude, then probably the knowledge of the fact that this attitude sort of organizes events will not help you much.
We have considered some theoretical minimum, let's try to move further and consider a multi-threaded program in a specific language - Java, from two streams with a common changeable state.
Classic example.
We need to simulate the execution of this program and get all the possible results - the values of the variables x and y. There will be several results, as we remember from the theory, such a program is non-deterministic.
How are we going to model? Just want to use the model of alternation of operations. But the “happened before” model tells us that events in one stream are parallel to events from another stream. Therefore, the model of alternation of operations is not appropriate here, if there is no relationship between “operations before” between operations.
The result of executing each thread is always deterministic, since events in one thread are always ordered, consider that they get the relation “happened before” as a gift. But how events in different streams can get the attitude “happened before” is not entirely obvious. Of course, this relationship is formalized in the model, the whole model is written in mathematical language. But what to do with this in practice, in a specific language, cannot be immediately disassembled.
What are the options?
Ignore constraints and simulate interlacing. You can try something, maybe nothing terrible will happen.
To understand what kind of results you can get, let's simply iterate through all possible execution options.
All possible program performances can be represented as a finite state machine.
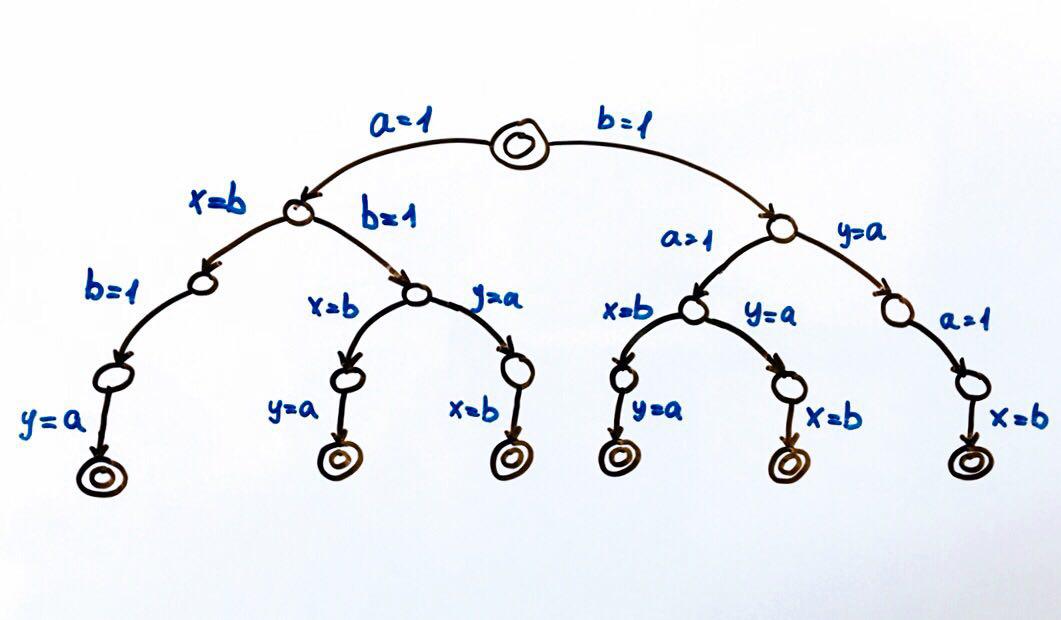
Each circle is the state of the system, in our case the variables a, b, x, y . The transition function is an action on a state that takes the system to a new state. Since two streams can perform actions on a general state, there will be two transitions from each state. Double circles are the final and initial states of the system.
A total of 6 different executions are possible, which result in a pair of x, y values: We can run the program and check the results. As befits a competitive program, it will have a non-deterministic result. To test competitive programs it is better to use special tools ( tool , report ).
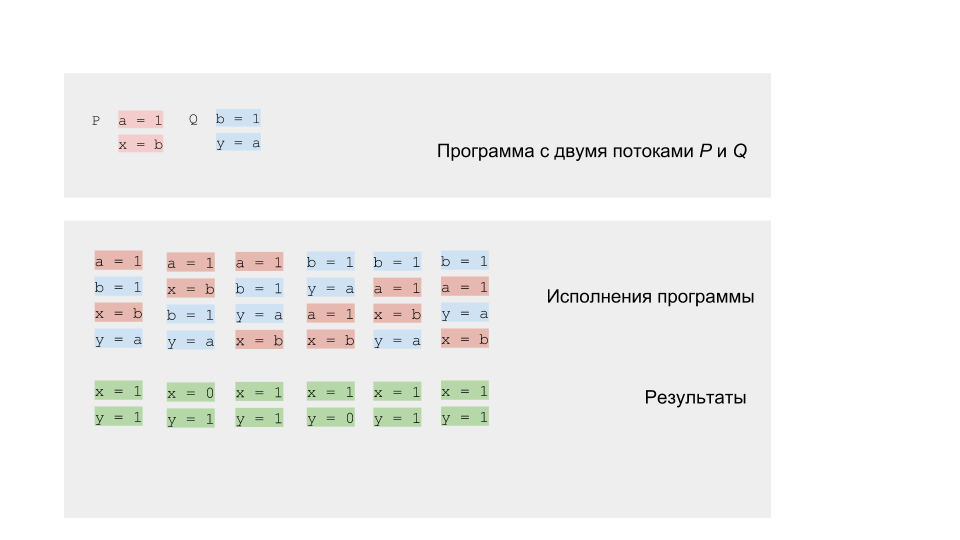
But you can try to run the program several million times, or even better, write a cycle that will do it for us.
If we run the code on a single-core or single-processor architecture, then we must get the result from the set that we expect. The rotation pattern will work just fine. On a multi-core architecture, such as x86, a surprise may await us - we can get a result (0,0), which cannot be according to our modeling.
The explanation for this can be searched on the Internet by keyword - reordering . Now it is important to understand that the alternation modeling is really not suitable in a situation where we cannot determine the order of access to the shared state .
The time has come to consider the relationship “happened before” and how it is friendly with the JMM. The original definition of the relation “happened before” can be found in the document Time, Clocks, and the Distributed System.
The memory model of a language helps in writing a competitive code, since it determines which operations have a relation “happened before”. The list of such operations is presented in the specification in the section Happens-before Order. In fact, this section answers the question - under what conditions will we see the result of a recording in another stream.
There are different orders in JMM. Alexey Shipilev tells very cheerfully about the order in one of his reports .
In a model with global time, all operations in one thread have order. For example, the events of writing and reading a variable can be represented as two intervals, then the model ensures that these intervals never intersect within the same flow. In JMM, this order is called Program Order ( PO ).
PO connects actions in one thread and says nothing about the order of execution, says only about the order in the source code. This is quite enough to guarantee determinism for each stream separately . PO can be viewed as raw data. PO is always easy to place in the program - all operations (linear order) in the source code within one stream will have a PO .
In our example, we get something like this:
Spied on this form of writing w (a, 1) PO r (b): 0. I really hope that no one patented for reports. However, the specification has a similar form.
But each stream separately is not particularly interesting to us, since the threads have a common state, we are more interested in the interaction of the threads. All we want is to be sure that we will see the recording of variables in other threads.
Let me remind you that this did not work out for us, because the operations of writing and reading variables in different streams are not instantaneous (these are segments that intersect), so it’s impossible to make out where the beginning and end of operations is.
The idea is simple - at the moment when we read the variable a in the stream Q , writing this variable itself in the stream P might not end yet. And no matter how much physical time these events share - nanosecond or a few hours.
To streamline the events we need the relationship “happened before”. JMM defines this attitude. In the specification, the order is fixed in one stream:
If operation x and y pass in one stream and x occurs first in PO and then y, then x occurs before y.
Looking ahead, we can say that we can replace all POs with Happens-before ( HB ):
But again we are spinning under one thread. HB is possible between operations occurring in different streams, in order to deal with these cases, we will get acquainted with other orders.
Synchronization Order ( SO ) - links Synchronization Actions ( SA ), the full list of SA is given in the specification, in section 17.4.2. Actions. Here are some of them:
SO is interesting to us, because it has the property that all readings in SO order see the last entries in SO . And I remind you, we are just trying to achieve this.
At this point I will repeat what we are trying to achieve. We have a multi-threaded program, we want to simulate all possible performances and get all the results that it can give. There are models that allow you to do this quite simply. But they require that all actions on the shared state be ordered.
According to the property of SO - if all actions in the program are SA then we will achieve our goal. Those. we can arrange for all variables the volatile modifierand we can use the model of alternations. If intuition tells you not to do this, then you are absolutely right. By these actions we simply forbid optimizing the code, of course, sometimes it is a good option, but this is definitely not a general case.
Consider another Synchronizes-With Order ( SW ) order - SO for specific unlock / lock pairs, write / read volatile. It does not matter in which flows these actions will take place, the main thing is that they are over one monitor, a volatile variable. SW gives a “bridge” between threads.
And now we come to the most interesting order - Happens-before ( HB ).
HB is a transitive closure of SW and PO unions . POgives a linear order inside the stream, and SW “bridge” between the streams. HB is transitive, i.e. if a
In the specification there is a list of HB relations, you can get acquainted with it in more detail, here are some of the list:
Within a single thread, any operation happens-before any operation following it in the source code.
Exit from synchronized block / method happens-before enter synchronized block / method on the same monitor.
Writing a volatile field happens-before reading the same volatile field.
Let's return to our example:
Let's return to our example and try to analyze the program, taking into account the orders.
Analysis of the program with the help of JMM is based on putting forward any hypotheses and their confirmation or denial.
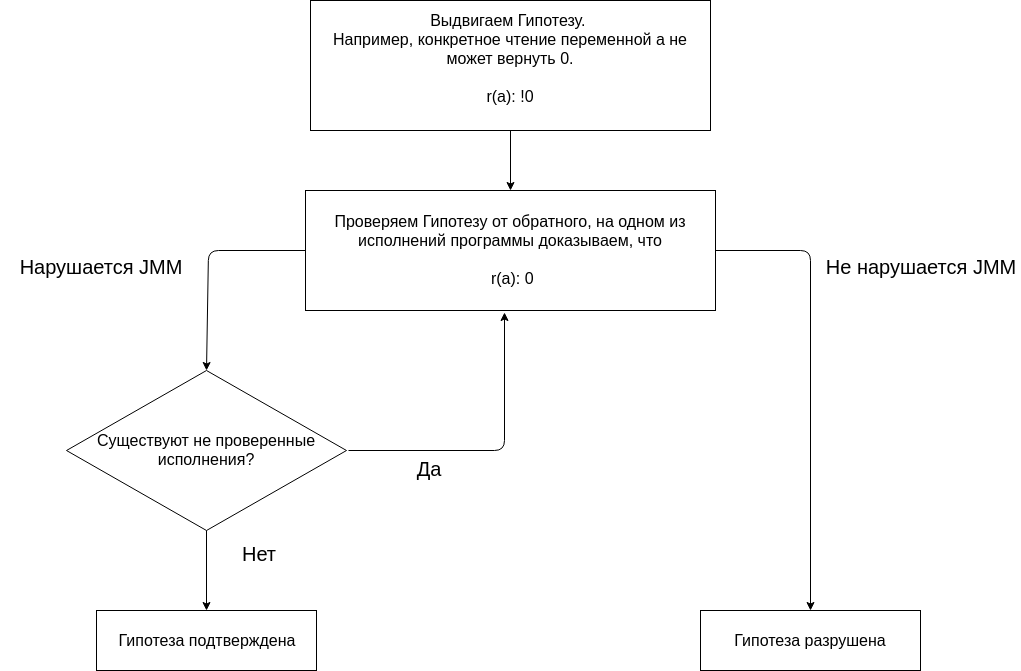
We begin the analysis with the hypothesis that no execution of the program gives the result (0, 0). The absence of a (0, 0) result on all executions is an expected property of the program.
We check the hypothesis by building different executions.
The nomenclature was peeped here (sometimes the
We make a small reservation.
Since all actions over common variables are important to us, and in the example common variables are a, b, x, y . Then, for example, the operation x = b should be considered as r (b) and w (x, b), moreover
Check the first performance.
The flow Q read variable a, write in this variable flow P . There is no order between writing and reading (PO, SW, HB) .
If the variable is written in one stream and the reading is in another stream and there is no HB relationship between the operations , then the variable is said to read under the race. And under the race according to JMM, we can read either the last recorded value in HB , or any other value.
Such a performance is possible. Execution does not violate JMM. When reading the variable a, you can see any value, since the reading takes place under the race and there is no guarantee that we will see the action w (a, 1). This does not mean that the program is working correctly, it just means that we expect such a result.
It makes no sense to consider the rest of the execution, since the hypothesis has already been destroyed .
JMM says that if a program does not have data races, then all executions can be viewed as sequential. Let's get rid of the race, for this we need to streamline read and write operations in different threads. It is important to understand that a multi-threaded program, as opposed to a sequential one, has several versions. And in order to say that a program has any property, it is required to prove that the program has this property not on one of the performances, but on all the performances.
To prove that the program is non-racing, you need to do this for all performances. Let's try to make an SA and mark the variable a with the volatile modifier . Volatile variables will be marked with the prefix v.
We put forward a new hypothesis. If the variable a is made volatile , then no execution of the program will give the result (0, 0).
Execution does not violate the JMM . Reading va takes place under the race. Any race destroys the transitivity of HB.
We put forward another hypothesis . If the variable b is made volatile , then no execution of the program will give the result (0, 0).
Execution does not violate the JMM. Reading a takes place under the race.
Let's test the hypothesis that if the variables a and b are volatile , then no execution of the program will give the result (0, 0).
Check the first performance.
Since all actions in the SA program (specifically reading or writing a volatile variable), we get the full SO order between all actions. This means that r (va) should see w (va, 1). This execution violates JMM .
It is necessary to proceed to the next execution to confirm the hypothesis. But since, for any execution, there will be SO , it is possible to abandon the formalism - it is obvious that the result (0, 0) violates the JMM for any execution.
To use the interleaving model, you need to add volatile for the variables a and b. Such a program will give results (1.1), (1.0) or (0.1).
As a result, it can be said that very simple programs are quite simple to analyze.
But complex programs with a large number of executions and shared data are quite difficult to analyze, since you need to check all performances.
Why consider other competitive programming models?
With the help of threads and synchronization primitives, all problems can be solved. This is all true, but the problem is that we looked at an example of a dozen lines of code, where 4 lines of code do useful work.
And we ran into a bunch of questions there, to the extent that we couldn’t correctly calculate all possible results without specification. Synchronization flows and primitives are a very complicated thing, the use of which is certainly justified in some cases. These cases are mainly related to performance.
Sorry, I refer a lot to Elizarov, but what to do if a person really has experience in this area. So, he has another great report.“Millions of quotes per second on pure Java”, in which he says that the unchanged state is good, but I will not copy my millions of quotations into each stream, sorry. But not all millions of quotations, many of course the task is more modest. Are there any competitive programming models that allow you to forget about JMM and still write a safe competitive code?
If this question is really very interesting to you, I highly recommend Paul Butcher’s book “Seven models of competition in seven weeks. Reveal the secrets of the flow. " Unfortunately, it was not possible to find enough information about the author, but the book should open your eyes to new paradigms. I, unfortunately, have no experience with many other models of competition, so I got a review from this book.
Answering the question above. As far as I understand, there are competitive programming models that at least greatly reduce the need for knowledge of the nuances of JMM. However, if there is a changeable state and flows, then what abstractions above them are not wrapped around, all the same there will be a place where these threads should synchronize access to the state. Another question is that you may not have to synchronize access yourself, for example, the framework may be responsible. But as we have said, sooner or later, abstraction can flow.
You can exclude a changeable state at all. In the world of functional programming, this is normal practice. If there are no mutable structures, then there probably won't be any problems with shared memory either. The JVM has representatives of functional languages, for example Clojure. Clojure is a hybrid functional language, because it still allows you to change data structures, but provides more efficient and safe tools for this.
Functional languages are an excellent tool for working with competitive code. Personally, I do not use it, because my field of activity is mobile development, and there it is simply not the mainstream. Although certain approaches can be adopted.
Another way to work with editable data is to eliminate data sharing. Such a programming model is actors. Actors simplify programming by not allowing simultaneous access to data. This is achieved by the fact that a function that performs work at a time can work only in one thread.
However, the actor can change the internal state. Considering that at the next time point, the same actor can be executed on another thread, this can be a problem. The problem can be solved in different ways, in programming languages such as Erlang or Elixir, where the model of actors is an integral part of the language, recursion can be used to call the actor with a new state.
In Java, recursion can be too expensive. But in Java there are frameworks for convenient work with this model, probably the most popular one is Akka. The Akka developers have taken care of everything; you can go to the Akka and the Java Memory Model documentation section and read about two cases in which access to a shared state from different threads may occur. But more importantly, the documentation says which events are related to “what happened before.” Those. this means that we can change the state of the actor as many times as necessary, but when we accept the following message and possibly process it in another thread, we are guaranteed to see all the changes made in another thread.
We considered two models of competitive programming, in fact, even more of them, which make competitive programming easier and safer.
But why then are threads and locks still so popular?
It seems to me that the reason is the simplicity of the approach, of course, on the one hand with the flows, it is easy to make many unobvious mistakes, shoot one’s leg, etc. But on the other hand there is nothing complicated in the flows, especially if you do not think about the consequences .
At one point in time, the kernel can execute one instruction (in fact, no, parallelism exists at the instruction level, but this is not important now), but thanks to multitasking, even on single-core machines, several programs can be executed simultaneously (of course, pseudo simultaneously).
For multitasking to work, competition is needed. As we have already figured out the competition is impossible without several control flows.
How do you think how many threads need a program that runs on a quad-core mobile phone processor to be as fast and responsive as possible?
There may be several dozen. Now the question is, why do you need so many threads for a program that runs on hardware that allows you to perform only 2-4 threads at the same time?
To try to answer this question, suppose that only our program is running on the device and nothing else. How would we manage the resources provided to us?
You can give one core for the user interface, the rest of the core for any other tasks. If one of the threads is blocked, for example, the thread can access the memory controller and wait for a response, then we will get a blocked kernel.
What technologies are there to solve the problem?
There are threads in Java, we can create multiple threads, and then other threads will be able to perform operations while a thread is blocked. Having a tool like streams, we can simplify our lives.
The approach with threads is not free, creating threads usually takes time (decided by thread pools), memory is allocated for them, switching between threads is an expensive operation. But it is relatively easy to program with them, so this is a mass technology that is so widely used in general purpose languages, such as Java.
In Java, they generally like threads, it is not necessary to create for each action in a stream, there are higher-level things, such as Executors, that allow you to work with pools and write more scalable and flexible code. The streams are really convenient; you can make a blocking request to the network and write the processing of the result in the next line. Even if we wait for the result for a few seconds, we will still be able to perform other tasks, since the operating system takes care of the allocation of processor time between threads.
Threads are popular not only in backend development, in mobile development it is considered quite normal to create dozens of threads so that you can block a stream for a couple of seconds while waiting for data to load over the network or data from a socket.
Languages like Erlang or Clojure are still niche, and accordingly competitive programming models that they use are not so popular. However, the forecasts for them are the most optimistic.
If you are developing on the JVM platform, then you need to accept the rules of the game, indicated by the platform. This is the only way to write normal multi-threaded code. It is very desirable to understand the context of everything that happens, it will be easier to accept the rules of the game. It is even better to look around and familiarize yourself with other paradigms, even though there is no way out of a submarine, but you can discover new approaches and tools.
I tried to place in the text of the article links to sources from which I scooped information.
In general, JMM material is easy to find on the Internet. Here I will post links to some additional material that is associated with the JMM and may not immediately catch my eye.
Reading
Podcasts
Releases that seemed to me especially interesting. They are not about JMM, they are about Hell, which is created in the gland. But after listening to them, I want to kiss the hands of the creators of JMM, who protected us from all this.
Video
In addition to the speeches of the above-mentioned people, pay attention to the academic video.
In a multithreaded environment, you can perforce observe interesting things. For example, the execution of program instructions is not in the order as written in the source code. You must admit that it is not pleasant to realize that the execution of the source code line by line is just our imagination.
But everyone has already realized, because it is necessary to live with it somehow. And Java programmers even live quite well. Because Java has a memory model - the Java Memory Model (JMM), which provides fairly simple rules for writing correct multi-threaded code.
And these rules are enough for most programs. If you do not know them, but write or want to write multi-threaded programs in Java, it is better to get acquainted with them as soon as possible . And if you know, but you do not have enough context or it is interesting to find out where your JMM legs grow from, then the article can help you.
And abstraction chases
In my view, there is a pie, or more appropriately an iceberg. JMM is the tip of the iceberg. Under the water iceberg itself - the theory of multi-threaded programming. Under the iceberg - Hell.
An iceberg is an abstraction, if it leaks, then Hell we will certainly see. Although there is a lot of interesting things going on, in a review article we will not get to that.
In the article I am more interested in the following topics:
- Theory and terminology
- How multithreaded programming theory affects JMM
- Competitive programming models
The theory of multi-threaded programming allows you to get away from the complexity of modern processors and compilers, it allows you to simulate the execution of multi-threaded programs and study their properties. Roman Elizarov made an excellent report , the purpose of which is to provide a theoretical basis for understanding JMM. I recommend the report to anyone interested in this topic.
Why is it so important to know the theory? In my opinion, I hope only for mine, some programmers have the opinion that JMM is a complication of the language and patching some platform problems with multithreading. The theory shows that in Java they did not complicate, but they simplified and made very complex multi-threaded programming more predictable.
Competition and concurrency
First, let's look at the terminology. Unfortunately, there is no consensus in terminology - by studying different materials, you can meet different definitions of competition and concurrency.
The problem is that even if we get to the bottom of the truth and find exact definitions of these concepts, it’s still hardly necessary to expect that everyone will mean the same thing by these concepts. All there is not find .
Roman Elizarov, in the report on the theory of parallel programming for practitioners, says that sometimes these concepts are confused. Sometimes parallel programming is distinguished as a general concept, which is divided into competitive and distributed.
It seems to me that in the context of JMM, one should still separate competition and concurrency, or rather even understand that there are two different paradigms, whatever they are called.
Often cited by Rob Pike, who distinguishes the concepts as follows:
- Competition is a way to solve multiple problems simultaneously.
- Parallelism is a way to perform different parts of the same task.
The opinion of Rob Pike is not a benchmark, but in my opinion, it is convenient to make a start from him to further study the issue. You can read more about the differences here .
Most likely, more understanding in the question will appear if we highlight the main features of a competitive and parallel program. There are a lot of signs, consider the most significant.
Signs of competition.
- The presence of several control threads (for example, Thread in Java, Korutin in Kotlin), if the control flow is one, then there can be no competitive execution
- Nondeterministic output. The result depends on random events, implementation, and how synchronization was performed. Even if each stream is fully deterministic, the final result will be non-deterministic.
A parallel program will have a different set of features.
- Optionally has multiple control threads
- It can lead to a deterministic result, for example, the result of multiplying each element of the array by a number will not change if multiplied in parallel
Oddly enough, parallel execution is possible on a single control thread, and even on a single-core architecture. The fact is that parallelism at the level of tasks (or control flows) to which we are used to is not the only way to perform computations in parallel.
Parallelism is possible at the level of:
- bits (for example, in 32-bit machines, addition occurs in one action, processing all 4 bytes of a 32-bit number in parallel)
- instructions (on one core, in one thread, the processor can execute instructions in parallel, despite the fact that the code is sequential)
- data (there are architectures with parallel data processing (Single Instruction Multiple Data) that can execute one instruction on a large data set)
- tasks (implies the presence of multiple processors or cores)
Parallelism at the instruction level is one of the examples of optimizations that occur with the execution of the code, and which are hidden from the programmer.
It is guaranteed that the optimized code will be equivalent to the source code within a single thread, because it is impossible to write adequate and predictable code if it does not do what the programmer meant.
Not everything that runs in parallel matters to JMM. Parallel execution at the instruction level within a single thread is not covered in the JMM.
The terminology is very shaky, in Roman Elizarov the report is called “Theory of parallel programming for practitioners”, although there it’s more about competitive programming, if we stick to the above.
In the context of JMM in the article, I will stick to the term competition, since competition is often about general condition. But here one must be careful not to cling to the terms, but understand that there are different paradigms.
Models with a common state: “alternation of operations” and “occurred before”
In his article, Maurice Hurlihi (author of The Art Of Multiprocessor programming) writes that the competitive system contains a collection of sequential processes (in theoretical works means the same thing as a stream), which communicate through common memory.
A shared state model includes computations with message passing, where the shared state is a message queue and shared memory calculations, where the common state is structures in memory.
Each of the calculations can be modeled.
The model is based on a state machine. The model focuses solely on the shared state and completely ignores the local data of each stream. Each action of flows over a shared state is a function of transition to a new state.
For example, if 4 threads write data to a shared variable, then there will be 4 transition functions to the new state. Which of these functions will be used depends on the chronology of events in the system.
Calculations with message passing are modeled in a similar way, only the state and transition functions depend on the sending or receiving of messages.
If the model seemed complicated to you, then in the example we will fix it. It is really very simple and intuitive. So much so that without knowing about the existence of this model, most people will still analyze the program as the model suggests.
This model is called the model of execution through the alternation of operations (the name was heard in the report of Roman Elizarov).
In the advantages of the model, you can safely record intuitiveness and naturalness. In the jungle, you can go on the keyword Sequential consistency and the work of Leslie Lamport.
However, there is an important clarification about this model. The model has a limitation that all actions on the shared state must be instantaneous and at the same time actions cannot occur simultaneously. They say that such a system has a linear order - all actions in the system are ordered.
In practice, this does not happen. The operation does not occur instantly, but is performed in the interval, on multi-core systems, these intervals may overlap. Of course, this does not mean that the model is useless in practice, you just need to create certain conditions for its use.
In the meantime, consider another model - “happened before” , which focuses not on state, but on a set of read and write operations of memory cells during execution (history) and their relationships.
The model says that events in different streams do not pass instantly and atomically, but in parallel, and it is not possible to build order between them. Events (writing and reading shared data) in threads on a multiprocessor or multi-core architecture actually occur in parallel. The system lacks the concept of global time; we cannot understand when one operation ended and another began.
In practice, this means that we can write to a variable in one stream and do it, say in the morning, and read from this variable in another stream in the evening, and we cannot say that we will read the value recorded in the morning for sure. In theory, these operations take place in parallel and it is not clear when one operation will end and another operation will begin.
It is difficult to imagine how it turns out that simple read and write operations done at different times of the day take place simultaneously. But if you think about it, then we really don’t care about the time when the events of writing and reading occur, if we cannot guarantee that we will see the result of the recording.
And we really can not see the result of the recording, i.e. the variable value of which is 0 in the stream Pwe write 1 , and in the stream Q we read this variable. No matter how much physical time passes after the recording, we can still read 0 .
This is how computers work and the model reflects this.
The model is completely abstract and needs visualization for convenient operation. For visualization, and only for it, a model with global time is used, with reservations that the global time is not used when proving program properties. In the visualization, each event is represented as an interval with a start and end.
Events run in parallel, as we found out. But still, the system has a partial order.since there are particular pairs of events that have order, then they say that these events are related to “what happened before.” If for the first time you hear about the “happened before” attitude, then probably the knowledge of the fact that this attitude sort of organizes events will not help you much.
We try to analyze Java program
We have considered some theoretical minimum, let's try to move further and consider a multi-threaded program in a specific language - Java, from two streams with a common changeable state.
Classic example.
privatestaticint x = 0, y = 0;
privatestaticint a = 0, b = 0;
synchronized (this) {
a = 0;
b = 0;
x = 0;
y = 0;
}
Thread p = new Thread(() -> {
a = 1;
x = b;
});
Thread q = new Thread(() -> {
b = 1;
y = a;
});
p.start();
q.start();
p.join();
q.join();
System.out.println("x=" + x + ", y=" + y);
We need to simulate the execution of this program and get all the possible results - the values of the variables x and y. There will be several results, as we remember from the theory, such a program is non-deterministic.
How are we going to model? Just want to use the model of alternation of operations. But the “happened before” model tells us that events in one stream are parallel to events from another stream. Therefore, the model of alternation of operations is not appropriate here, if there is no relationship between “operations before” between operations.
The result of executing each thread is always deterministic, since events in one thread are always ordered, consider that they get the relation “happened before” as a gift. But how events in different streams can get the attitude “happened before” is not entirely obvious. Of course, this relationship is formalized in the model, the whole model is written in mathematical language. But what to do with this in practice, in a specific language, cannot be immediately disassembled.
What are the options?
Ignore constraints and simulate interlacing. You can try something, maybe nothing terrible will happen.
To understand what kind of results you can get, let's simply iterate through all possible execution options.
All possible program performances can be represented as a finite state machine.
Each circle is the state of the system, in our case the variables a, b, x, y . The transition function is an action on a state that takes the system to a new state. Since two streams can perform actions on a general state, there will be two transitions from each state. Double circles are the final and initial states of the system.
A total of 6 different executions are possible, which result in a pair of x, y values: We can run the program and check the results. As befits a competitive program, it will have a non-deterministic result. To test competitive programs it is better to use special tools ( tool , report ).
(1, 1), (1, 0), (0, 1)
But you can try to run the program several million times, or even better, write a cycle that will do it for us.
If we run the code on a single-core or single-processor architecture, then we must get the result from the set that we expect. The rotation pattern will work just fine. On a multi-core architecture, such as x86, a surprise may await us - we can get a result (0,0), which cannot be according to our modeling.
The explanation for this can be searched on the Internet by keyword - reordering . Now it is important to understand that the alternation modeling is really not suitable in a situation where we cannot determine the order of access to the shared state .
Theory of Competitive Programming and JMM
The time has come to consider the relationship “happened before” and how it is friendly with the JMM. The original definition of the relation “happened before” can be found in the document Time, Clocks, and the Distributed System.
The memory model of a language helps in writing a competitive code, since it determines which operations have a relation “happened before”. The list of such operations is presented in the specification in the section Happens-before Order. In fact, this section answers the question - under what conditions will we see the result of a recording in another stream.
There are different orders in JMM. Alexey Shipilev tells very cheerfully about the order in one of his reports .
In a model with global time, all operations in one thread have order. For example, the events of writing and reading a variable can be represented as two intervals, then the model ensures that these intervals never intersect within the same flow. In JMM, this order is called Program Order ( PO ).
PO connects actions in one thread and says nothing about the order of execution, says only about the order in the source code. This is quite enough to guarantee determinism for each stream separately . PO can be viewed as raw data. PO is always easy to place in the program - all operations (linear order) in the source code within one stream will have a PO .
In our example, we get something like this:
P: a = 1 PO x = b- writing to a and reading b has PO order Q: b = 1 PO y = a- writing to b and reading a has PO order Spied on this form of writing w (a, 1) PO r (b): 0. I really hope that no one patented for reports. However, the specification has a similar form.
But each stream separately is not particularly interesting to us, since the threads have a common state, we are more interested in the interaction of the threads. All we want is to be sure that we will see the recording of variables in other threads.
Let me remind you that this did not work out for us, because the operations of writing and reading variables in different streams are not instantaneous (these are segments that intersect), so it’s impossible to make out where the beginning and end of operations is.
The idea is simple - at the moment when we read the variable a in the stream Q , writing this variable itself in the stream P might not end yet. And no matter how much physical time these events share - nanosecond or a few hours.
To streamline the events we need the relationship “happened before”. JMM defines this attitude. In the specification, the order is fixed in one stream:
If operation x and y pass in one stream and x occurs first in PO and then y, then x occurs before y.
Looking ahead, we can say that we can replace all POs with Happens-before ( HB ):
P: w(a, 1) HB r(b)
Q: w(b, 1) HB r(a)But again we are spinning under one thread. HB is possible between operations occurring in different streams, in order to deal with these cases, we will get acquainted with other orders.
Synchronization Order ( SO ) - links Synchronization Actions ( SA ), the full list of SA is given in the specification, in section 17.4.2. Actions. Here are some of them:
- Read volatile variable
- Record volatile variable
- Monitor lock
- Unlock monitor
SO is interesting to us, because it has the property that all readings in SO order see the last entries in SO . And I remind you, we are just trying to achieve this.
At this point I will repeat what we are trying to achieve. We have a multi-threaded program, we want to simulate all possible performances and get all the results that it can give. There are models that allow you to do this quite simply. But they require that all actions on the shared state be ordered.
According to the property of SO - if all actions in the program are SA then we will achieve our goal. Those. we can arrange for all variables the volatile modifierand we can use the model of alternations. If intuition tells you not to do this, then you are absolutely right. By these actions we simply forbid optimizing the code, of course, sometimes it is a good option, but this is definitely not a general case.
Consider another Synchronizes-With Order ( SW ) order - SO for specific unlock / lock pairs, write / read volatile. It does not matter in which flows these actions will take place, the main thing is that they are over one monitor, a volatile variable. SW gives a “bridge” between threads.
And now we come to the most interesting order - Happens-before ( HB ).
HB is a transitive closure of SW and PO unions . POgives a linear order inside the stream, and SW “bridge” between the streams. HB is transitive, i.e. if a
x HB y и y HB z, тогда x HB zIn the specification there is a list of HB relations, you can get acquainted with it in more detail, here are some of the list:
Within a single thread, any operation happens-before any operation following it in the source code.
Exit from synchronized block / method happens-before enter synchronized block / method on the same monitor.
Writing a volatile field happens-before reading the same volatile field.
Let's return to our example:
P: a = 1 PO x = b
Q: b = 1 PO y = aLet's return to our example and try to analyze the program, taking into account the orders.
Analysis of the program with the help of JMM is based on putting forward any hypotheses and their confirmation or denial.
We begin the analysis with the hypothesis that no execution of the program gives the result (0, 0). The absence of a (0, 0) result on all executions is an expected property of the program.
We check the hypothesis by building different executions.
The nomenclature was peeped here (sometimes the
…word racewith an arrow is found instead , Alexey himself uses the arrow and the word race in the reports, but warns that there is no such order in the JMM and uses this designation for clarity). We make a small reservation.
Since all actions over common variables are important to us, and in the example common variables are a, b, x, y . Then, for example, the operation x = b should be considered as r (b) and w (x, b), moreover
r(b) HB w(x,b)(based on PO ). But since the variable x in threads is not readable anywhere (reading in print at the end of the code is not interesting, since after the join operation on the stream we will see the value x), we can not consider the action w (x, b). Check the first performance.
w(a, 1) HB r(b): 0 … w(b, 1) HB r(a): 0The flow Q read variable a, write in this variable flow P . There is no order between writing and reading (PO, SW, HB) .
If the variable is written in one stream and the reading is in another stream and there is no HB relationship between the operations , then the variable is said to read under the race. And under the race according to JMM, we can read either the last recorded value in HB , or any other value.
Such a performance is possible. Execution does not violate JMM. When reading the variable a, you can see any value, since the reading takes place under the race and there is no guarantee that we will see the action w (a, 1). This does not mean that the program is working correctly, it just means that we expect such a result.
It makes no sense to consider the rest of the execution, since the hypothesis has already been destroyed .
JMM says that if a program does not have data races, then all executions can be viewed as sequential. Let's get rid of the race, for this we need to streamline read and write operations in different threads. It is important to understand that a multi-threaded program, as opposed to a sequential one, has several versions. And in order to say that a program has any property, it is required to prove that the program has this property not on one of the performances, but on all the performances.
To prove that the program is non-racing, you need to do this for all performances. Let's try to make an SA and mark the variable a with the volatile modifier . Volatile variables will be marked with the prefix v.
We put forward a new hypothesis. If the variable a is made volatile , then no execution of the program will give the result (0, 0).
w(va, 1) HB r(b): 0 … w(b, 1) HB r(va): 0Execution does not violate the JMM . Reading va takes place under the race. Any race destroys the transitivity of HB.
We put forward another hypothesis . If the variable b is made volatile , then no execution of the program will give the result (0, 0).
w(a, 1) HB r(vb): 0 … w(vb, 1) HB r(a): 0Execution does not violate the JMM. Reading a takes place under the race.
Let's test the hypothesis that if the variables a and b are volatile , then no execution of the program will give the result (0, 0).
Check the first performance.
w(va, 1) SO r(vb): 0 SO w(vb, 1) SO r(va): 0Since all actions in the SA program (specifically reading or writing a volatile variable), we get the full SO order between all actions. This means that r (va) should see w (va, 1). This execution violates JMM .
It is necessary to proceed to the next execution to confirm the hypothesis. But since, for any execution, there will be SO , it is possible to abandon the formalism - it is obvious that the result (0, 0) violates the JMM for any execution.
To use the interleaving model, you need to add volatile for the variables a and b. Such a program will give results (1.1), (1.0) or (0.1).
As a result, it can be said that very simple programs are quite simple to analyze.
But complex programs with a large number of executions and shared data are quite difficult to analyze, since you need to check all performances.
Other competitive performance models
Why consider other competitive programming models?
With the help of threads and synchronization primitives, all problems can be solved. This is all true, but the problem is that we looked at an example of a dozen lines of code, where 4 lines of code do useful work.
And we ran into a bunch of questions there, to the extent that we couldn’t correctly calculate all possible results without specification. Synchronization flows and primitives are a very complicated thing, the use of which is certainly justified in some cases. These cases are mainly related to performance.
Sorry, I refer a lot to Elizarov, but what to do if a person really has experience in this area. So, he has another great report.“Millions of quotes per second on pure Java”, in which he says that the unchanged state is good, but I will not copy my millions of quotations into each stream, sorry. But not all millions of quotations, many of course the task is more modest. Are there any competitive programming models that allow you to forget about JMM and still write a safe competitive code?
If this question is really very interesting to you, I highly recommend Paul Butcher’s book “Seven models of competition in seven weeks. Reveal the secrets of the flow. " Unfortunately, it was not possible to find enough information about the author, but the book should open your eyes to new paradigms. I, unfortunately, have no experience with many other models of competition, so I got a review from this book.
Answering the question above. As far as I understand, there are competitive programming models that at least greatly reduce the need for knowledge of the nuances of JMM. However, if there is a changeable state and flows, then what abstractions above them are not wrapped around, all the same there will be a place where these threads should synchronize access to the state. Another question is that you may not have to synchronize access yourself, for example, the framework may be responsible. But as we have said, sooner or later, abstraction can flow.
You can exclude a changeable state at all. In the world of functional programming, this is normal practice. If there are no mutable structures, then there probably won't be any problems with shared memory either. The JVM has representatives of functional languages, for example Clojure. Clojure is a hybrid functional language, because it still allows you to change data structures, but provides more efficient and safe tools for this.
Functional languages are an excellent tool for working with competitive code. Personally, I do not use it, because my field of activity is mobile development, and there it is simply not the mainstream. Although certain approaches can be adopted.
Another way to work with editable data is to eliminate data sharing. Such a programming model is actors. Actors simplify programming by not allowing simultaneous access to data. This is achieved by the fact that a function that performs work at a time can work only in one thread.
However, the actor can change the internal state. Considering that at the next time point, the same actor can be executed on another thread, this can be a problem. The problem can be solved in different ways, in programming languages such as Erlang or Elixir, where the model of actors is an integral part of the language, recursion can be used to call the actor with a new state.
In Java, recursion can be too expensive. But in Java there are frameworks for convenient work with this model, probably the most popular one is Akka. The Akka developers have taken care of everything; you can go to the Akka and the Java Memory Model documentation section and read about two cases in which access to a shared state from different threads may occur. But more importantly, the documentation says which events are related to “what happened before.” Those. this means that we can change the state of the actor as many times as necessary, but when we accept the following message and possibly process it in another thread, we are guaranteed to see all the changes made in another thread.
Why is the threading model so popular?
We considered two models of competitive programming, in fact, even more of them, which make competitive programming easier and safer.
But why then are threads and locks still so popular?
It seems to me that the reason is the simplicity of the approach, of course, on the one hand with the flows, it is easy to make many unobvious mistakes, shoot one’s leg, etc. But on the other hand there is nothing complicated in the flows, especially if you do not think about the consequences .
At one point in time, the kernel can execute one instruction (in fact, no, parallelism exists at the instruction level, but this is not important now), but thanks to multitasking, even on single-core machines, several programs can be executed simultaneously (of course, pseudo simultaneously).
For multitasking to work, competition is needed. As we have already figured out the competition is impossible without several control flows.
How do you think how many threads need a program that runs on a quad-core mobile phone processor to be as fast and responsive as possible?
There may be several dozen. Now the question is, why do you need so many threads for a program that runs on hardware that allows you to perform only 2-4 threads at the same time?
To try to answer this question, suppose that only our program is running on the device and nothing else. How would we manage the resources provided to us?
You can give one core for the user interface, the rest of the core for any other tasks. If one of the threads is blocked, for example, the thread can access the memory controller and wait for a response, then we will get a blocked kernel.
What technologies are there to solve the problem?
There are threads in Java, we can create multiple threads, and then other threads will be able to perform operations while a thread is blocked. Having a tool like streams, we can simplify our lives.
The approach with threads is not free, creating threads usually takes time (decided by thread pools), memory is allocated for them, switching between threads is an expensive operation. But it is relatively easy to program with them, so this is a mass technology that is so widely used in general purpose languages, such as Java.
In Java, they generally like threads, it is not necessary to create for each action in a stream, there are higher-level things, such as Executors, that allow you to work with pools and write more scalable and flexible code. The streams are really convenient; you can make a blocking request to the network and write the processing of the result in the next line. Even if we wait for the result for a few seconds, we will still be able to perform other tasks, since the operating system takes care of the allocation of processor time between threads.
Threads are popular not only in backend development, in mobile development it is considered quite normal to create dozens of threads so that you can block a stream for a couple of seconds while waiting for data to load over the network or data from a socket.
Languages like Erlang or Clojure are still niche, and accordingly competitive programming models that they use are not so popular. However, the forecasts for them are the most optimistic.
findings
If you are developing on the JVM platform, then you need to accept the rules of the game, indicated by the platform. This is the only way to write normal multi-threaded code. It is very desirable to understand the context of everything that happens, it will be easier to accept the rules of the game. It is even better to look around and familiarize yourself with other paradigms, even though there is no way out of a submarine, but you can discover new approaches and tools.
Additional materials
I tried to place in the text of the article links to sources from which I scooped information.
In general, JMM material is easy to find on the Internet. Here I will post links to some additional material that is associated with the JMM and may not immediately catch my eye.
Reading
- Alexey Shipilyov's blog - I know what is obvious, but just a sin not to mention
- Cheremin Ruslan's blog - he hasn’t been actively writing lately, you need to search his old posts in a blog, believe me it is worth it - there is a storehouse
- Habr Gleb Smirnov - there are excellent articles about multithreading and memory model
- The blog of Roman Elizarov is abandoned, but archaeological excavations should be carried out. In general, Roman has done a lot for the enlightenment of the people in the field of the theory of multi-threaded programming, look for it in the media.
Podcasts
Releases that seemed to me especially interesting. They are not about JMM, they are about Hell, which is created in the gland. But after listening to them, I want to kiss the hands of the creators of JMM, who protected us from all this.
- SDCast # 62 : visiting Alexander Titov and Amir Ayupov, engineers from Intel and Alexey Markin, programmer from MCST
- SDCast # 63 : Away Alexey Markin, a programmer from the MCST
- Debriefing: # 107 Stories climbers
- Debriefing: # 154 Intestines - Attack on New Year
Video
In addition to the speeches of the above-mentioned people, pay attention to the academic video.