Bumps packed over 15 years of using actors in C ++. Part II
We conclude the story begun in the first part . Today we’ll look at a few more rakes that happened over the years of using SObjectizer in everyday work.
We continue to list the rake
People want synchronization ...
Actors in the Actors Model and agents in our SObjectizer communicate via asynchronous messages. And this is one of the reasons for the attractiveness of the Model of Actors for some types of tasks. It would seem that asynchrony is one of the cornerstones, one of the bonuses, so use your health and have fun.
But no. In practice, requests quickly began to make the possibility of synchronous interaction of agents in SObjectizer. For a very long time I resisted these requests. But in the end he gave up. I had to add the ability to execute a synchronous request from one agent to another in SObjectizer .
It looks like this in the code:
// Тип запроса.
struct get_messages final : public so_5::signal_t {};
...
// Инициация синхронного запроса...
auto msgs = request_value, get_messages>(mbox, so_5::infinite_wait);
// ...обработка его результатов.
for(const auto & m : msgs) ... This is a call to the request_value function, which executes a synchronous request, pausing the execution of the current thread until the request result is received.
In this case, we send a request of type get_messages in order to get a vector of message objects in response. And we will wait for an answer without time limit.
However, SObjectizer implements this all the same through a message. Inside the request_value, a message is sent to the target agent, which receives and processes it in the usual way. Those. the recipient does not even know that a synchronous request came to him, for him everything looks like a normal asynchronous message.
class collector : public so_5::agent_t {
public :
...
virtual void so_define_agent() override {
// Подписываемся на запрос.
so_subscribe(mbox).event(&collector::on_get_messages);
...
}
private :
std::vector collected_messages_;
// Обработчик запроса, вызывается при получении сигнала get_messages.
std::vector on_get_messages() {
std::vector r;
std::swap(r, collected_messages_);
return r;
}
}; Those. inside collector :: on_get_messages, the message receiving agent cannot determine whether it received get_messages as a regular asynchronous message or is it part of a synchronous request.
But under the hood is hidden not very complex mechanics, built on the basis of std :: promise and std :: future from the standard C ++ 11 library.
Firstly, when sending a synchronous request, the receiver does not receive a regular message, but a tricky one, along with the std :: promise object inside:
struct special_message : public so_5::message_t {
std::promise> promise_;
...
}; This message gets into a special handler, which is automatically generated by the SObjectizer when subscribing:
collector * collector_agent = ...;
auto actual_message_handler = [collector_agent](special_message & cmd) {
try {
cmd.promise_.set_value(collector_agent->on_get_messages());
}
catch(...) {
cmd.promise_.set_exception(std::current_exception());
}
};
do_special_subscribe(mbox, actual_message_handler); This tricky handler calls the user-defined message handler, and then saves the returned value (or the exception thrown out) to the std :: promise object from the tricky message. This will trigger std :: future, on which the request sender is sleeping. Accordingly, a return from request_value will occur.
Obviously, synchronous interaction between agents is a direct way to obtaining deadlocks. Therefore, there is request_value in SObjectizer, but we recommend using it with great care.
The funny thing for me personally was that very quickly a useful application was found for request_value. Just in the mechanisms of protecting agents from overload. If this protection is done through a pair of collector / performer, then performer is convenient to apply for the next batch of messages through request_value. And since collector and performer agents, in principle, should work on different threads, the danger of getting deadlock here is minimized.
The moral of this story is this: strict adherence to the principles of a theoretical model is good. But if in practice you are urged to do something that conflicts with these very principles, then it makes sense to listen. Something useful might come out.
Distribution out of the box: everything is not so rosy
In SObjectizer-4, the developer was able to create distributed applications out of the box. We had our own protocol on top of TCP / IP, our own way of serializing C ++ data structures.
On the one hand, it was very cool and fun. With the help of simple gestures, it was possible to make messages automatically fly between nodes on which parts of a distributed application were running. SObjectizer took care of data serialization and deserialization, control of transport channels, reconnection during breaks, etc.
In general, at first everything was cool.
But over time, as the range of tasks solved by SObjectizer expanded, as the load on applications grew, we had a lot of troubles:
- firstly, for each type of task it is desirable to have its own protocol. Because, say, the spread of telemetry, i.e. the exchange of a large number of small messages, the loss of some of which is not terrible, is very different from the exchange of large binary files. For example, an application where you need to exchange large archives or pieces of video files should use some other protocol than an application in which thousands of messages from sensors of the current air temperature are transmitted;
- secondly, the implementation of back-pressure for asynchronous agents is not an easy thing in itself. And when communication over the network also mixes in here, the situation becomes much worse. Any delays in the network or braking on one of the nodes leads to the accumulation of large volumes of undelivered messages on the remaining nodes and this pretty much spoils life;
- thirdly, the times when large distributed systems could only be written in one C ++, ended a long time ago. Today, certain components will be written in other programming languages. This means that interoperability is required. Which automatically leads to the fact that our own protocol, sharpened by C ++ and SObjectizer, does not help, but hinders the development of distributed applications.
Therefore, SObjectizer-5 does not have tools to support distribution. We look more towards facilitating agents' communication with the outside world through de facto standard protocols. This is better than inventing your own bicycles.
Many agents are a problem, not a solution. SEDA-wei forever!
Well, this topic is very much like me personally. For they emphasize once again that marketing and common sense can contradict each other :)
Almost all actor frameworks in their marketing materials necessarily say that actors are lightweight entities and in the application you can create at least one hundred thousand actors, at least a million, at least ten million actors.
When an unprepared programmer is faced with the opportunity to create a million actors in a program, his roof may be slightly demolished. It's so tempting to arrange each activity inside the application as an actor.
A programmer succumbs to such a temptation, begins to create actors for everyone and soon discovers that he has tens of thousands or even hundreds of thousands of actors working in his program ... Which can lead to at least one of two problems.
What is going on inside the application with a million actors?
The first problem that you can encounter when creating a large number of actors is a lack of understanding of what is happening in the program, why the program works this way and how the program will behave further.
What happens is what I call the effect of a bird flock: the behavior of an individual bird in a flock can be described by a set of several simple rules, while the configuration of the entire flock is complex and almost unpredictable.
Similarly, in an application with a large number of agents. Each agent can work according to simple and understandable rules, but the behavior of the entire application can be difficult to predict.
For example, some agents suddenly stop showing signs of life. It seems like they are, but their work is not visible. And then suddenly they “wake up” and start working so actively that there are not enough resources for other agents.
In general, keeping track of what is happening inside the application with ten thousand agents is much more complicated than in an application where only one hundred agents work. Imagine that you have ten thousand agents and you wanted to know how heavily loaded one of them is. I think this will already be a problem.
Incidentally, one of Erlang's killer features is that Erlang provides tools for introspection. A developer can at least see what is going on inside his Erlang virtual machine. How many processes, how much each of the processes eats, what the size of the queues, etc. But Erlang has its own virtual machine, and there it is possible.
If we are talking about C ++, then C ++ frameworks, as far as I know, are very far behind Erlang in this area. On the one hand, this is objective. Still, C ++ compiles to native code and monitoring pieces of native code is much more difficult. On the other hand, the implementation of such monitoring is a non-trivial task, requiring a lot of labor and investment. Therefore, it is difficult to expect advanced features in OpenSource frameworks that are developed only with pure enthusiasm.
So, creating a large number of agents in a C ++ application and not having the same advanced monitoring tools as in Erlang, it’s difficult to monitor the application and understand what works there.
Sudden bursts of activity
The second possible problem is sudden bursts of activity, when part of your actors suddenly begins to consume all available resources.
Imagine that you have 100 thousand agents in the application. Each of them initiates some operation and sets a timer to control the timeout of the operation.
Suppose a piece of the application began to slow down, previously started operations began to fall off by timeout, and pending messages about the expiration of timeouts began to arrive in batches. For example, within 2 seconds, 10 thousand timers worked. This means calling 10 thousand pending message handlers.
And here it may turn out that for some reason each such handler spends 10ms. This means that it will take 100 seconds to process all 10 thousand pending messages. Even if these messages will be processed in four parallel threads. But it's still 25 seconds.
It turns out that part of our application will stupidly freeze for these 25 seconds. And until it processes these 10,000 pending messages, it will not respond to anything else.
Misfortune never comes alone...
The saddest thing is that both of the above problems overlap perfectly. Due to a sudden burst of activity, we are faced with unplanned behavior of our application, and because of the effect of the bird flock, we cannot understand what is happening. The application seems to work, but somehow it’s not. And it is not clear what to do about it. You can, of course, stupidly beat the application and restart it. But this means re-creating 100 thousand agents, restoring them in some state, resuming connections to some external services, etc. Unfortunately, such a restart will not cost you.
So the ability to create a bunch of agents in your application should not be treated as a way to solve your problems. And as a way to make yourself even more problems.
The solution, of course, is simple: you need to do with fewer agents. But how to do that?
SEDA Approach
Introducing the SEDA (Staged Event-Driven Architecture) approach very well puts brains in place . In the early 2000s, a small group of researchers developed the Java framework of the same name and with its help proved the viability of the underlying idea: to break down the execution of complex operations into stages, to allocate a separate flow of execution (or a group of threads) for each stage, and organize the interaction between stages through asynchronous message queues.
Imagine that we need to service a payment request. We receive a request, check its parameters, then check the possibility of making a payment for a given client (for example, did he exceed the daily limits on his payments), then we assess the risk of the payment (for example, if the client is from Belarus, and the payment is for some reason initiated from Bangladesh , then this is suspicious), then we are already debiting funds and generating the payment result. Here you can clearly see several stages of processing a single operation.
The ability to create a million agents in the application pushes us to create one agent for each payment, who himself would consistently carry out all stages. Those. he himself would validate the payment parameters, he would determine the daily limits and their excess, he would make requests to the fraud monitoring system, etc. Schematically, it could look like this:

In the case of the SEDA approach, we could do one agent for each stage. One agent accepts payment requests from customers and transfers them to the second agent. The second agent checks the request parameters and sends valid requests to the third agent. The third agent checks the limits, etc. Schematically, it looks like this:
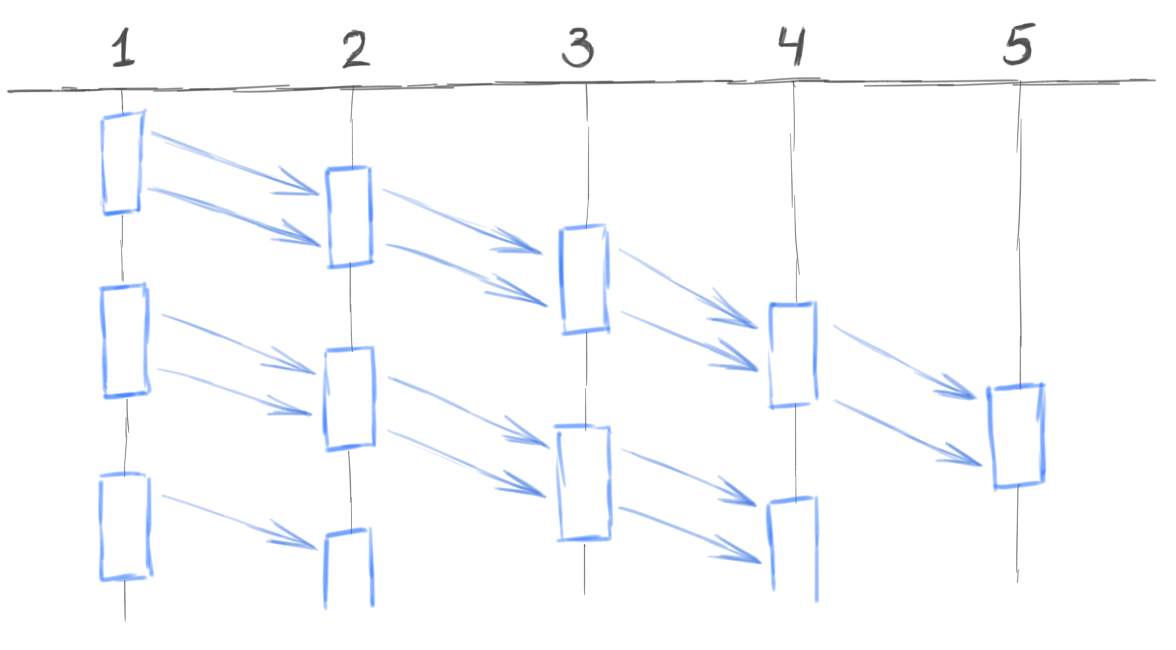
The number of agents is reduced by orders of magnitude. Monitoring these agents is much easier. The protection of such agents from overloads is greatly simplified. These agents, if they work with the DBMS, get the opportunity to use bulk operations. Those. the agent accumulates, say, 1000 messages, then serves them all with 2-3 bulk-calls to the database. We have the opportunity to dose the activity of agents. For example, if an external fraud monitoring system suddenly falls off and we need to generate 10 thousand negative answers, then we may not immediately send all these 10 thousand answers, but spread them evenly, say, for ten seconds. Thus, we protect other parts of the system from overload.
An additional bonus: if only one agent serves a certain stage, the task of prioritizing transaction processing at this stage is greatly simplified. For example, if you need to process transactions from on-line clients with higher priority than scheduled transactions. In the case of the SEDA approach, this is implemented easier than when each agent is responsible for each transaction.
Moreover, even within the framework of the SEDA approach, we still take advantage of the benefits that the Model of Actors gives us. But we are limited to literally a few tens of actors, instead of tens of thousands.
Conclusion
In conclusion, I want to say that the Model of Actors is a cool joke, but not a silver bullet at all. In some tasks, the Model of Actors works well, in some it is not very, in some it does not work at all.
But even if the Model of Actors fits the task, then still a couple of things would not really hurt:
- firstly, the developer himself must have a head on his shoulders. If a developer thoughtlessly creates hundreds of thousands of actors in his application, does not think about the problem of overload, has no idea what a spontaneous burst of activity is, etc., then you can make as much trouble with the Model of Actors as you can with “ bare threads;
- secondly, it would be good for the actor framework to provide all possible assistance to the developer. In particular, in such things as protecting actors from overload, error handling and introspection of what is happening inside the application. That is why we are gradually expanding the functionality of SObjectizer in this direction. We have already added such things as limits for messages, reaction to exceptions, collection of statistics and monitoring information, as well as tools for tracing the message delivery mechanism.
By the way, just a set of such auxiliary tools in an actor’s framework, in my opinion, is some sign that determines the maturity of the framework. For to implement an idea in your framework and show its performance is not so difficult. You can spend several months of work and get quite a working and interesting tool. This is all done with pure enthusiasm. Literally: I liked the idea, I wanted and did it.
But equipping what happened with all sorts of auxiliary means, such as collecting statistics or tracing messages, is already a boring routine, which is not so easy to find time and desire.
Therefore, my advice to those who are looking for a ready-made actor framework: pay attention not only to the originality of ideas and the beauty of examples. Look also at all sorts of auxiliary things that will help you figure out what is happening in your application: for example, to find out how many actors are inside now, what are their queue sizes, if the message does not reach the recipient, then where does it go ... If the framework does provides something like that, it will be easier for you. If it does not, then you will have more work.
Well, I’ll add on my own: if you wanted to take and create from scratch your own actor framework that would protect the developer from the rake discussed above, then this is not a good idea. Occupation is absolutely ungrateful. Yes, and hardly paid back. This has already been verified. In public.