Broad semantic news aggregator implementation
 The purpose of this article is to share experience and ideas on the implementation of a project based on the complete transformation of texts into a semantic representation and the organization of semantic (semantic) search based on the obtained knowledge base. We will talk about the basic principles of the functioning of this system, the technologies used, and the problems that arise during its implementation.
The purpose of this article is to share experience and ideas on the implementation of a project based on the complete transformation of texts into a semantic representation and the organization of semantic (semantic) search based on the obtained knowledge base. We will talk about the basic principles of the functioning of this system, the technologies used, and the problems that arise during its implementation.Why is this needed?
Ideally, the semantic system “understands” the content of the processed articles in the form of a system of semantic concepts and selects the main ones from them (“what is the text about”). This gives great opportunities for more precise clustering, automatic summarization and semantic search, when the system does not search according to the query words, but in the meaning behind these words.
Semantic search is not only the answer within the meaning of the phrase typed in the search string, but in general the way the user interacts with the system. A semantic query can be not only a simple concept or phrase, but also a document - the system at the same time issues semantically related documents. The user's interests profile is also a semantic request and can act in the background in parallel with other requests.
The response to a semantic query generally consists of the following components:
- A direct answer to the question and other information regarding the concepts requested and related.
- Semantic concepts that are semantically related to the concepts of a request, which can be both an answer to a question and a means for "clarifying" a request.
- Text documents, multimedia objects, links to related sites that reveal and describe the requested semantic concept.
News aggregator is the most convenient information application for working out such a semantic approach. You can build a working system with a relatively small amount of processed text and a high acceptable level of processing errors.
Ontology
When choosing an ontology, the main criterion was the convenience of its use both for constructing a semantic text parser and for efficient search organization. To simplify the system, an assumption was made that it is possible not to process, or to process with a large acceptable level of errors, a part of the information contained in the text, which is supposed not to be very important for search tasks (supporting information).
In our ontology, simple semantic concepts (objects) can be divided into the following classes:
- Material objects, people, organizations, intangible objects (for example, films), geographical objects, etc.
- Actions, indicators ("sell", "inflation", "make").
- Characteristics ("large", "blue"), we will call them attributes.
- Periods of time, numerical information.
The basis of the information contained in the text is “nodes” formed by semantic combinations of the concepts of the second class (action) and the first class. Objects of various types fill in free valencies (roles) (for example, price - for which product? Where? From which seller? ). We can say that objects of the first class specify, specify actions and indicators (price - oil price ). Not only action objects, but also first-class objects (“ Russian companies”) can act as a “node-forming” object . This approach is similar to the frames ( Framenet ) widely known in Western computer linguistics .
Nodes can enter one another when one node fills an empty role in another node. As a result, the text is converted into a system of nested nodes.
Characteristics applied to the semantic concepts of the first and second class, as a rule, can be considered "secondary" information in relation to search tasks. For example, in the expressions “ low oil prices remain ”, “ stable oil supplies to Europe”, the attributes in italics are less important, the other objects. Such information is not included in the nodes, but is tied to them in relation to a specific place in the document. Similarly, numerical information and time periods are attached to nodes.
The figure below illustrates the semantic transformation of two simple phrases. Colored rectangles are elements of node templates, and rectangles above them are elements of a node constructed according to this template.
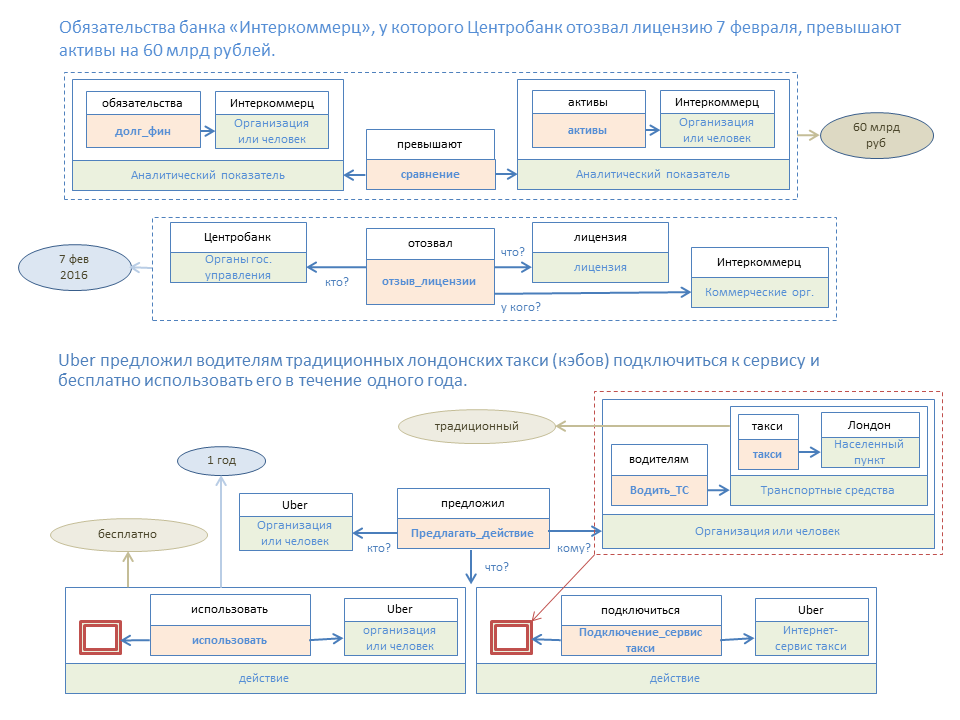
With this approach, we have two kinds of information:
- A specific node exists ("oil prices"). The drive of such nodes will be called the “Knowledge Base”.
- This node exists in certain places of documents with certain attributes, numerical values and time periods.
We do such a separation to simplify and speed up information retrieval, when, as a rule, we first look for nodes relevant to the query, and then filter the received data by auxiliary parameters.
Convert text to semantic representation
The main task of semantic text transformation is to structure the objects contained therein as a set of suitable nodes. To do this, we use a system of node templates, in which for each element a condition is set for an acceptable type of object. Types form a tree graph. When a certain type of object is set for a given role in a node template, then all objects of the same type or “subordinate” types may be suitable for this role.
For example, in the node “trade operations” the active object (seller or buyer) can be an object of the type “person or organization”, as well as objects of all underlying types (companies, shops, cultural institutions, etc.). In node templates, we also introduce syntactic restrictions. Unlike most other systems of semantic analysis of texts, we do not do preliminary parsing with the formation of a network of syntactic dependencies, but apply syntactic restrictions in parallel with semantic analysis.
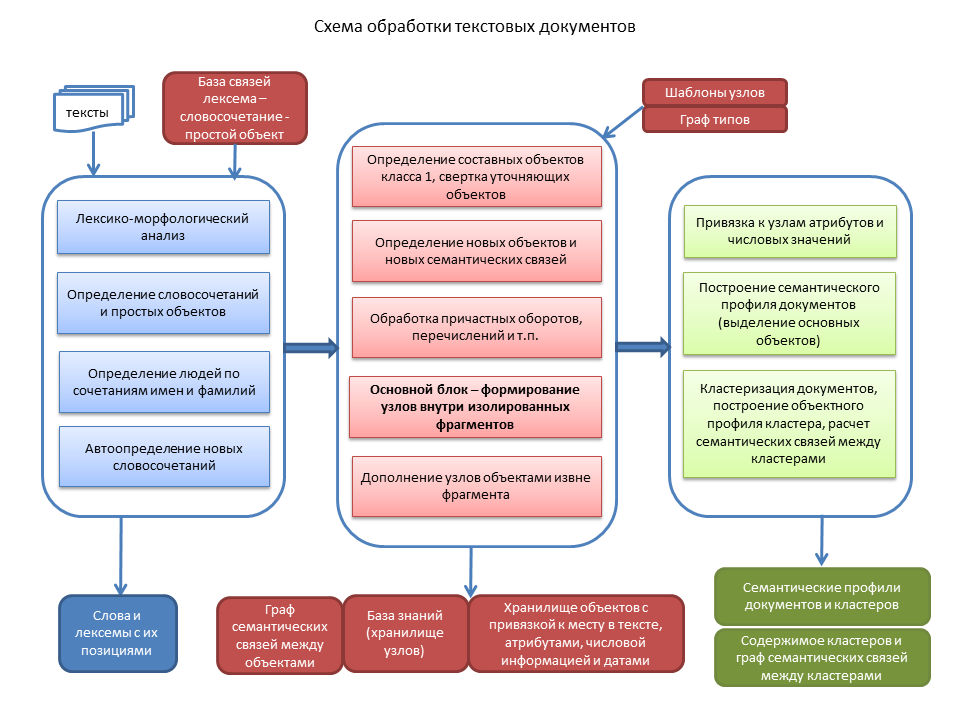
Briefly explain the main stages.
First, the identification of simple objects, which are determined by single words or known phrases. Next, combinations of first and last names are determined as indications of people, and an algorithm for analyzing individual words and sequences of words that may be objects unknown to the system works.
At the second stage, we form nodes based on objects of class 1 with objects that refine them. Phrases such as “CEO of the Moscow trading company Horns and Hooves” are rolled up into one object. The complementary information contained in these nodes (“Moscow” as a sign of location and “trading” as a sign of an industry in this example) can be added to the semantic link graph for the specified company. In the next chapter, we will consider the graph of semantic relations in more detail.
Then, the text needs to be structured assequences of independent fragments , each of which usually contains a certain phrase based on a verb, and ideally should be folded into one node, which may include other nodes. We process the participial revolutions and other designs, and we turn the enumerations of class 1 objects, including already formed nodes, into special objects.
After that, for each fragment there is a search for suitable nodes based on objects of class 2. If several nodes are formed for one node-forming object, those remain that include the maximum number of objects in this fragment. Thus, on the basis of the type of surrounding objects, there is a transition from semantically wide objects like “going” to a node that has a clear semantic meaning. If during the initial processing several parallel objects arose at the place of homonyms, then after this processing only those objects that are included in the nodes remain (that is, they are semantically consistent with neighboring objects).
The last block of transformation into a semantic representation is the accounting of objects that are removed from node-forming objects in the text, but the meaning is implied. For example, “Moscow is warm, it is raining. It will be colder tomorrow and it will snow. ” A semantic analysis of the end of a sentence leaves the role of a geographical object vacant, and by a number of signs one can determine what suits Moscow.
When the nodes are fully formed, we attach attributes, numerical information and time periods to them. A typical situation is when the time period is indicated only in one place of the text, but refers to several nodes throughout the text. We have to use a special algorithm for the “distribution” of periods across all nodes where the “time period” is not enough based on their semantic value ..
Finally, in each document we define the main objects (what this document is about). In addition to the number of entries,
Having rich semantic information, you can build a fairly accurate measure of the semantic proximity of documents. We combine documents into a cluster when the measure exceeds the semantic proximity of a certain threshold. We form the semantic profiles of the clusters (the main objects of the cluster, they are usually searched for) and a network of semantic links between the clusters, allowing you to display a “cloud” of documents related in meaning to a specific document.
How semantic search works
The semantic search algorithm consists of the following main blocks:
Firstly, if the text query, then you need to convert it into a semantic representation . Differences from the above document processing algorithm are dictated, first of all, by the need for a very fast search query. Therefore, we do not form any nodes, but select one or several blocks consisting of a potentially node-forming object and a number of objects, which, based on their type and position in the request, can refer to this node-forming.
At the same time, several parallel combinations can be formed, in one of which at the next stage it is necessary to open combinations of the type “Moscow companies” through the knowledge base into a list of specific objects, but in the other it is not necessary.
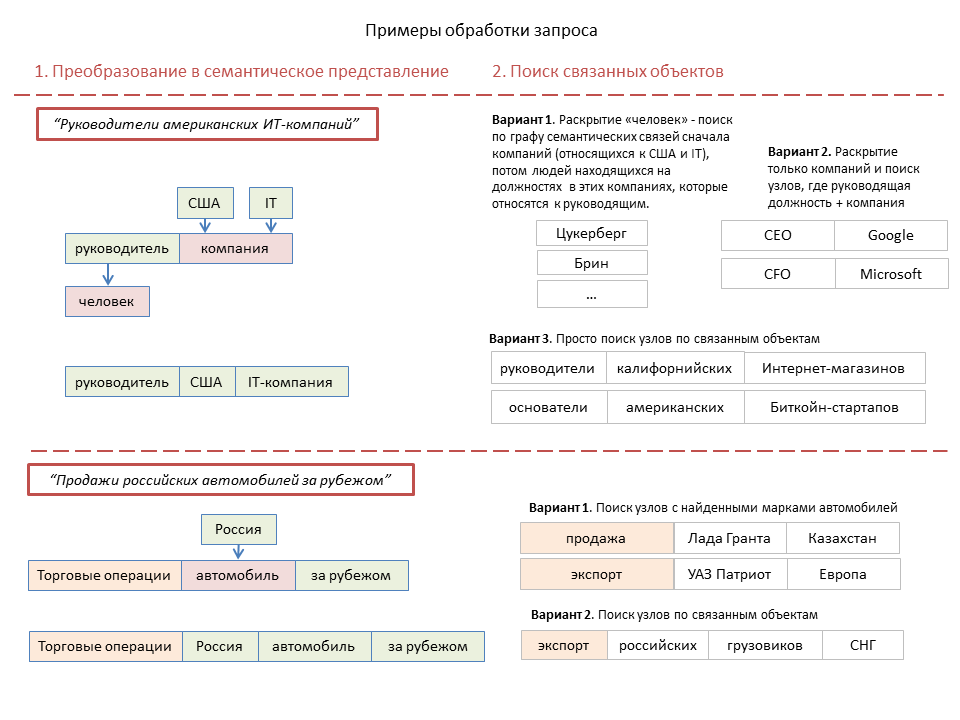
The next stage is the search for semantically related objects and nodes . For single class 1 objects, this is a selection of semantically related objects. In the case of the combination “action + objects”, a search is made for nodes that have the same or subordinate type of a node-forming object, and at the same time have objects that match or are semantically related to request objects. Also, combinations of the type “Moscow companies” or “European countries” are disclosed to the list of specific objects.
Here, a tree graph of semantic relationships between objects is used. The principle of its construction is simple - those "subordinate" objects that should be taken into account in the search for this object are attached to a specific object. For example, cities are subordinate to states, politicians are also subordinate to states, companies are subordinate to countries or cities, company leaders are subordinate to companies. For material objects, this graph is constructed from more general concepts to particular ones and partially coincides with the type graph.
For a number of objects, the number of "subordinates" can be very large and there is a need to choose the most significant. For this, a numerical coefficient of semantic connection is established between the elements of the graph, which is calculated based on the significance of the objects. For different types of objects, significance is determined differently, for example, for companies - based on economic indicators (turnover) or the number of employees, for geographical objects - according to the number of population.
Next, we look for simple objects and nodes that were obtained at the output of the previous stage in the object profiles of clusters . If few clusters are found, then a search is made in the object profiles of the documents.
If the search query contains attribute objects (characteristics), an additional filtering of the found documents is carried out by the presence of the required attributes tied to the found nodes. If the query has tokens for which there is no transition to semantic objects in the database, the semantic search is supplemented by a regular text search by lexemes.
Finally, we rank the found clusters and documents, form snippets and other elements of the output (links to related objects, etc.). The ranking is usually based on the degree of semantic connection between the request objects and the objects through which documents are found. Also, when ranking, a semantic profile of user interests can be taken into account.
Before starting the execution of a complex query, it is necessary to analyze the complexity of processing its various components, and to build the order of its execution in such a way that fewer intermediate objects or documents appear during processing. Therefore, the processing order may not always be as described above. Sometimes it may be advantageous to first find documents based on part of the request, and then filter the objects contained in them with respect to the remaining part of the request.
A separate algorithm is required for "broad" queries - "economy", "politics", "Russia", etc., which are characterized by a very large number of related objects and relevant documents.
For example, with the object "policy" are associated:
- Politicians - senior government officials or reputable experts
- Organizations - political parties, state bodies. authorities.
- A series of events and actions (elections, appointments to certain positions, activities of the State Duma, etc.).
In this case, we search by a relatively small number of relevant clusters with a high degree of significance, and rank them by the number of fresh documents in the cluster.
The main problems of implementing this approach and their solutions
Problem 1. The system must “know” all the objects that are found in the texts.
Possible solutions include the following:
- Application of a semantic system in an area where ignorance or identification errors of rare and little-known objects are not critical.
- Downloading objects from existing databases of structured information (DBpedia, Rosstat, etc.)
- The use of simple algorithms for automatic identification of the type of an object by qualifying words (for example, the movie “The Martian”), automatic identification of persons, as well as phrases that may be unknown to the system objects. With a low probability of error, objects are automatically entered into the database; in cases of a high probability of error, we use a manual verification system.
- To identify objects, we consider the possibility of using machine learning, teaching the system to sample already known objects and relying on the semantic type of objects surrounding an unknown object.
Problem 2. How to create templates for all possible semantic nodes.
In solving the similar problems of distributing objects according to the semantic roles of the English-language systems SRL (Semantic Role Labeling), machine learning algorithms are used using already labeled cases. As an action + role construction system, for example, Framenet is used. However, for the Russian language there is no suitable marked corpus. In addition, the implementation of this approach has its own problems, the discussion of which is beyond the scope of this short article.
In our approach, as described above, the distribution of objects by roles is based on the correspondence of the types of objects to the semantic restrictions established for roles in the node template. In total, the system now has about 1700 node templates, most of which were generated semi-automatically based on Framenet frames. However, the semantic restrictions for roles have to be set mainly by hand, at least for the most common nodes.
You can try the automatic formation of nodes using machine learning based on already formed ones. If there is a certain combination of objects and words (unknown to the system) with certain syntactic characteristics, then it is possible to form nodes similar to existing ones. Although you will still need to manually create templates for these nodes, the presence of such a node will still be better than its absence.
Problem 3. The high computational complexity of many semantic queries.
Some queries may include processing a very large number of intermediate objects and nodes and run slowly. This problem is completely solved by technical methods.
- Parallel query execution is required.
- Analysis of the complexity of the various ways to fulfill the request and choosing the best
- The use of numerical coefficients in the graph of semantic relationships allows you to limit the number of objects involved in the intermediate stages of query processing.
Recommended Reading
- A series of articles on Habr on technology ABBYY Compreno .
- Good review book: "Semantic Role Labeling", Martha Palmer, Daniel Gildea, and Nianwen Xue, 2010.
- Dipanjan Das, Desai Chen, André FT Martins, Nathan Schneider, Noah A. Smith (2014) Frame-Semantic Parsing .