NetApp ONTAP: SnapMirror for SVM
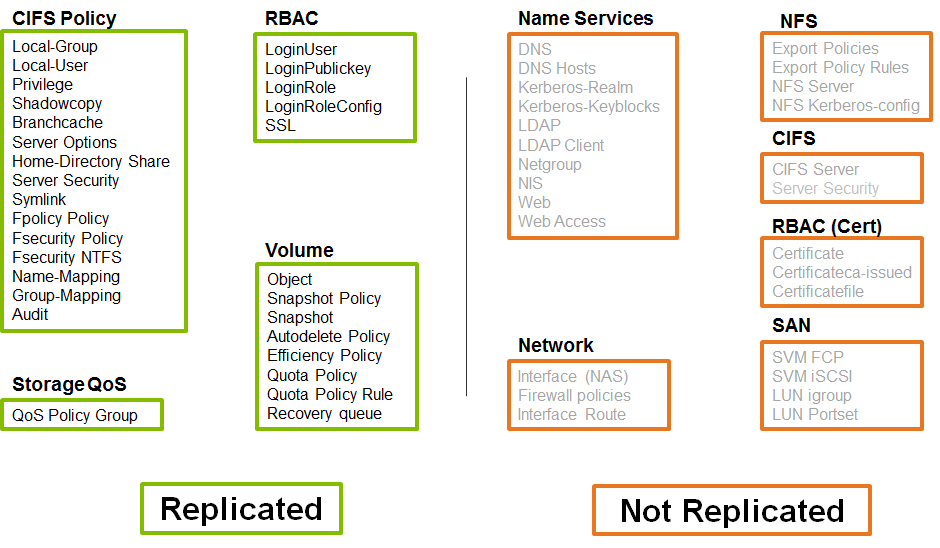
Starting with version 8.3.1, a new functionality called SnapMirror for SVM was presented in the software (firmware) of Data ONTAP . SnapMirror for SVM is the ability to replicate all the data on the storage system and all the settings, or only part of the data or settings on the spare platform (Disaster Recovery).
In order to be able to run all your services on a backup system, it is logical that the primary and secondary systems are more or less the same in performance. If the system is weaker on the backup site, you should ask yourself in advance which of the most critical services will need to be launched and which ones will not be started. You can replicate both the entire SVM with all its volumes, and exclude from the replica part of the volumes and network interfaces (starting with ONTAP 9).
There are two modes of operation for SnapMirror for SVM: Identity Preserve and Identity Discard.
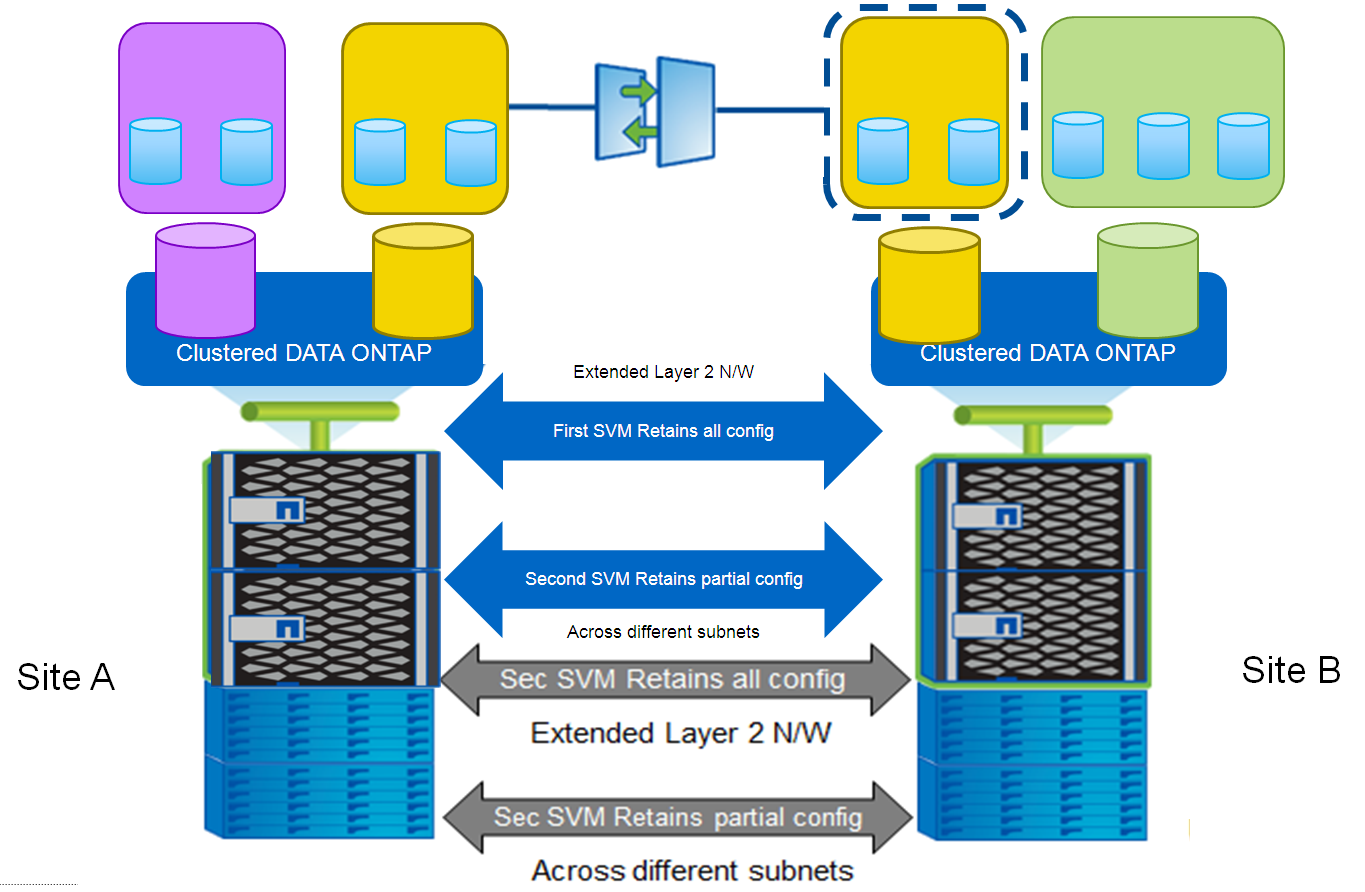
SVM is something like virtual machines on servers, but designed for storage. Let this analogy not mislead you, it will not work on the storage system to run your virtual machines with Windows, Linux, and so on. SVM is a virtual machine (very often the only one, but you can deploy a lot if you wish) in a storage cluster. A storage cluster with ONTAP software (firmware) can consist of one or more nodes, at the moment there are a maximum of 24 nodes in the cluster. Each SVM is “logically”, it is one entity that is visible to the administrator as a single entity. SVM lives immediately on the entire cluster, but physically, in fact, “under the hood” of the storage system, it is a set of virtual machines, one machine on each node of the entire cluster, which are combined in a special way and presented to the administrator as a single management point.
The meaning of SVM in the ONTAP cluster, on the one hand, is that it is visible to the storage administrator as one control point of the entire cluster and, if necessary, migrates objects (volumes, moons, network addresses), by cluster nodes, without any special configuration (SVM takes care of all the migration itself).
On the other hand, the meaning of SVM is also to deceive hosts in a beautiful, sophisticated way, so that 2, 4.8, or even 24 nodes of the cluster are visible to the final host as a single device, and the migration of data or network addresses from one node to another, for hosts it was transparent.
All of these SVM features in a cluster are called “Single Namespace”.
Identity Preserve mode is designed for NAS, which stores network parameters and addresses, can be used with several schemes:

An L2 domain between sites requires appropriate network equipment and channels. Imagine two sites with two storage systems that replicate data from the first to the second, in the event of an accident, the administrator switches to the backup site, and the same network IP addresses go up to the second storage system, as they were on the main site, and in general everything that was configured on the first storage also moves. In turn, when the moved servers (with the old settings for connecting to the storage system) using the first (main) storage system earlier go up to the second (spare, DR) site, they see the same addresses where they connected earlier, but in fact it is a backup site , but they simply don’t know about it, and connect to the second storage system, as if to the main one, which greatly simplifies and accelerates the process of switching to the backup site.Large companies can afford the required equipment and channels; on the other hand, this mode significantly speeds up the switch to the backup site .
In the absence of a stretched L2 network between the main and backup sites, you will need several different IP subnets and routing. If the data were available at the old addresses, on the second (backup, DR) site, then the applications would not be able to access them, because there are other subnets on the backup site. In this case, the Identity Preserve function also comes to the rescue with saving network addresses - after all, you can specify in advance the new network IP addresses for the DR platform (which will rise on the DR platform at the time of switching to the secondary storage), by which data will be available on the backup storage. If you just migrate the hosts, then their network addresses will also need to be reconfigured: manually or using scripts on the backup site so that they can see their data, connecting from their new IP addresses, again, to the new IP addresses of the storage.This mode of operation will be more interesting not for large companies that can afford a longer switching time in the event of a disaster or accident, without wasting money on expensive equipment and channels.
Sometimes there is a need to completely abandon the old settings, when switching to a backup site, for example, abandon the NFS export settings, CIFS server settings, DNS, etc. It may also be necessary to provide the ability to read data at a remote site or when there is a need to replicate moons for SAN environments. In all such situations, the Identity Discard function (Identity Preserve = False) comes to the rescue.
As in the case of the Identity Preserve L3 configuration, on the remote site, after switching, it will be necessary to reconfigure the network IP or FC addresses (and other settings that were not replicated, according to the Identity Discard mode), according to which old data will be available on the secondary storage. If you simply migrate the hosts, then their network addresses will also need to be reconfigured: manually or using scripts on the backup site so that they can see their data. This mode of operation will be moreIt is interesting for customers who need to be able to replicate LUNs for SAN infrastructure or for those who want to read data on a backup site (for example, cataloging). Also, this mode will be interesting for checking the backup copy for the possibility of being restored to it, as well as for a variety of testers and developers .
Clustered Data ONTAP SnapMirror Toolkit is a free set of Perl scripts that will speed up and streamline the process of automating validation, preparation, configuration, initialization, updating, switching to the backup site and back to SnapMirror replication.
Download the SnapMirror Toolkit .
For Windows machines, the NetApp PowerShell Toolkit is available , which allows you to create NetApp management scripts.
Workflow automation- This is a free graphical utility that allows you to create sets or bundles of tasks to automate ONTAP management processes. For example, through it, you can configure the creation of new permissions for the file sphere or iGroup, add to it replicated volumes and new initiating hosts from the DR platform, raise new LIF interfaces and much more (create Broadcast Domain, create Failover Groups, Firewall Policies, Routes, DNS, etc.). All this can be automated so that it is done immediately after replication break is completed, with just one click of the mouse. Workflow Automation will be more useful for Identity Preserve L3 and Identity Discard modes, since in these modes, after switching to the backup site, you will need to perform additional configuration of storage systems and servers.
Data replication can be performed both on the physical FAS platform and on their virtual brothers: Data ONTAP Edge , ONTAP Select, or Cloud ONTAP to the public cloud. The last option is called Snap-to-Cloud. To be more precise, Snap-to-Cloud is a set (bundle) of certain models of FAS platforms + Cloud ONTAP with installed replication licenses for backup to the cloud.

To provide 0 switching time , you will need even higher costs for channels, more and more expensive network equipment. Therefore, it is often more appropriate to use DR rather than HA. In the case of DR, downtime when switching to the backup site is inevitable, RPO and RTO can be quite small, but it does not equal 0, as is the case with HA.
To exclude volume / moons from the DR replica of the entire SVM, you must do the following on the source:
Using a spare site as a development environment using thin cloning (Data Protection of volume) reduces the load on the main storage system, while testers and developers may have newer information (compared to the traditional FullBackup approach because snaps are removed and replicated much faster and usually because of this more often) for their work, replicated from the main storage system. For thin cloning, you need a FlexClone license at the appropriate site.
Snapshots of NetApp in general do not affect the performance of the entire system in such an architectural manner. Due to this, snapshots are convenient for replication - transferring only changes. This is more efficient than Full Backup / Restore, since during backup operations only these changes are read / written, and not every time in a new way. It is more efficient to use hardware replication by means of storage because the host CPU and its network ports are not used during backup. This allows you to backup more often, and the ability to instantly take snapshots will allow you to remove them right in the middle of the work day.
I want to note that replication based on Netap snapshots, albeit much less than the traditional backup scheme or traditional CoW snapshots, loads storage, but it still loads it additionally. First, for replication, additional read operations of actually new changes are generated, generating additional tasks of reading from the disk subsystem. Secondly, read operations pass through the storage system CPU. There is no magic: we can significantly reduce and optimize the load from the backup process, but you cannot completely level it.
SnapMirror technology subtly replicates and restores data using snapshots. This allows you to reduce the load on the network and disk subsystem in comparison with Full Backup / Restore and perform replicas even in the middle of the working day, thereby increasing the number of backups and thus significantly reducing the backup windowing window. SnapMirror for SVM functionality provides a convenient way to create DR recovery schemes for the entire storage system. In addition to DR, the second site can be used for Test / Dev, removing these tasks from the main storage.
Translation into English:
ONTAP: SnapMirror for SVM
This may contain links to Habra articles that will be published later .
Please send messages about errors in the text to the LAN .
Comments, additions and questions on the opposite article, please comment .
In order to be able to run all your services on a backup system, it is logical that the primary and secondary systems are more or less the same in performance. If the system is weaker on the backup site, you should ask yourself in advance which of the most critical services will need to be launched and which ones will not be started. You can replicate both the entire SVM with all its volumes, and exclude from the replica part of the volumes and network interfaces (starting with ONTAP 9).
There are two modes of operation for SnapMirror for SVM: Identity Preserve and Identity Discard.
What is NetApp SVM?
SVM is something like virtual machines on servers, but designed for storage. Let this analogy not mislead you, it will not work on the storage system to run your virtual machines with Windows, Linux, and so on. SVM is a virtual machine (very often the only one, but you can deploy a lot if you wish) in a storage cluster. A storage cluster with ONTAP software (firmware) can consist of one or more nodes, at the moment there are a maximum of 24 nodes in the cluster. Each SVM is “logically”, it is one entity that is visible to the administrator as a single entity. SVM lives immediately on the entire cluster, but physically, in fact, “under the hood” of the storage system, it is a set of virtual machines, one machine on each node of the entire cluster, which are combined in a special way and presented to the administrator as a single management point.
The meaning of SVM in the ONTAP cluster, on the one hand, is that it is visible to the storage administrator as one control point of the entire cluster and, if necessary, migrates objects (volumes, moons, network addresses), by cluster nodes, without any special configuration (SVM takes care of all the migration itself).
On the other hand, the meaning of SVM is also to deceive hosts in a beautiful, sophisticated way, so that 2, 4.8, or even 24 nodes of the cluster are visible to the final host as a single device, and the migration of data or network addresses from one node to another, for hosts it was transparent.
All of these SVM features in a cluster are called “Single Namespace”.
Identity Preserve for NAS (IP)
Identity Preserve mode is designed for NAS, which stores network parameters and addresses, can be used with several schemes:
- When there is a stretched L2 domain between sites
- When there is L3 connectivity between sites (routing)
- When there is no need to replicate the settings of network IP addresses, then they will need to be manually configured after switching to the backup site.
Identity Preserve: L2 Domain for NAS
An L2 domain between sites requires appropriate network equipment and channels. Imagine two sites with two storage systems that replicate data from the first to the second, in the event of an accident, the administrator switches to the backup site, and the same network IP addresses go up to the second storage system, as they were on the main site, and in general everything that was configured on the first storage also moves. In turn, when the moved servers (with the old settings for connecting to the storage system) using the first (main) storage system earlier go up to the second (spare, DR) site, they see the same addresses where they connected earlier, but in fact it is a backup site , but they simply don’t know about it, and connect to the second storage system, as if to the main one, which greatly simplifies and accelerates the process of switching to the backup site.Large companies can afford the required equipment and channels; on the other hand, this mode significantly speeds up the switch to the backup site .
Identity Preserve: L3 Domain for NAS
In the absence of a stretched L2 network between the main and backup sites, you will need several different IP subnets and routing. If the data were available at the old addresses, on the second (backup, DR) site, then the applications would not be able to access them, because there are other subnets on the backup site. In this case, the Identity Preserve function also comes to the rescue with saving network addresses - after all, you can specify in advance the new network IP addresses for the DR platform (which will rise on the DR platform at the time of switching to the secondary storage), by which data will be available on the backup storage. If you just migrate the hosts, then their network addresses will also need to be reconfigured: manually or using scripts on the backup site so that they can see their data, connecting from their new IP addresses, again, to the new IP addresses of the storage.This mode of operation will be more interesting not for large companies that can afford a longer switching time in the event of a disaster or accident, without wasting money on expensive equipment and channels.
Identity Discard for SAN or NAS
Sometimes there is a need to completely abandon the old settings, when switching to a backup site, for example, abandon the NFS export settings, CIFS server settings, DNS, etc. It may also be necessary to provide the ability to read data at a remote site or when there is a need to replicate moons for SAN environments. In all such situations, the Identity Discard function (Identity Preserve = False) comes to the rescue.
As in the case of the Identity Preserve L3 configuration, on the remote site, after switching, it will be necessary to reconfigure the network IP or FC addresses (and other settings that were not replicated, according to the Identity Discard mode), according to which old data will be available on the secondary storage. If you simply migrate the hosts, then their network addresses will also need to be reconfigured: manually or using scripts on the backup site so that they can see their data. This mode of operation will be moreIt is interesting for customers who need to be able to replicate LUNs for SAN infrastructure or for those who want to read data on a backup site (for example, cataloging). Also, this mode will be interesting for checking the backup copy for the possibility of being restored to it, as well as for a variety of testers and developers .
SnapMirror Toolkit
Clustered Data ONTAP SnapMirror Toolkit is a free set of Perl scripts that will speed up and streamline the process of automating validation, preparation, configuration, initialization, updating, switching to the backup site and back to SnapMirror replication.
Download the SnapMirror Toolkit .
NetApp-PowerShell Commandlets
For Windows machines, the NetApp PowerShell Toolkit is available , which allows you to create NetApp management scripts.
Workflow automation
Workflow automation- This is a free graphical utility that allows you to create sets or bundles of tasks to automate ONTAP management processes. For example, through it, you can configure the creation of new permissions for the file sphere or iGroup, add to it replicated volumes and new initiating hosts from the DR platform, raise new LIF interfaces and much more (create Broadcast Domain, create Failover Groups, Firewall Policies, Routes, DNS, etc.). All this can be automated so that it is done immediately after replication break is completed, with just one click of the mouse. Workflow Automation will be more useful for Identity Preserve L3 and Identity Discard modes, since in these modes, after switching to the backup site, you will need to perform additional configuration of storage systems and servers.
Snap-to-cloud
Data replication can be performed both on the physical FAS platform and on their virtual brothers: Data ONTAP Edge , ONTAP Select, or Cloud ONTAP to the public cloud. The last option is called Snap-to-Cloud. To be more precise, Snap-to-Cloud is a set (bundle) of certain models of FAS platforms + Cloud ONTAP with installed replication licenses for backup to the cloud.
Disaster Recovery is not High Avalability
To provide 0 switching time , you will need even higher costs for channels, more and more expensive network equipment. Therefore, it is often more appropriate to use DR rather than HA. In the case of DR, downtime when switching to the backup site is inevitable, RPO and RTO can be quite small, but it does not equal 0, as is the case with HA.
VOLUME EXCLUSION FROM DR REPLICA
To exclude volume / moons from the DR replica of the entire SVM, you must do the following on the source:
source_cluster::> volume modify -vserver vs1 -volume test_vol1 -vserver-dr-protection unprotected
The second use of SnapMirror is Test / Dev.
Using a spare site as a development environment using thin cloning (Data Protection of volume) reduces the load on the main storage system, while testers and developers may have newer information (compared to the traditional FullBackup approach because snaps are removed and replicated much faster and usually because of this more often) for their work, replicated from the main storage system. For thin cloning, you need a FlexClone license at the appropriate site.
Traditional backup vs Snap *
Snapshots of NetApp in general do not affect the performance of the entire system in such an architectural manner. Due to this, snapshots are convenient for replication - transferring only changes. This is more efficient than Full Backup / Restore, since during backup operations only these changes are read / written, and not every time in a new way. It is more efficient to use hardware replication by means of storage because the host CPU and its network ports are not used during backup. This allows you to backup more often, and the ability to instantly take snapshots will allow you to remove them right in the middle of the work day.
I want to note that replication based on Netap snapshots, albeit much less than the traditional backup scheme or traditional CoW snapshots, loads storage, but it still loads it additionally. First, for replication, additional read operations of actually new changes are generated, generating additional tasks of reading from the disk subsystem. Secondly, read operations pass through the storage system CPU. There is no magic: we can significantly reduce and optimize the load from the backup process, but you cannot completely level it.
conclusions
SnapMirror technology subtly replicates and restores data using snapshots. This allows you to reduce the load on the network and disk subsystem in comparison with Full Backup / Restore and perform replicas even in the middle of the working day, thereby increasing the number of backups and thus significantly reducing the backup windowing window. SnapMirror for SVM functionality provides a convenient way to create DR recovery schemes for the entire storage system. In addition to DR, the second site can be used for Test / Dev, removing these tasks from the main storage.
Translation into English:
ONTAP: SnapMirror for SVM
This may contain links to Habra articles that will be published later .
Please send messages about errors in the text to the LAN .
Comments, additions and questions on the opposite article, please comment .