kubernetes, playground, microservices and a bit of magic
In the life of any DevOps engineer, there is a need to create a playground for the development team. As always, he should be smart, smart and consume a minimal amount of resources. In this article I want to talk about how I solved the problem of creating such a beast for a microservice application on kubernetes.

A little about what the system is for which it was necessary to create a playground:
Requirements that we were able to formulate with active communication with team leader:
From the very beginning it was clear that the most logical way to create parallel spaces in k8s is the most logical way to use the native tool of virtual clusters, or in the terminology of k8s - namespaces. The task is also simplified by the fact that all interactions within the cluster are performed using the short names provided by kube-dns, which means that the structure can be launched in a separate namespace without losing connectivity.
This solution has only one problem - the need to deploy all available services in namespace, which is long, inconvenient and consumes a large amount of resources.
When creating any service, k8s creates a DNS record of the form..svc.cluster.local . This mechanism allows communication through short names within the same namespace due to changes made to resolv.conf of each launched container.
In the normal state, it looks like this: that is, you can access the service in the same namespace by name
in adjacent namespace by name .
At that moment, the simple thought comes to my mind: “ The base is general, the api-gateway is responsible for routing service requests, why not make it go to the service first in its namespace, and if it is not in default? ”
Yes, such a solution could be organized namespace settings (we remember that this is nginx), but such a solution will cause a difference in the settings on pg and on other clusters, which is inconvenient and can cause a number of problems.
So, the method of replacing the string With was chosen. This approach will automatically switch to namespace default in the absence of the necessary service in its namespace.

A similar result can be achieved in a cluster as follows. Kubelet adds search parameters to the container from resolve.conf of the host machine, so it’s enough to simply add a line to /etc/resolv.conf of each node:
If you do not want the addresses to be resolved by the nodes, you can use the --resolv- parameter conf when kubelet starts, which allows you to specify any other file instead of /etc/resolv.conf. For example, the file /etc/k8s/resolv.conf with the same line.
The further decision is quite simple, you just need to accept the following agreements:
Nginx config to redirect requests to api-gw in the corresponding namespace
To automate the deployment process, the Jenkins Pipeline Multibranch Plugin plugin is used .
In the project settings, we indicate that only branches matching the play / * pattern are to be collected. And we add Jenkinsfile to the root of all projects the collector will work with.
A groovy script is used for processing, I will not give it in its entirety, just a couple of examples. The rest of the deployment is fundamentally no different from the usual.
Getting branch name:
The minimal configuration of namespace requires an expanded api-gateway, so we add a call to the project creating the namespace and deploying the api-gateway into it:
There is no silver bullet, but I still could not find not only best practices, but also descriptions of how the sandboxes are organized from others, so I decided to share the method that I used to create the sandbox based on k8s. Perhaps this is not an ideal way, so I will gladly accept comments or stories about how this problem is solved with you.
Incoming conditions and requirements
A little about what the system is for which it was necessary to create a playground:
- Kubernetes, bare-metal cluster;
- Simple api-gateway based on nginx;
- MongoDB as a database;
- Jenkins as a CI server;
- Git on Bitbucket;
- Two dozen microservices that can communicate with each other (via the api-gateway), with the base and with the user.
Requirements that we were able to formulate with active communication with team leader:
- Minimization of resource consumption;
- Minimizing changes in the code of services for working on the playground;
- Possibility of parallel development of several services;
- Ability to develop multiple services in one space;
- The ability to demonstrate changes to customers before deploying to staging;
- All developed services can work with one database;
- Minimize developer efforts to deploy test code.
Reflections on the topic
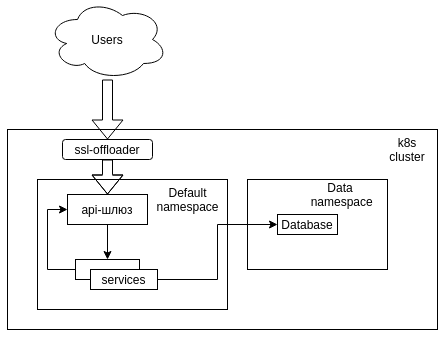
From the very beginning it was clear that the most logical way to create parallel spaces in k8s is the most logical way to use the native tool of virtual clusters, or in the terminology of k8s - namespaces. The task is also simplified by the fact that all interactions within the cluster are performed using the short names provided by kube-dns, which means that the structure can be launched in a separate namespace without losing connectivity.
This solution has only one problem - the need to deploy all available services in namespace, which is long, inconvenient and consumes a large amount of resources.
Namespace and DNS
When creating any service, k8s creates a DNS record of the form
In the normal state, it looks like this: that is, you can access the service in the same namespace by name
search .svc.cluster.local svc.cluster.local cluster.local
nameserver 192.168.0.2
options ndots:5 Go around the system
At that moment, the simple thought comes to my mind: “ The base is general, the api-gateway is responsible for routing service requests, why not make it go to the service first in its namespace, and if it is not in default? ”
Yes, such a solution could be organized namespace settings (we remember that this is nginx), but such a solution will cause a difference in the settings on pg and on other clusters, which is inconvenient and can cause a number of problems.
So, the method of replacing the string With was chosen. This approach will automatically switch to namespace default in the absence of the necessary service in its namespace.
search .svc.cluster.local svc.cluster.local cluster.local search .svc.cluster.local svc.cluster.local cluster.local default.svc.cluster.local A similar result can be achieved in a cluster as follows. Kubelet adds search parameters to the container from resolve.conf of the host machine, so it’s enough to simply add a line to /etc/resolv.conf of each node:
search default.svc.cluster.localIf you do not want the addresses to be resolved by the nodes, you can use the --resolv- parameter conf when kubelet starts, which allows you to specify any other file instead of /etc/resolv.conf. For example, the file /etc/k8s/resolv.conf with the same line.
Matter of technology
The further decision is quite simple, you just need to accept the following agreements:
- New features are developed in separate branches of the form play /
- To work with several services within the same feature, the branch names must match in the repositories of all the services involved.
- Jenkins does all the deployment work automatically.
- For tests, feature branches are available at
.cluster.local
Ssl-offloader settings
Nginx config to redirect requests to api-gw in the corresponding namespace
server_name ~^(?.+)\.cluster\.local;
location / {
resolver 192.168.0.2;
proxy_pass http://api-gw.$namespace.svc.cluster.local;
} Jenkins
To automate the deployment process, the Jenkins Pipeline Multibranch Plugin plugin is used .
In the project settings, we indicate that only branches matching the play / * pattern are to be collected. And we add Jenkinsfile to the root of all projects the collector will work with.
A groovy script is used for processing, I will not give it in its entirety, just a couple of examples. The rest of the deployment is fundamentally no different from the usual.
Getting branch name:
def BranchName() {
def Name = "${env.BRANCH_NAME}" =~ "play[/]?(.*)"
Name ? Name[0][1] : null
}The minimal configuration of namespace requires an expanded api-gateway, so we add a call to the project creating the namespace and deploying the api-gateway into it:
def K8S_NAMESPACE = BranchName()
build job: 'Create NS', parameters: [[$class: 'StringParameterValue', name: 'K8S_NAMESPACE', value: "${K8S_NAMESPACE}"]]
build job: 'Create api-gw', parameters: [[$class: 'StringParameterValue', name: 'K8S_NAMESPACE', value: "${K8S_NAMESPACE}"]]
Conclusion
There is no silver bullet, but I still could not find not only best practices, but also descriptions of how the sandboxes are organized from others, so I decided to share the method that I used to create the sandbox based on k8s. Perhaps this is not an ideal way, so I will gladly accept comments or stories about how this problem is solved with you.