Colorize a black and white photo using a neural network of 100 lines of code
- Transfer

Translation of the article Colorizing B&W Photos with Neural Networks .
Not so long ago, Amir Avni, using neural networks, trolled the / r / Colorization branch to Reddit , where people gather who are fond of manually painting historical black and white images in Photoshop. Everyone was amazed at the quality of the neural network. What takes up to a month of manual work can be done in a few seconds.
Let's reproduce and document Amir's image processing process. To get started, look at some of the accomplishments and failures (at the very bottom - the latest version).

Original black and white photographs taken from Unsplash .
Today, black and white photographs are usually painted manually in Photoshop. Watch this video to get an idea of the enormous complexity of such work:
It may take a month to colorize one image. We have to research a lot of historical materials dating back to that time. Up to 20 layers of pink, green and blue shadows are superimposed on a face alone to get the right shade.
This article is for beginners. If you are not familiar with the terminology of deep learning of neural networks, then you can read the previous articles ( 1 , 2 ) and watch a lecture by Andrey Karpaty.
In this article, you will learn how to build your own neural network for coloring images in three stages.
In the first part we will deal with the basic logic. Let’s build a neural network framework of 40 lines, this will be the “alpha” version of the coloring bot. There is little mystery in this code; it will help you familiarize yourself with the syntax.
In the next step, we will make a generalize neural network - a "beta" version. She will already be able to colorize images that are not familiar to her.
In the “final” version, we will combine our neural network with the classifier. To do this, take Inception Resnet V2 , trained on 1.2 million images. And we will teach the neural network to colorize images with Unsplash .
If you can’t wait, then here is the Jupyter Notebook with the alpha version of the bot. You can also watch three versions on FloydHub and GitHub, and also the code used in all experiments that were conducted on the FloydHub service's cloud video cards.
Basic logic
In this section, we will consider image rendering, talk about the theory of digital color and the basic logic of the neural network.
Black and white images can be represented as a grid of pixels. Each pixel has a brightness value ranging from 0 to 255, from black to white.

Color images consist of three layers: red, green and blue. Suppose you want to spread a picture with a green leaf on a white background in three channels. You might think that the leaf will be presented only in the green layer. But, as you can see, it is in all three layers, because the layers determine not only color, but also brightness.

For example, to get white, we need to get an equal distribution of all colors. If you add the same amount of red and blue, then green will become brighter. That is, in a color image using three layers, color and contrast are encoded.

As in a black and white image, the pixels of each layer of a color image contain a value from 0 to 255. Zero means that this pixel has no color in this layer. If all three channels have zeros, the result is a black pixel in the picture.
As you know, a neural network establishes a relationship between input and output values. In our case, the neural network should find the connecting features between black-and-white and color images. That is, we are looking for properties by which we can compare values from a black-and-white grid with values from three color ones.

f () - neural network, [B&W] - input data, [R], [G], [B] - output data.
Alpha version
First, we’ll make a simple version of a neural network that will paint a woman’s face. As you add new features, you will become familiar with the basic syntax of our model.
For 40 lines of code, we will move from the left picture - black and white - to the middle one, which is made by our neural network. The right picture is an original photograph from which we made black and white. The neural network was trained and tested on one image, we’ll talk about this in the beta section.

Color space
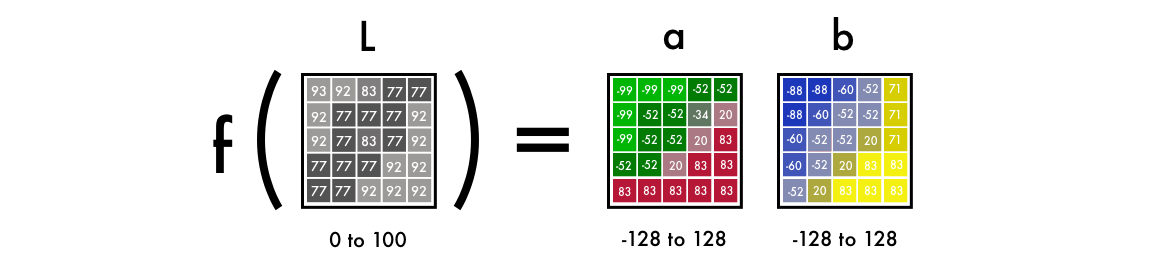
First, we use the algorithm for changing color channels from RGB to Lab. L stands for lightness, a and b are Cartesian coordinates that determine the position of the color in the range, respectively, from green to red and from blue to yellow.
As you can see, the image in the Lab space contains one layer of grayscale, and three color layers are packed into two. Therefore, we can use the original black and white version in the final image. It remains to calculate two more channels.

Scientific fact: 94% of the retina receptors in our eyes are responsible for determining brightness. And only 6% of receptors recognize colors. Therefore, for you, a black and white image looks much more distinct than color layers. This is another reason why we will use this picture in the final version.
From grayscale to color
As input we take a layer with grayscale, and based on it we will generate color layers a and b in the Lab color space. We will take it as the L-layer of the final picture.
To get two layers from one layer, we will use convolution filters. They can be represented as blue and red glass in 3D glasses. Filters determine what we see in the picture. They can underline or hide some part of the image so that our eye will extract the necessary information. Using a filter, a neural network can also create a new image or combine several filters into one picture.
In convolutional neural networks, each filter is automatically tuned to make it easier to get the desired output. We will add hundreds of filters and then bring them together and get layers a and b.
Before we get into the details of how the code works, let's run it.
Deploying code on FloydHub
If you haven’t worked with FloydHub before, you can still start the installation and see a five-minute video tutorial or step-by-step instructions . FloydHub is the best and easiest way to deeply model cloud graphics cards.
Alpha version
After installing FloydHub, enter the command:
git clone https://github.com/emilwallner/Coloring-greyscale-images-in-KerasThen open the folder and initialize FloydHub. The FloydHub web panel will open in your browser. You will be prompted to create a new FloydHub project called colornet. When you create it, return to the terminal and issue the same initialization command. Run the task: A few explanations:
cd Coloring-greyscale-images-in-Keras/floydhub
floyd init colornetfloyd init colornetfloyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard- Using this command, we mounted a public dataset on FloydHub:
--dataemilwallner/datasets/colornet/2:data
On FloydHub you can view and use this and many other public datasets. - Enable Tensorboard Using Command
--tensorboard - Launched a task in Jupyter Notebook mode using the command
--mode jupyter
If you can connect video cards to the task, then add a flag to the command
–gpu. It will turn out about 50 times faster. Go to the Jupyter Notebook. On the FloydHub website, in the Jobs tab, click on the Jupyter Notebook link and find the file:
floydhub/Alpha version/working_floyd_pink_light_full.ipynbOpen the file and press Shift + Enter on all cells.
Gradually increase the epoch value to understand how the neural network is learning.
model.fit(x=X, y=Y, batch_size=1, epochs=1)Start with epochs = 1, then increase to 10, 100, 500, 1000 and 3000. This value shows how many times the neural network is trained in the image. As soon as you train the neural network, you will find the img_result.png file in the main folder. FloydHub command to run this network:
# Get images
image = img_to_array(load_img('woman.png'))
image = np.array(image, dtype=float)
# Import map images into the lab colorspace
X = rgb2lab(1.0/255*image)[:,:,0]
Y = rgb2lab(1.0/255*image)[:,:,1:]
Y = Y / 128
X = X.reshape(1, 400, 400, 1)
Y = Y.reshape(1, 400, 400, 2)
model = Sequential()
model.add(InputLayer(input_shape=(None, None, 1)))
# Building the neural network
model = Sequential()
model.add(InputLayer(input_shape=(None, None, 1)))
model.add(Conv2D(8, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(8, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', strides=2))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(2, (3, 3), activation='tanh', padding='same'))
# Finish model
model.compile(optimizer='rmsprop',loss='mse')
#Train the neural network
model.fit(x=X, y=Y, batch_size=1, epochs=3000)
print(model.evaluate(X, Y, batch_size=1))
# Output colorizations
output = model.predict(X)
output = output * 128
canvas = np.zeros((400, 400, 3))
canvas[:,:,0] = X[0][:,:,0]
canvas[:,:,1:] = output[0]
imsave("img_result.png", lab2rgb(canvas))
imsave("img_gray_scale.png", rgb2gray(lab2rgb(canvas)))floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboardTechnical Explanations
Recall that at the entrance we have a grid representing a black and white image. And at the output there are two grids with color values. Between the input and output values, we created link filters. We have a convolutional neural network.
To train the network, color images are used. We converted from RGB to Lab. The black-and-white layer is fed to the input, and the output produces two colored layers.

We in one range compare (map) calculated values with real ones, thereby comparing them with each other. The boundaries of the range are from –1 to 1. To compare the calculated values, we use the tanh activation function (hyperbolic tangential). If you apply it to any value, the function will return a value in the range from –1 to 1.
Actual color values vary from –128 to 128. In Lab space, this is the default range. If each value is divided by 128, then all of them will be in the range from –1 to 1. This “normalization” allows us to compare the error of our calculation.
After calculating the resulting error, the neural network updates the filters to adjust the result of the next iteration. The whole procedure is repeated cyclically until the error becomes minimal.
Let's look at the syntax of this code: 1.0 / 255 means that we use a 24-bit RGB color space. That is, for each color channel, we use values in the range from 0 to 255. This gives us 16.7 million colors. But since the human eye can only recognize from 2 to 10 million colors, it makes no sense to use a wider color space. Lab color space uses a different range. Color spectrum ab
X = rgb2lab(1.0/255*image)[:,:,0]
Y = rgb2lab(1.0/255*image)[:,:,1:]Y = Y / 128varies from –128 to 128. If you divide all the values of the output layer by 128, they will fit into the range from –1 to 1, and then it will be possible to compare these values with those calculated by our neural network.
After using the function to
rgb2lab()transform the color space, we use [:,:, 0] to select the black and white layer. This is the input to the neural network. [:,:, 1:] selects two color layers, red-green and blue-yellow. After training the neural network, we perform the last calculation, which we transform into a picture. Here we submit a black and white image to the input and drive it through a trained neural network. We take all output values from -1 to 1 and multiply them by 128. So we get the correct colors in the Lab system.
output = model.predict(X)
output = output * 128canvas = np.zeros((400, 400, 3))
canvas[:,:,0] = X[0][:,:,0]
canvas[:,:,1:] = output[0]Create a black RGB canvas, filling all three layers with zeros. Then copy the black and white layer from the test image and add two color layers. The resulting array of pixel values is converted to an image.
What we learned when working on the alpha version
- Reading research papers is hard work . But it was worth summarizing the key provisions of the articles, and it became easier to study them. It also helped to include some details in this article.
- You need to start small . Most of the implementations we found on the network consisted of 2-10 thousand lines of code. This makes it very difficult to get an idea of the basic logic. But if at hand there is a simplified, basic version, then it is easier to read both the implementation and the research papers.
- Do not be lazy to understand other people's projects . We had to browse through dozens of image painting projects on Github to determine the contents of our code.
- Not everything works as intended . Perhaps at first your network will only be able to create red and yellow colors. For the first time, we used Relu's activation function for final activation. But it only generates positive values, and therefore the blue and green spectra are inaccessible to it. We managed to solve this shortcoming by adding the tanh activation function to convert values along the Y axis.
- Understanding> speed . Many of the implementations we saw were executed quickly, but it was difficult to work with them. Therefore, we decided to optimize our code for the speed of adding new features, rather than execution.
Beta version
Offer the alpha version to colorize the image on which she was not trained, and immediately understand what the main drawback of this version is. She can't handle it. The fact is that the neural network remembered the information. She did not learn how to color an unfamiliar image. And we will fix it in the beta version - we will teach the neural network to generalize.
The following shows how the beta version colored test images.
Instead of using Imagenet, we created a public dataset on FloydHub with better images. They are taken from Unsplash - a site where photos of professional photographers are laid out. There are 9500 training images and 500 test images in the dataset.

Feature Highlighter
Our neural network is looking for characteristics that connect black and white images with their color versions.
Imagine you need to colorize black and white pictures, but you can only see nine pixels on the screen at a time. You can view each picture from left to right and from top to bottom, trying to calculate the color of each pixel.

Let these nine pixels be on the edge of the woman’s nostrils. As you understand, it is almost impossible to choose the right color here, so you have to break the solution of the problem into stages.
First, we are looking for simple characteristic structures: diagonal lines, only black pixels, and so on. In each square of 9 pixels, we look for the same structure and delete everything that does not correspond to it. As a result, we created 64 new images from 64 of our mini-filters.

The number of processed image filters at each stage.
If we look at the images again, we find the same small repeating structures that we have already defined. To better analyze the image, reduce its size by half.

Reduce the size in three stages.
We still have a 3x3 filter, which needs to scan each image. But if we apply our simpler filters to new nine-pixel squares, more complex structures can be detected. For example, a semicircle, a small dot, or a line. Once again, we find the same repeating structure in the picture. This time we generate 128 new images processed by filters.
After a couple of steps, the images processed by the filters will look like this:

To repeat: you start by looking for simple properties, such as edges. As you process, the layers are combined into structures, then into more complex features, and in the end you get a face. More details are explained in this video:
The described process is very similar to computer vision algorithms. Here we use the so-called convolutional neural network, which combines several processed images to understand the contents of the entire image.
From extracting properties to color
The neural network operates on the principle of trial and error. First, it randomly assigns a color to each pixel. Then, for each pixel, it calculates errors and adjusts the filters so that in the next attempt to improve the results.
The neural network adjusts its filters, starting from the results with the largest error values. In our case, the neural network decides whether to color or not, and how to arrange different objects in the picture. First, she paints all objects in brown. This color is most similar to all other colors, so with it when using it you get the smallest errors.
Due to the uniformity of the training data, the neural network is trying to understand the differences between various objects. She still can not calculate more accurate color shades, this we will do when creating the full version of the neural network.
Here is the beta code: FloydHub command to launch the beta version of the neural network:
# Get images
X = []
for filename in os.listdir('../Train/'):
X.append(img_to_array(load_img('../Train/'+filename)))
X = np.array(X, dtype=float)
# Set up training and test data
split = int(0.95*len(X))
Xtrain = X[:split]
Xtrain = 1.0/255*Xtrain
#Design the neural network
model = Sequential()
model.add(InputLayer(input_shape=(256, 256, 1)))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(2, (3, 3), activation='tanh', padding='same'))
model.add(UpSampling2D((2, 2)))
# Finish model
model.compile(optimizer='rmsprop', loss='mse')
# Image transformer
datagen = ImageDataGenerator(
shear_range=0.2,
zoom_range=0.2,
rotation_range=20,
horizontal_flip=True)
# Generate training data
batch_size = 50
def image_a_b_gen(batch_size):
for batch in datagen.flow(Xtrain, batch_size=batch_size):
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:,:,:,0]
Y_batch = lab_batch[:,:,:,1:] / 128
yield (X_batch.reshape(X_batch.shape+(1,)), Y_batch)
# Train model
TensorBoard(log_dir='/output')
model.fit_generator(image_a_b_gen(batch_size), steps_per_epoch=10000, epochs=1)
# Test images
Xtest = rgb2lab(1.0/255*X[split:])[:,:,:,0]
Xtest = Xtest.reshape(Xtest.shape+(1,))
Ytest = rgb2lab(1.0/255*X[split:])[:,:,:,1:]
Ytest = Ytest / 128
print model.evaluate(Xtest, Ytest, batch_size=batch_size)
# Load black and white images
color_me = []
for filename in os.listdir('../Test/'):
color_me.append(img_to_array(load_img('../Test/'+filename)))
color_me = np.array(color_me, dtype=float)
color_me = rgb2lab(1.0/255*color_me)[:,:,:,0]
color_me = color_me.reshape(color_me.shape+(1,))
# Test model
output = model.predict(color_me)
output = output * 128
# Output colorizations
for i in range(len(output)):
cur = np.zeros((256, 256, 3))
cur[:,:,0] = color_me[i][:,:,0]
cur[:,:,1:] = output[i]
imsave("result/img_"+str(i)+".png", lab2rgb(cur))floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboardTechnical Explanations
From other neural networks that work with images, ours differs in that the location of pixels is important for it. In color neural networks, the image size or aspect ratio remains unchanged. And for other types of networks, the image is distorted as it approaches the final version.
A pooling layer with a maximum function, used in classifying networks, increases the density of information, but at the same time distorts the picture. It only evaluates information, not the image layout. And in color nets, to reduce the width and height by half, we use step 2 (stride of 2). The density of information is also increasing, but the picture is not distorted.

Also, our neural network differs from the other layers of upsampling and maintaining the aspect ratio of the image. Classifying networks only care about the final classification, therefore they gradually reduce the size and quality of the image as it passes through the neural network.
Coloring neural networks do not change the aspect ratio of the image. To do this, use the parameter to
*padding='same'*add white fields, as in the illustration above. Otherwise, each convolution layer would crop the images. To double the size of the picture, the coloring neural network uses the upsampling layer . This cycle
for filename in os.listdir('/Color_300/Train/'):
X.append(img_to_array(load_img('/Color_300/Test'+filename)))for-loopFirst, it counts the names of all the files in the directory, goes through the directory and converts all the pictures into arrays of pixels, and finally combines them into a huge vector.
Using ImageDataGenerator, you can enable the image generator. Then each image will be different from the previous ones, which will speed up the training of the neural network. The setting sets the tilt of the image left or right, it can also be increased, rotated or flipped horizontally.
Apply these settings to the images in the Xtrain folder and generate new images. Then we extract the black and white layer for and two colors for the two color layers.datagen = ImageDataGenerator(
shear_range=0.2,
zoom_range=0.2,
rotation_range=20,
horizontal_flip=True)shear_rangebatch_size = 50
def image_a_b_gen(batch_size):
for batch in datagen.flow(Xtrain, batch_size=batch_size):
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:,:,:,0]
Y_batch = lab_batch[:,:,:,1:] / 128
yield (X_batch.reshape(X_batch.shape+(1,)), Y_batch)X_batchmodel.fit_generator(image_a_b_gen(batch_size), steps_per_epoch=1, epochs=1000)The more powerful your video card, the more pictures you can process in it at the same time. For example, the described system can process 50-100 images. The value of the steps_per_epoch parameter is obtained by dividing the number of training images by the batch size.
For example: if we have 100 pictures, and the series size is 50, then we get 2 stages in a period. The number of periods determines how many times you will train the neural network in all pictures. If you have 10 thousand pictures and 21 periods, then it will take about 11 hours on a Tesla K80 graphics card.
What have learned
- Сначала побольше экспериментов с небольшими сериями, а потом можно переходить к большим прогонам. У нас были ошибки даже после 20–30 экспериментов. Если что-то выполняется, ещё не значит, что оно работает. Баги в нейросетях как правило менее заметны, чем традиционные ошибки программирования. К примеру, одним из наших самых причудливых багов был Adam hiccup.
- Чем разнообразнее датасет, тем больше коричневого будет в изображениях. Если в вашем датасете очень похожие изображения, то нейросеть будет работать вполне прилично без применения более сложной архитектуры. Но такая нейросеть будет хуже обобщать.
- Формы, формы и ещё раз формы. Размеры картинок должны быть точными и пропорциональными друг другу в течение всей работы нейросети. Сначала мы использовали изображение в 300 пикселей, потом несколько раз уменьшили его вдвое: до 150, 75 и 35,5 пикселей. В последнем варианте потерялось полпикселя, из-за чего пришлось подставлять кучу костылей, пока не дошло, что лучше использовать двойку в степени: 2, 4, 8, 16, 32, 64, 256 и так далее.
- Создание датасетов: a) Отключите файл .DS_Store, иначе он сведёт вас с ума. б) Проявите выдумку. Для скачивания файлов мы воспользовались консольным скриптом в Chrome и расширением. в) Делайте копии исходных файлов, которые вы обрабатываете, и упорядочивайте скрипты для очистки.
Full version of the neural network
Our final version of the coloring neural network contains four components. We divided the previous network into an encoder and a decoder, and between them a fusion layer. If you are not familiar with classifying neural networks, we recommend that you read this manual: http://cs231n.github.io/classification/ .
Input data simultaneously passes through the encoder and through the most powerful modern classifier - Inception ResNet v2 . This is a neural network trained in 1.2 million images. We extract the classification layer and combine it with the output of the encoder.
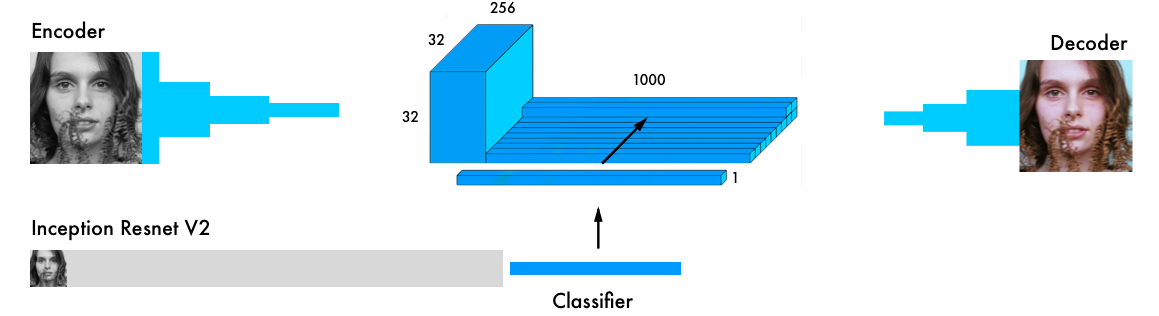
More detailed visual explanation: https://github.com/baldassarreFe/deep-koalarization .
If you transfer training from the classifier to a coloring network, then it will be able to understand what is shown in the picture, and therefore compare the representation of the object with the coloring scheme.
Here are some test images, only 20 pictures were used to train the network.

Most of the photos are painted crookedly. But thanks to the large test set (2500 images), there are several decent ones. Training a network on a larger sample gives more stable results, but still the majority of the pictures turned out to be brown. Here is a complete list of experiments and test images.
The most common architectures from various research works:
- Вручную добавляем в картинку маленькие цветные точки, чтобы дать сети подсказку (ссылка).
- Находим похожее изображение и переносим с него цвета (подробнее здесь и здесь).
- Слой остаточного кодировщика (residual encoder) и слой классификации объединением (merging classification) (ссылка).
- Объединяем гиперколонок (hypercolumns) из классифицирующей сети (подробнее здесь и здесь).
- Объединяем итоговую классификацию между кодировщиком и декодировщиком (подробнее здесь и здесь).
Color spaces : Lab, YUV, HSV and LUV (more details here and here )
Losses : standard error, classification, weighted classification ( link ).
We chose an architecture with a “merge layer” (fifth on the list) because it gave the best results. It is also easier to understand and easier to reproduce in Keras . Although this is not the strongest architecture, it will do for a start.
The structure of our neural network is borrowed from the work of Federico Baldasarre and his colleagues, and adapted to work with Keras. Note: this code uses the functional API instead of the Keras sequential model. [ Documentation ]
# Get images
X = []
for filename in os.listdir('/data/images/Train/'):
X.append(img_to_array(load_img('/data/images/Train/'+filename)))
X = np.array(X, dtype=float)
Xtrain = 1.0/255*X
#Load weights
inception = InceptionResNetV2(weights=None, include_top=True)
inception.load_weights('/data/inception_resnet_v2_weights_tf_dim_ordering_tf_kernels.h5')
inception.graph = tf.get_default_graph()
embed_input = Input(shape=(1000,))
#Encoder
encoder_input = Input(shape=(256, 256, 1,))
encoder_output = Conv2D(64, (3,3), activation='relu', padding='same', strides=2)(encoder_input)
encoder_output = Conv2D(128, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(128, (3,3), activation='relu', padding='same', strides=2)(encoder_output)
encoder_output = Conv2D(256, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(256, (3,3), activation='relu', padding='same', strides=2)(encoder_output)
encoder_output = Conv2D(512, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(512, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(256, (3,3), activation='relu', padding='same')(encoder_output)
#Fusion
fusion_output = RepeatVector(32 * 32)(embed_input)
fusion_output = Reshape(([32, 32, 1000]))(fusion_output)
fusion_output = concatenate([encoder_output, fusion_output], axis=3)
fusion_output = Conv2D(256, (1, 1), activation='relu', padding='same')(fusion_output)
#Decoder
decoder_output = Conv2D(128, (3,3), activation='relu', padding='same')(fusion_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
decoder_output = Conv2D(64, (3,3), activation='relu', padding='same')(decoder_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
decoder_output = Conv2D(32, (3,3), activation='relu', padding='same')(decoder_output)
decoder_output = Conv2D(16, (3,3), activation='relu', padding='same')(decoder_output)
decoder_output = Conv2D(2, (3, 3), activation='tanh', padding='same')(decoder_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
model = Model(inputs=[encoder_input, embed_input], outputs=decoder_output)
#Create embedding
def create_inception_embedding(grayscaled_rgb):
grayscaled_rgb_resized = []
for i in grayscaled_rgb:
i = resize(i, (299, 299, 3), mode='constant')
grayscaled_rgb_resized.append(i)
grayscaled_rgb_resized = np.array(grayscaled_rgb_resized)
grayscaled_rgb_resized = preprocess_input(grayscaled_rgb_resized)
with inception.graph.as_default():
embed = inception.predict(grayscaled_rgb_resized)
return embed
# Image transformer
datagen = ImageDataGenerator(
shear_range=0.4,
zoom_range=0.4,
rotation_range=40,
horizontal_flip=True)
#Generate training data
batch_size = 20
def image_a_b_gen(batch_size):
for batch in datagen.flow(Xtrain, batch_size=batch_size):
grayscaled_rgb = gray2rgb(rgb2gray(batch))
embed = create_inception_embedding(grayscaled_rgb)
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:,:,:,0]
X_batch = X_batch.reshape(X_batch.shape+(1,))
Y_batch = lab_batch[:,:,:,1:] / 128
yield ([X_batch, create_inception_embedding(grayscaled_rgb)], Y_batch)
#Train model
tensorboard = TensorBoard(log_dir="/output")
model.compile(optimizer='adam', loss='mse')
model.fit_generator(image_a_b_gen(batch_size), callbacks=[tensorboard], epochs=1000, steps_per_epoch=20)
#Make a prediction on the unseen images
color_me = []
for filename in os.listdir('../Test/'):
color_me.append(img_to_array(load_img('../Test/'+filename)))
color_me = np.array(color_me, dtype=float)
color_me = 1.0/255*color_me
color_me = gray2rgb(rgb2gray(color_me))
color_me_embed = create_inception_embedding(color_me)
color_me = rgb2lab(color_me)[:,:,:,0]
color_me = color_me.reshape(color_me.shape+(1,))
# Test model
output = model.predict([color_me, color_me_embed])
output = output * 128
# Output colorizations
for i in range(len(output)):
cur = np.zeros((256, 256, 3))
cur[:,:,0] = color_me[i][:,:,0]
cur[:,:,1:] = output[i]
imsave("result/img_"+str(i)+".png", lab2rgb(cur))FloydHub-command to run the full version of the neural network:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboardTechnical Explanations
The functional Keras API is great for concatenating or combining multiple models.
First, download the Inception ResNet v2 neural network and load the weights. Since we will simultaneously use two models, we need to determine which ones. This is done at Tensorflow , the Keras backend. Let's create a series (batch) from the corrected images. We translate them into b / w and run them through the Inception ResNet model. First you need to resize the pictures to feed their models. Then, using the preprocessor, we bring the pixels and values in color to the desired format. Finally, let's drive the images through the Inception network and extract the final layer of the model.
inception = InceptionResNetV2(weights=None, include_top=True)
inception.load_weights('/data/inception_resnet_v2_weights_tf_dim_ordering_tf_kernels.h5')
inception.graph = tf.get_default_graph()grayscaled_rgb = gray2rgb(rgb2gray(batch))
embed = create_inception_embedding(grayscaled_rgb)def create_inception_embedding(grayscaled_rgb):
grayscaled_rgb_resized = []
for i in grayscaled_rgb:
i = resize(i, (299, 299, 3), mode='constant')
grayscaled_rgb_resized.append(i)
grayscaled_rgb_resized = np.array(grayscaled_rgb_resized)
grayscaled_rgb_resized = preprocess_input(grayscaled_rgb_resized)
with inception.graph.as_default():
embed = inception.predict(grayscaled_rgb_resized)
return embedLet's go back to the generator. For each series, we will generate 20 images of the format described below. The Tesla K80 GPU took about an hour. Using this model, this video card can generate up to 50 images at a time without any memory problems.
yield ([X_batch, create_inception_embedding(grayscaled_rgb)], Y_batch)This matches the format of our colornet model.
model = Model(inputs=[encoder_input, embed_input], outputs=decoder_output)encoder_inputistransferred to the Encoder model, its output data are then combined in the merge layer with embed_inputin; The merge output is fed to the Decoder model, which returns the resulting data decoder_output.fusion_output = RepeatVector(32 * 32)(embed_input)
fusion_output = Reshape(([32, 32, 1000]))(fusion_output)
fusion_output = concatenate([fusion_output, encoder_output], axis=3)
fusion_output = Conv2D(256, (1, 1), activation='relu')(fusion_output)In the merge layer, we first multiply the layer with 1000 categories (1000 category layer) by 1024 (32 * 32). So we get 1024 rows of the final layer from the Inception model. The 32 x 32 grid is converted from two-dimensional to three-dimensional representation, with 1000 columns of categories (category pillars). The columns are then linked to the output of the encoder model. Apply a convolutional network with 254 filters and a 1x1 core to the final results of the merge layer.
What have learned
- Research terminology was intimidating . We spent three days looking for a way to implement the “merger model” in Keras. It sounds so complicated that I just didn’t want to take on this task, we tried to find advice that would facilitate our work.
- Вопросы в сети. В Slack-канале Keras не нашлось ни единого комментария, а на Stack Overflow заданные вопросы были удалены. Но когда мы начали разбирать проблему публично в поисках простого ответа, нам стало понятнее, как решать эту задачу
- Рассылка писем. На форумах вас могут проигнорировать, но если обратиться к людям напрямую, они будут отзывчивее. Нас воодушевили обсуждения работы с цветовыми пространствами с исследователями по Skype!
- После затруднений с решением задачи слияния, мы решили сначала написать все компоненты, а потом объединить их друг с другом. Вот несколько экспериментов по разбиению слоя слияния.
- If it seemed that some component should now work, then there was no certainty about it . We knew that the basic logic was in full order, but we did not believe that it would work. After tea with lemon and a long walk, we decided to launch. An error appeared on the very first line of our model. But four days later, several hundred bugs and several thousand requests to Google, the coveted “Epoch 1/22” appeared while the model was working.
What's next
Coloring images is a very interesting task. Here you have to do both science and creativity. Perhaps this article can save you time. Where could you start:
- Implement another pre-trained model.
- Try another dataset.
- Use more images to increase the accuracy of the neural network.
- Написать усилитель (amplifier) для цветового пространства RGB. Создайте аналогичную модель для раскрашивающей сети, которая берёт на вход очень насыщенные цветные изображения, а на выходе получаются картинки с корректными цветами.
- Реализуйте взвешенную классификацию.
- Примените нейросеть к видео. Уделите внимание не точности раскрашивания, а стабильности переходов между отдельными кадрами. Или можете собирать большие изображения из мелких «лоскутков».
Можете раскрасить свои чёрно-белые изображения с помощью всех трёх описанных версий нейросети на FloydHub.
- Для применения альфа-версии просто замените файл woman.jpg на свой файл с тем же названием (размером 400x400 пикселей).
- For the beta and full versions, add your images to the Test folder, and then run the FloydHub command. Or you can download them directly into a Notebook folder in the Test folder, right at work. These images must be strictly 256x256 pixels. All test images can be downloaded in color, they will still be automatically converted to black and white.