Your Data is So Big: An Introduction to Spark in Java
Apache Spark is a universal tool for processing big data with which you can write to Hadoop from various DBMSs, stream all kinds of sources in real time, do some complicated processing with the data, and all this is not done with the help of some batches, scripts and SQL queries as well using a functional approach.

There are several myths about Spark:
Why? Look under the cut.
Surely you heard about Spark, and most likely you even know what it is and what it is eaten with. Another thing is that if you are not professionally working with this framework, there are several typical stereotypes in your head that make you risk never getting to know him better.
What is Hadoop? Roughly speaking, this is a distributed file system, a data warehouse with a set of APIs for processing this very data. And, oddly enough, it would be more correct to say that Hadoop needs Spark, and not vice versa!
The fact is that the standard Hadoop toolkit does not allow you to process existing data at high speed, and Spark allows. So the question is, does Spark need Hadoop? Let's take a look at what Spark is:
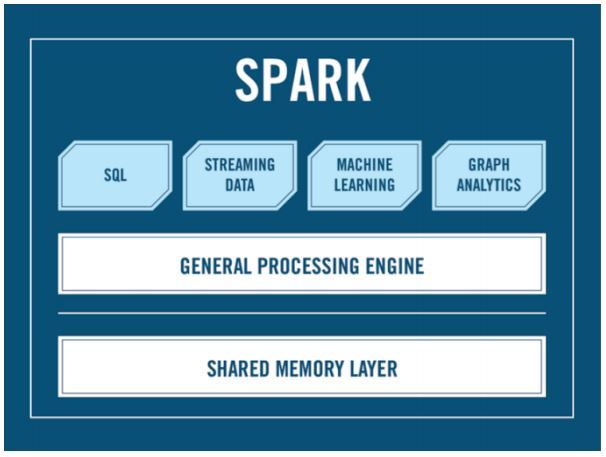
As you can see, there is no Hadoop here: there is an API, there is SQL, there is streaming and much more. Hadoop is optional. And Cluster manager, you ask? Who will run your Spark on the cluster? Alexander Sergeevich? It’s precisely from this question that our myth’s legs are growing: most often YARN is used under Hadoop to distribute Spark’s jobs across the cluster, but there are also alternatives: Apache Mesos, for example, which you can use if for some reason you don’t like Hadoop.
You can work with Spark under both Java and Scala, while the second option is considered by many to be the best for several reasons:
Let's start with the first thesis about Scala coolness and fashion. The counterargument is simple and fits on one line: You may be surprised, but most Java developers ... know Java ! And it costs a lot - the team of seniors, turning to the cliff, turns into StackOverflow-Driven juniors!

The syntax is another story - if you read any Java vs. Holivar Scala, you will come across something like these examples (as you can see, the code simply sums the lengths of the lines):
Scala
Java
A year ago, even in the Spark documentation, the examples looked exactly like that. However, let's look at Java 8 code:
Java 8
Looks pretty good, doesn't it? In any case, you also need to understand that Java is a familiar world to us: Spring, design patterns, concepts, and much more. At Scala, the javista will have to face a completely different world and here it is worth considering whether you or your customer are ready for such a risk.
All examples are taken from the report of Evgeny EvgenyBorisov Borisov about Spark, which was made at JPoint 2016, becoming, by the way, the best report of the conference. Want to continue: RDD, testing, examples, and live coding? Watch the video:
More Spark to the BigData gods
And if, after watching Eugene’s report, you experienced an existential catharsis, realizing that you need to get to know Spark more tightly, you can do it live with Eugene a month later:
on October 12-13, a big two-day training will be held in St. Petersburg “ Welcome to Spark . "
Let's discuss the problems and solutions that inexperienced Spark developers initially encounter. We will deal with the syntax and all sorts of tricks, and most importantly, we will see how you can write Spark in Java using the frameworks, tools and concepts you know, such as Inversion of Control, design patterns, Spring framework, Maven / Gradle, Junit. All of them can help make your Spark application more elegant, readable and familiar.
There will be many tasks, live coding, and in the end you will leave this training with sufficient knowledge to start working independently on Spark-e in the familiar Java world.
It’s not much sense to post a detailed program here; anyone who wants to will find it on the training page .
EVGENY BORISOV
Naya Technologies

Evgeny Borisov has been developing in Java since 2001 and has taken part in a large number of Enterprise projects. Having gone from a simple programmer to an architect and tired of the routine, he became a free artist. Today he writes and conducts courses, seminars and master classes for various audiences: live-courses on J2EE for officers of the Israeli army. Spring - via WebEx for Romanians, Hibernate via GoToMeeting for Canadians, Troubleshooting and Design Patterns for Ukrainians.
PS I take this opportunity to congratulate everyone on the day of the programmer!
There are several myths about Spark:
- Spark'y need Hadoop: not needed!
- Spark needs Scala: not necessary!
Why? Look under the cut.
Surely you heard about Spark, and most likely you even know what it is and what it is eaten with. Another thing is that if you are not professionally working with this framework, there are several typical stereotypes in your head that make you risk never getting to know him better.
Myth 1. Spark does not work without Hadoop
What is Hadoop? Roughly speaking, this is a distributed file system, a data warehouse with a set of APIs for processing this very data. And, oddly enough, it would be more correct to say that Hadoop needs Spark, and not vice versa!
The fact is that the standard Hadoop toolkit does not allow you to process existing data at high speed, and Spark allows. So the question is, does Spark need Hadoop? Let's take a look at what Spark is:
As you can see, there is no Hadoop here: there is an API, there is SQL, there is streaming and much more. Hadoop is optional. And Cluster manager, you ask? Who will run your Spark on the cluster? Alexander Sergeevich? It’s precisely from this question that our myth’s legs are growing: most often YARN is used under Hadoop to distribute Spark’s jobs across the cluster, but there are also alternatives: Apache Mesos, for example, which you can use if for some reason you don’t like Hadoop.
Myth 2. Spark is written in Scala, which means you also need to write in Scala
You can work with Spark under both Java and Scala, while the second option is considered by many to be the best for several reasons:
- Scala is cool!
- More launcher and more convenient syntax.
- The Spark API is sharpened by Scala, and comes out earlier than the Java API;
Let's start with the first thesis about Scala coolness and fashion. The counterargument is simple and fits on one line: You may be surprised, but most Java developers ... know Java ! And it costs a lot - the team of seniors, turning to the cliff, turns into StackOverflow-Driven juniors!
The syntax is another story - if you read any Java vs. Holivar Scala, you will come across something like these examples (as you can see, the code simply sums the lengths of the lines):
Scala
val lines = sc.textFile("data.txt")
val lineLengths = lines.map(_.length)
val totalLength = lineLengths.reduce(_+_)
Java
JavaRDD lines = sc.textFile ("data.txt");
JavaRDD lineLengths = lines.map (new Function() {
@Override
public Integer call (String lines) throws Exception {
return lines.length ();
}
});
Integer totalLength = lineLengths.reduce (new Function2() {
@Override
public Integer call(Integer a, Integer b) throws Exception {
return a + b;
}
});
A year ago, even in the Spark documentation, the examples looked exactly like that. However, let's look at Java 8 code:
Java 8
JavaRDD lines = sc.textFile ("data.txt");
JavaRDD lineLengths = lines.map (String::length);
int totalLength = lineLengths.reduce ((a, b) -> a + b); Looks pretty good, doesn't it? In any case, you also need to understand that Java is a familiar world to us: Spring, design patterns, concepts, and much more. At Scala, the javista will have to face a completely different world and here it is worth considering whether you or your customer are ready for such a risk.
All examples are taken from the report of Evgeny EvgenyBorisov Borisov about Spark, which was made at JPoint 2016, becoming, by the way, the best report of the conference. Want to continue: RDD, testing, examples, and live coding? Watch the video:
More Spark to the BigData gods
And if, after watching Eugene’s report, you experienced an existential catharsis, realizing that you need to get to know Spark more tightly, you can do it live with Eugene a month later:
on October 12-13, a big two-day training will be held in St. Petersburg “ Welcome to Spark . "
Let's discuss the problems and solutions that inexperienced Spark developers initially encounter. We will deal with the syntax and all sorts of tricks, and most importantly, we will see how you can write Spark in Java using the frameworks, tools and concepts you know, such as Inversion of Control, design patterns, Spring framework, Maven / Gradle, Junit. All of them can help make your Spark application more elegant, readable and familiar.
There will be many tasks, live coding, and in the end you will leave this training with sufficient knowledge to start working independently on Spark-e in the familiar Java world.
It’s not much sense to post a detailed program here; anyone who wants to will find it on the training page .
EVGENY BORISOV
Naya Technologies
Evgeny Borisov has been developing in Java since 2001 and has taken part in a large number of Enterprise projects. Having gone from a simple programmer to an architect and tired of the routine, he became a free artist. Today he writes and conducts courses, seminars and master classes for various audiences: live-courses on J2EE for officers of the Israeli army. Spring - via WebEx for Romanians, Hibernate via GoToMeeting for Canadians, Troubleshooting and Design Patterns for Ukrainians.
PS I take this opportunity to congratulate everyone on the day of the programmer!