Queues and locks. Theory and practice
We exhaled after HighLoad ++ and continue to publish the best reports of past years. HighLoad ++ turned out great, the number of organizational improvements spasmodically grew into a new product quality. Habr, by the way, conducted a text broadcast from the conference ( first , second days).

Dear colleagues! My report will be about the thing that no HighLoad project can do without - about the queue server, and if I have time, I’ll talk about locks (note the decryptor - I did :).

What will the report be about? I’ll talk about where and how queues are used, why all this is needed, and a little bit about protocols.
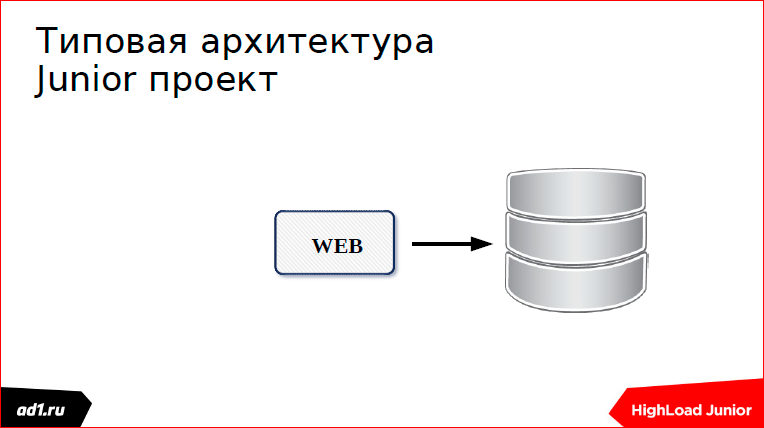
Because our conference calls HighLoad Junior, I would like to go from a Junior project. We have a typical Junior project - this is some kind of web page that accesses the database. Maybe this is an electronic store or something else there. And so, users went and went to us, and at some stage we got a mistake (maybe another mistake):

We went online, began to explore how to scale, we decided to get backends.
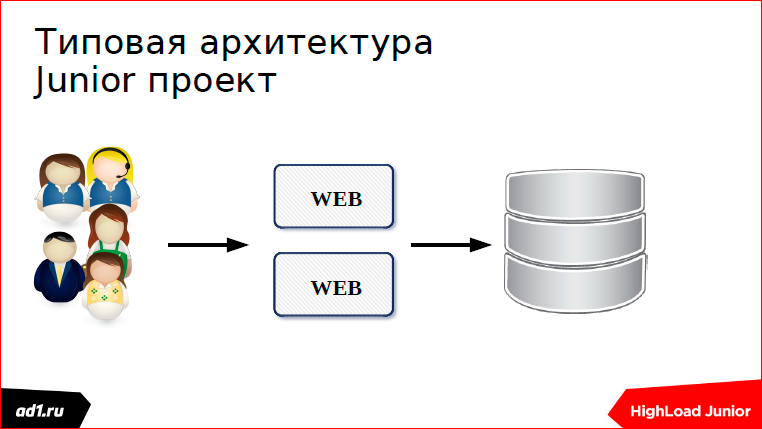
More users went, and more users, and we got another mistake:

Then we climbed into the logs, looked at how you can scale the SQL server. Found and made replication.
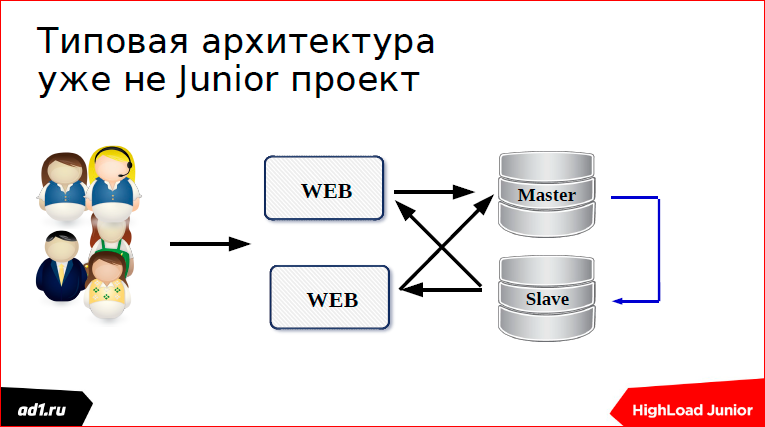
But here we got errors in MySQL:

Well, there may be errors in simpler configurations, as I have shown figuratively here.
And at this moment we begin to think about our architecture.

We examine our architecture “under the microscope” and single out two things:

First, some critical elements of our logic that need to be done; and the second - some slow and unnecessary things that can be postponed until later. And we are trying to separate this architecture:

We divided it into two parts.
We try to put one part on one server, and another - on another. I call this pattern a "cunning student."

He himself once “suffered” this: he told his parents that I had already done my lessons and ran for a walk, and the next day I read these lessons before classes and told the teachers in two minutes.
There is a more scientific name for this pattern:

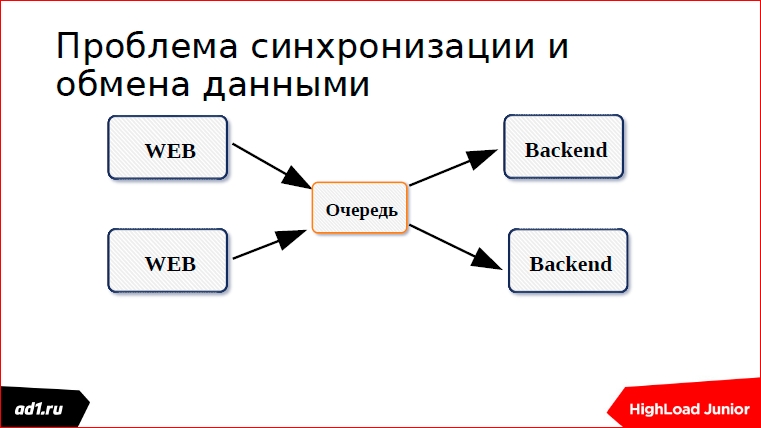
And in the end, we come to such an architecture where there is a web server and a backend server:

We need to somehow connect them together. When these are two servers, this is made easier. When there are several, it is a little more complicated. And we wonder how to connect them? And one of the solutions for communication between these servers is the queue.
What is the queue? A queue is a list.

There is a longer and tedious one, but this is just a list where we write the elements, and then read them and cross them out, execute them. The list goes on, the elements decrease, the queue is so regulated.
We turn to the second part - where and how is it used? Once I worked in such a project:

This is an analog of Yandex.Market. In this project, a lot of different services are spinning. And these services somehow had to be synchronized. They synchronized through the database.
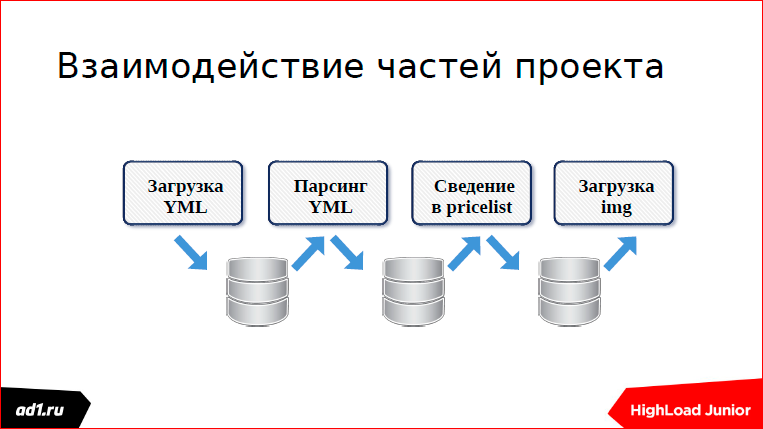
How is the queue based on the database?

There is a certain counter - in MySQL it is auto-increment, in Postgress it is implemented through sikens; there is some data.
We write data:

We read data:

We delete from the queue, but for complete happiness we need locks.

Is this good or bad?
It is slow. My given pattern for this does not exist, but in some cases many people do a queue through a database.

First, you can store history through a database. Then the deleted field is added, it can be both flag and write timestamp. My colleagues, through the turn, make communication that goes through the affiliate network, they record banners - how many clicks there were, then their analytics in Vertika finds clusters, which user groups respond to which banners more.
We use MongoDb for this.

In principle, everything is the same, only some collection is used. We write to this collection, read from this collection. With deletion - we read the item, it automatically deleted.

It is also slow, but still faster than DB. For our needs, we use this in statistics, this is normal.
Further, I worked on such a project, it was a social toy - a “one-armed bandit”:

Everyone knows, you press a button, we have drums spinning, coincidences fall out. The toy was implemented in PHP, but I was asked to refactor it, because our database could not cope.

I used Tarantool for this. Tarantool in a nutshell is a key value repository, it is now closer to document-oriented databases. I had an operational cache implemented on my Tarantool, it only helped a little. We decided to organize all this through the queue. Everything worked perfectly, but once it all fell for us. The backend server has fallen. And in Tarantool, queues began to accumulate, user data was accumulating, and the memory was full, because it is a Memory Only storage.

The memory is full, everything has fallen, user data has been lost for half a day. Users are a little unhappy, somewhere they played, lost, won. Whoever loses is good to him who won - worse. What conclusion? It is necessary to do monitoring.
What is there to monitor? The length of the queue. If we see that it exceeds the average length by a factor of 5 or 10, 20 times, then we must send an SMS - we have such a service made on Telegram. Telegram is free, SMS is still worth the money.
What else does Tarantool give us? Tarantool is a good solution, there is sharding out of the box, replication out of the box.

Tarantool also has a great Queue package.

What I implemented was 4-5 years ago, then there was no such package. Now Tarantool has a very good API, if anyone uses Python, they have an API that is generally tailored to the queue. I myself have been in PHP since 2002, 15 years already. I developed the module for Tarantool in PHP, so PHP is a little closer to me.
There are two operations: writing to the queue and reading from the queue. I want to pay attention to this number (0.1 in blue on the slide) - this is our timeout. And, in general, when approaching the writing of backend scripts that parse the queue, there are two approaches: synchronous and asynchronous.

What is a synchronous approach? This is when we read from the queue and, if there is data, then we process it, if there is no data, then we get into the lock and wait until the data arrives. The data came, we went to read further.

Asynchronous approach, as it is clear, when there is no data, we went on - either read from another queue, or do some other operations. If necessary, wait. And again we go to the beginning of the cycle. Everyone understands, everything is very simple.

What kind of buns give us a Queue package? There are queues with priorities, which I have not seen anywhere else among other queue servers. There you can still set life for the queue element - sometimes it is very useful. Delivery confirmation - and that's it. I spoke about synchronism and asynchrony.
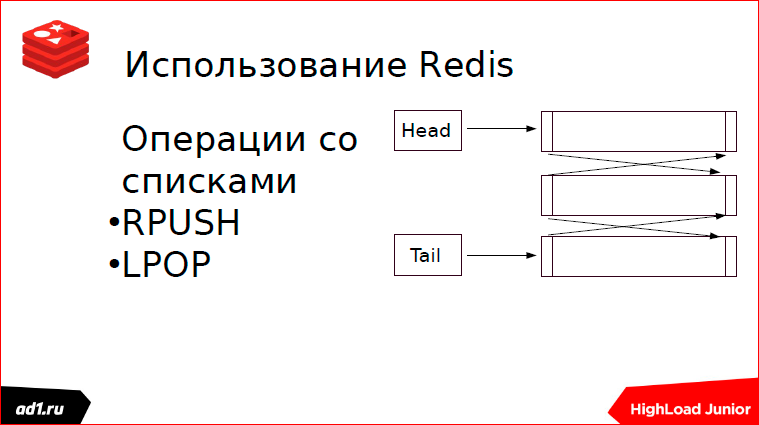
Redis This is our zoo, where there are many different data structures. The queue is implemented on lists. What are good listings? They are good in that the access time to the first element of the list or to the last occurs in a constant time. How is the queue implemented? We write from the beginning of the list, and read from the end of the list. You can do the opposite, it does not matter.

I worked in such a toy. This toy was written on VKontakte. The classic implementation was, the toy worked quickly, the flash drive communicated with the web server.

Everything was perfect, but once we were told from above: “Let's use the statistics, our partners want to know how many units we bought, what the most purchased units, how many we have left, and what level of users, etc.” And they offered us not to reinvent the wheel and use external statistics scripts. And everything was wonderful.
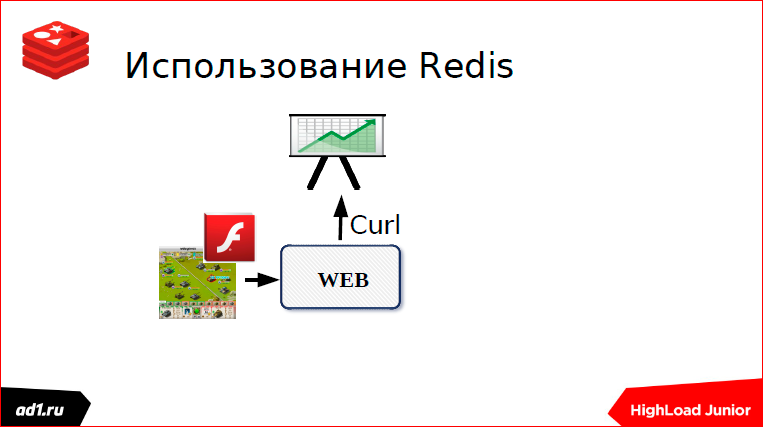
Only my script worked out 50 ms, and when I turned to the external script, there was some kind of America, it was 250 ms minimum, or even more than 2 seconds ping went there. Accordingly, the whole toy crashed.
We used this scheme:

And everything was fine with us, everything worked quickly. But one day our admin went on vacation. The admin went on vacation, everything was fine the first week, and a week later we learned that Redis was flowing. Redis is flowing, there is no admin, we come, we look at the console in the morning, we look at how much memory is left, how much is left before the swap, we sighed: “Oh, how good it has gone today. A lot of users came to us on Friday, especially after lunch, there was not enough memory.

The conclusions are the same as with Tarantool. Another project, the mistakes are the same. Memory needs to be monitored. The queue length needs to be monitored. Everyone talks a lot about monitoring, I won’t repeat myself.

In Redis, you can also perform both blocking and non-blocking read operations; Count operation is needed just for monitoring.
Somehow, I worked remotely in a project for downloading videos from popular video hosting sites:

What is the problem of this project? The fact is that if we upload a video, we convert it, if the video is a little longer, the web client just falls off. We used this scheme:

Everything is fine with us. Downloaded the file. But the queue works for us only in one direction, and we must inform our web script - the file has already been uploaded.
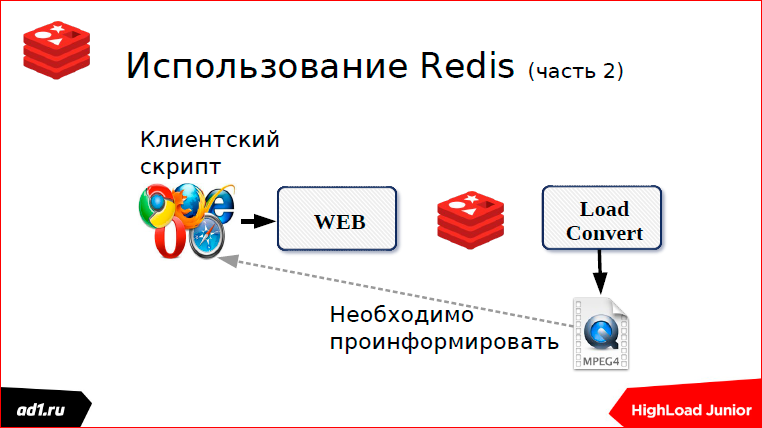
How it's done? This is done in two ways.
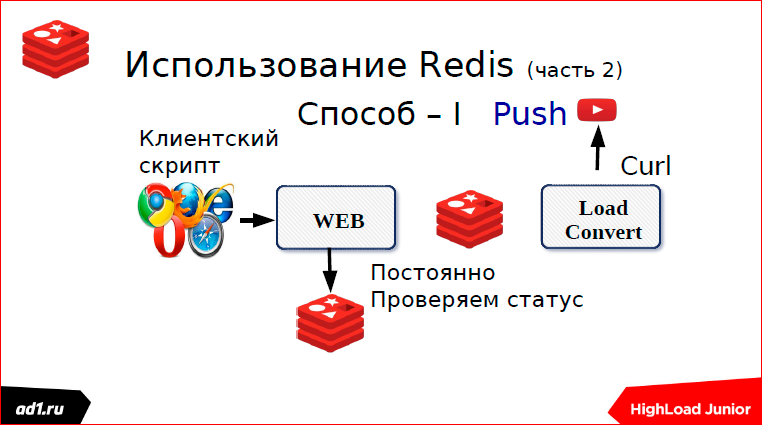
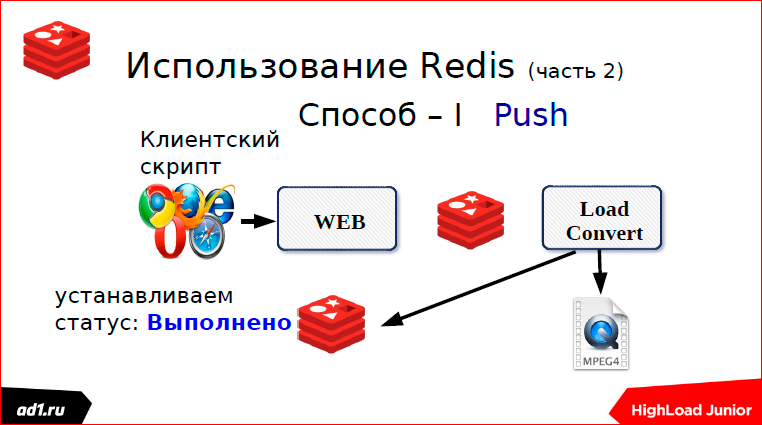

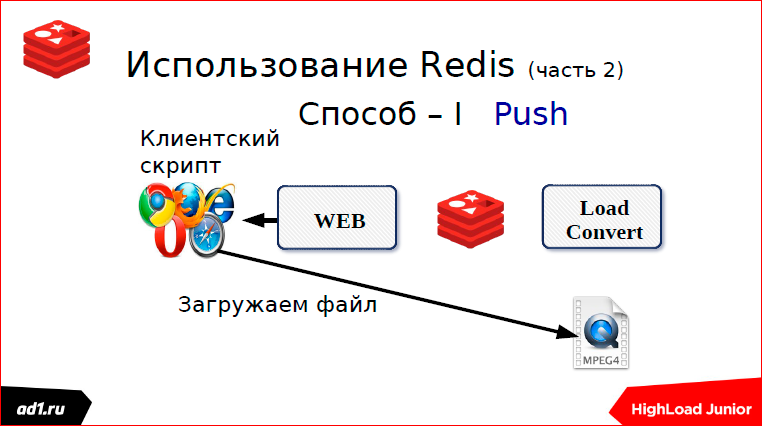
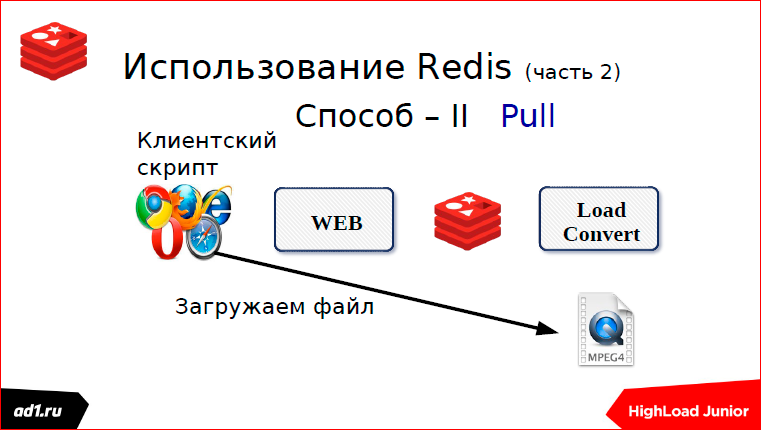
The first is that we check the status after a certain timeout. What could be a status? This is keyvalue storage - it’s better to take the same Redis. Key can serve some MD5 hash from our URL. And after we converted, we write the status in keyvalue. The status can be: “completed”, “converted”, “not found” or something else. After a second, after some timeut, the script will request a status, see what is completed or not completed, show everything to the client. All clear. This is the first way we used pooling.
The second is web sockets.
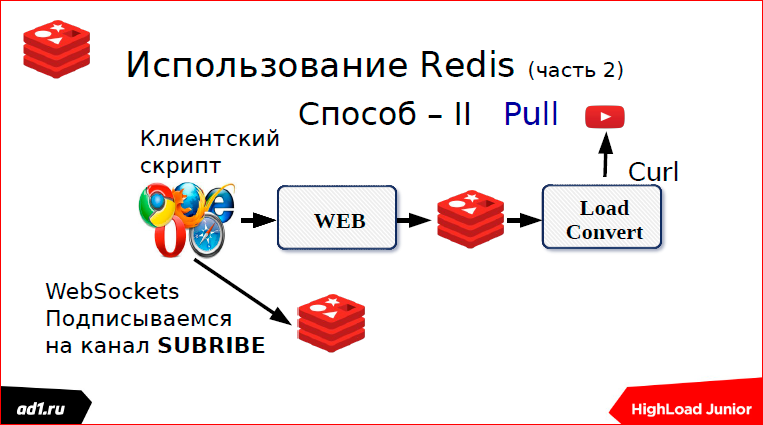

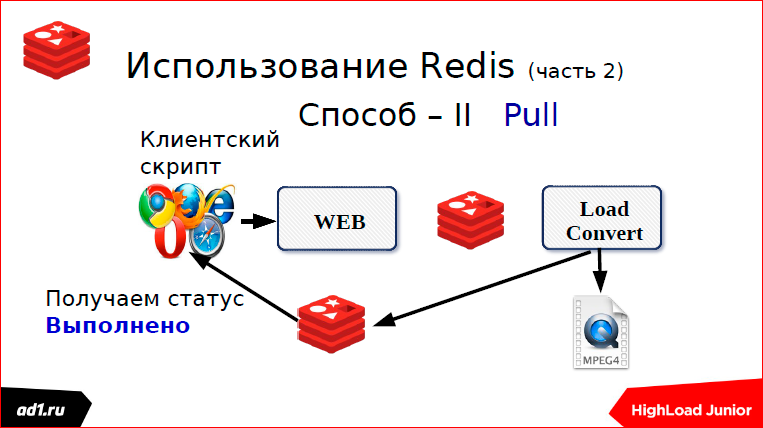
We upload the file - this is the second way. This is a subscription. Here, just used web sockets.
How it's done? As soon as we started the download, we immediately subscribe to the channel in Redis. If it was possible, for example, to use memcaсhed or something else, if we did not use Redis, then here it is tied to Redis. Subscribe to some channel, channel name. Roughly speaking, the same MD5 hash from the URL.
As soon as we have downloaded the file, we take and push the channel that we have the status “completed” or the status “not found”. And immediately, instantly with us, Push gives the status to the web script. After that, upload the file if it is found.

Not quite directly, approximately such a scheme.

How it's done? There is a certain source of data - the volcano temperature, the number of stars visible through telescopes sent by NASA, the number of transactions for specific stocks ... We accept this data, and our background script, which received this data, pushes them into a certain channel. Our web script through a web socket, usually JS nodes are used, subscribes to a specific channel, as soon as the data is received there, it transmits this data to the client script through the web socket, and it is displayed there.

There is such a solution - MamecachedQ. This is a rather old solution, I would say one of the first. It was spawned using Mamecached and BerkeleyDb, it is an embedded, one of the earliest, keyvalue repository.
What is remarkable for this decision? The fact that the Mamecached protocol is used.

What is the big minus - here we will not monitor the length of the queue. What I said - monitoring is needed, but this monitoring is not here.
Speaking about the queues, we can not say about the Zerro MQ.

Zerro MQ is a good and quick solution, but it is not a queue broker, this must be understood. This is just an API, i.e. we connect one point with another point. Or one point with many points. But there are no queues here, if one of the points disappears, then some data will be lost. Of course, I can write the same broker on the same Zerro MQ and implement it ...

Apache Kafka. Somehow I tried to use this solution. This is a solution from the hadoop stack. It is, in principle, a good, high-performance solution, but it is needed where there is a large flow of data and you need to process it. And so, I would use easier solutions.

It needs to be configured for a very long time, synchronized through Zookepek, etc.
Protocols What are protocols?

I showed you a bunch of all sorts of solutions. The IT community thought and said, “Why are we all inventing bicycles, let's standardize the whole thing.” And came up with the protocols. One of the earliest protocols is STOMP.

His description covers everything that can be done with queues.
The second protocol, MQTT, is the Message Queue Telemetry Transport protocol.

It is binary, unlike STOMP, covers, in principle, all the same functionality as STOMP, but more quickly due to the fact that it is binary.
Here are the most prominent representatives of the queue broker who work with the protocols:

ActiveMQ uses all three protocols, even four (there is one more). RabbitMQ uses three protocols; Qpid uses Q and P.
Now briefly about AMQP - Advanced Message Queuing Protocol.

If you talk about him for a long time, you can talk about his features for an hour and a half, no less. I briefly. We will present the broker as an ideal mail service. Exchange - this will be the sender's mailbox where the message arrives.

This Exchange has type properties.

Here it is written in PHP how to declare it. By the way, I also developed this driver.
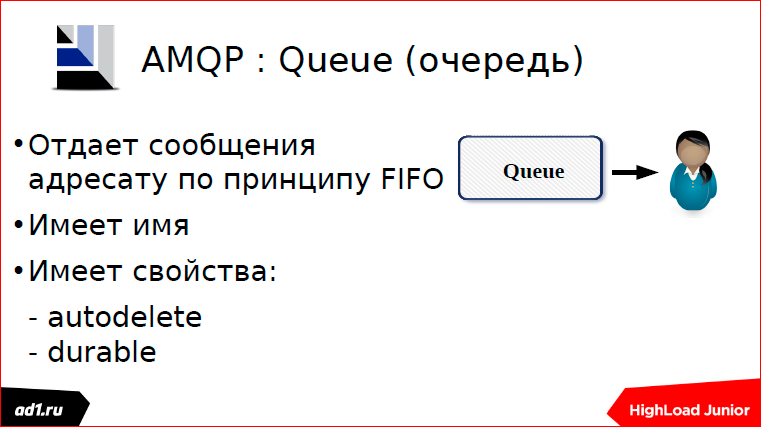
Once there is a sender box, we should have a receiver box. The recipient's box has such a feature that we can take only one letter per call. The recipient's box also has a name, a property. Something like this should be declared:

Between the mailbox of the sender and the mailbox of the recipient you need to lay a route along which the postmen will run and carry our letters.

This route is determined by the routing key.

When we declare a connection, we must specify a routing key. This is one way to declare a connection.
It looks something like how messages are sent:

What are our typical mistakes?

Typical mistakes are that people often forget to define a connection. Now the third Rabbit is more or less decent, it has a web interface, you can see everything through the web interface: what it says, what queues, what type they have, what kind of exchange they have, what types they have.
The second typical mistake. When we declare a queue or exchange, they have autodelete by default - the session has ended, the queue has been killed. Therefore, it must be re-announced each time. In principle, this is undesirable to do, but it is better to make a permanent queue and still assign durable. Durable is such a sign that if we have a durable queue, then after a reboot of RabbitMQ this queue will live with us.

What about RabbitMQ? It is not very pleasant to administer, but it can be expanded if we know Erlang. He is very demanding from memory. RabbitMQ works through an Erlang embedded solution, but it eats a lot of memory. There are some plugins that work with other repositories, but I honestly did not work with them.

Here in such a magazine, "System Administrator" I wrote an article "Rabbit in the sandbox" - there, in principle, the same thing that I told you here.

And in this article, I painted more interesting patterns such as how you can use RabbitMQ, what queue redirection can be done there, for example, how to make sure that if the queue is not read, then this data is written to another queue, to a spare one, which can then read another script. If possible, then read.

I told about such a project at the very beginning. If I did this project today, I would use microservices.
And microservices require synchronization as an interaction. We use a tool such as Apache Zookeeper for synchronization.
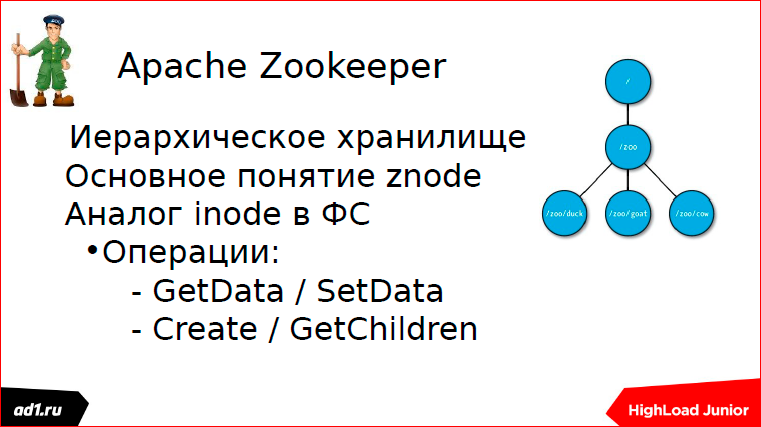
The Apache Zookeeper philosophy is based on znode. Znode, by analogy with an element of the file system, has a certain path. And we have an operation of creating a node, creating children of a node, getting children, getting data, and writing something into the data.
Znode comes in two types: simple and ephemeral.

Ephemeral - these are znode, which, if our user session has died, then znode is destroyed, autodelete.
Sequences are auto-incrementing znode, i.e. these are znode, which have a certain name and a numerical prefix auto-increment.
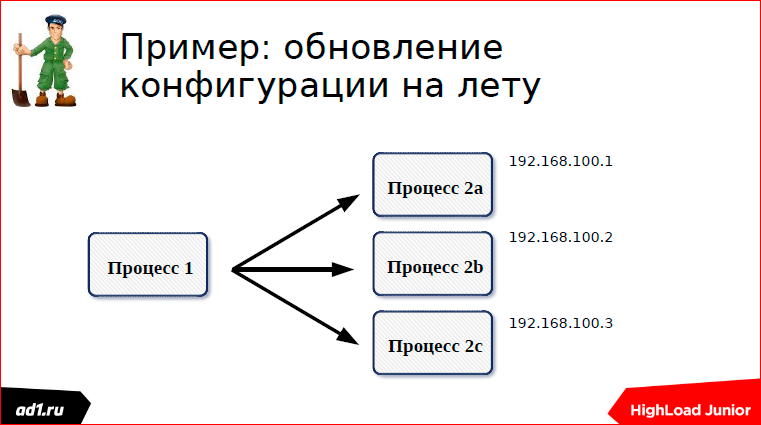
Using the configuration example on the fly I’ll tell you how approximately this all works. We have two groups of processes - process group a and process group b. Processes 1 connect to processes 2 and somehow interact. Processes 2, when launched, write their configuration to Zookeeper.
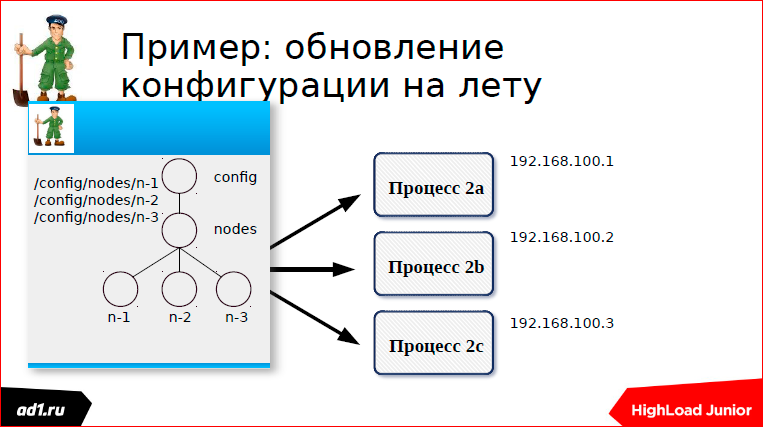
Each process creates its own znode - the first process, the second, the third.
And so we stopped one of the processes or, for example, started. Here, on an example of stopping processes,

I have shown: Our process is stopped, the connection is broken, the znode is deleted, an event is sent that we listened to this znode, that one znode was missing in it.
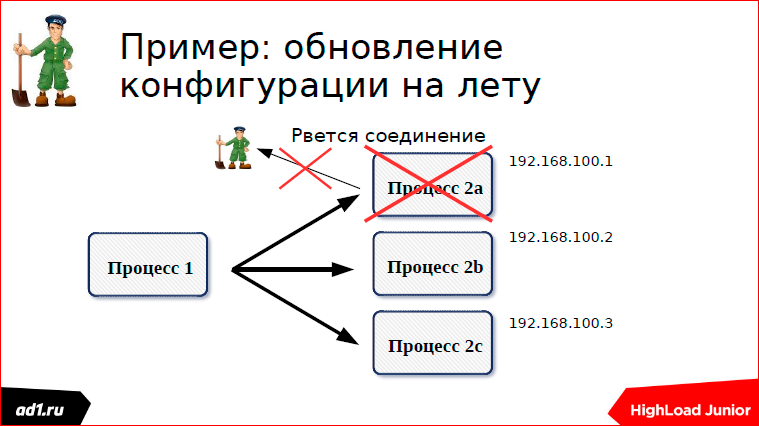
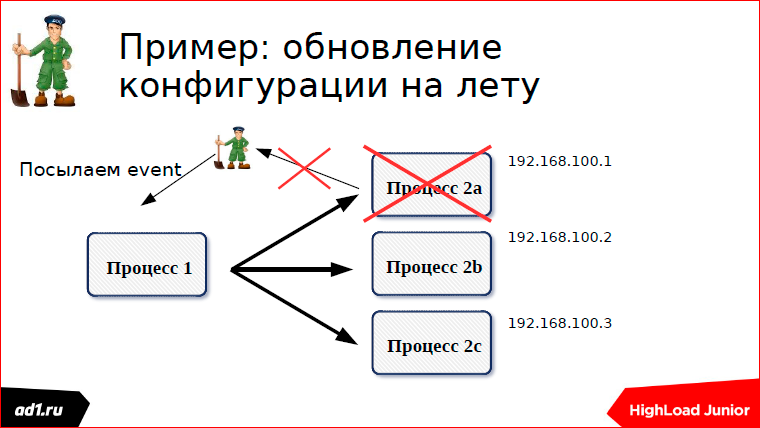

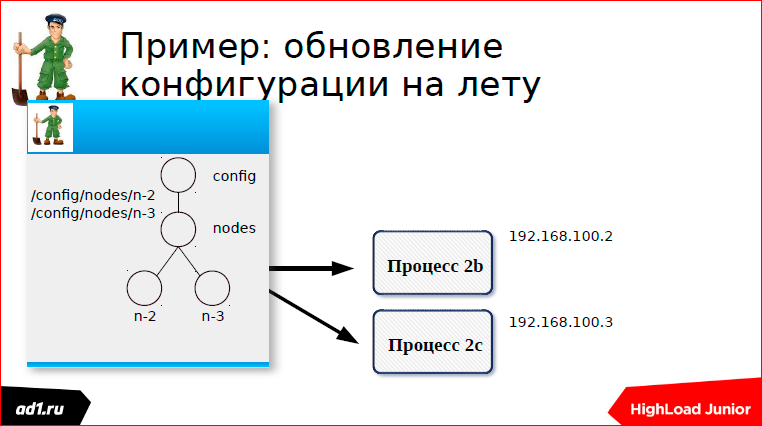
Event is sent, we recount the configuration. Everything works very nicely.

Something like this all synchronizes. There are other examples of how someone synchronized with backups there.

On this final slide, I would like to demonstrate all the capabilities of the queue servers. Where we have question marks is either a moot point or there was simply no data. For example, our database is scaled, right? It is not clear, but, in principle, it scales. But is it possible to scale the queue for them or not? In principle, no. So I have a question here. For ActiveMQ, I simply do not have data. With Redis I can explain - there is an ACL, but it is not entirely correct. You can say it is not. Redis scalable? It scales through the client, I did not see any such elements, boxed solutions.

These are the conclusions:
" Akalend
" akalend@mail.ru
Alexander Kalendarev ( akalend )
Dear colleagues! My report will be about the thing that no HighLoad project can do without - about the queue server, and if I have time, I’ll talk about locks (note the decryptor - I did :).
What will the report be about? I’ll talk about where and how queues are used, why all this is needed, and a little bit about protocols.
Because our conference calls HighLoad Junior, I would like to go from a Junior project. We have a typical Junior project - this is some kind of web page that accesses the database. Maybe this is an electronic store or something else there. And so, users went and went to us, and at some stage we got a mistake (maybe another mistake):
We went online, began to explore how to scale, we decided to get backends.
More users went, and more users, and we got another mistake:
Then we climbed into the logs, looked at how you can scale the SQL server. Found and made replication.
But here we got errors in MySQL:
Well, there may be errors in simpler configurations, as I have shown figuratively here.
And at this moment we begin to think about our architecture.
We examine our architecture “under the microscope” and single out two things:
First, some critical elements of our logic that need to be done; and the second - some slow and unnecessary things that can be postponed until later. And we are trying to separate this architecture:
We divided it into two parts.
We try to put one part on one server, and another - on another. I call this pattern a "cunning student."
He himself once “suffered” this: he told his parents that I had already done my lessons and ran for a walk, and the next day I read these lessons before classes and told the teachers in two minutes.
There is a more scientific name for this pattern:
And in the end, we come to such an architecture where there is a web server and a backend server:
We need to somehow connect them together. When these are two servers, this is made easier. When there are several, it is a little more complicated. And we wonder how to connect them? And one of the solutions for communication between these servers is the queue.
What is the queue? A queue is a list.
There is a longer and tedious one, but this is just a list where we write the elements, and then read them and cross them out, execute them. The list goes on, the elements decrease, the queue is so regulated.
We turn to the second part - where and how is it used? Once I worked in such a project:
This is an analog of Yandex.Market. In this project, a lot of different services are spinning. And these services somehow had to be synchronized. They synchronized through the database.
How is the queue based on the database?
There is a certain counter - in MySQL it is auto-increment, in Postgress it is implemented through sikens; there is some data.
We write data:
We read data:
We delete from the queue, but for complete happiness we need locks.
Is this good or bad?
It is slow. My given pattern for this does not exist, but in some cases many people do a queue through a database.
First, you can store history through a database. Then the deleted field is added, it can be both flag and write timestamp. My colleagues, through the turn, make communication that goes through the affiliate network, they record banners - how many clicks there were, then their analytics in Vertika finds clusters, which user groups respond to which banners more.
We use MongoDb for this.
In principle, everything is the same, only some collection is used. We write to this collection, read from this collection. With deletion - we read the item, it automatically deleted.
It is also slow, but still faster than DB. For our needs, we use this in statistics, this is normal.
Further, I worked on such a project, it was a social toy - a “one-armed bandit”:
Everyone knows, you press a button, we have drums spinning, coincidences fall out. The toy was implemented in PHP, but I was asked to refactor it, because our database could not cope.
I used Tarantool for this. Tarantool in a nutshell is a key value repository, it is now closer to document-oriented databases. I had an operational cache implemented on my Tarantool, it only helped a little. We decided to organize all this through the queue. Everything worked perfectly, but once it all fell for us. The backend server has fallen. And in Tarantool, queues began to accumulate, user data was accumulating, and the memory was full, because it is a Memory Only storage.
The memory is full, everything has fallen, user data has been lost for half a day. Users are a little unhappy, somewhere they played, lost, won. Whoever loses is good to him who won - worse. What conclusion? It is necessary to do monitoring.
What is there to monitor? The length of the queue. If we see that it exceeds the average length by a factor of 5 or 10, 20 times, then we must send an SMS - we have such a service made on Telegram. Telegram is free, SMS is still worth the money.
What else does Tarantool give us? Tarantool is a good solution, there is sharding out of the box, replication out of the box.
Tarantool also has a great Queue package.
What I implemented was 4-5 years ago, then there was no such package. Now Tarantool has a very good API, if anyone uses Python, they have an API that is generally tailored to the queue. I myself have been in PHP since 2002, 15 years already. I developed the module for Tarantool in PHP, so PHP is a little closer to me.
There are two operations: writing to the queue and reading from the queue. I want to pay attention to this number (0.1 in blue on the slide) - this is our timeout. And, in general, when approaching the writing of backend scripts that parse the queue, there are two approaches: synchronous and asynchronous.
What is a synchronous approach? This is when we read from the queue and, if there is data, then we process it, if there is no data, then we get into the lock and wait until the data arrives. The data came, we went to read further.
Asynchronous approach, as it is clear, when there is no data, we went on - either read from another queue, or do some other operations. If necessary, wait. And again we go to the beginning of the cycle. Everyone understands, everything is very simple.
What kind of buns give us a Queue package? There are queues with priorities, which I have not seen anywhere else among other queue servers. There you can still set life for the queue element - sometimes it is very useful. Delivery confirmation - and that's it. I spoke about synchronism and asynchrony.
Redis This is our zoo, where there are many different data structures. The queue is implemented on lists. What are good listings? They are good in that the access time to the first element of the list or to the last occurs in a constant time. How is the queue implemented? We write from the beginning of the list, and read from the end of the list. You can do the opposite, it does not matter.
I worked in such a toy. This toy was written on VKontakte. The classic implementation was, the toy worked quickly, the flash drive communicated with the web server.
Everything was perfect, but once we were told from above: “Let's use the statistics, our partners want to know how many units we bought, what the most purchased units, how many we have left, and what level of users, etc.” And they offered us not to reinvent the wheel and use external statistics scripts. And everything was wonderful.
Only my script worked out 50 ms, and when I turned to the external script, there was some kind of America, it was 250 ms minimum, or even more than 2 seconds ping went there. Accordingly, the whole toy crashed.
We used this scheme:
And everything was fine with us, everything worked quickly. But one day our admin went on vacation. The admin went on vacation, everything was fine the first week, and a week later we learned that Redis was flowing. Redis is flowing, there is no admin, we come, we look at the console in the morning, we look at how much memory is left, how much is left before the swap, we sighed: “Oh, how good it has gone today. A lot of users came to us on Friday, especially after lunch, there was not enough memory.
The conclusions are the same as with Tarantool. Another project, the mistakes are the same. Memory needs to be monitored. The queue length needs to be monitored. Everyone talks a lot about monitoring, I won’t repeat myself.
In Redis, you can also perform both blocking and non-blocking read operations; Count operation is needed just for monitoring.
Somehow, I worked remotely in a project for downloading videos from popular video hosting sites:
What is the problem of this project? The fact is that if we upload a video, we convert it, if the video is a little longer, the web client just falls off. We used this scheme:
Everything is fine with us. Downloaded the file. But the queue works for us only in one direction, and we must inform our web script - the file has already been uploaded.
How it's done? This is done in two ways.
The first is that we check the status after a certain timeout. What could be a status? This is keyvalue storage - it’s better to take the same Redis. Key can serve some MD5 hash from our URL. And after we converted, we write the status in keyvalue. The status can be: “completed”, “converted”, “not found” or something else. After a second, after some timeut, the script will request a status, see what is completed or not completed, show everything to the client. All clear. This is the first way we used pooling.
The second is web sockets.
We upload the file - this is the second way. This is a subscription. Here, just used web sockets.
How it's done? As soon as we started the download, we immediately subscribe to the channel in Redis. If it was possible, for example, to use memcaсhed or something else, if we did not use Redis, then here it is tied to Redis. Subscribe to some channel, channel name. Roughly speaking, the same MD5 hash from the URL.
As soon as we have downloaded the file, we take and push the channel that we have the status “completed” or the status “not found”. And immediately, instantly with us, Push gives the status to the web script. After that, upload the file if it is found.
Not quite directly, approximately such a scheme.
How it's done? There is a certain source of data - the volcano temperature, the number of stars visible through telescopes sent by NASA, the number of transactions for specific stocks ... We accept this data, and our background script, which received this data, pushes them into a certain channel. Our web script through a web socket, usually JS nodes are used, subscribes to a specific channel, as soon as the data is received there, it transmits this data to the client script through the web socket, and it is displayed there.
There is such a solution - MamecachedQ. This is a rather old solution, I would say one of the first. It was spawned using Mamecached and BerkeleyDb, it is an embedded, one of the earliest, keyvalue repository.
What is remarkable for this decision? The fact that the Mamecached protocol is used.
What is the big minus - here we will not monitor the length of the queue. What I said - monitoring is needed, but this monitoring is not here.
Speaking about the queues, we can not say about the Zerro MQ.
Zerro MQ is a good and quick solution, but it is not a queue broker, this must be understood. This is just an API, i.e. we connect one point with another point. Or one point with many points. But there are no queues here, if one of the points disappears, then some data will be lost. Of course, I can write the same broker on the same Zerro MQ and implement it ...
Apache Kafka. Somehow I tried to use this solution. This is a solution from the hadoop stack. It is, in principle, a good, high-performance solution, but it is needed where there is a large flow of data and you need to process it. And so, I would use easier solutions.
It needs to be configured for a very long time, synchronized through Zookepek, etc.
Protocols What are protocols?
I showed you a bunch of all sorts of solutions. The IT community thought and said, “Why are we all inventing bicycles, let's standardize the whole thing.” And came up with the protocols. One of the earliest protocols is STOMP.
His description covers everything that can be done with queues.
The second protocol, MQTT, is the Message Queue Telemetry Transport protocol.
It is binary, unlike STOMP, covers, in principle, all the same functionality as STOMP, but more quickly due to the fact that it is binary.
Here are the most prominent representatives of the queue broker who work with the protocols:
ActiveMQ uses all three protocols, even four (there is one more). RabbitMQ uses three protocols; Qpid uses Q and P.
Now briefly about AMQP - Advanced Message Queuing Protocol.
If you talk about him for a long time, you can talk about his features for an hour and a half, no less. I briefly. We will present the broker as an ideal mail service. Exchange - this will be the sender's mailbox where the message arrives.
This Exchange has type properties.
Here it is written in PHP how to declare it. By the way, I also developed this driver.
Once there is a sender box, we should have a receiver box. The recipient's box has such a feature that we can take only one letter per call. The recipient's box also has a name, a property. Something like this should be declared:
Between the mailbox of the sender and the mailbox of the recipient you need to lay a route along which the postmen will run and carry our letters.
This route is determined by the routing key.
When we declare a connection, we must specify a routing key. This is one way to declare a connection.
Есть второй подход. Мы можем объявить Exchange и с него сделать Bind на очередь, т.е. это наоборот — мы можем с очереди сделать связь на Exchange или с Exchange на очередь, это без разницы.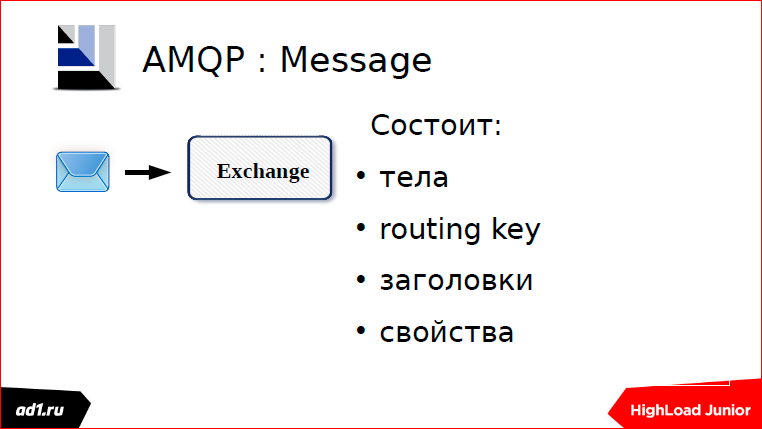
Есть у нас сообщение. В сообщении должен быть обязательно указан routingKey, т.е. это тот ключ, по которому маршруту побежит наш почтальон.
Наши почтальоны могут быть трех типов:
- Первый тип — это слепые почтальоны. Они не могут прочитать ключ, они бегут только по тому маршруту, который мы им проложили. Эти почтальоны бегут, и это
самые быстрые почтальоны. - Почтальоны второго типа могут немного читать, они сверяют буковки, только не знают, как чего… Сверили буковки, что совпадает ключ нашего сообщения и
соответствующей тропинки, по которой бежать, и бегут по той тропинке. Т.е. наш получатель идет чисто по ключу совпадения. - И третий вид почтальонов — это Topic. Мы можем задать маску, маска такая же, как в файловой системе, и по этой маске почтальончики наши относят письма.
It looks something like how messages are sent:
What are our typical mistakes?
Typical mistakes are that people often forget to define a connection. Now the third Rabbit is more or less decent, it has a web interface, you can see everything through the web interface: what it says, what queues, what type they have, what kind of exchange they have, what types they have.
The second typical mistake. When we declare a queue or exchange, they have autodelete by default - the session has ended, the queue has been killed. Therefore, it must be re-announced each time. In principle, this is undesirable to do, but it is better to make a permanent queue and still assign durable. Durable is such a sign that if we have a durable queue, then after a reboot of RabbitMQ this queue will live with us.
What about RabbitMQ? It is not very pleasant to administer, but it can be expanded if we know Erlang. He is very demanding from memory. RabbitMQ works through an Erlang embedded solution, but it eats a lot of memory. There are some plugins that work with other repositories, but I honestly did not work with them.
Here in such a magazine, "System Administrator" I wrote an article "Rabbit in the sandbox" - there, in principle, the same thing that I told you here.
And in this article, I painted more interesting patterns such as how you can use RabbitMQ, what queue redirection can be done there, for example, how to make sure that if the queue is not read, then this data is written to another queue, to a spare one, which can then read another script. If possible, then read.
Locks
I told about such a project at the very beginning. If I did this project today, I would use microservices.
And microservices require synchronization as an interaction. We use a tool such as Apache Zookeeper for synchronization.
The Apache Zookeeper philosophy is based on znode. Znode, by analogy with an element of the file system, has a certain path. And we have an operation of creating a node, creating children of a node, getting children, getting data, and writing something into the data.
Znode comes in two types: simple and ephemeral.
Ephemeral - these are znode, which, if our user session has died, then znode is destroyed, autodelete.
Sequences are auto-incrementing znode, i.e. these are znode, which have a certain name and a numerical prefix auto-increment.
Using the configuration example on the fly I’ll tell you how approximately this all works. We have two groups of processes - process group a and process group b. Processes 1 connect to processes 2 and somehow interact. Processes 2, when launched, write their configuration to Zookeeper.
Each process creates its own znode - the first process, the second, the third.
And so we stopped one of the processes or, for example, started. Here, on an example of stopping processes,
I have shown: Our process is stopped, the connection is broken, the znode is deleted, an event is sent that we listened to this znode, that one znode was missing in it.
Event is sent, we recount the configuration. Everything works very nicely.
Something like this all synchronizes. There are other examples of how someone synchronized with backups there.
On this final slide, I would like to demonstrate all the capabilities of the queue servers. Where we have question marks is either a moot point or there was simply no data. For example, our database is scaled, right? It is not clear, but, in principle, it scales. But is it possible to scale the queue for them or not? In principle, no. So I have a question here. For ActiveMQ, I simply do not have data. With Redis I can explain - there is an ACL, but it is not entirely correct. You can say it is not. Redis scalable? It scales through the client, I did not see any such elements, boxed solutions.
These are the conclusions:
- It is necessary to use each tool as intended. I talked a lot with different developers, RabbitMQ now uses only lazy, but in
most cases the same RabbitMQ can be replaced with Redis. - Speed times reliability. What did I mean by that? The faster the tool works, the less reliable it is. But on the other hand, the
value of this constant can vary - this is my personal observation. - Well, about monitoring here, much has been said by professionals before me.
Contacts
" Akalend
" akalend@mail.ru
Этот доклад — расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем HighLoad++ Junior.
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля "Российские интернет-технологии", в который входит восемь конференций, включая HighLoad++ Junior. Мы, конечно, жадные коммерсы, но сейчас продаём билеты по себестоимости — можно успеть до повышения цен :)