12 billion requests per month for $ 120 in java
When you launch your product, you are completely unaware of what will happen after the launch. You can remain an absolutely useless project, you can get a small trickle of customers or a whole tsunami of users at once, if the leading media write about you. We did not know.
This post is about the architecture of our system, its evolutionary development for almost 3 years and the trade-offs between development speed, productivity, cost and simplicity.
The simplified task looked like this - you need to connect the microcontroller to the mobile application via the Internet. Example - we press the button in the application the LED on the microcontroller lights up. We put out the LED on the microcontroller and the button in the application changes the status accordingly.
Since we started the project on kickstarter, before starting the server in production, we already had a rather large base of first users - 5,000 people. Probably many of you have heard about the famous habr effect that many web resources put in the past. Of course, we did not want to repeat this fate. Therefore, this affected the selection of the technical stack and application architecture.
Immediately after the launch, our whole architecture looked like this:

It was 1 Digital Ocean virtual machine for $ 80 per month (4 CPU, 8 GB RAM, 80 GB SSD). Taken with a margin. Since "what if the load goes?". Then we really thought that, let’s start, and thousands of users will rush at us. As it turned out - to attract and lure users is the other task and server load - the last thing worth thinking about. Of the technologies at that time, there was only Java 8 and Netty with our own binary protocol on ssl / tcp sockets (yes, without a database, spring, hibernate, tomcat, websphere and other charms of a bloody enterprise).
All user data was simply stored in memory and periodically dumped into files:
The whole process of raising the server came down to one line:
Peak load immediately after launch was 40 rivers-sec. The real tsunami never happened.
Nevertheless, we worked hard and hard, constantly adding new features, listening to feedback from our users. The user base, although slowly but steadily and constantly growing by 5-10% every month. The load on the server also increased.
The first major feature was reporting. At the moment when we started to implement it, the load on the system was already 1 billion requests per month. And most of the requests were real data, such as temperature sensors. It was obvious that storing every request was very expensive. So we went for tricks. Instead of saving each request, we calculate the average value in memory with minute granularity. That is, if you sent the numbers 10 and 20 within a minute, then the output will get the value 15 for this minute.
First, I succumbed to hype and implemented this approach on apache spark. But when it came to deployment, I realized that the sheepskin is not worth the candle. So of course it was “right” and “enterprise”. But now I had to deploy and monitor 2 systems instead of my cozy monolithic. In addition, an overhead was added for data serialization and transmission. In general, I got rid of spark and just counts the values in the memory and flushes it to disk once a minute. The output looks like this:
A system with a single monolith server worked fine. But there were quite obvious disadvantages:
8 months after the launch, the stream of new features was a little sleepy and I had time to change this situation. The task was simple - to reduce the delay in different regions, to reduce the risk of the fall of the entire system at the same time. Well, do it all quickly, simply, cheaply and with minimal effort. Startup, after all.
The second version turned out like this:
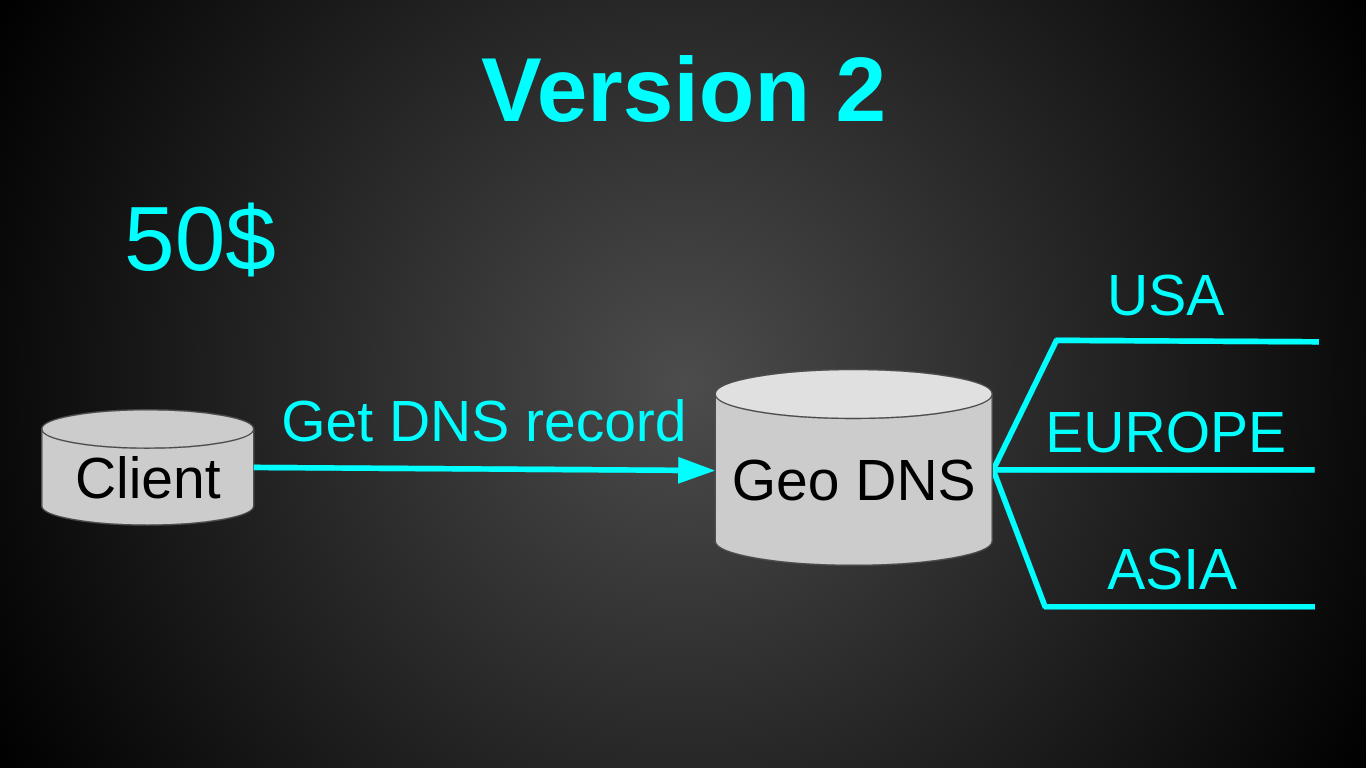
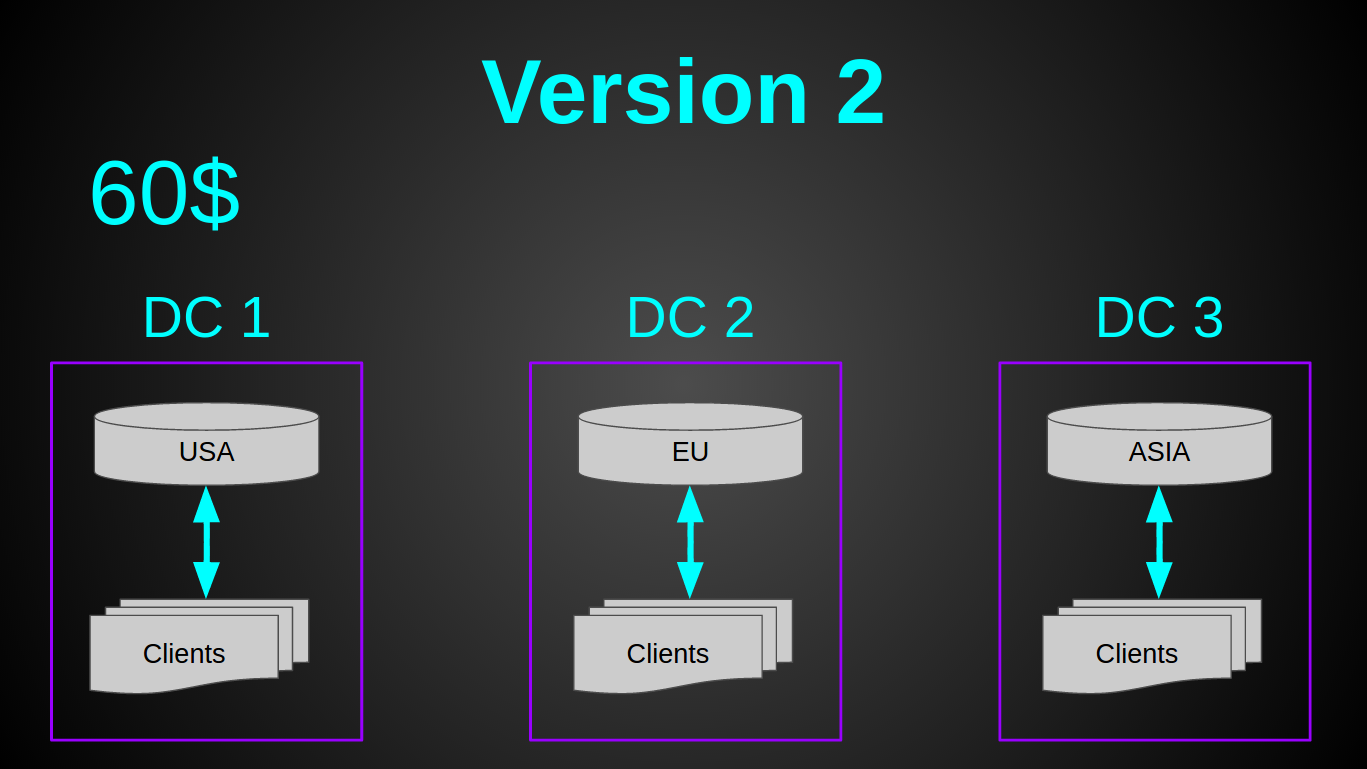
As you probably noticed - I opted for GeoDNS. It was a very quick decision - the entire setup of 30 minutes in Amazon Route 53 to read and configure. Pretty cheap - Amazon's Geo DNS routing costs $ 50 a month (I was looking for cheaper alternatives, but couldn't find one). Pretty simple - since the load balancer was not needed. And it required a minimum of effort - I only had to prepare the code a little (it took less than a day).
Now we had 3 monolithic servers for $ 20 (2 CPU, 2 GB RAM, 40 GB SSD) + $ 50 for Geo DNS. The whole system cost $ 110 per month, while it had 2 cores more for the price of $ 20 cheaper. At the time of transition to the new architecture, the load was 2000 rivers-sec. And the previous virtual machine was only 6% loaded.
All the problems of the monolith above were solved, but a new one appeared - when a person was moved to another zone - he would go to another server and nothing would work for him. This was a deliberate risk and we took it. The motivation is very simple - users do not pay (at that time the system was completely free), so let them put up with it. We also used statistics, according to which - only 30% of Americans at least once in their life left their country, and only 5% regularly move. Therefore, it was suggested that this problem will affect only a small% of our users. The prediction came true. On average, we received about one letter in 2-3 days from a user whose “Projects were gone. What to do? Save! ” Over time, such letters began to be very annoying (despite detailed instructions on how to quickly fix this for the user). Moreover, such an approach would hardly suit the business we were just starting to switch to. It was necessary to do something.
There were many options for solving the problem. I decided that the cheapest way to do this would be to send microcontrollers and applications to one server (to avoid overhead when sending messages from one server to another). In general, the requirements for the new system emerged as follows - different connections of one user must go to one server and a shared state between such servers is needed in order to know where to connect the user.
I heard a lot of good reviews about cassandra, which perfectly suited this task. Therefore, I decided to try it. My plan looked like this:
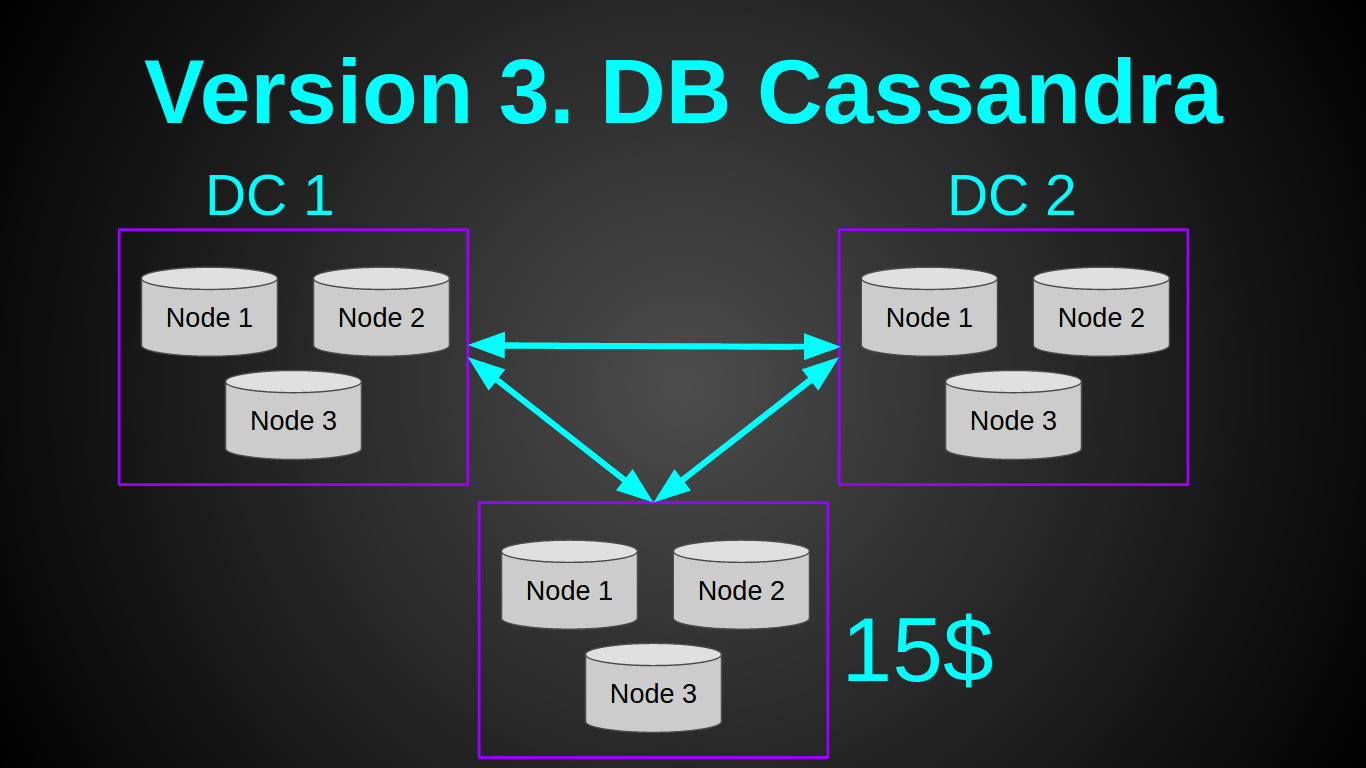
Yes, I am a rogue and a naive Chukchi youth. I thought that I could raise one cassandra node on the cheapest virtual machine for a $ 5 DO - 512 MB RAM, 1 CPU. And I even read the article of the lucky one who raised the cluster to Rasp PI. Unfortunately, I was not able to repeat his feat. Although I removed / trimmed all the buffers, as described in the article. I was able to raise one cassandra node only on a 1GB instance, while the node immediately fell from OOM (OutOfMemory) at a load of 10 rivers-sec. Cassandra behaved more or less stably with 2GB. It was not possible to increase the load of one cassander node to 1000 rivers-sec, again OM. At this stage, I abandoned the casandra, because even if it had shown a worthy performance, the minimum cluster in one data center would cost in 60s. It was expensive for me, considering that our income at that time was $ 0.
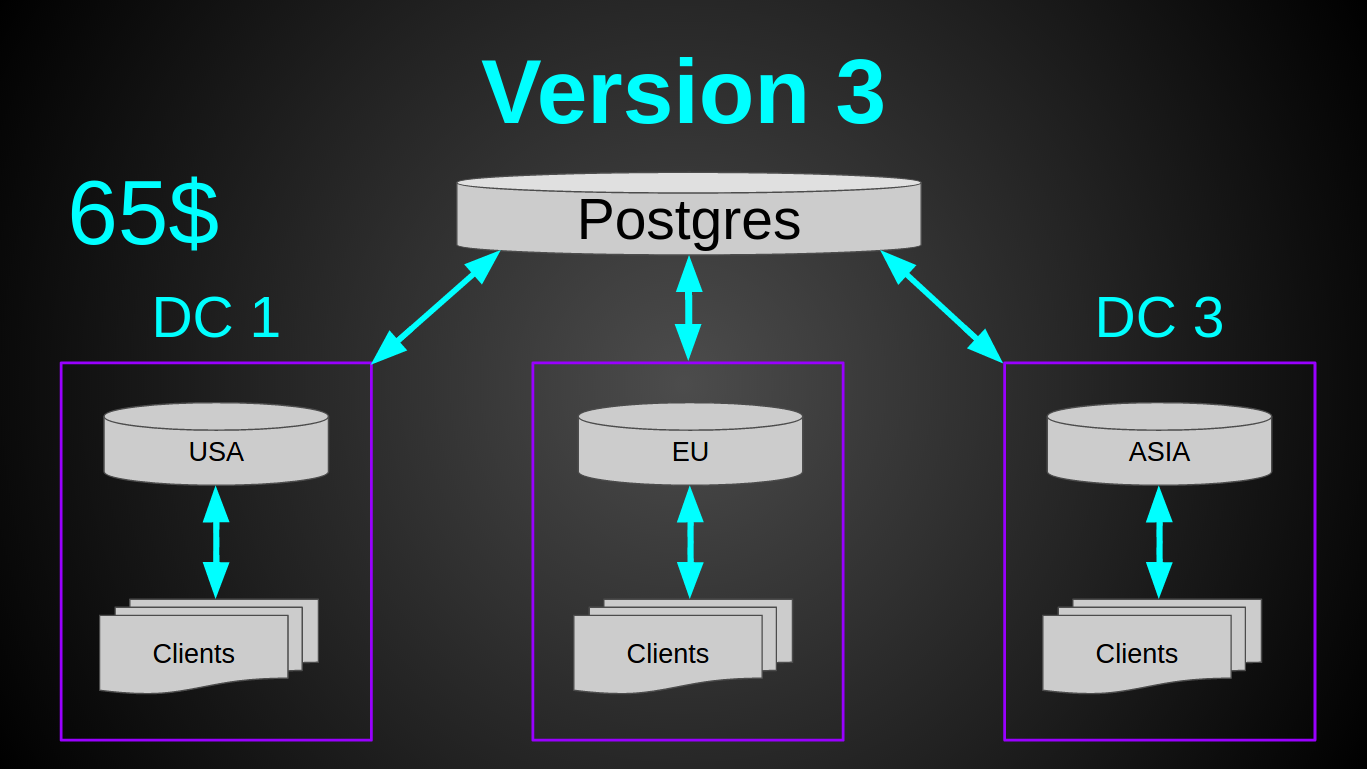
Good old postgres. He had never let me down (okay, almost never, yes, full vacuum?). Postgres ran perfectly on the cheapest virtual machine, absolutely did not eat RAM, inserting 5000 lines with batches took 300ms and loaded the only core with 10%. What you need! I decided not to deploy a database in each of the data centers, but to make one common storage. Since postgres to scale / shard / master-slave is more difficult than the same casandra. And the margin of safety allowed it.
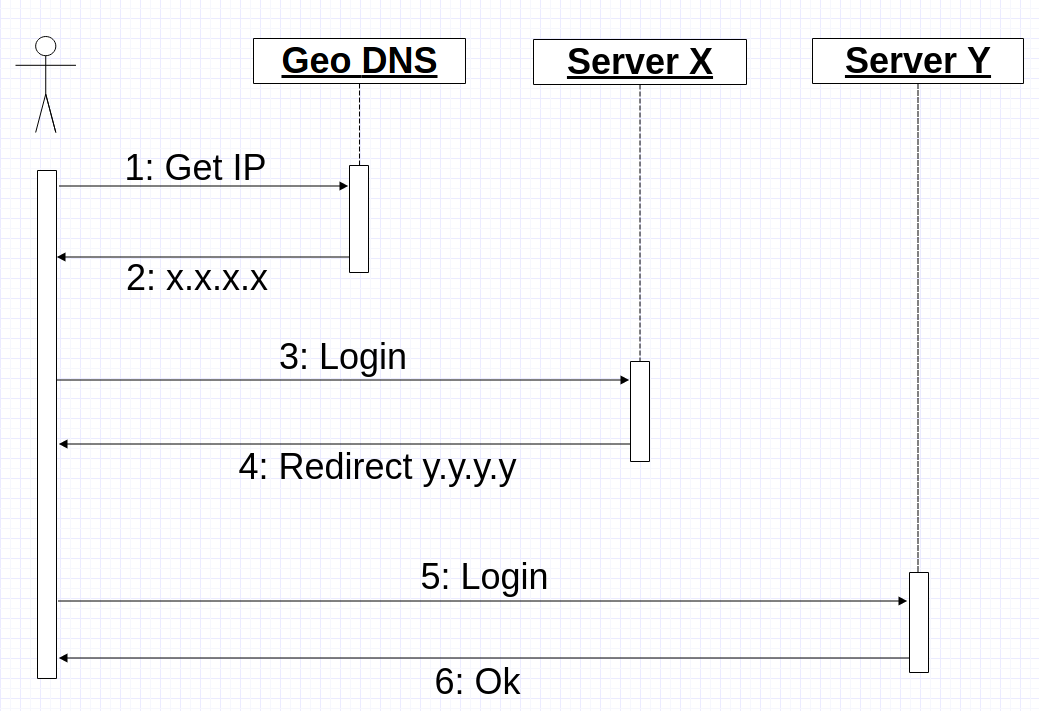
Now another problem had to be solved - to send the client and its microcontrollers to the same server. In essence, make a sticky session for tcp / ssl connections and your binary protocol. Since I did not want to make drastic changes to the existing cluster, I decided to reuse Geo DNS. The idea was this: when a mobile application receives an IP address from Geo DNS, the application opens a connection and sends login over that IP. The server, in turn, either processes the login command and continues to work with the client if it is a “correct” server or returns a redirect command to it indicating the IP where it should connect. In the worst case, the connection process looks like this:
But there was one small nuance - the load. The system at the time of implementation was already processing 4700 rivers-sec. ~ 3k devices were constantly connected to the cluster. From time to time ~ 10k was connected. That is, at the current growth rate in a year it will be 10k rivers-sec. Theoretically, a situation could arise when many devices are connected to the same server at the same time (for example, upon restart, ramp up period) and if, all of a sudden, they all connected “to the wrong” server, then there might be too much load on the database, which can lead to her failure. Therefore, I decided to play it safe and brought out information about user-serverIP to the radish. The final system is as follows.
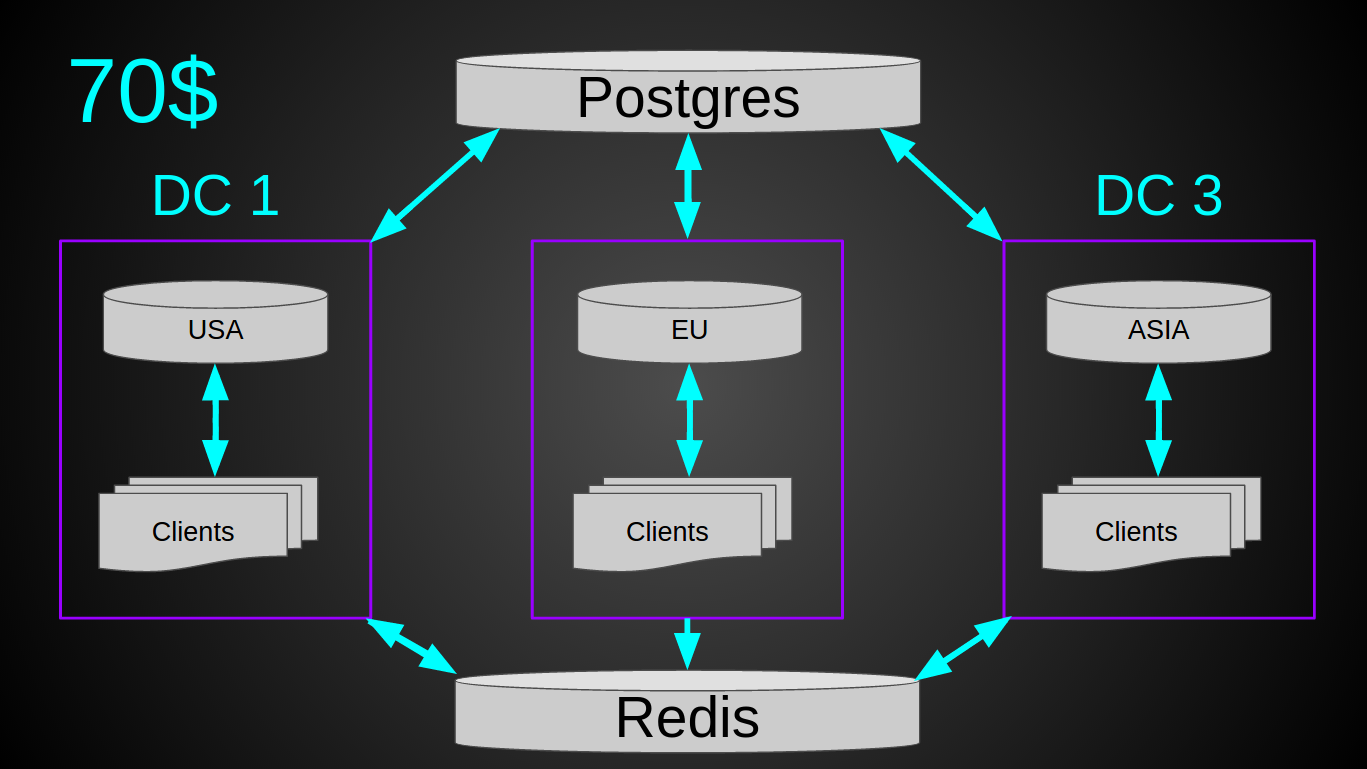
With a current load of 12 billion rivers per month, the entire system is loaded on average by 10%. Network traffic ~ 5 Mbps (in / out, thanks to our simple protocol). That is, in theory, such a cluster for $ 120 can withstand up to 40k rivers-sec. Of the pluses - you do not need a load balancer, a simple deployment, maintenance and monitoring are quite primitive, there is the possibility of vertical growth by 2 orders of magnitude (10x due to the utilization of current iron and 10x due to more powerful virtuals).
The open source project. Sources can be looked here.
That, in fact, is all. I hope you enjoyed the article. Any constructive criticism, advice and questions are welcome.
This post is about the architecture of our system, its evolutionary development for almost 3 years and the trade-offs between development speed, productivity, cost and simplicity.
The simplified task looked like this - you need to connect the microcontroller to the mobile application via the Internet. Example - we press the button in the application the LED on the microcontroller lights up. We put out the LED on the microcontroller and the button in the application changes the status accordingly.
Since we started the project on kickstarter, before starting the server in production, we already had a rather large base of first users - 5,000 people. Probably many of you have heard about the famous habr effect that many web resources put in the past. Of course, we did not want to repeat this fate. Therefore, this affected the selection of the technical stack and application architecture.
Immediately after the launch, our whole architecture looked like this:
It was 1 Digital Ocean virtual machine for $ 80 per month (4 CPU, 8 GB RAM, 80 GB SSD). Taken with a margin. Since "what if the load goes?". Then we really thought that, let’s start, and thousands of users will rush at us. As it turned out - to attract and lure users is the other task and server load - the last thing worth thinking about. Of the technologies at that time, there was only Java 8 and Netty with our own binary protocol on ssl / tcp sockets (yes, without a database, spring, hibernate, tomcat, websphere and other charms of a bloody enterprise).
All user data was simply stored in memory and periodically dumped into files:
try (BufferedWriter writer = Files.newBufferedWriter(fileTo, UTF_8)) {
writer.write(user.toJson());
}The whole process of raising the server came down to one line:
java -jar server.jar &Peak load immediately after launch was 40 rivers-sec. The real tsunami never happened.
Nevertheless, we worked hard and hard, constantly adding new features, listening to feedback from our users. The user base, although slowly but steadily and constantly growing by 5-10% every month. The load on the server also increased.
The first major feature was reporting. At the moment when we started to implement it, the load on the system was already 1 billion requests per month. And most of the requests were real data, such as temperature sensors. It was obvious that storing every request was very expensive. So we went for tricks. Instead of saving each request, we calculate the average value in memory with minute granularity. That is, if you sent the numbers 10 and 20 within a minute, then the output will get the value 15 for this minute.
First, I succumbed to hype and implemented this approach on apache spark. But when it came to deployment, I realized that the sheepskin is not worth the candle. So of course it was “right” and “enterprise”. But now I had to deploy and monitor 2 systems instead of my cozy monolithic. In addition, an overhead was added for data serialization and transmission. In general, I got rid of spark and just counts the values in the memory and flushes it to disk once a minute. The output looks like this:
A system with a single monolith server worked fine. But there were quite obvious disadvantages:
- Since the server was in New York - in remote areas, for example, in Asia, lags were visually visible when using the application interactively. For example, when you changed the brightness level of the lamp using the slider. Nothing critical, and not one of the users complained about it, but we are changing the world, damn it.
- The deploy required a disconnection of all connections and the server was unavailable for ~ 5 seconds at each restart. In the active phase of development, we made about 6 deployments per month. What is funny - for all the time of such restarts here - not a single user has noticed the unavailability of servers. That is, the restarts were so fast (hello spring and tomcat) that users did not notice them at all.
- The failure of one server, the data center laid everything.
8 months after the launch, the stream of new features was a little sleepy and I had time to change this situation. The task was simple - to reduce the delay in different regions, to reduce the risk of the fall of the entire system at the same time. Well, do it all quickly, simply, cheaply and with minimal effort. Startup, after all.
The second version turned out like this:
As you probably noticed - I opted for GeoDNS. It was a very quick decision - the entire setup of 30 minutes in Amazon Route 53 to read and configure. Pretty cheap - Amazon's Geo DNS routing costs $ 50 a month (I was looking for cheaper alternatives, but couldn't find one). Pretty simple - since the load balancer was not needed. And it required a minimum of effort - I only had to prepare the code a little (it took less than a day).
Now we had 3 monolithic servers for $ 20 (2 CPU, 2 GB RAM, 40 GB SSD) + $ 50 for Geo DNS. The whole system cost $ 110 per month, while it had 2 cores more for the price of $ 20 cheaper. At the time of transition to the new architecture, the load was 2000 rivers-sec. And the previous virtual machine was only 6% loaded.
All the problems of the monolith above were solved, but a new one appeared - when a person was moved to another zone - he would go to another server and nothing would work for him. This was a deliberate risk and we took it. The motivation is very simple - users do not pay (at that time the system was completely free), so let them put up with it. We also used statistics, according to which - only 30% of Americans at least once in their life left their country, and only 5% regularly move. Therefore, it was suggested that this problem will affect only a small% of our users. The prediction came true. On average, we received about one letter in 2-3 days from a user whose “Projects were gone. What to do? Save! ” Over time, such letters began to be very annoying (despite detailed instructions on how to quickly fix this for the user). Moreover, such an approach would hardly suit the business we were just starting to switch to. It was necessary to do something.
There were many options for solving the problem. I decided that the cheapest way to do this would be to send microcontrollers and applications to one server (to avoid overhead when sending messages from one server to another). In general, the requirements for the new system emerged as follows - different connections of one user must go to one server and a shared state between such servers is needed in order to know where to connect the user.
I heard a lot of good reviews about cassandra, which perfectly suited this task. Therefore, I decided to try it. My plan looked like this:
Yes, I am a rogue and a naive Chukchi youth. I thought that I could raise one cassandra node on the cheapest virtual machine for a $ 5 DO - 512 MB RAM, 1 CPU. And I even read the article of the lucky one who raised the cluster to Rasp PI. Unfortunately, I was not able to repeat his feat. Although I removed / trimmed all the buffers, as described in the article. I was able to raise one cassandra node only on a 1GB instance, while the node immediately fell from OOM (OutOfMemory) at a load of 10 rivers-sec. Cassandra behaved more or less stably with 2GB. It was not possible to increase the load of one cassander node to 1000 rivers-sec, again OM. At this stage, I abandoned the casandra, because even if it had shown a worthy performance, the minimum cluster in one data center would cost in 60s. It was expensive for me, considering that our income at that time was $ 0.
Good old postgres. He had never let me down (okay, almost never, yes, full vacuum?). Postgres ran perfectly on the cheapest virtual machine, absolutely did not eat RAM, inserting 5000 lines with batches took 300ms and loaded the only core with 10%. What you need! I decided not to deploy a database in each of the data centers, but to make one common storage. Since postgres to scale / shard / master-slave is more difficult than the same casandra. And the margin of safety allowed it.
Now another problem had to be solved - to send the client and its microcontrollers to the same server. In essence, make a sticky session for tcp / ssl connections and your binary protocol. Since I did not want to make drastic changes to the existing cluster, I decided to reuse Geo DNS. The idea was this: when a mobile application receives an IP address from Geo DNS, the application opens a connection and sends login over that IP. The server, in turn, either processes the login command and continues to work with the client if it is a “correct” server or returns a redirect command to it indicating the IP where it should connect. In the worst case, the connection process looks like this:
But there was one small nuance - the load. The system at the time of implementation was already processing 4700 rivers-sec. ~ 3k devices were constantly connected to the cluster. From time to time ~ 10k was connected. That is, at the current growth rate in a year it will be 10k rivers-sec. Theoretically, a situation could arise when many devices are connected to the same server at the same time (for example, upon restart, ramp up period) and if, all of a sudden, they all connected “to the wrong” server, then there might be too much load on the database, which can lead to her failure. Therefore, I decided to play it safe and brought out information about user-serverIP to the radish. The final system is as follows.
With a current load of 12 billion rivers per month, the entire system is loaded on average by 10%. Network traffic ~ 5 Mbps (in / out, thanks to our simple protocol). That is, in theory, such a cluster for $ 120 can withstand up to 40k rivers-sec. Of the pluses - you do not need a load balancer, a simple deployment, maintenance and monitoring are quite primitive, there is the possibility of vertical growth by 2 orders of magnitude (10x due to the utilization of current iron and 10x due to more powerful virtuals).
The open source project. Sources can be looked here.
That, in fact, is all. I hope you enjoyed the article. Any constructive criticism, advice and questions are welcome.