Unit tests. Quick start - effective result (with examples in C ++)

Instead of joining
Hello! Today I would like to talk about how to simply and with pleasure write test code. The fact is that in our company we constantly monitor and greatly appreciate the quality of our products. Indeed, millions of people work with them every day, and it’s simply unacceptable for us to let our users down. Just imagine, the deadline for reporting has come, and you will carefully and with pleasure using the carefully designed user interface of VLSI, prepared the documents, double-checked each number and again made sure that there would be no meeting with polite people from the tax office in the near future. And now, with a light click of the mouse, click on the coveted “Submit” button and here BACH! the application crashes, documents are destroyed, the monitor burns with a hot flame, and it seems that people in uniform are already persistently knocking on the door, demanding reporting. Something like this can somehow turn out:

Fuh ... Well, I agree, I probably got excited with the monitor;) But still, the situation that has arisen may leave the user of our product not in the most blissful state of mind.
So, since we value the moral state of our customers in Tensor, it is very important for us that the products developed by us are comprehensively tested - in our company, this is largely ensured by almost 300 testers monitoring the quality of our products. However, we try to ensure that quality is controlled at all stages of development. Therefore, in the development process, we try to use automated unit testing, not to mention integration, load and acceptance tests.
However, to date, from our experience in interviews, it can be noted that not everyone has the skills to create testable code. Therefore, we want to talk “on the fingers” about the principles of creating the test code, and also show how you can create unit tests that are easy to maintain and upgrade.
The material presented below was largely presented at the C ++ Russia conference, so you can read, listen and even watch it.
Characteristics of Good Unit Tests
One of the first tasks that you have to deal with when writing any automatically executed test is processing external dependencies. By external dependency we mean entities with which the tested code interacts, but over which it does not have full control. Such uncontrolled external dependencies include operations that require interaction with a hard disk, database, network connection, random number generator, and more.
I must say that automated testing can be performed at different levels of the system, but we will consider issues related specifically to unit tests.
For a clearer understanding of the principles underlying the examples below, the code has been simplified (for example, const qualifiers are omitted) The test examples themselves are implemented using the GoogleTest library .
One of the most important differences between the integration test and the unit test is that the unit test has full control over all external dependencies. This allows you to achieve that a single unit test has the following properties:
- we repeat - as a result of starting the test, the output always gives the same value (always brings the system to the same state);
- stable - no matter what time of day or night the test starts, it either always passes or always does not pass;
- isolated - the order of starting all available unit tests, as well as the actions performed inside the tests, do not affect the result of a single unit test.
All this leads to the fact that the launch of many unit tests with the described properties can be automated and carried out, in fact, by pressing a single button.
A good unit test is fast. Because if there are a lot of tests in the project, and the run of each of them will be long, then the run of all tests will take a considerable time. This can lead to the fact that when unit code is run, all unit tests will be run less and less, because of this, the time it takes for the system to respond to the changes will increase, and thus the time for detecting an introduced error will increase.
They say that for some with testing applications everything is much simpler, but for us, mere mortals who do not have such a fast turntable , it is not so sweet. So we will understand further.

Unit testing. Where does it all begin
Writing any unit test begins with the selection of its name. One of the recommended approaches to the unit test name is to form its name in three parts:
- name of the work unit being tested
- test script
- expected result
Thus, we can get, for example, such names: Sum_ByDefault_ReturnsZero , Sum_WhenCalled_CallsTheLogger . They are read as a complete sentence, and this increases the ease of working with tests. To understand what is being tested, it is enough, without understanding the logic of the code, just read the names of the tests.
But in some cases, you still need to understand the logic of the test code. To simplify this work, the unit test structure can be formed of three parts:
- partArrange - here the creation and initialization of the objects required for the test is performed
- part of Act - the actual conduct of the test action
- part of Assert - here, the result is compared with the reference one.
In order to increase the readability of the tests, it is recommended to separate these parts from each other with an empty line. This will orient those who read your code and help you quickly find the part of the test that interests them the most.
When covering the logic of the code with unit tests, each module of the tested code must perform one of the following actions. So, you can test:
- the returned result
- the change in the state of the system
- interaction between objects
In the first two cases, we are faced with the task of separation . It consists in not introducing code into the testing tools, over which we do not have full control. In the latter case, it is necessary to solve the recognition problem . It consists in accessing values that are not available for the tested code: for example, when you need to control the receipt of logs by a remote web server.
To write test code, you should be able to implement and apply the intended objects fake ( fake objects ).
There are several approaches to the classification of fake objects. We will consider one of the basic ones, which corresponds to the tasks solved in the process of creating the tested code.
She distinguishes two classes of fake objects: stub objects and mock objects . They are designed to solve various problems: a stub object to solve the separation problem, and a mock object to solve the recognition problem. The biggest difference is that when using the stub-object assert (the operation of comparing the obtained result with the reference) is performed between the test and the tested code, and the use of the mock-object assumes its analysis, which shows whether the test passed.
If the logic of work can be tested based on the analysis of the return value or change in the state of the system, then do so. As practice shows, unit tests that use mock objects are more difficult to create and maintain than tests that use stub objects.
Let's consider the given principles on an example of work with the legacy code. Suppose we have the EntryAnalyzer class , shown in Fig. 1, and we want to cover with the unit tests his public method Analyze . This is due to the fact that we plan to change this class, or we want to document its behavior in this way.
To cover the code with tests, we define its external dependencies. In our case, there are two of these dependencies: working with a database and working with a network connection, which is performed in the WebService and DatabaseManager classes, respectively.
class EntryAnalyzer {
public:
bool Analyze( std::stringename ) {
if( ename.size() < 2 ) {
webService.LogError( "Error: "+ ename );
return false;
}
if( false== dbManager.IsValid( ename ) )
return false;
return true;
}
private:
DatabaseManager dbManager;
WebService webService;
};Fig. 1. The code of the tested class, which is not suitable for covering with unit tests.
Thus, for the EntryAnalyzer class , they are external dependencies. Potentially, between the dbManager.IsValid check and the final return true statement, there may be code that requires testing. When writing tests, we can access it only after getting rid of existing external dependencies. To simplify further presentation, such additional code is not given.
Now let's look at ways to break external dependencies. The structure of these classes is shown in Fig. 2.
class WebService {
public:
void LogError( std::string msg ) {
/* логика, включающая
работу с сетевым соединением*/
}
};
class DatabaseManager {
public:
bool IsValid( std::string ename ) {
/* логика, включающая
операции чтения из базы данных*/
}
};Fig. 2. Class structure for working with a network connection and a database.
For writing test code, it is very important to be able to develop based on contracts, and not on specific implementations. In our case, the contract of the source class is to determine whether the name of the cell ( entry ) is valid or not .
In C ++, this contract can be documented as an abstract class that contains the IsValid virtual methodwhose body is not required to be determined. Now you can create two classes that implement this contract: the first will interact with the database and be used in the “production” version of our program, and the second will be isolated from uncontrolled dependencies and will be used directly for testing. The described circuit is shown in Fig. 3.
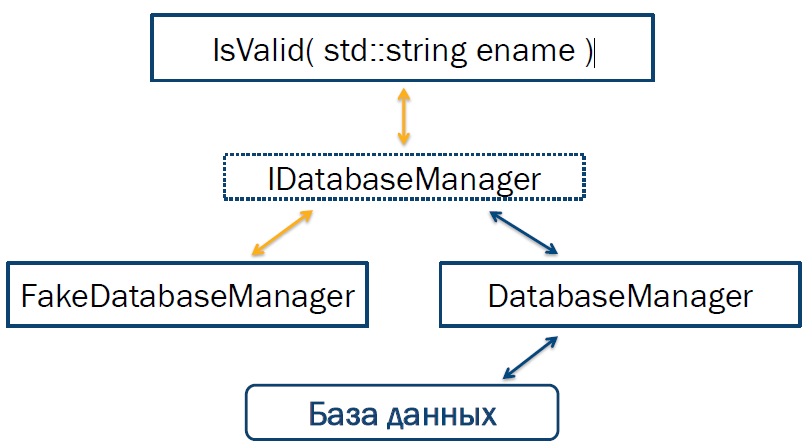
Fig. 3. Introducing an interface for breaking the dependence on interaction with the database
An example code that allows breaking the dependence, in our case on the database, is shown in Fig. 4.

Fig. 4. Example of classes that allow breaking the dependency on the database
In the above code, you should pay attention to the override specifierfor methods that implement the functionality specified in the interface. This increases the reliability of the generated code, since it explicitly tells the compiler that the signatures of these two functions must match.
You should also pay attention to declaring the abstract class destructor virtual. If this looks surprising and unexpected, then you can drive after S. Myers book “Effective Use of C ++” and read it excitedly, with particular attention to rule No. 7 given there;).
Spoiler for the most impatient
this is necessary to avoid memory leaks when destroying an object of a derived class through a pointer to the base class.
Breaking a dependency using stub objects
Consider the steps required to test our EntryAnalyzer class . As mentioned above, the implementation of tests using stub objects is somewhat simpler than using mock objects. Therefore, we first consider ways to break the dependence on the database.
Method 1. Parameterization of the constructor
First, get rid of the hard-coded use of the DatabaseManager class . To do this, let's move on to working with a pointer, such as IDatabaseManager . To keep the class operational, we also need to define a default constructor, in which we indicate the need to use a “combat” implementation. The introduced changes and the resulting modified class are presented in Fig. 5.

Fig. 5. A class after refactoring, which allows breaking the dependency on the database.
To implement the dependency, you need to add another class constructor, but now with an argument. This argument will precisely determine which interface implementation should be used. The constructor that will be used to test the class is shown in Fig. 6.

Fig. 6 . The constructor used to implement the dependency
Now our class looks as follows (the constructor used to test the class is surrounded by a green frame):
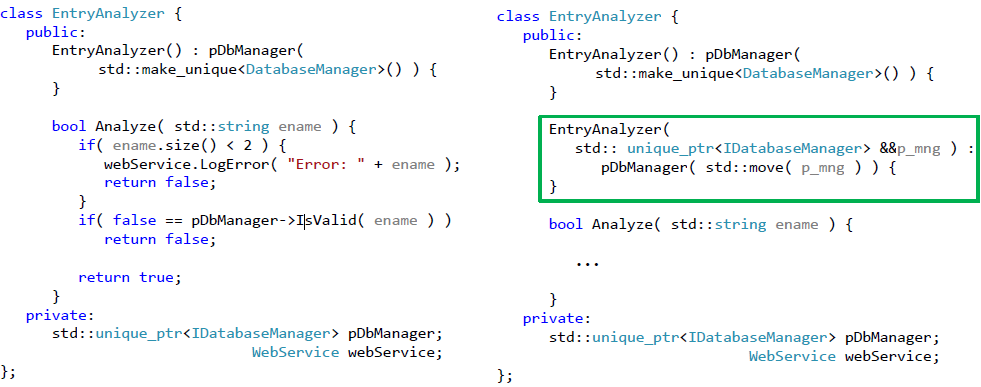
Fig. 7. Class refactoring that allows breaking the dependency on the database
Now we can write the following test that demonstrates the result of processing a valid cell name (see Fig. 8):
TEST_F( EntryAnalyzerTest, Analyze_ValidEntryName_ReturnsTrue )
{
EntryAnalyzer ea( std::make_unique( true ) );
bool result = ea.Analyze( "valid_entry_name" );
ASSERT_EQ( result, true );
}
class FakeDatabaseManager : public IDatabaseManager {
public:
bool WillBeValid;
FakeDatabaseManager( bool will_be_valid ) :
WillBeValid( will_be_valid ) {
}
bool IsValid( std::string ename ) override {
return WillBeValid;
}
}; Fig. 8. An example of a test that does not interact with a real database
Changing the value of the constructor parameter of a fake object affects the result of the IsValid function . In addition, this allows you to reuse the fake object in tests that require both affirmative and negative results of accessing the database.
Consider the second method of parameterizing the constructor. In this case, we will need to use factories - objects that are responsible for creating other objects.
First, let's follow the same steps to replace the hard-coded use of the DatabaseManager class.- let's move on to using a pointer to an object that implements the required interface. But now in the default constructor we will assign the responsibility for creating the required objects to the factory.
The resulting implementation is shown in Fig. 9.
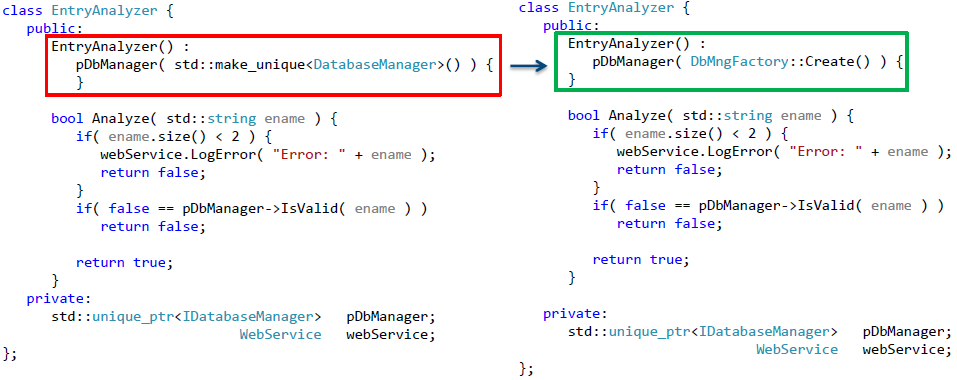
Fig. 9. Refactoring a class to use factories to create an object that interacts with a database.
Given the factory class introduced, the test itself can now be written as follows:
TEST_F( EntryAnalyzerTest,
Analyze_ValidEntryName_ReturnsTrue )
{
DbMngFactory::SetManager(
std::make_unique( true ) );
EntryAnalyzer ea;
bool result = ea.Analyze( "valid_entry_name" );
ASSERT_EQ( result, true );
}
class DbMngFactory {
public:
static std::unique_ptr Create() {
if( nullptr == pDbMng )
return std::make_unique();
return std::move( pDbMng );
}
static void SetManager(
std::unique_ptr &&p_mng ) {
pDbMng = std::move( p_mng );
}
private:
static std::unique_ptr pDbMng;
}; Fig. 10. Another example of a test that does not interact with a real database.
An important difference between this approach and the previously considered one is the use of the same constructor to create objects for both combat and test code. The factory takes all care to create the required facilities. This allows you to distinguish between the areas of responsibility of classes. Of course, a person who will deal with your code will need some time to understand the relationship of these classes. However, in the future, this approach allows us to achieve more flexible code adapted for long-term support.
Method 2. "Select and Override"
Consider another approach to breaking the dependence on the database - “Select and override” (Extract and override). Perhaps its application will seem simpler and will not cause such emotions:

Its main idea is to localize the dependencies of the “combat” class in one or more functions, and then redefine them in the successor class. Let us consider in practice this approach.
Let's start by localizing the dependency. In our case, the dependency is to access the IsValid method of the DatabaseManager class. We can separate this dependence into a separate function. Please note that changes should be made as carefully as possible. The reason is the lack of tests with which you can make sure that these changes do not break the existing logic of work. In order for the changes we make to be the safest, you must try to keep function signatures as much as possible. Thus, we transfer the code containing the external dependency into a separate method (see Fig. 11).

Fig. 11. Removing code containing an external dependency in a separate method
How can we test our class in this case? It's simple - let's declare the selected function virtual, inherit a new class from the original class, in which we redefine the function of the base class containing the dependency. So we got a class free from external dependencies - and now it can be safely entered into testing tools to cover tests. In fig. 12 illustrates one way to implement such a test class.
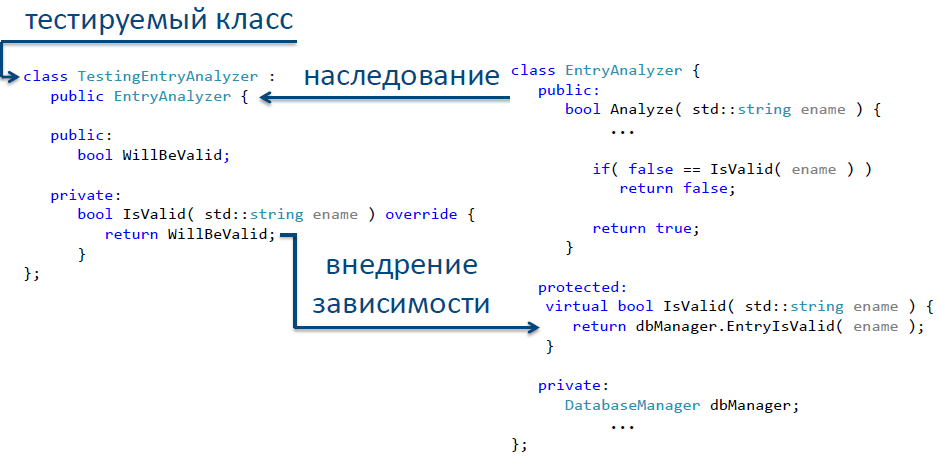
Fig. 12. Implementation of the “Select and override” method for breaking the dependency
The test itself can now be written as follows:
TEST_F( EntryAnalyzerTest, Analyze_ValidEntryName_ReturnsTrue)
{
TestingEntryAnalyzer ea;
ea.WillBeValid = true;
bool result = ea.Analyze( "valid_entry_name" );
ASSERT_EQ( result, true );
}
class TestingEntryAnalyzer : public EntryAnalyzer {
public:
bool WillBeValid;
private:
bool IsValid( std::string ename ) override {
return WillBeValid;
}
};Fig. 13. And another example of a test that does not interact with a real database.
The described approach is one of the easiest to implement, and it is useful to have it in your arsenal of skills.
Breaking a dependency using mock objects
Now we can break database dependencies using stub objects. But we still have raw dependency on the remote web server. With a mock, we can break this dependency.
What needs to be done for this? Here, a combination of the methods already considered will come in handy. First, we localize our dependency in one of the functions, which we then declare as virtual. Do not forget to save function signatures! Now we select the interface that defines the contract for the WebService class and instead of using the class explicitly, we will use the unique_ptr pointer of the required type. And create an inheritor class in which this virtual function will be redefined. The class obtained after refactoring is shown in Fig. 14.

Fig. 14. A class after refactoring, prepared to break the dependence on network interaction.
We introduce the shared_ptr pointer to an object that implements the selected interface in the derived class . All that remains for us is to use the constructor parameterization method to implement the dependency. Now our class, which can now be tested, looks like this:
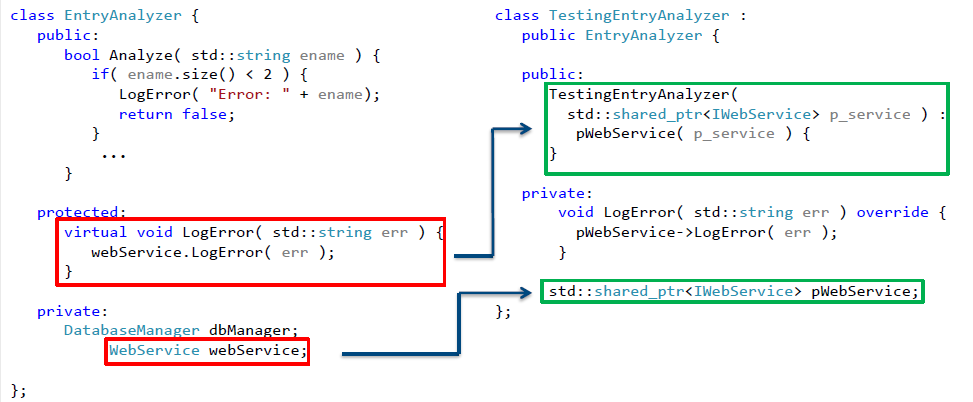
Fig. 15. A tested class that allows breaking the dependence on network interaction.
And now we can write the following test:
TEST_F( EntryAnalyzerTest, Analyze_TooShortEntryName_LogsErrorToWebServer )
{
std::shared_ptr p_web_service =
std::make_shared();
TestingEntryAnalyzer ea( p_web_service );
bool result = ea.Analyze( "e" );
ASSERT_EQ( p_web_service->lastError, "Error: e" );
}
class TestingEntryAnalyzer : public EntryAnalyzer {
public:
TestingEntryAnalyzer(
std::shared_ptr p_service ) :
pWebService( p_service ) {
}
private:
void LogError( std::string err ) override {
pWebService->LogError( err );
}
std::shared_ptr pWebService;
};
class FakeWebService : public IWebService {
public:
void LogError( std::string error ) override {
lastError = error;
}
std::string lastError;
}; Fig.16. An example of a test that does not interact with a network connection
Thus, having implemented the dependency using the constructor parameterization, based on the analysis of the state of the mock-object, we can find out what messages the remote web-service will receive.
Recommendations for making tests easy to maintain and upgrade
Let us now consider approaches to building unit tests that are easy to maintain and upgrade. Perhaps in many ways this is again due to distrust of oneself.

The first recommendation is that one test should test only one result of work. In this case, if the test fails, then you can immediately clearly say which part of the logic of the "combat" code did not pass the test. If in one test there are several assert, then without a repeated run of the test and subsequent additional analysis, it is difficult to say unequivocally exactly where the logic was violated.
The second recommendation is that only public class methods should be tested. This is due to the fact that public methods, in fact, determine the class contract - that is, the functionality that it undertakes to fulfill. However, the specific implementation of its implementation remains at its discretion. Thus, during the development of the project, the way of performing one or another action can be changed, which may require a change in the logic of the private class methods. As a result, this can lead to failure of a number of tests written for private methods, although the public class contract itself is not violated. If testing a private method is still required, it is recommended that you find a public method with the class that uses it and write a test with respect to it.
However, sometimes the tests fail, and you have to figure out what went wrong. In this case, a rather unpleasant situation can arise if the error is contained in the test itself. As a rule, in the first place, we begin to look for the reasons for failure precisely in the logic of the tested "combat" code, and not the test itself. In this case, a lot of time can be spent searching for the cause of failure. In order to avoid this, we must strive to make the test code as simple as possible - avoid using any branching operators in the test ( switch , if , for , whileetc.). If it is necessary to test the branching in the "combat" code, then it is better to write two separate tests for each of the branches. Thus, a typical unit test can be represented as a sequence of method calls with further assert.
Consider now the following situation: there is a class for which a large number of tests have been written, for example, 100. Inside each of them, the creation of a test object is required, the constructor of which requires one argument. However, with the development of the project, the situation has changed - and now one argument is not enough, and two are needed. Changing the number of constructor parameters will lead to the fact that all 100 tests will not be successfully compiled, and in order to put them in order you will have to make changes to all 100 places.
To avoid this situation, let's follow the well-known to all of us rule: "Avoid duplication of code." This can be achieved through the use of factory methods in tests for creating test objects. In this case, when changing the constructor signature of the tested object, it will be enough to make the corresponding editing in only one place of the test project.
This can significantly reduce the time spent maintaining existing tests in a healthy state. And this may turn out to be especially important in a situation when once again we will be running out of time on all sides.

Became interesting? You can dive deeper.
For further and more detailed immersion in the topic of unit testing, I advise Roy Osherove's book “The art of unit testing” . In addition, quite often a situation also arises when you need to make changes to existing code that is not covered by tests. One of the safest approaches is to first create a kind of “safety net” - cover it with tests, and then make the required changes. This approach is very well described in the book of M. Fishers "Effective work with legacy code . " So mastering the approaches described by the authors can bring us, as developers, an arsenal of very important and useful skills.
Thank you for your time! I am glad if any of the above is useful and timely. I’m happy to try to answer in the comments on the questions, if any arise.
Posted by: Viktor Yastrebov vyastrebov