Predictive Web Interface Behavior
Immediately, it should be noted that this article is only subjective reflections on how the behavior of interface elements that the user is doing at a particular moment can look and be realized. Reflections, however, supported by a little research and implementation. Go.
At the dawn of the Internet, sites did not look for individuality in styling basic interface elements. The variability was small, so the pages were fairly uniform in their components.
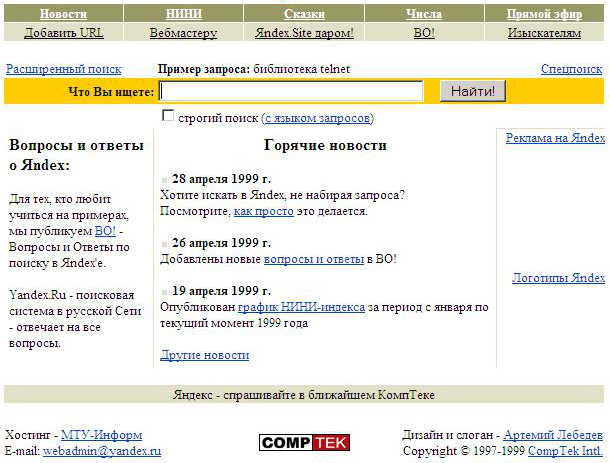
Each link looked like a link, a button like a button, and a checkbox like a checkbox. The user knew what his action would lead to, because he had a clear idea of how each element works.
The link should be sent to another page, no matter where the link comes from, from the navigation menu or from the text in the description. The button will change the contents of the current page, possibly, by sending a request to the server. The state of the checkbox will most likely not affect the content in any way until we press the button of some action that uses this state. Thus, it was enough for the user to look at the interface element in order to more likely understand how to interact with it and what it will lead to.
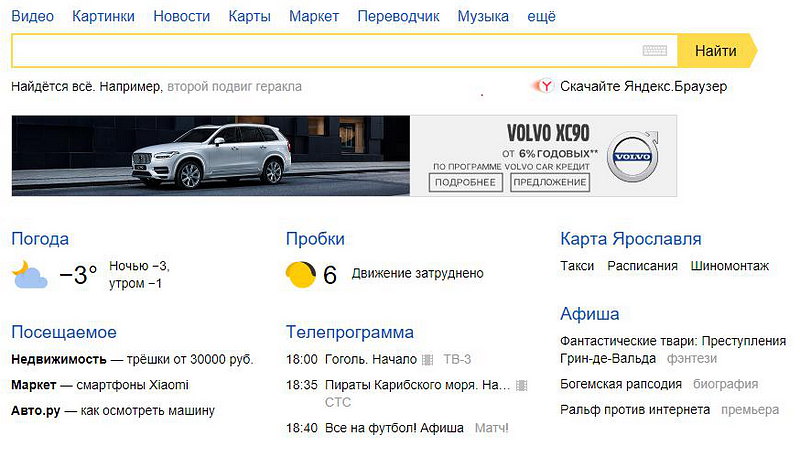
Modern websites provide the user with a much larger number of puzzles. All links look completely different, buttons do not look like buttons, and so on. To understand whether a line is a link, the user must hover the cursor on it to see the color change to a more contrasting one. To understand whether an element is a button, we also hover the mouse to see the change in the fill tone. With the elements of the various menus, too, everything is difficult, some of them will probably expand an additional submenu, and some will not, although outwardly they are identical.
However, we quickly get used to the interfaces that we use regularly, and are no longer confused in the functionality of the elements. A major role is played by the general continuity of interfaces. Looking at the page above, we most likely immediately realize that the yellow arrow with the word “Find” is not just a decorative element, but a button, although it does not look like a standard HTML button at all. So, in terms of predictability and individuality, most resources have come to a stable consensus adopted by users.
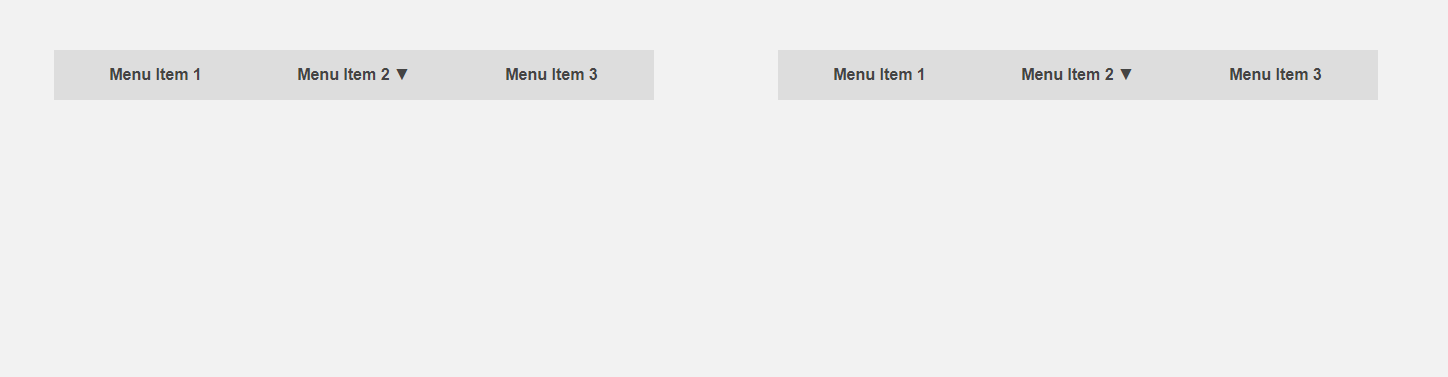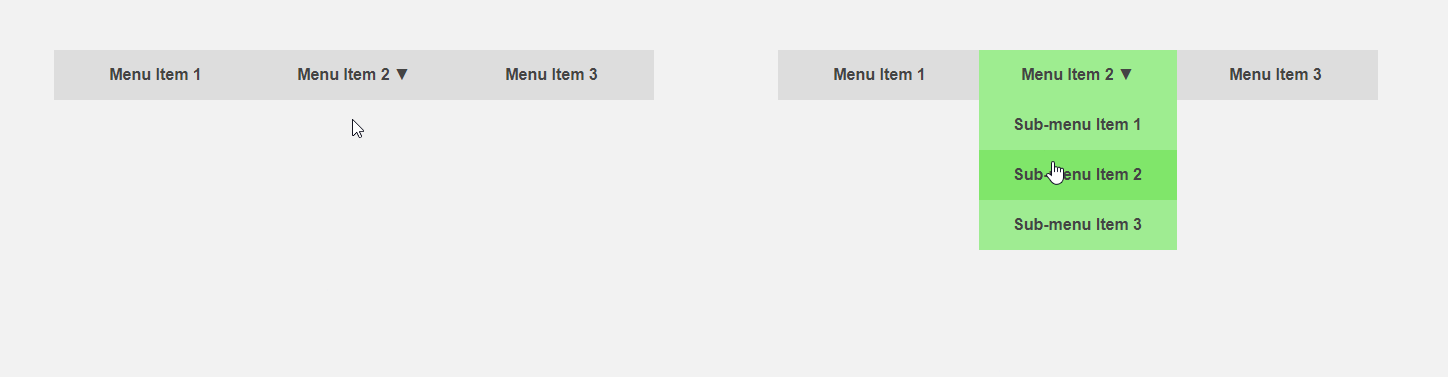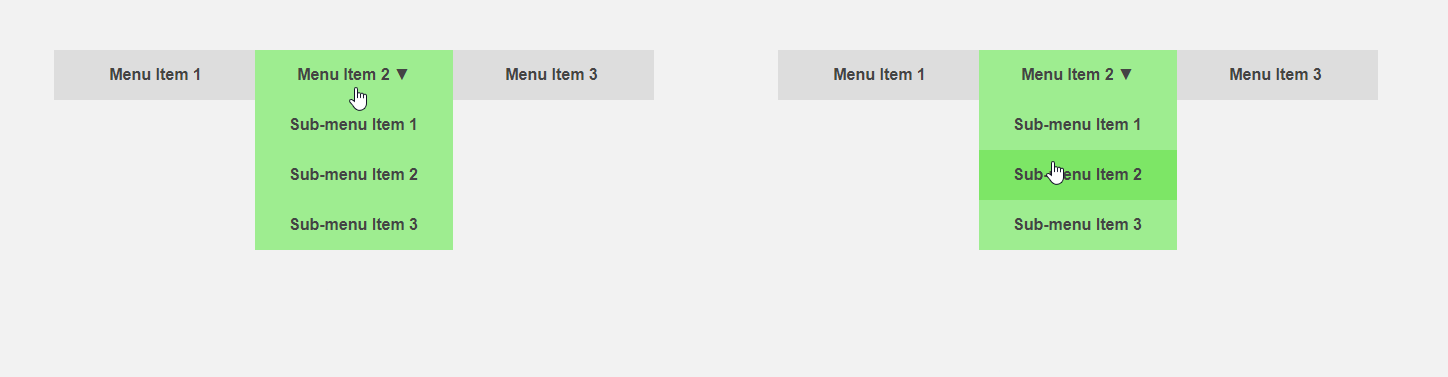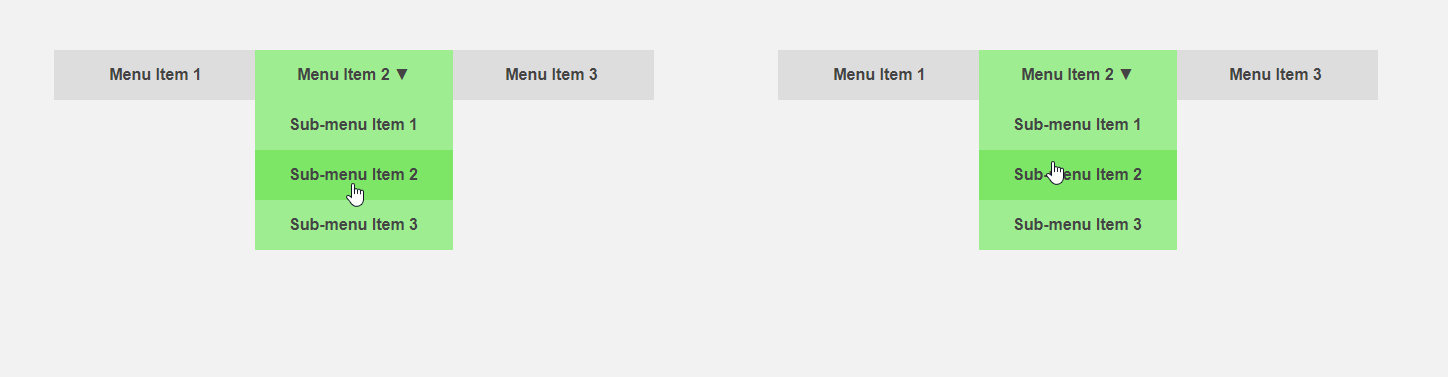
On the other hand, it would be interesting to get an interface that tells the user in advance about the specifics of an element or performs part of the routine work for it. The cursor moves in the direction of the menu item - you can expand the submenu in advance, thereby speeding up the interaction with the interface, the user directs the cursor to the button - you can load additional content that is required only after pressing. The article header compares the standard interface (left) and the predictive one.
A simple visual test shows that analyzing the speed of the cursor and its derivatives, it is possible to predict the direction of movement and the coordinates of the stop in a certain number of steps. Considering that motion events are triggered with a frequency constant relative to the magnitude of the acceleration, the speed decreases as one approaches the target. Thereby, it is possible to recognize the action scheduled by the user in advance, which leads to the advantages already announced.

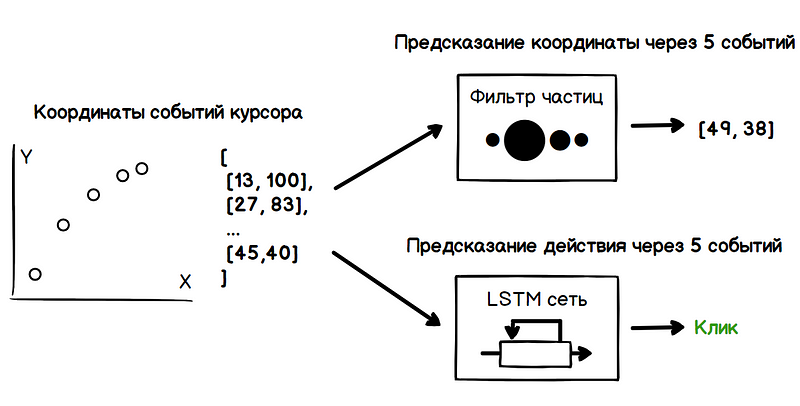
Thus, the problem involves two tasks: determining the future coordinates of the cursor and determining the user's intentions (guidance, click, selection, and so on). All these data should be obtained only on the basis of the analysis of the previous values of the coordinates of the cursor.
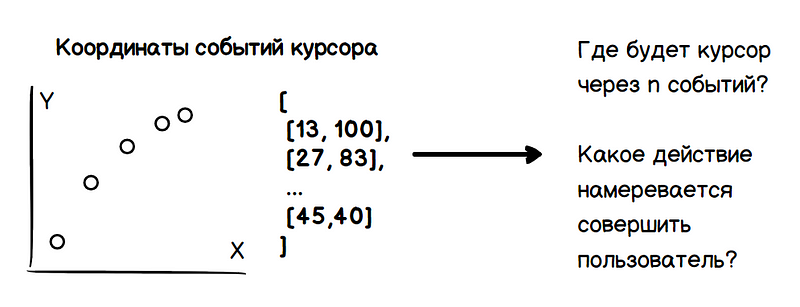
The primary task is to estimate the direction of movement of the cursor, rather than predicting the moment of stopping, which is a more complex problem. As an estimate of the parameters of a noisy quantity, the problem of calculating the direction of motion can be solved by a mass of known methods.
The first option that comes to mind is a filter based on a moving average . Averaging the values of speed in previous moments, you can get its value in subsequent. Previous values can be weighted according to a certain law (linear, power, exponential) to increase the influence of nearby states, reducing the contribution of more distant values.
Another option is to use a recursive algorithm, such as a particle filter.. To estimate the speed of the cursor, the filter creates many hypotheses about the current value of the speed, also called particles. At the initial moment, these hypotheses are absolutely random, but further along the direction of travel, the filter removes invalid hypotheses and periodically at the redistribution stage generates new ones based on reliable ones. Thus, out of a multitude of hypotheses, only the ones closest to the true value of the speed remain.
In the example below, when the cursor moves, each of the particles for visualization is set to a radius value directly proportional to its weight. Thus, the region with the highest concentration of heavy particles characterizes the most probable direction of movement of the cursor.
However, the received direction of movement is not enough to determine the intentions of the user. With a high density of interface elements, the cursor path can run over a lot of them, which will lead to a lot of false positives of the prediction algorithm. This is where machine learning methods come to the rescue, namely recurrent neural networks.
The coordinates of the cursor movement are a sequence of strongly correlated values. When the movement is slowed down, the difference between the coordinates of the neighboring positions on the time scale decreases from event to event. At the beginning of the movement, a reverse tendency is noticeable — coordinate intervals increase. Probably, with acceptable accuracy, this problem can be solved analytically by examining the values of derivatives in different parts of the path and encoding the trigger threshold, based on the behavior of these values. But by its nature, the coordinate sequence of the cursor positions looks like a data set that fits well with the principles of the networks of long short-term memory.
Lstmnetworks are a specific kind of recurrent neural network architecture, adapted to learning long-term dependencies. This is facilitated by the ability to memorize information by network modules for a number of states. Thus, the network can reveal signs based on, for example, how long the cursor slowed down, what preceded it, how the cursor speed changed at the beginning of the slowdown, and so on. These signs characterize specific patterns of user behavior in certain actions, such as clicking on a button.
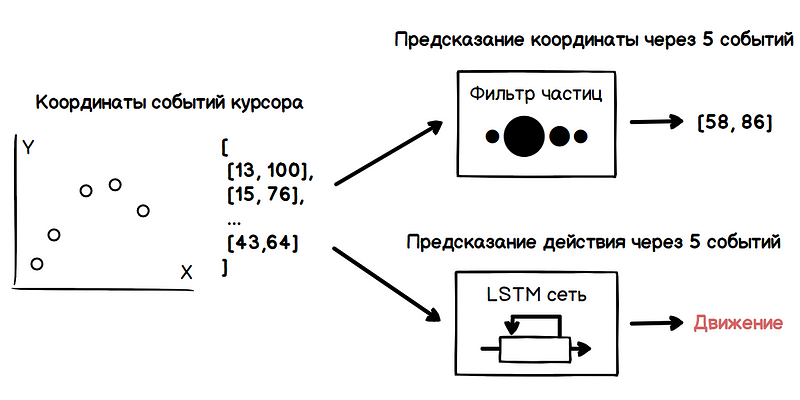
Thus, by continuously analyzing the data obtained at the output of the particle filter and the neural network, we get a moment when you can, for example, show a drop-down menu, as the user leads the cursor to it in order to open it in the next second. Performing this analysis for each event from the mouse, it is difficult to miss the right moment.
LSTM network training can be conducted on a data set obtained in the process of analyzing the behavior of a user who performs a series of tasks designed to identify its features when interacting with the interface: click a button, move the cursor over a link, open a menu, and so on. The following is an example of the operation of the matrix of predictive elements only on the basis of a particle filter, without neural network analysis.

The animation below demonstrates the contribution of the neural network to the process of predicting user behavior. False positives become significantly less.

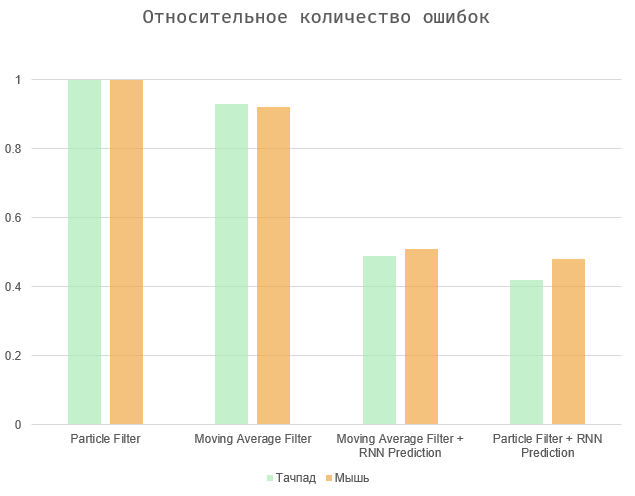
In general, the task is reduced to balancing between two values - the time period between the action and its prediction and the number of errors (false positives and gaps). The two extreme cases are to select all elements on the page (the maximum prediction period, a huge number of errors), or to force the algorithm to operate directly during the user action (zero prediction period and missing errors).
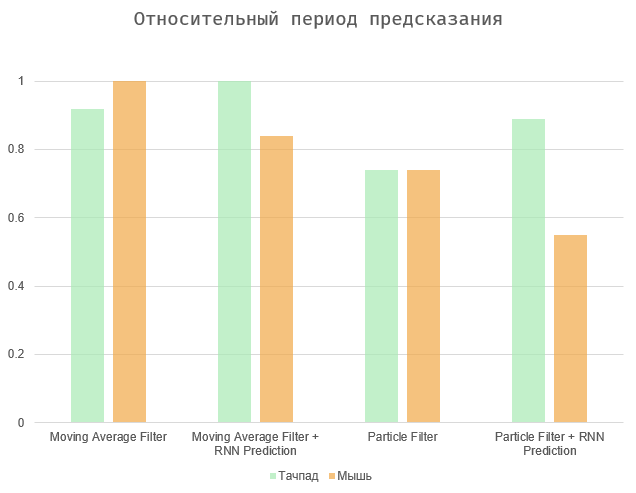
The diagrams show the results normalized to maximum values, since the user’s speed is very individual, and the number of errors depends on the interface in question. Algorithms based on the moving average and particle filter show approximately similar results. The second is a bit more accurate, especially in the case of using the touchpad. Ultimately, all of these parameters can be highly dependent on the specific user and device.
In conclusion, there is a small demo of the predictive behavior of HTML elements, which is far from perfect, but reveals a little.
Of course, in such tasks it is crucial to strike a balance between functionality and predictability. If the resulting behavior is incomprehensible to the user, the irritation caused negates all efforts. It is difficult to say whether it is possible to make the learning process of the algorithm imperceptible to the user, for example, during the first sessions of his communication with the page interface, so that, using trained algorithms, the interface elements can be predictive. In any case, additional additional training will be necessary due to the individual characteristics of each person and this is the subject of additional research.