Data Science: About love, names and more. Part II
Because in much wisdom there is much sadness;
And whoever multiplies knowledge, multiplies sorrow.
• Ecclesiastes 1:18
This article cannot serve as a pretext for expressing intolerance or discrimination on any grounds.
In the first part of the article, I only outlined the problem, which was as follows: the probability of being alone / lonely depends on the person’s name . It would be more correct to use the word correlation , however, I still allow myself some linguistic liberty once again in this matter and I hope that everyone understands this statement correctly. However, I would like to thank everyone for the comments on my previous article.
In one of the comments I said that it is quite possible that there is some third factor that correlates with name and loneliness. As an illustration, I gave an example with apples: suppose that loneliness depends on how many apples a girl eats, and for some reason, girls named Katya eat more apples than Masha has. It is clear that for each specific Masha or Katya this does not mean absolutely anything, but on average it turns out that some are more alone than others because they eat apples in different quantities.
In fact, the problem boils down to another exactly the same: why do people with the same name eat more apples than others? However, an explanation of this correlation may be simpler.
Cherry picking and statistical significance
Before I continue, I will make a few comments about the selection in the previous article, because we will continue to work with it. On the one hand, I really prefer quality arguments. On the other hand, I understand people who ask why the sample was just that and whether the results are statistically significant. I deliberately did not write anything about statistical significance, because the situation when two "random" processes behave identically in different systems, with different people and the mechanics of status setting seems completely unbelievable to me. As for the choice of names, there is an element of randomness (I tried to take not only the names of my friends of the girls, but also fill in the parts of the distribution that were missing in the frequency sense), but I did not do anything on purpose, except to limit myself in quantity,
However, at the request of the workers (as written in one of the comments), I took 100 completely random names for which there were enough statistics in Odnoklassniki and checked what would happen if the names themselves were mixed. If I got exactly the same distribution (after counting u), as some people predicted, it would be possible to say that the result is not statistically significant and in the best case we can talk about dependence only on the frequency of the name. However, the Mann-Whitney test showed p-value = 0.000256, i.e. the initial distribution and what happened with mixing are completely different things.
Therefore, I will continue to use the original tables, considering them to be sufficiently representative for our study.
Will I have a problem with you, Bond?
My experience at St. Petersburg State University prompted me to the following thought (it seems to me that she did not visit me alone): what if more intelligent people are more alone? That is, all this dialogue between Bond and Vesper in the picture from the movie Casino Royale is a kind of tautology in the probabilistic sense.
It is well known that IQ tests are not very representative, and it is not possible to directly measure IQ on a social network. But we can make the following assumption: people who have higher education are, on average, smarter than those who do not. Of course, this is a so-so criterion, because almost everyone has a higher education. Therefore, you can try to take more or less elite educational institutions, but such that the diversity of specialization was good enough. Therefore, we will try to do the following: for the city of St. Petersburg we will see the distribution of names among students of St. Petersburg State University, and for Moscow - respectively, among students of Moscow State University. This is again a speculative assumption, but on average it is quite viable for our purposes.
Let's do the following: just find those who studied at St. Petersburg State University and Moscow State University with a given name and divide by the number of all with that name in the desired city. In truth, the name of Layla should be removed here, i.e. it has some "regional specificity", but for completeness we will not touch anything.
Let's see what happened and compare with those tables for the cities of St. Petersburg and Moscow, which I did for the previous article:
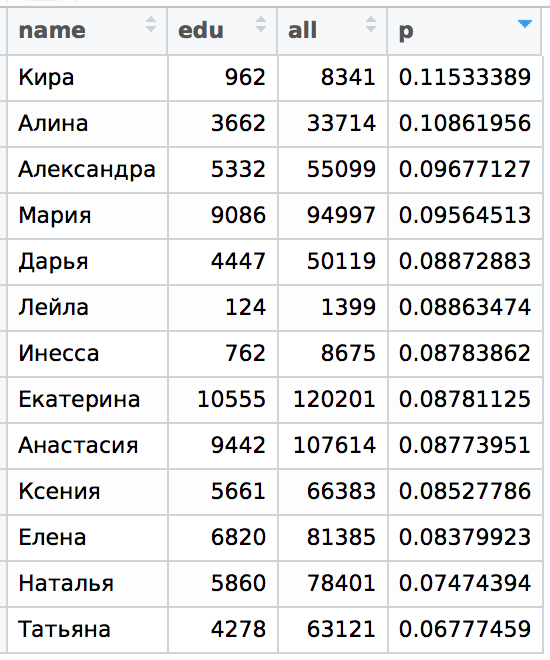
Here p = edu / all, i.e. the proportion of girls with a given name (according to VK statistics) who studied or are studying at St. Petersburg State University in the total volume of people with the same name in St. Petersburg.
Now the same for MSU:
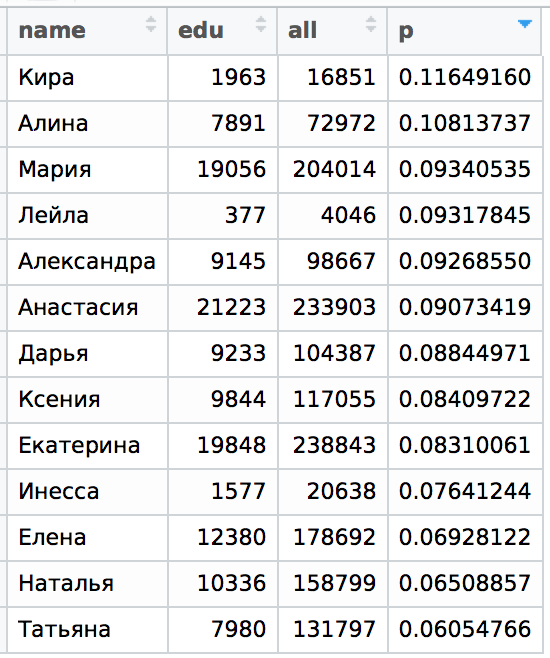
Let's take a look again for comparison at the tables from the previous article. Here is the distribution of St. Petersburg ( q- this is a unified indicator of "loneliness", the full range of designations can be found in the first part of the article ).
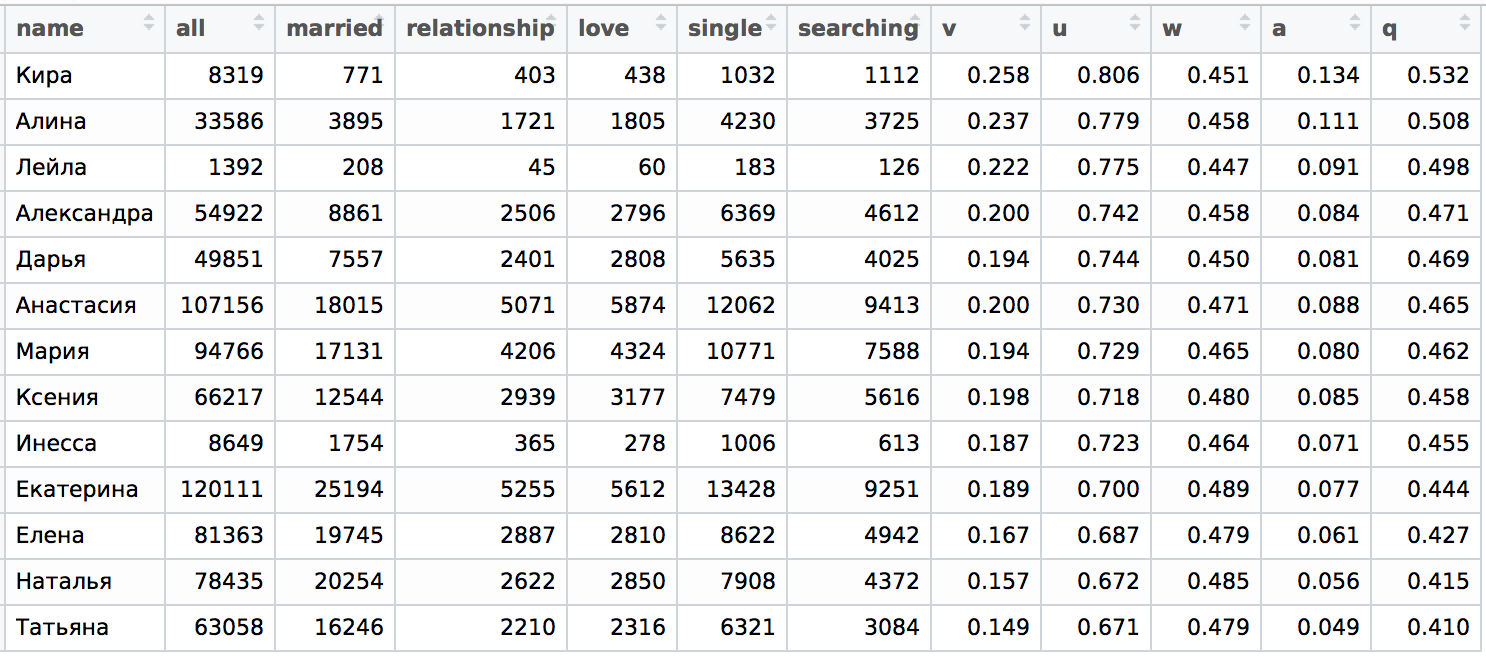
For Moscow, the distribution is as follows:
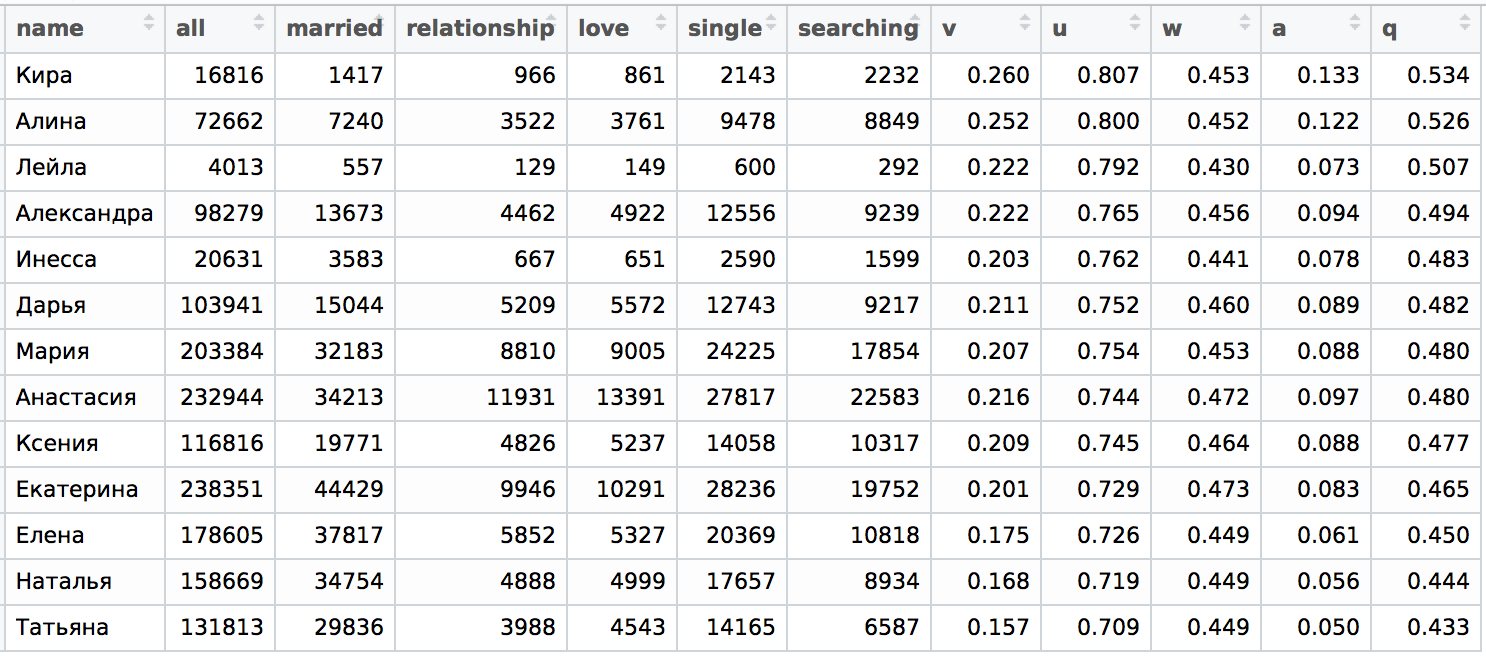
It can be seen that at least the upper and lower parts of the table coincide when sorting by pand qmore or less, the average is a bit mixed, but there are no significant permutations between the parts. In the case of the name Inessa, there is some discrepancy; for an accurate analysis, it would be necessary to separate the name Inna and Inessa and see the distribution details for Moscow and St. Petersburg. But here we will not do this, we will limit ourselves only to a qualitative assessment. To do this, we construct a “dependence” qon pfor the case of St. Petersburg:
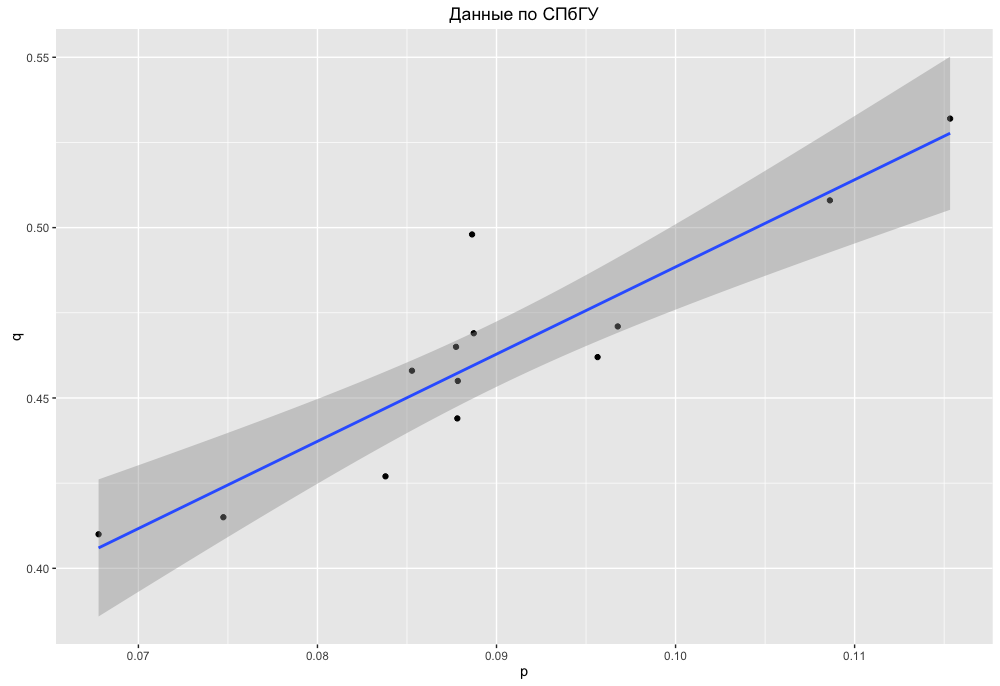
Now the same schedule for MSU:

That is, it turns out that more intelligent and well-educated girls are more alone. This is all of course conditional, and it is possible, for example, that this only means a later marriage.
University ranking
In fact, if there is a correlation between loneliness and good education, then, probably, loneliness can be considered a measure of the quality of education and intelligence (of course, in a probabilistic sense). Therefore, I took several good universities that I could immediately recall (and which I managed to find with some difficulty in a search in the VK) and decided to calculate for them the very indicators q, uand vwhich in the last article I counted for a lot of names. As in the case of names, I took and sorted by q(as an additional parameter, I calculated diversity d = all / (all + all_m)by gender, where all_mis the number of young people at the university):
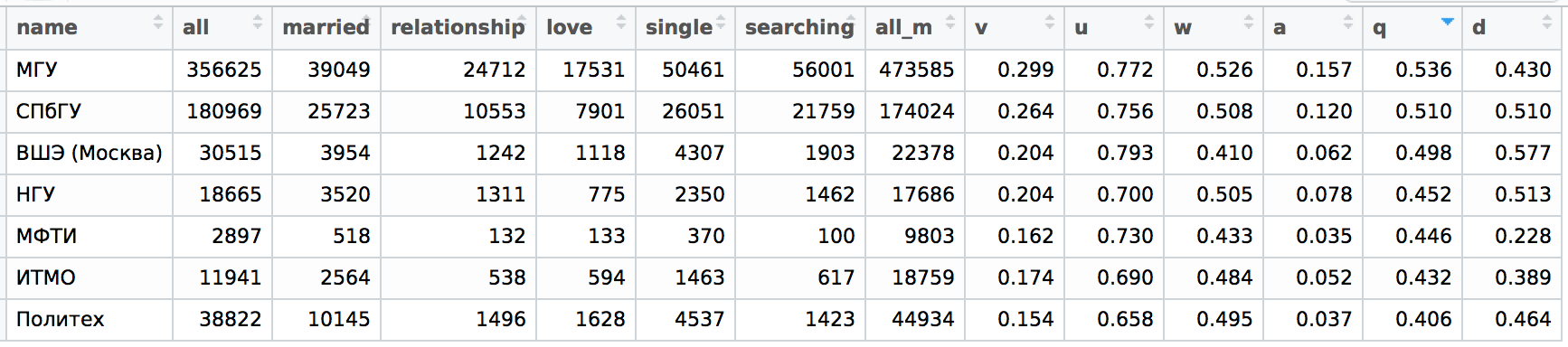
Does this remind you of anything? That's right, if you google the university rating, you can find the following (this is the top of the national rating):
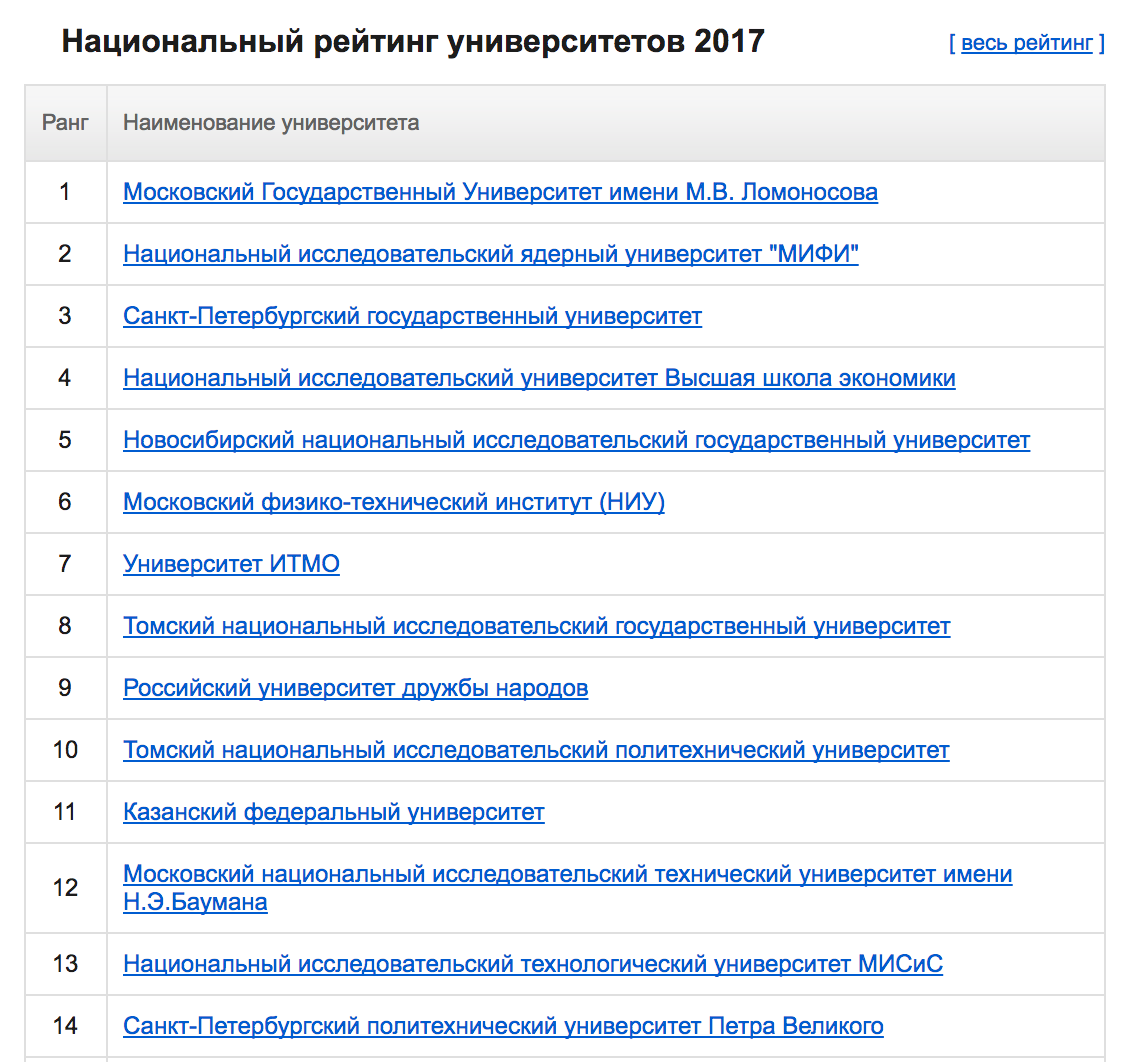
Who wants to see the full rating, go here: National University Ranking 2017 . Of course, not all universities are in my table, and for universities with a low rating, this does not work like this (for example, for the Herzen State Pedagogical University), but this definitely makes me wonder.
Instead of a conclusion
It is hard to say how much we have come close to understanding what is happening. However, the correlation between education and loneliness no longer looks as crazy as the correlation between name and loneliness.
Here I used Odnoklassniki data only to check the statistical significance of the results of the previous article, and everything else was built entirely on VKontakte data.