GraphQL - a new look at the API. Part 1
Hello everyone, I want to share the accumulated knowledge of GraphQL, which was formed on the basis of about a hundred articles / docks read and the month of building the API using GraphQL.
GraphQL is a standard for declaring data structures and methods for obtaining data, which acts as an additional layer between the client and server.
One of the main features of GraphQL is that the structure and volume of data is determined by the client application.
Consider an example of a simple user request.
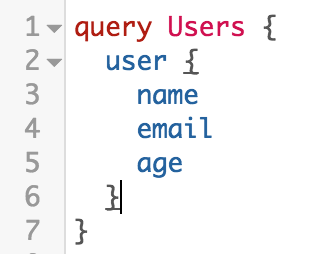
The client accurately indicates what data he wants to receive, using a declarative, graph-like structure, which is very similar to the JSON format.
In this case, the client requests three fields (name, email and age). But it can request both a single field, for example name, and an arbitrary number of fields that are defined in the user type on the GraphQL server.
In this approach, in addition to convenience, we have reduced either the number of requests or the volume of data at the transport level.
GraphQL makes it easy to aggregate data from multiple sources.
Let's look at a simple client-server architecture.

We have a client application and one server. Data transport looks quite simple,
no matter which data transfer protocol is used for this. In the case of http, we send a request and get a response, everything is pretty simple.

As I said earlier, GraphQL is an additional layer between the client and the server, and if you look at this architecture, then using GraphQL looks kind of redundant.
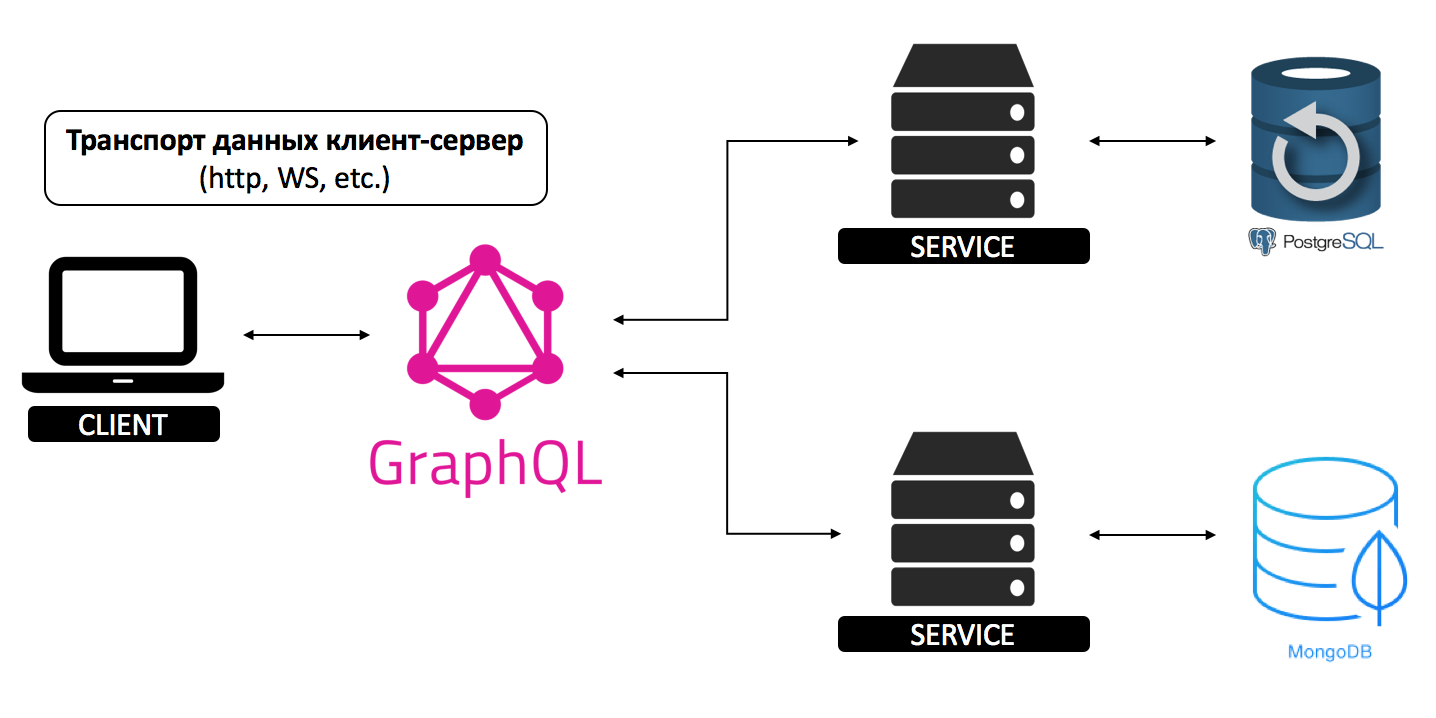
But as soon as another service is added, everything falls into place.
Services can be written in any programming language, interact with different databases, Sql or NoSql, and can have different APIs. It becomes quite difficult to work with such an architecture, and adding each new service requires a lot of resources.
This is a classic problem of scaling a project, and for certain when working with several services you use some kind of “API Gateway”.
GraphQL is this standardized API Gateway. Client-server data transport can be performed using any protocol (http, ssh, ws, cli, etc.).
A client requests resources from a GraphQL server using a GraphQL query. GraphQL server analyzes the query, recursively goes through the graph and performs its “resolver” function for each field. When all the data on request is collected, GraphQL server will return a response.
It is important to note that adding a new service does not affect the existing application. Due to the fact that the client determines what data he wants to receive, you can not be afraid to expand existing types.
GraphQL uses a type system to describe data.
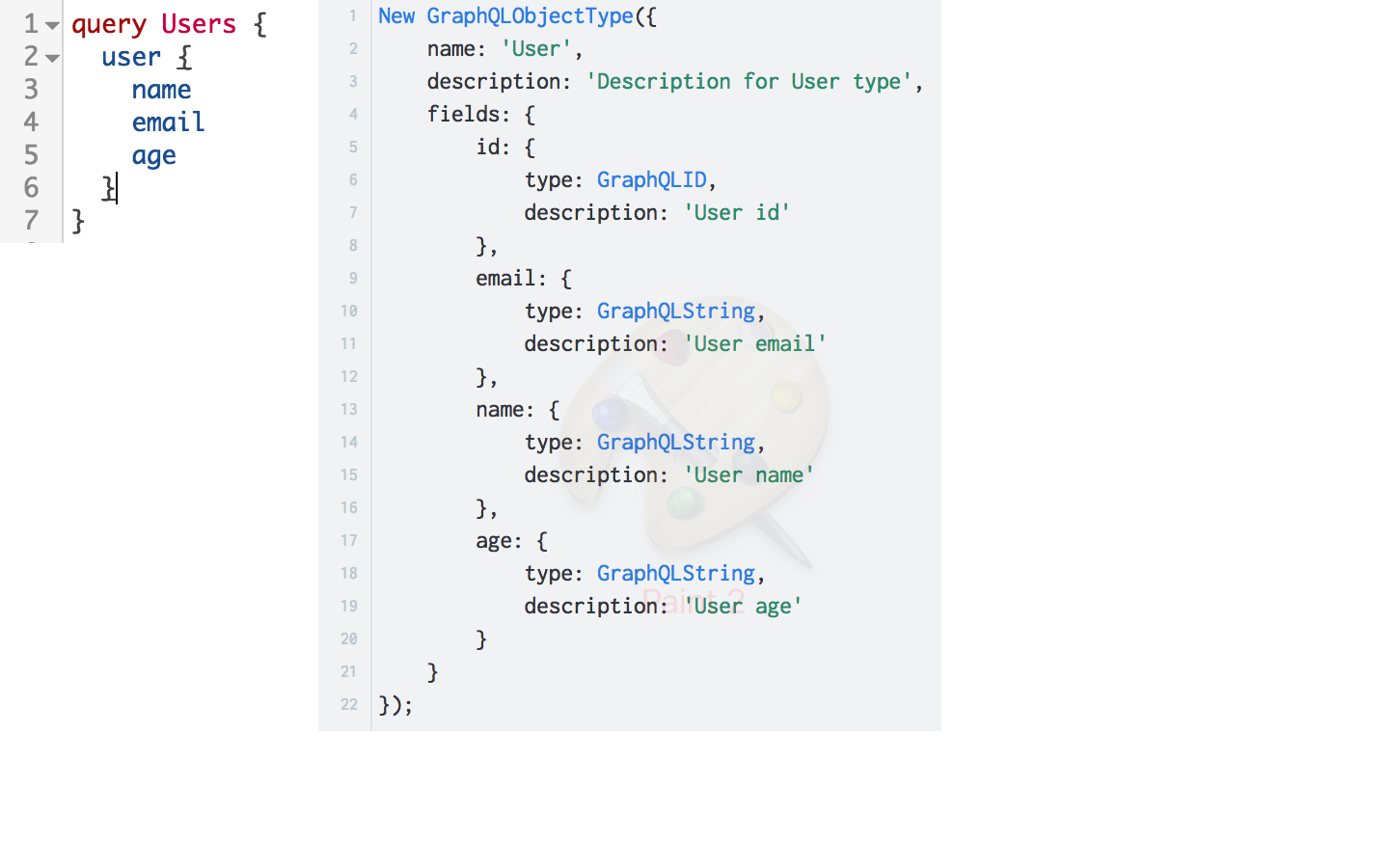
In GraphQL, fields can be represented by both basic and user types. In this example, the user field is represented by the user type User. The User type describes a set of fields that are represented by basic types.
Thus, a graph-like structure of an indefinite level of nesting is realized.
At this end of the first part, the second part will be added soon. Thanks to all!)
Well, let's start with what GraphQL is?
GraphQL is a standard for declaring data structures and methods for obtaining data, which acts as an additional layer between the client and server.
One of the main features of GraphQL is that the structure and volume of data is determined by the client application.
Consider an example of a simple user request.
The client accurately indicates what data he wants to receive, using a declarative, graph-like structure, which is very similar to the JSON format.
In this case, the client requests three fields (name, email and age). But it can request both a single field, for example name, and an arbitrary number of fields that are defined in the user type on the GraphQL server.
In this approach, in addition to convenience, we have reduced either the number of requests or the volume of data at the transport level.
GraphQL makes it easy to aggregate data from multiple sources.
Let's look at a simple client-server architecture.
We have a client application and one server. Data transport looks quite simple,
no matter which data transfer protocol is used for this. In the case of http, we send a request and get a response, everything is pretty simple.
As I said earlier, GraphQL is an additional layer between the client and the server, and if you look at this architecture, then using GraphQL looks kind of redundant.
But as soon as another service is added, everything falls into place.
Services can be written in any programming language, interact with different databases, Sql or NoSql, and can have different APIs. It becomes quite difficult to work with such an architecture, and adding each new service requires a lot of resources.
This is a classic problem of scaling a project, and for certain when working with several services you use some kind of “API Gateway”.
GraphQL is this standardized API Gateway. Client-server data transport can be performed using any protocol (http, ssh, ws, cli, etc.).
A client requests resources from a GraphQL server using a GraphQL query. GraphQL server analyzes the query, recursively goes through the graph and performs its “resolver” function for each field. When all the data on request is collected, GraphQL server will return a response.
It is important to note that adding a new service does not affect the existing application. Due to the fact that the client determines what data he wants to receive, you can not be afraid to expand existing types.
Type system
GraphQL uses a type system to describe data.
In GraphQL, fields can be represented by both basic and user types. In this example, the user field is represented by the user type User. The User type describes a set of fields that are represented by basic types.
Thus, a graph-like structure of an indefinite level of nesting is realized.
Compare GraphQL API and REST API
- Dependence on the data transfer protocol.
GraphQL is independent of the data transfer protocol, can use any (http, ws, ssh, cli, etc.)
REST is based on the http protocol, and depends on it. - Single entry point. (Entry point)
In GraphQL, to work with data, we always turn to a single entry point - GraphQL server. Changing the structure, fields, query parameters, we work with different data.
In the REST API, each route is a separate entry point. - Ability to return different data formats.
GraphQL can only return JSON format.
REST in this case is more flexible. The REST API can return data in various formats - JSON, XML, etc., it depends on the headers of the http request, and on the implementation of the API itself. - The declaration, documentation, development tools
GraphQL allows you to write documentation directly in code (inline documentation).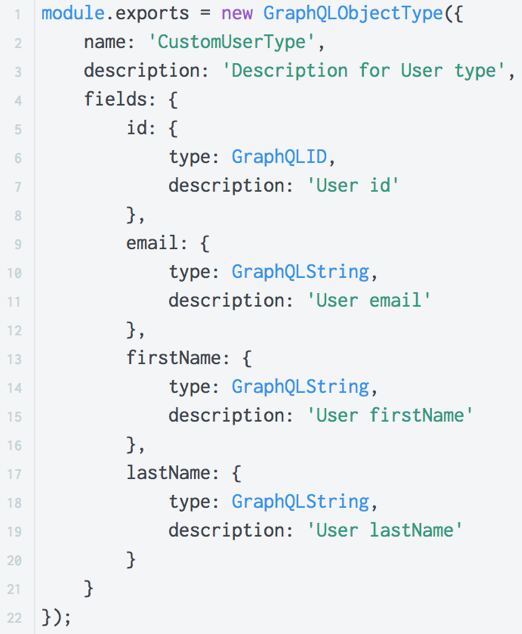
In GraphQL, we can describe any type we create. To do this, when creating a type, you need to describe in the "description" field what this type is for. Various utilities, IDEs can parse this documentation, which greatly simplifies working with GraphQL.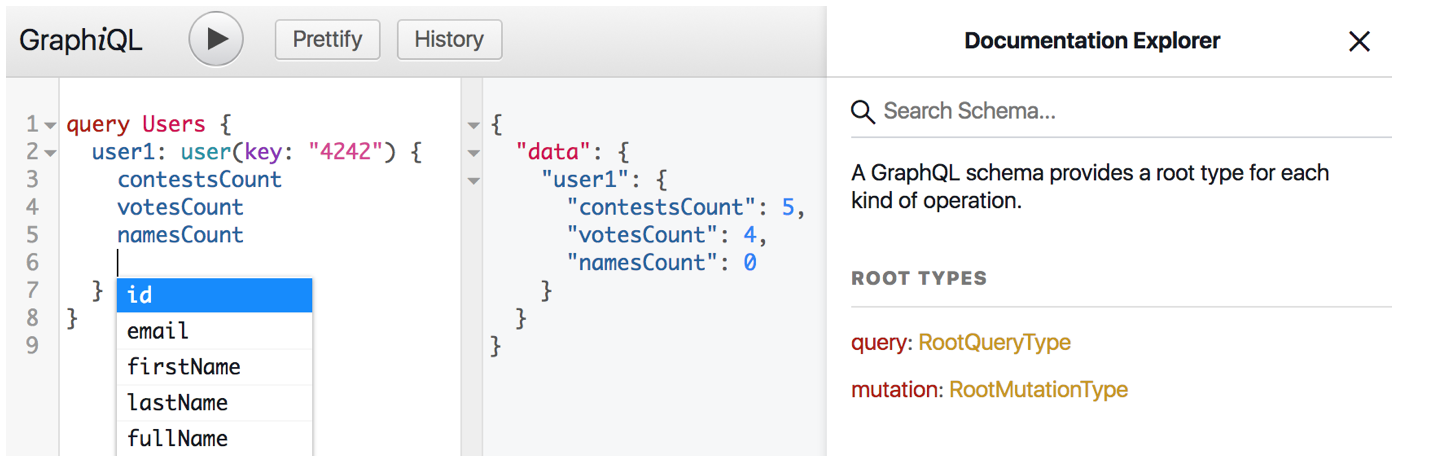
Also, GraphQL out of the box has its own IDE, which works in the browser and is called GraphiQL.
GraphiQL stores the query history, highlights the syntax, prompts the fields that we can request from the current type, parses the documentation. This greatly simplifies the writing of queries.
GraphiQL can be enabled through the GraphQL configuration, using the graphiql = true setting and following the path <domain name> / graphiql. Or you can use one of the extensions for the browser, which have almost the same functionality but a different UI.
REST does not have similar functionality, but it is possible to implement it using SWAGGER.
- The ability to form the structure and amount of data on the client
Actually, this is one of the main features of GraphQL, the format and structure of the data is determined on the client side. In REST, the format and data structure are rigidly defined on the server. - Passing Arguments to the Query

When concluding from the previous paragraphs, you probably already know the answer, due to the fact that GraphQL is a single entry point in GraphQL, we are able to pass arguments to any level of nesting.
In REST, each path is represented as a separate entry point, in which case we can only pass arguments for the entire request.
At this end of the first part, the second part will be added soon. Thanks to all!)