How we launched Habr for humanities
“In the next two years, one should not try to pretend to be something special, but just be smart enough to compose what humanity has already created” (c) bobuk
A year ago, at an internal hackathon, our Rostov guys crossed a visual text editor, Muravyov's Typographer and an anti-plagiarism service overnight. It turned out a thing that helped to quickly prepare and send the publication to the blog.
At one time, the thing lived as a side project, then we were given a few resources - well, like an internal startup. The result was a convenient collective media without an editorial staff.

Old man Gutenberg would be pleased.
It allows people to read interesting stories, like a 40-year-old uncle diver raising sunken ships in the Barents Sea, and writers on popular non-technical topics earning a little money from texts.
Let's see what to consider when developing such a service, and what to choose so that without crutches.
By tradition, we divided the post into chapters - each one has tips and direct speech from the project participant with a minimum of external comments.
Why out of 10 editors you should choose Medium (JS)
Thanks to Muravyov for the typographer (Python)
How the anti-plagiarism system works (Pytnon)
How can an author understand what effect texts give
How to support it (about work with system administrators)
The Story of Uncle Diver (on uPages)
But let's start from the beginning. When the side project began to develop into a highly loaded platform, there was an understanding that something needs to be added and rewritten.
0. How did we choose technology
We expect that by the end of the year, 8 thousand authors will use the platform, and the readership will approach 300 thousand.
Ilya devhard , CTO uPages: “When choosing technologies for the project, we proceeded from such considerations: promising and resistance to heavy loads.
The choice fell on a bunch of Node.js + MongoDB. There are no angulars, reacts, reductions on the client. Express.js was chosen as the framework because of its minimalism and the availability of everything you need out of the box or with small additional settings.
We also had ESlint- a utility that helped a lot to bring the code of several developers to a more or less uniform style without much debate in the spirit of "which is better: tabs or spaces". Very useful in the early stages of development.
ESlint has a demo on the site. You can download the project from GitHub.
Docker containers - as a working environment for project applications - to protect themselves from paranoia like “update the library and everything breaks” and, if necessary, quickly get the right library versions or even several completely different assemblies (roughly speaking, stable and bleeding_edge assemblies).
We also had 3 Git repositories (one locally in the office, two in different data centers). And I knew that someday we would start writing a visual editor. ”
1. If you decide to write your own WYSIWYG, we sympathize with you
 Sergey, our developer: “The prototype from the hackathon was made for blogs and sites on uCoz. And of course, the first thing we thought was to take something from there. But, as you know, part of uCoz is written in Perl - and we chose Node.js. So, the editor would have to be connected as a separate service or rewritten.
Sergey, our developer: “The prototype from the hackathon was made for blogs and sites on uCoz. And of course, the first thing we thought was to take something from there. But, as you know, part of uCoz is written in Perl - and we chose Node.js. So, the editor would have to be connected as a separate service or rewritten. After reviewing a dozen more options, they were discarded as well, because:
- Either they were not “see-something-and-get” editors.
- Or out of the box did not look modern, but like Word 2003.
- Either customizing them is like kostylizing.
You will find a list of editors that we do not recommend in the first comment, but we’ll open one right now:
CKEDITOR is not your bro (at least for reason # 2) The
authors on the site will be different people - both professional journalists, and copywriters, and quite newcomers, and those who tried blogging in the harsh 2000s. I wanted to make the editor so that everyone could download the article quickly and without too much fuss.
Having searched again, we realized that in the spring of 2016 the choice was clear - the Medium Editor , an open source editor inspired by the popular blog platform of the same name. At first glance, it has some advantages.
At MEquite complete and understandable documentation, the project is constantly being updated, it is not abandoned. He also had the necessary functions “out of the box” (toolbar and tools for working with text - this is what is on GitHub) and the possibility of customization.

Editing tools only appear when needed. Behind the plus sign on the side is the insertion of photos and videos.
Widgets that were not included in the kit - "video", "pictures" and "separator" - I wrote myself, starting from the design. And their creation did not take much time.
But not without a fly in the ointment. The first surprise was the fact that ME redefined the standard events inside the editor - keyup, paste , etc., replacing them with their own. To take control of the situation, I had to go into the ME code and add an exception.

Having discovered the vulnerability, we wrote to those who use ME in projects, and explained how to close it.
Vulnerability was discovered during the first tests. We realized that in ME there is no protection against dangerous links, such as:
javascript:alert('xss http://www.ru')This can be solved by elementary tracking and breaking sequences of the javascript: type, as we did.
On the one hand, we are doing it rudely - in the case of a dangerous link, we are simply not trying to save the article. But on the other hand, if a person decides to conduct such an experiment, then he is clearly not our user.
2. Herringbone and dash quotes instead of a hyphen
Peter, our developer: “In general, it is worth noting that text processing in a natural language is a non-trivial task, especially with regard to the Russian language. It was obvious - do not delay the development of attempts to do something different, since you can use ready-made tools with the functionality we need.
It was decided to introduce utilities familiar to us from the hackathon. We stuffed them into a separate microservice in the form of a Docker container - a kind of Python-wrapper with its API working through WSGI.

One of the tools was the Printing House Muravyova . In my humble opinion, there is no better tool for typography correction throughout Runet: an impressive summary of the rules, implementations in PHP and Python. And what’s very important is the license.
To the great honor of @emuragev, it is distributed as a public domain (public domain), so we took it and fastened it to our project in a Python implementation. So far they have not changed anything, although there is an opportunity and ideas on how to supplement the rules. ”
3. How to avoid becoming an SEO content farm
In order to prevent graphomaniacs and amateurs from re-posting from cozy blozics, we introduced pre-moderation. The text of publications is checked for uniqueness: both the author and us can perform such a check.

Peter, our developer: “The concept of the platform is in entertaining stories and reviews without strict regulation of topics and formats. But also we give to earn on each text. And it is clear that it must be unique.
In general, to implement online functionality for checking the uniqueness of text, you need Yandex.XML technology and, ideally, a database of text patterns to first run text on it, and only then knock on Y.XML.
But the number of requests from one domain to the Y.XML service is limited and directly depends on the site’s CY. And what kind of TIC can an unreleased web project have? No. And during development, it was constantly required to send requests, parse the answer and do something with the data.
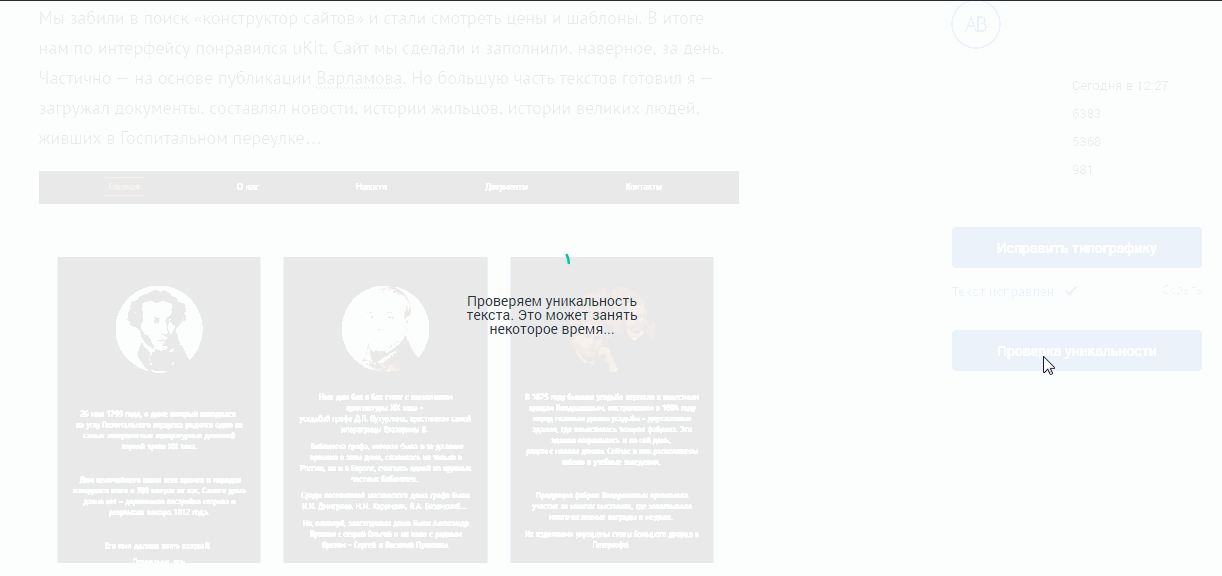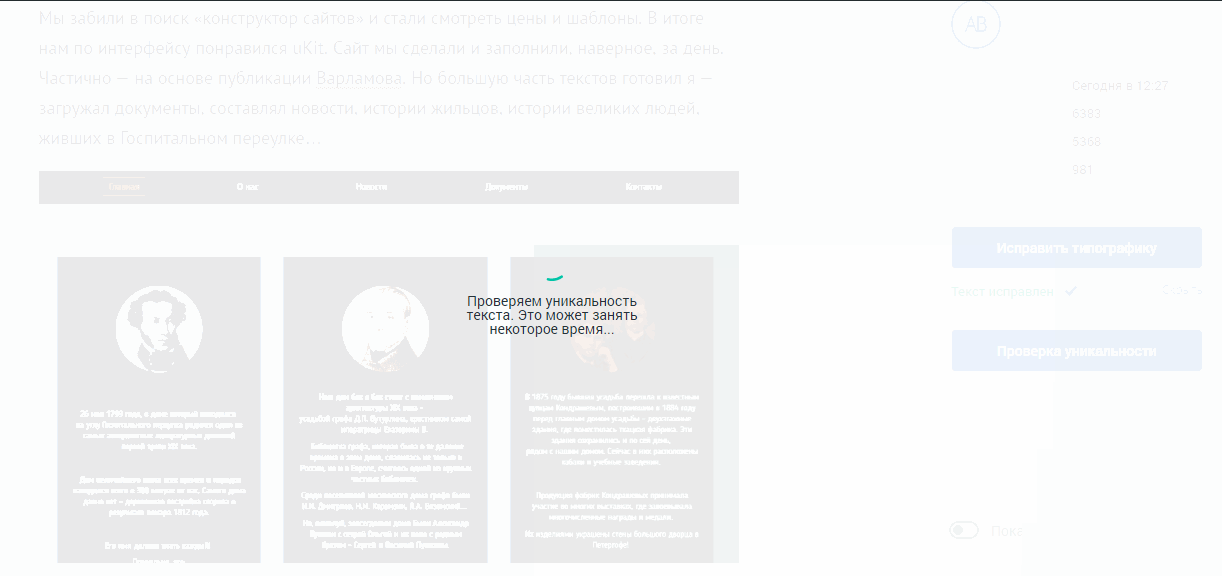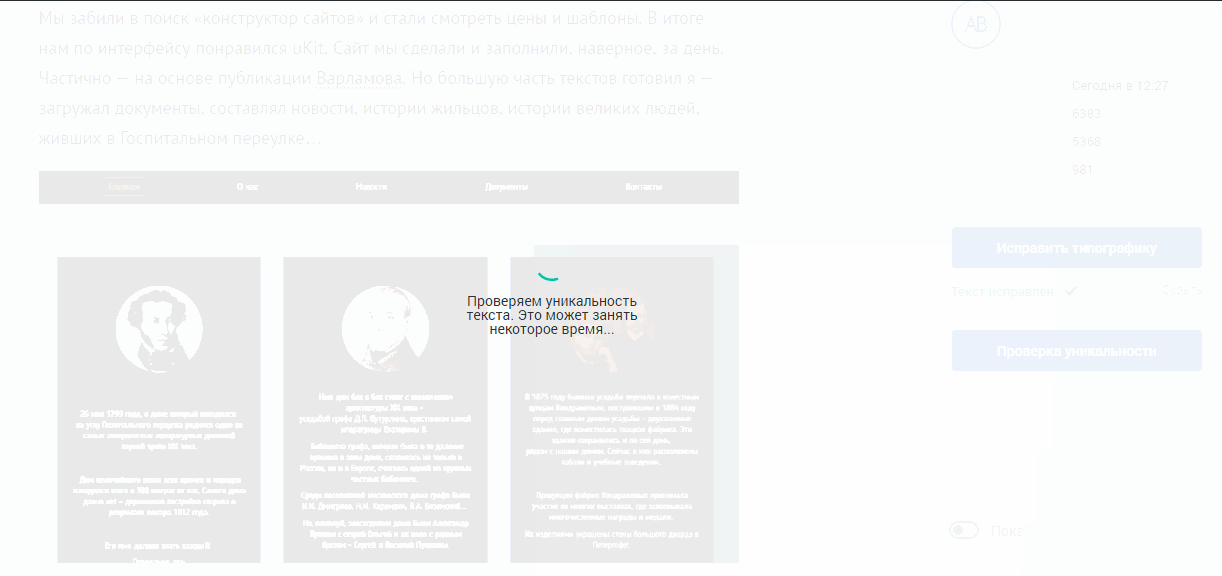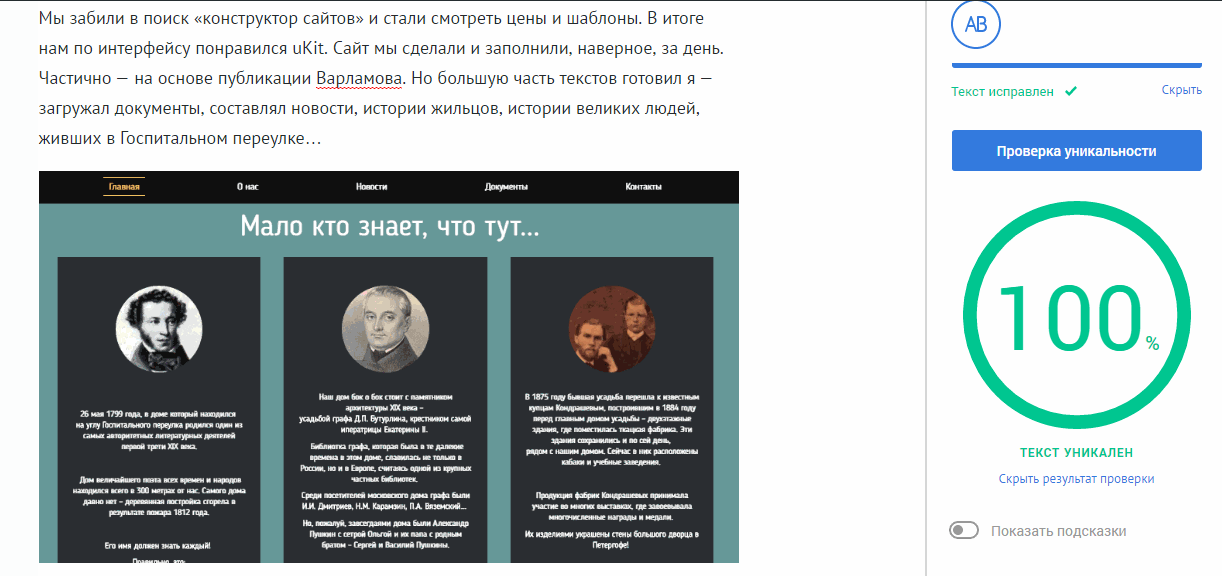
One could, of course, send a request from some domain subject to us, where the site with a large TIC lies. But in the end, we decided not to do this and take the ready-made Content-Watch (CW) API. The system is paid, but for us the guys went to special conditions.
Although the reviews on the network vary, they seem to have a good understanding of the issue and filmed the service with good documentation, a minimalistic API and some of its algorithms in addition to Y.XML.
For us, as for the users of their service, everything works very simply - we send a request for a CW service with the text to be checked, and then we get a json response. The response contains information about the degree of uniqueness of the text (we show a beautiful pie chart on it) and links to pages on the network where this or that piece of text is found - so far only moderators who use the links to check articles before posting on the main page use the topic with links ”.
4. How to let authors analyze articles
To make the authors more interesting, we decided to introduce text analysis and payment tools for everyone. Income is generated as follows: next to the text there are two banners - advertising and recommendation. The banner has a click price (it is determined by the advertising system) - we give 80% of the cost of each click to the author.
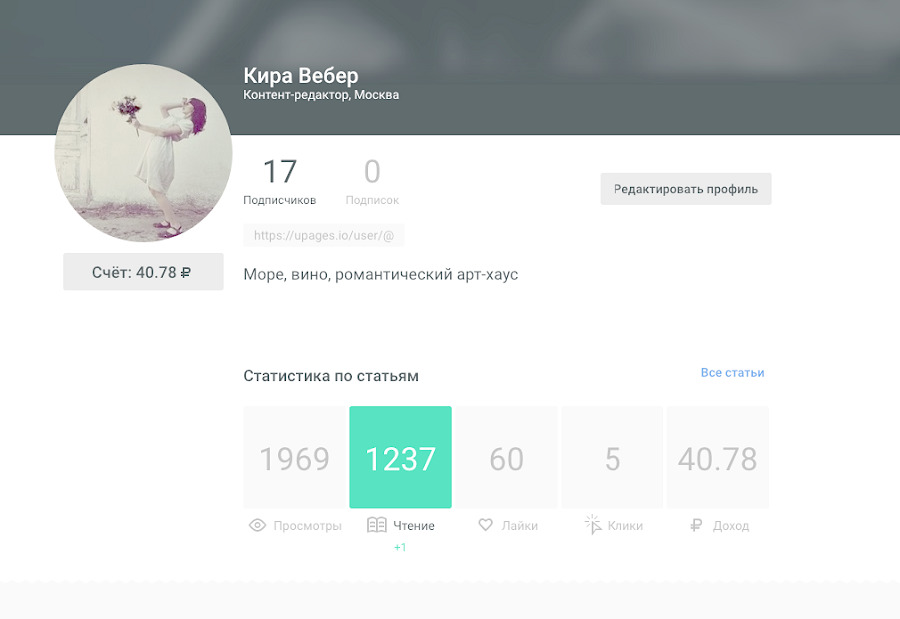
Ilya, CTO uPages: “An interesting task was to show the author how much and when he earned, and at the same time to show the fact - not everyone reads the article, and you need to learn how to work on engaging within the text, and not just on the teaser and headline.
Therefore, we made a statistics module.
It consists of a client part - we draw graphs through Chart.js , giving numbers and lists.
On the server side, we consider something ourselves - the number of likes, reads, bookmarks, for example.
And part of the data - about clicks on banners, from which the author earns - we take through the Google Analytics API and Engageya recommendation service. The second ones do not have a convenient API, but it was possible to agree that once a day they upload reports to us with all the necessary information. This is how we show advertising clicks on the side of the article and the income of the author.
In the case of the Google API, requests come with a certain frequency to meet the limits.
Yes, the Google API is a pain . With so many different products, you have to re-read a huge amount of documentation and try several approaches. At first, we tried to use the AdSense Management API to retrieve Adsense revenue data, but their reports cannot provide information for detailed accounting of revenue sources.
After a long googling and banging my head on the keyboard, salvation came from analytics.
A link is established between your Google Adsense and Analytics accounts, after which AdSense data is available when you request analytics APIs. ”
5. How to maintain it

Ruslan pys , system administrator: “The task subtly hinted that it should be a cloud server. Well, I didn’t really want to do all this monitoring of the temperature of the motherboard, fan speed, monitor the disks - and change them, not forgetting to rewrite the serial numbers.
We took the following requirements for cloud virtual machines:
- Data Center in Moscow (because we have a Russian-speaking audience),
- convenient configuration change,
- two servers from different providers - for fault tolerance and the ability to carry out technical work without downtime.

Another important task was the deployment model of software. Obviously, life on the development server and in battle are two big differences. It is good that the guys immediately chose universal containerization - for which, taking this opportunity, thanks are expressed from the entire system administration.
We chose Saltstack as the container deployment and configuration management system , because we have already successfully used it on other projects.
As a result of putting the service on alert, a natural desire arose to conduct exercises, i.e. firing from Yandex.Tank. In the course of experiments with a different ratio of requests to the processor cores and settings of system and application software, we determined the capacity of one node and the correlation of this capacity with the configuration of virtual hardware and OS settings. Well, they started on November 1st. ”
PS Send your http-requests to our new service !