Making a bot prototype for fighting in Clash Royale
Have you ever found yourself stuck in some kind of simple game, thinking that artificial intelligence could easily cope with it? I've had it, and I decided to try to create such a bot player. Moreover, now there are a lot of tools for computer vision and machine learning, which allow building models without a deep understanding of implementation details. "Mere mortals" can make a prototype, not building neural networks for months from scratch.

Under the cat you will find the process of creating a proof-of-concept bot for the game Clash Royale, in which I used Scala, Python, and the CV library. Using computer vision and machine learning, I tried to create a game bot that interacts as a live player.
My name is Sergey Tolmachyov, I am Lead Scala Developer in the Waves Platform and teach Scala course in the Binary District, and in my spare time I study other technologies, such as AI. And I wanted to reinforce the obtained skills with some practical experience. In contrast to the AI competition, where your bot plays against the bots of other users, you can play Clash Royale against people, which sounds funny. Your bot can learn to beat real players!
The mechanics of the game is quite simple. You and your opponent have three buildings: a fortress and two towers. Players before the game collect decks - 8 available units, which are then used in battle. They have different levels, and they can be pumped, collecting more maps of these units and buying upgrades.
After the start of the game, you can put available units at a safe distance from enemy towers, while spending units of mana, which are slowly restored during the game. Units are sent to enemy buildings and are distracted by enemies encountered along the way. The player can control only the initial position of the units - their further movement and damage can be affected only by the installation of other units.
There are still spells that can be played anywhere in the field, usually they cause damage to units in different ways. Spells can clone, freeze or speed up units in some area.
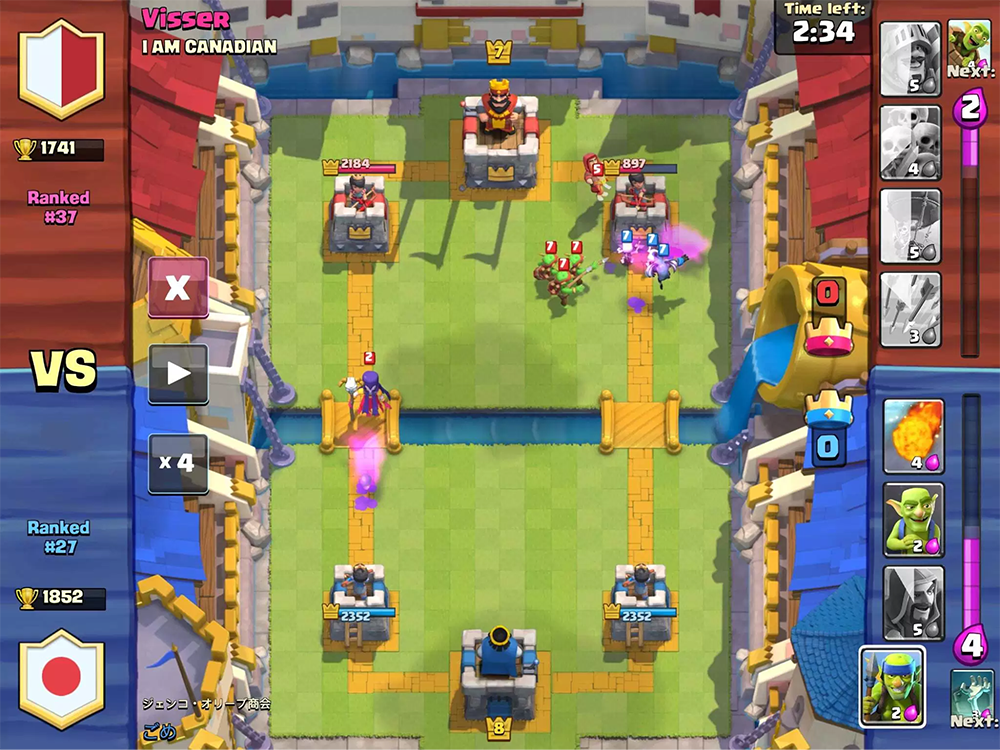
The goal of the game is to destroy enemy buildings. For a complete victory, you need to destroy the fortress or after two minutes of the game destroy more buildings (the rules depend on the game modes, but in general they sound like this).
During the game, you need to take into account the movement of units, the possible mana number and current enemy cards. You also need to consider how the installation of the unit affects the playing field.
Clash Royale is a mobile game, so I decided to run it on Android and interact with it via ADB. This would allow to support work with a simulator or with a real device.
I decided that the bot, like many other AI games, should work using the Perception-Analysis-Action algorithm. The whole environment in the game is displayed on the screen, and it interacts with it using the screen tap. Therefore, the bot must be a program, the input of which is a description of the current state in the game: the location and characteristics of units and buildings, the current possible maps and the amount of mana. At the output, the bot must give an array of coordinates, where it is necessary to tap the unit.
But before creating the bot itself, it was necessary to solve the problem of extracting information about the current state of the game from the screenshot. By and large, this task is devoted to the further content of the article.
To solve this problem, I decided to use Computer Vision. Perhaps this is not the best solution: CV without much experience and resources clearly has limitations and cannot recognize everything at the human level.
It would be more accurate to take data from the memory, but I had no such experience. Root is required and in general this solution looks more complicated. It is also unclear whether it is possible to achieve speed here around real time, if you look for objects with a heap JVM inside the device. In addition, the CV task I wanted to solve more than this.
In theory, one could make a proxy server and take information from there. But the network protocol of the game often changes, proxy servers on the Internet come across, but quickly become obsolete and not supported.
To begin with, I decided to get acquainted with the available materials from the game. I found a club of craftsmen who got packed game resources [1] [2] . First of all, I was interested in the pictures of units, but in the unpacked game package they are presented in the form of a tile map (pieces of which the unit consists).
I also found footage of units' animations glued together (albeit not perfectly) using a script - they were useful for learning the recognition model.

In addition, you can find csv with various game data in the resources - the number of HP, the damage of units of different levels, etc. This is useful when creating bot logic. For example, from the data it became clear that the field is divided into 18 x 29 cells, and you can only place units on them. Still there were all the images of maps of units, which will be useful to us later.
After searching for available CV-solutions, it became clear that in any case it would be necessary to train them on a marked dataset. I made screenshots of the screen and was already ready to mark some screenshots with my hands. This has proven to be a daunting task.
The search for available recognition programs took some time. I stopped at labelImg . All the annotation applications that I found were quite primitive: many did not support keyboard shortcuts, the choice of objects and their types was made much less convenient than in labelImg.
During the markup, it was helpful to have the source code of the application. I took screenshots every couple of seconds of the match. There are many objects on the screenshots (for example, an army of skeletons), and I made a modification in labelImg - by default, when marking the next image, labels from the previous one were taken. Often they had to simply move under the new position of the units, remove the dead units and add a few that appeared, and not mark up from scratch.

The process turned out to be resource-intensive - in two days in quiet mode I marked about 200 screenshots. The sample looks very small, but I decided to start experimenting. You can always add more examples and improve the quality of the model.
At the time of the markup, I did not know which training tool I would use, so I decided to save the markup results in the VOC format - one of the conservative and seemingly universal ones.
The question may arise: why not just look for pixel-by-pixel images of units by complete coincidence? The problem is that for this you would have to look for a huge number of different frames of animation of different units. It would hardly work. I wanted to make a universal solution that supports different resolutions. In addition, units may have a different color depending on the effect applied to them - freezing, acceleration.
I started researching possible image recognition solutions. I looked at the use of various algorithms: OpenCV, TensorFlow, Torch. I wanted to make the recognition as fast as possible, even sacrificing accuracy, and get the POC as soon as possible.
After reading the articles , I realized that my task does not fit with the HOG / LBP / SVM / HAAR / ... classifiers. Although they are fast, they would have to be applied many times - according to the classifier for each unit - and then one by one to apply them to the image for search. In addition, their principle of operation in theory would give bad results: units may have a different form, for example, when moving to the left and up.
Theoretically, using a neural network, you can apply it once to an image and get all the units of different types with their position, so I began to dig in the direction of neural networks. TensorFlow found support for Convolutional Neural Networks (CNN). It turned out that it is not necessary to train neural networks from scratch - you can retrain an existing powerful network .
Then I found a more practical YOLO algorithm, which promises less complexity and, therefore, should provide a high speed search algorithm without sacrificing accuracy (and in some cases surpassing other models).
On the YOLO websitepromise a huge difference in speed using the “tiny” model and a smaller, optimized network. YOLO also allows you to retrain the finished neural network for your task, with darknet - opensource-framework for using various neural networks, the creators of which developed YOLO - is a simple native C application, and all work with it occurs through its calls with parameters.
TensorFlow, written in Python, is in fact a Python library and is used using self-written scripts that need to be sorted out or sharpened to fit your needs. Probably, for someone the flexibility of TensorFlow is a plus, but, without going into details, you can hardly take it quickly and use it. Therefore, in my project, the choice fell on YOLO.
To work on learning the model, I installed Ubuntu 18.10, delivered the packages for the build, the OpenCL package from NVIDIA and other dependencies, collected darknet.
Github has a section with simple steps to retrain the YOLO model : you need to download the model and configs, change them and run retraining.
At first I wanted to try to retrain a simple YOLO model, then Tiny and compare them. However, it turned out that for learning simple models you need 4 GB of video card memory, and I only had an NVIDIA GeForce GTX 1060 video card with 3 GB purchased for games. Therefore, I was able to immediately train only the Tiny-model.
The markup of units on the images I had was in the VOC format, and YOLO worked with its format, so I used the convert2Yolo utilityto convert annotation files.
After a night of training in my 200 screenshots, I got the first results, and they surprised me - the model was really able to recognize something correctly! I realized that I was moving in the right direction, and decided to make more teaching examples.

I didn’t want to continue to lay out the screenshots, and I remembered the frames from the animations of the units. I marked out all the small pictures of their classes and tried to train the network on this set. The result was very bad. I suppose that the model could not select the correct patterns from small pictures for use on large images.
After that, I decided to place them on ready-made backgrounds of combat arenas and programmatically create a VOC markup file. It turned out such a synthetic screenshot with automatic 100% accurate markup.
I wrote a Scala script that divides the screenshot into 16 4x4 squares and sets the units in their center so that they do not overlap with each other. The script also allowed me to customize the creation of training examples - when taking damage, the units are painted in the color of their team (red / blue), and when classifying, I separately recognize units of different colors. In addition to coloring, the damaged units of different teams have small differences in clothing. Also, I randomly increased and reduced units a little so that the model learned not to depend heavily on the size of the unit. As a result, I learned how to create tens of thousands of educational examples, approximately similar to real screenshots.
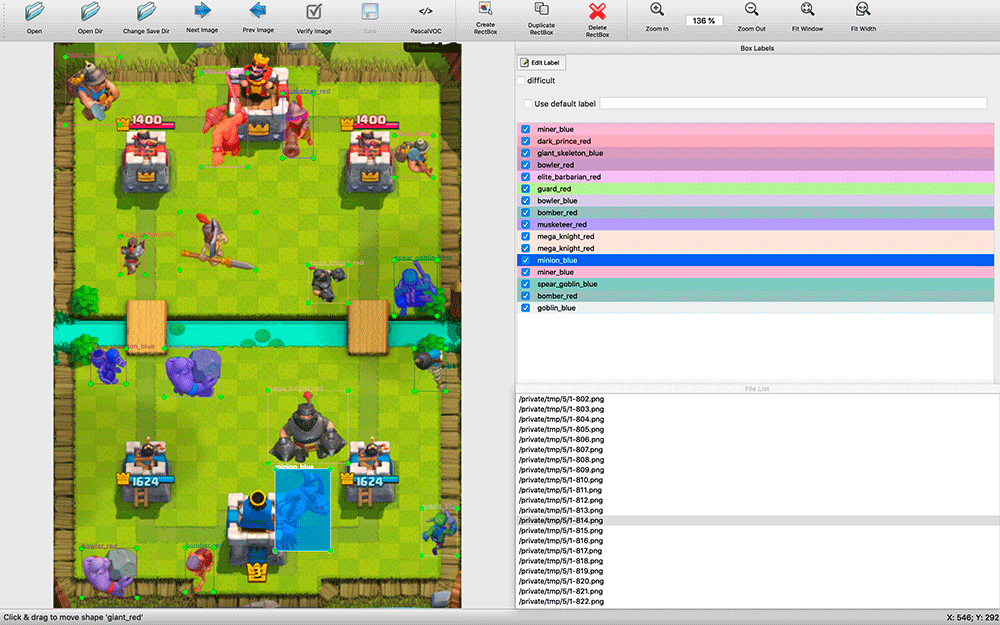
Generation was not perfect. Often, units were placed on top of buildings, although they would be behind them in the game; There were no examples of overlapping a part of a unit, although this is not uncommon in the game. But I decided to ignore all this for now.

The model obtained after several nights of training on a mixture of 200 real screenshots and 5000 generated images that were recreated in the process of learning once a day, when tested on these screenshots, gave poor results. It is not surprising, because the generated images have quite a few differences from the real ones.
Therefore, I set the resulting model to train on a mean sample in which there were only 200 of my screenshots. After that, she began to work much better.
I decided to write a bot in Python - it has many tools available for ML. I decided to use my model with OpenCV, which from 3.5 learned to use models of neural networks , and I even found a simple example . Having tried several libraries for working with ADB, I chose pure-python-adb - everything I need is simply implemented there: the function of obtaining the screen 'screencap' and performing the operation on the device 'shell'; I tap using 'input tap'.
So, after receiving a screenshot of the game, recognizing units on it and poking at the screen, I continued to work on recognizing the game state. In addition to units, I needed to make recognition of the current mana level and the cards available to the player.
The level of mana in the game is displayed in the form of a progress bar and numbers. Without thinking, I began to cut out the number, invert and recognize using pytesseract .
To determine the available maps and their locations, I used the keypoint detector KAZE from OpenCV . I still did not want to return to the neural network training again, and I chose a method that was faster and simpler, although he eventually had the least sufficient accuracy in the case when you need to search for many objects.
When launching the bot, I considered the keypoints for all the card pictures (there are several dozen of them), and during the game I searched for matches of all the cards with the player’s card area to reduce errors and increase speed. They were sorted according to accuracy and x coordinateto get the order of the cards - information about how they are located on the screen.
Having played a little with the parameters, in practice I got a lot of mistakes, although some complicated pictures of maps, which sometimes were mistaken for others by the algorithm, were recognized with great accuracy. We had to add a buffer of three elements: if we get three recognitions in a row, we get the same values, then we conditionally believe that we can trust them.

After getting all the necessary information (units and their approximate position, available mana and maps), you can make some decisions.
To begin with, I decided to take something simple: for example, if I had enough mana for an available card, I would play it on the field. But the bot still does not know how to “play” cards - he knows what cards we have, where the field is, you have to click on the desired card, and then on the desired cell on the field.
Knowing the resolution of the screenshot, you can understand the coordinates of the map and the desired cells of the field. Now I am tied to the exact screen resolution, but if necessary, this can be abstracted from. The decision function will return an array of clicks that need to be done in the near future. In general, our bot will be an infinite loop (simplified):
So far, a bot can only put units at one point, but already has enough information to build a more complex strategy.
In reality, I was faced with an unexpected and very unpleasant problem. Creating a screenshot via ADB takes about 100 ms, which introduces a significant delay - I expected this maximum delay, taking into account all the calculations and the choice of action, but not at one step of creating a screenshot. Simple and quick solutions could not be found. In theory, using the Android emulator, you can take screenshots directly from the application window, or you can make a utility to stream the image from the phone with compression via UDP and connect to it with a bot, but I did not find quick solutions either.
Soberly assessing the state of my project, I decided to stop on this model for now. I spent a few weeks of my free time on this, but the recognition of units is only part of the gameplay.
I decided to develop parts of the bot gradually - to make the basic logic of perception, then the simple logic of the game and interaction with the game, and then it will be possible to improve the individual subsiding parts of the bot. When the level of model recognition units becomes sufficient, adding information about HP and the level of units can lead the development of a game bot to a new level. Perhaps this will be the next goal, but for now you definitely should not dwell on this task.
Project repository on Github
I spent a lot of time on the project and, frankly, tired of it, but I don’t regret a bit - I got a new experience in ML / CV.
Maybe I will come back to him later - I will be glad if someone joins me. If you are interested, join the Telegram group , and also come to my Scala course .
Under the cat you will find the process of creating a proof-of-concept bot for the game Clash Royale, in which I used Scala, Python, and the CV library. Using computer vision and machine learning, I tried to create a game bot that interacts as a live player.
My name is Sergey Tolmachyov, I am Lead Scala Developer in the Waves Platform and teach Scala course in the Binary District, and in my spare time I study other technologies, such as AI. And I wanted to reinforce the obtained skills with some practical experience. In contrast to the AI competition, where your bot plays against the bots of other users, you can play Clash Royale against people, which sounds funny. Your bot can learn to beat real players!
Clash Royale game mechanics
The mechanics of the game is quite simple. You and your opponent have three buildings: a fortress and two towers. Players before the game collect decks - 8 available units, which are then used in battle. They have different levels, and they can be pumped, collecting more maps of these units and buying upgrades.
After the start of the game, you can put available units at a safe distance from enemy towers, while spending units of mana, which are slowly restored during the game. Units are sent to enemy buildings and are distracted by enemies encountered along the way. The player can control only the initial position of the units - their further movement and damage can be affected only by the installation of other units.
There are still spells that can be played anywhere in the field, usually they cause damage to units in different ways. Spells can clone, freeze or speed up units in some area.
The goal of the game is to destroy enemy buildings. For a complete victory, you need to destroy the fortress or after two minutes of the game destroy more buildings (the rules depend on the game modes, but in general they sound like this).
During the game, you need to take into account the movement of units, the possible mana number and current enemy cards. You also need to consider how the installation of the unit affects the playing field.
We build a solution
Clash Royale is a mobile game, so I decided to run it on Android and interact with it via ADB. This would allow to support work with a simulator or with a real device.
I decided that the bot, like many other AI games, should work using the Perception-Analysis-Action algorithm. The whole environment in the game is displayed on the screen, and it interacts with it using the screen tap. Therefore, the bot must be a program, the input of which is a description of the current state in the game: the location and characteristics of units and buildings, the current possible maps and the amount of mana. At the output, the bot must give an array of coordinates, where it is necessary to tap the unit.
But before creating the bot itself, it was necessary to solve the problem of extracting information about the current state of the game from the screenshot. By and large, this task is devoted to the further content of the article.
To solve this problem, I decided to use Computer Vision. Perhaps this is not the best solution: CV without much experience and resources clearly has limitations and cannot recognize everything at the human level.
It would be more accurate to take data from the memory, but I had no such experience. Root is required and in general this solution looks more complicated. It is also unclear whether it is possible to achieve speed here around real time, if you look for objects with a heap JVM inside the device. In addition, the CV task I wanted to solve more than this.
In theory, one could make a proxy server and take information from there. But the network protocol of the game often changes, proxy servers on the Internet come across, but quickly become obsolete and not supported.
Available game resources
To begin with, I decided to get acquainted with the available materials from the game. I found a club of craftsmen who got packed game resources [1] [2] . First of all, I was interested in the pictures of units, but in the unpacked game package they are presented in the form of a tile map (pieces of which the unit consists).
I also found footage of units' animations glued together (albeit not perfectly) using a script - they were useful for learning the recognition model.
In addition, you can find csv with various game data in the resources - the number of HP, the damage of units of different levels, etc. This is useful when creating bot logic. For example, from the data it became clear that the field is divided into 18 x 29 cells, and you can only place units on them. Still there were all the images of maps of units, which will be useful to us later.
Computer Vision for the lazy
After searching for available CV-solutions, it became clear that in any case it would be necessary to train them on a marked dataset. I made screenshots of the screen and was already ready to mark some screenshots with my hands. This has proven to be a daunting task.
The search for available recognition programs took some time. I stopped at labelImg . All the annotation applications that I found were quite primitive: many did not support keyboard shortcuts, the choice of objects and their types was made much less convenient than in labelImg.
During the markup, it was helpful to have the source code of the application. I took screenshots every couple of seconds of the match. There are many objects on the screenshots (for example, an army of skeletons), and I made a modification in labelImg - by default, when marking the next image, labels from the previous one were taken. Often they had to simply move under the new position of the units, remove the dead units and add a few that appeared, and not mark up from scratch.
The process turned out to be resource-intensive - in two days in quiet mode I marked about 200 screenshots. The sample looks very small, but I decided to start experimenting. You can always add more examples and improve the quality of the model.
At the time of the markup, I did not know which training tool I would use, so I decided to save the markup results in the VOC format - one of the conservative and seemingly universal ones.
The question may arise: why not just look for pixel-by-pixel images of units by complete coincidence? The problem is that for this you would have to look for a huge number of different frames of animation of different units. It would hardly work. I wanted to make a universal solution that supports different resolutions. In addition, units may have a different color depending on the effect applied to them - freezing, acceleration.
Why I chose YOLO
I started researching possible image recognition solutions. I looked at the use of various algorithms: OpenCV, TensorFlow, Torch. I wanted to make the recognition as fast as possible, even sacrificing accuracy, and get the POC as soon as possible.
After reading the articles , I realized that my task does not fit with the HOG / LBP / SVM / HAAR / ... classifiers. Although they are fast, they would have to be applied many times - according to the classifier for each unit - and then one by one to apply them to the image for search. In addition, their principle of operation in theory would give bad results: units may have a different form, for example, when moving to the left and up.
Theoretically, using a neural network, you can apply it once to an image and get all the units of different types with their position, so I began to dig in the direction of neural networks. TensorFlow found support for Convolutional Neural Networks (CNN). It turned out that it is not necessary to train neural networks from scratch - you can retrain an existing powerful network .
Then I found a more practical YOLO algorithm, which promises less complexity and, therefore, should provide a high speed search algorithm without sacrificing accuracy (and in some cases surpassing other models).
On the YOLO websitepromise a huge difference in speed using the “tiny” model and a smaller, optimized network. YOLO also allows you to retrain the finished neural network for your task, with darknet - opensource-framework for using various neural networks, the creators of which developed YOLO - is a simple native C application, and all work with it occurs through its calls with parameters.
TensorFlow, written in Python, is in fact a Python library and is used using self-written scripts that need to be sorted out or sharpened to fit your needs. Probably, for someone the flexibility of TensorFlow is a plus, but, without going into details, you can hardly take it quickly and use it. Therefore, in my project, the choice fell on YOLO.
Model building
To work on learning the model, I installed Ubuntu 18.10, delivered the packages for the build, the OpenCL package from NVIDIA and other dependencies, collected darknet.
Github has a section with simple steps to retrain the YOLO model : you need to download the model and configs, change them and run retraining.
At first I wanted to try to retrain a simple YOLO model, then Tiny and compare them. However, it turned out that for learning simple models you need 4 GB of video card memory, and I only had an NVIDIA GeForce GTX 1060 video card with 3 GB purchased for games. Therefore, I was able to immediately train only the Tiny-model.
The markup of units on the images I had was in the VOC format, and YOLO worked with its format, so I used the convert2Yolo utilityto convert annotation files.
After a night of training in my 200 screenshots, I got the first results, and they surprised me - the model was really able to recognize something correctly! I realized that I was moving in the right direction, and decided to make more teaching examples.
I didn’t want to continue to lay out the screenshots, and I remembered the frames from the animations of the units. I marked out all the small pictures of their classes and tried to train the network on this set. The result was very bad. I suppose that the model could not select the correct patterns from small pictures for use on large images.
After that, I decided to place them on ready-made backgrounds of combat arenas and programmatically create a VOC markup file. It turned out such a synthetic screenshot with automatic 100% accurate markup.
I wrote a Scala script that divides the screenshot into 16 4x4 squares and sets the units in their center so that they do not overlap with each other. The script also allowed me to customize the creation of training examples - when taking damage, the units are painted in the color of their team (red / blue), and when classifying, I separately recognize units of different colors. In addition to coloring, the damaged units of different teams have small differences in clothing. Also, I randomly increased and reduced units a little so that the model learned not to depend heavily on the size of the unit. As a result, I learned how to create tens of thousands of educational examples, approximately similar to real screenshots.
Generation was not perfect. Often, units were placed on top of buildings, although they would be behind them in the game; There were no examples of overlapping a part of a unit, although this is not uncommon in the game. But I decided to ignore all this for now.
The model obtained after several nights of training on a mixture of 200 real screenshots and 5000 generated images that were recreated in the process of learning once a day, when tested on these screenshots, gave poor results. It is not surprising, because the generated images have quite a few differences from the real ones.
Therefore, I set the resulting model to train on a mean sample in which there were only 200 of my screenshots. After that, she began to work much better.
Damn shame
Прошу прощения за оперирование такими ненаучными мерами, как «гораздо лучше», но я не знаю, как быстро произвести кросс-валидацию по изображениям, поэтому пробовал несколько скриншотов не из обучающей выборки и смотрел, удовлетворяют ли меня результаты. Это же самое важное. Мы ведь ленивые и делаем прототип, верно?
Следующие шаги по улучшению модели были понятны — разметить руками больше настоящих скриншотов и обучить на них модель, предобученную на сгенерированных скриншотах.
Следующие шаги по улучшению модели были понятны — разметить руками больше настоящих скриншотов и обучить на них модель, предобученную на сгенерированных скриншотах.
Let's get down to the bot
I decided to write a bot in Python - it has many tools available for ML. I decided to use my model with OpenCV, which from 3.5 learned to use models of neural networks , and I even found a simple example . Having tried several libraries for working with ADB, I chose pure-python-adb - everything I need is simply implemented there: the function of obtaining the screen 'screencap' and performing the operation on the device 'shell'; I tap using 'input tap'.
So, after receiving a screenshot of the game, recognizing units on it and poking at the screen, I continued to work on recognizing the game state. In addition to units, I needed to make recognition of the current mana level and the cards available to the player.
The level of mana in the game is displayed in the form of a progress bar and numbers. Without thinking, I began to cut out the number, invert and recognize using pytesseract .
To determine the available maps and their locations, I used the keypoint detector KAZE from OpenCV . I still did not want to return to the neural network training again, and I chose a method that was faster and simpler, although he eventually had the least sufficient accuracy in the case when you need to search for many objects.
When launching the bot, I considered the keypoints for all the card pictures (there are several dozen of them), and during the game I searched for matches of all the cards with the player’s card area to reduce errors and increase speed. They were sorted according to accuracy and x coordinateto get the order of the cards - information about how they are located on the screen.
Having played a little with the parameters, in practice I got a lot of mistakes, although some complicated pictures of maps, which sometimes were mistaken for others by the algorithm, were recognized with great accuracy. We had to add a buffer of three elements: if we get three recognitions in a row, we get the same values, then we conditionally believe that we can trust them.
After getting all the necessary information (units and their approximate position, available mana and maps), you can make some decisions.
To begin with, I decided to take something simple: for example, if I had enough mana for an available card, I would play it on the field. But the bot still does not know how to “play” cards - he knows what cards we have, where the field is, you have to click on the desired card, and then on the desired cell on the field.
Knowing the resolution of the screenshot, you can understand the coordinates of the map and the desired cells of the field. Now I am tied to the exact screen resolution, but if necessary, this can be abstracted from. The decision function will return an array of clicks that need to be done in the near future. In general, our bot will be an infinite loop (simplified):
бесконечно:
изображение = получить изображение
если есть действия:
сделать действие(первое действие)
небольшая задержка для правдоподобности
иначе:
юниты = распознаем юнитов(изображение)
карты = распознаем карты(изображение)
мана = распознаем ману(изображение)
действия += анализ(изображение, юниты, карты, мана)So far, a bot can only put units at one point, but already has enough information to build a more complex strategy.
First problems
In reality, I was faced with an unexpected and very unpleasant problem. Creating a screenshot via ADB takes about 100 ms, which introduces a significant delay - I expected this maximum delay, taking into account all the calculations and the choice of action, but not at one step of creating a screenshot. Simple and quick solutions could not be found. In theory, using the Android emulator, you can take screenshots directly from the application window, or you can make a utility to stream the image from the phone with compression via UDP and connect to it with a bot, but I did not find quick solutions either.
so
Soberly assessing the state of my project, I decided to stop on this model for now. I spent a few weeks of my free time on this, but the recognition of units is only part of the gameplay.
I decided to develop parts of the bot gradually - to make the basic logic of perception, then the simple logic of the game and interaction with the game, and then it will be possible to improve the individual subsiding parts of the bot. When the level of model recognition units becomes sufficient, adding information about HP and the level of units can lead the development of a game bot to a new level. Perhaps this will be the next goal, but for now you definitely should not dwell on this task.
Project repository on Github
I spent a lot of time on the project and, frankly, tired of it, but I don’t regret a bit - I got a new experience in ML / CV.
Maybe I will come back to him later - I will be glad if someone joins me. If you are interested, join the Telegram group , and also come to my Scala course .