Entertaining prologue # 3
So, community, please give me a chance to surprise you for the third time in Preda duschem decision, I used the python, thought here will draw the attention of experts and I just say, so why do it at all have the same regular expressions - made all there just will work, this our python can give and more speed.
The next topic of the article should be another task in turn, but no, I did not leave the first one, which can be done to get an even faster solution, since the victory on the site was crowned with another contest.
I wrote an implementation which on average was of this kind of speed, so there are 90 percent of the solutions that I did not notice that someone knows how to solve it even faster and he is silent , and having looked at the two previous articles did not say: oh, if this a question of productivity, then everything is clear - here the prologue does not fit. But with performance now everything is fine, imagine a program that will run on a weak gland is not possible, "in the end, why think about it?"
Call
Solve the problem even faster, was there a python and there was time, and is there a faster solution on python?
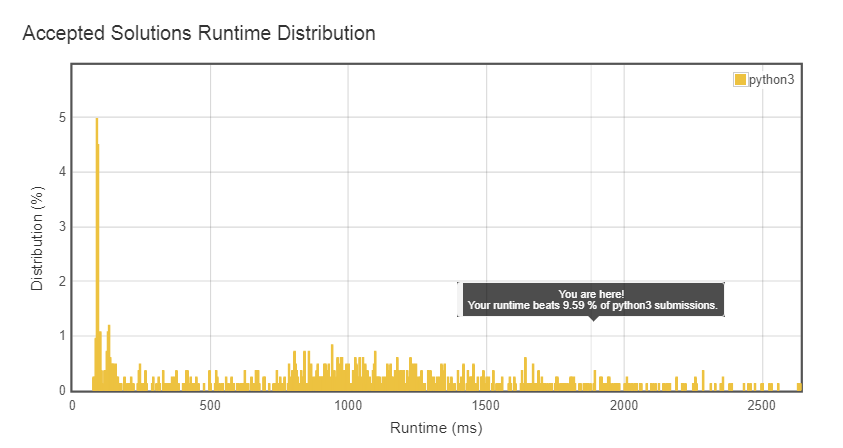
I’m told "Runtime: 2504 ms, faster than 1.55% of Python3 online submissions for Wildcard Matching."
I warn you, then there is a stream of thoughts online.
1 regular?
Maybe there is an option to write a faster program simply by using a regular expression.
Explicitly python can create a regular expression object that will check the input string and it will turn out to run right there, in the sandbox that is on the site for testing programs.
Just import re , I can make the import of such a module, it is interesting, we must try.
It is not easy to understand that creating a quick solution is not easy. We'll have to search a little, try and create an implementation like this:
1. to make an object of this regular
schedule ; 2. to slip a pattern corrected by it according to the rules of the regular library of the selected library;
3. to compare and the answer is ready
Voila:
import re
defisMatch(s,p):return re.match(s,pat_format(p))!=Nonedefpat_format(pat):
res=""for ch in pat:
if ch=='*':res+="(.)*"if ch=='?':res+="."else:
res+=ch
return resHere is a very short decision, as if correct.
I try to run it, but it was not there, it was not quite right, some option does not fit, it is necessary to test the conversion to a template.
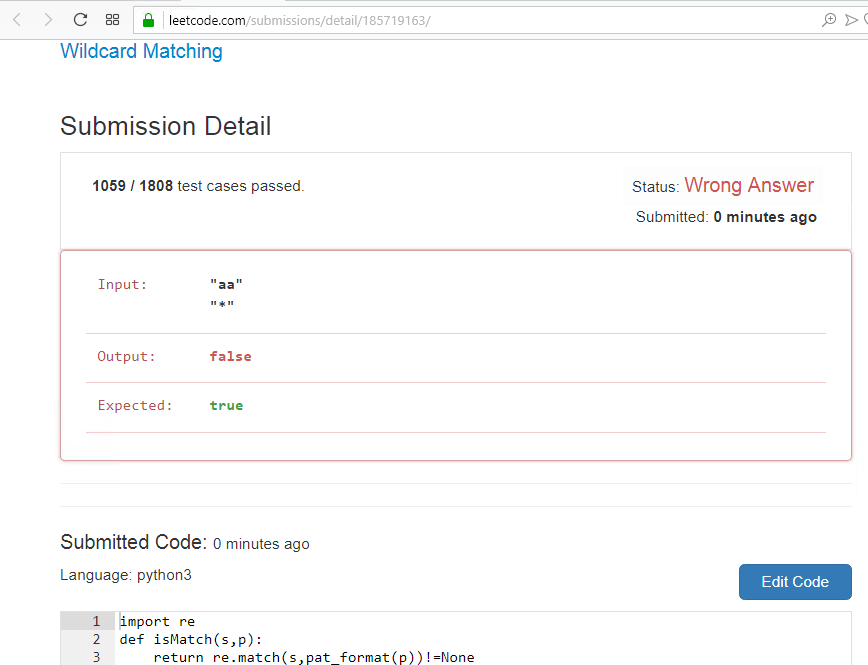
The truth is funny, I confused the pattern and the string, and the solutions came together, I passed 1058 tests and failed, only here.
Once again, on this site they are working carefully on the tests, as it turned out, all the previous ones are good, but here two main parameters are mixed up and this is manifested, here are the advantages of TDD ...
And on such a wonderful text, I still get an error
import re
defisMatch(s,p):return re.match(pat_format(p),s)==Nonedefpat_format(pat):
res=""for ch in pat:
if ch=='*':res+="(.)*"else:
if ch=='?':res+="."else:res+=ch
return res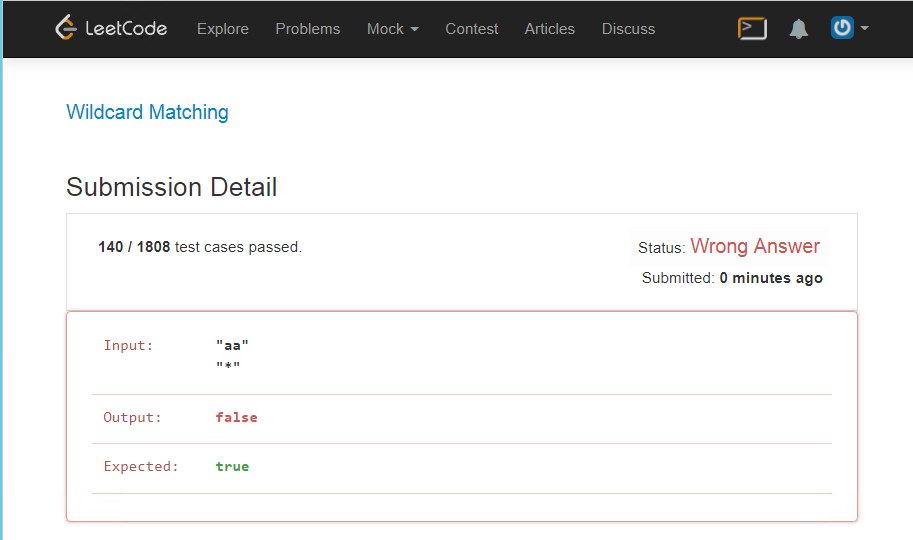
Complicated
It looks like this task was specially overlaid with tests, so that those who want to use regular expressions get more difficulties, I didn’t have any logical errors in the program before, and there are so many things to consider.
So, the regular expression matches and the first result should be equal to our string.
Victory?
It wasn’t easy to force him to use a regular expression, but the attempt failed, it’s not a simple solution to chemize regulars. The solution to the search in width worked faster.
This is the implementation
import re
defisMatch(s,p):
res=re.match(pat_format(p),s)
if res isNone: returnFalseelse: return res.group(0)==s
defpat_format(pat):
res=""for ch in pat:
if ch=='*':res+="(.)*"else:
if ch=='?':res+="."else:res+=ch
return resleads to this:
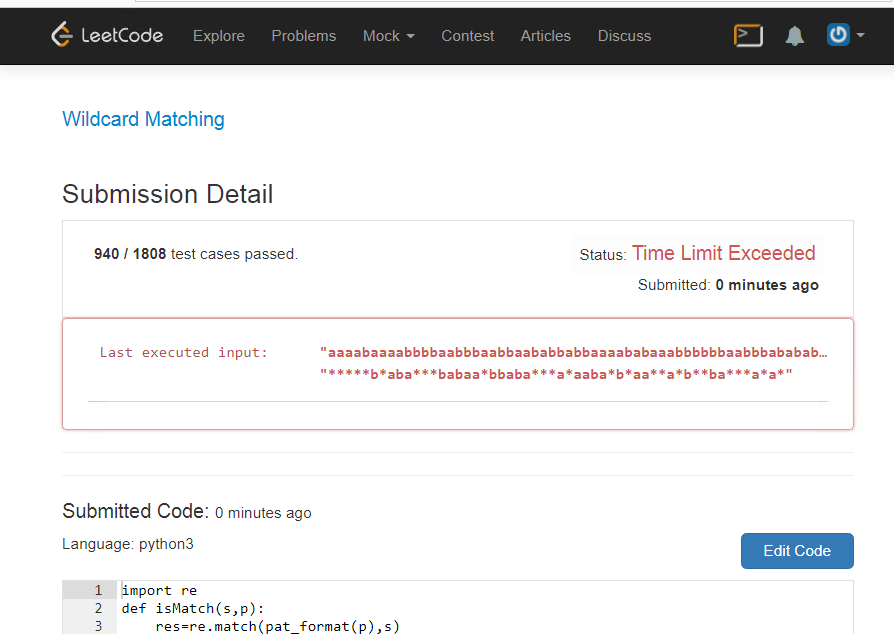
Appeal
Dear residents, try to check this out here, and Python makes it three , it cannot quickly accomplish this task:
import re
defisMatch(s,p):
res=re.match(pat_format(p),s)
if res isNone: returnFalseelse: return res[0]==s
defpat_format(pat):
res=""for ch in pat:
if ch=='*':res+="(.)*"else:
if ch=='?':res+="."else:res+=ch
return res
##test 940import time
pt=time.time()
print(isMatch("aaaabaaaabbbbaabbbaabbaababbabbaaaababaaabbbbbbaabbbabababbaaabaabaaaaaabbaabbbbaababbababaabbbaababbbba","*****b*aba***babaa*bbaba***a*aaba*b*aa**a*b**ba***a*a*"))
print(time.time()-pt)You can try at home. Miracles, it is not just long solved, it hangs, oooh.
Regular expressions as a subset of the declarative look limp performance?
The statement is strange, they are also present in all fashionable languages, does the performance have to be, but it’s not at all real that there’s not a finite state machine there ?, what happens in an endless cycle ??
Go
I read in one book, but that was a long time ago ... the newest language, Guo, works very quickly, but what about the regular expression?
I try and him:
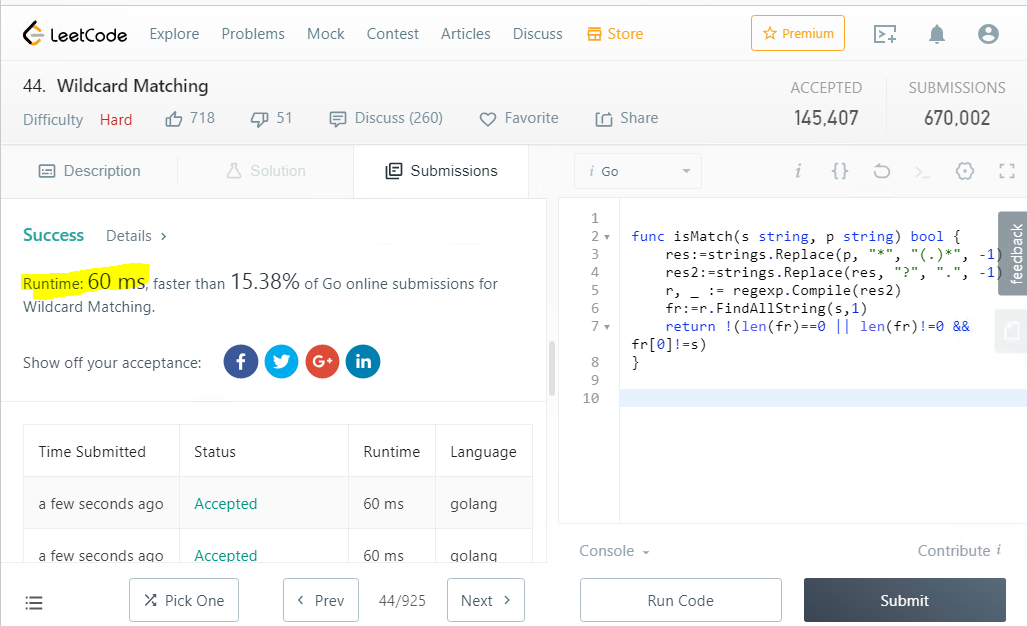
funcisMatch(s string, p string)bool {
res:=strings.Replace(p, "*", "(.)*", -1)
res2:=strings.Replace(res, "?", ".", -1)
r, _ := regexp.Compile(res2)
fr:=r.FindAllString(s,1)
return !(len(fr)==0 || len(fr)!=0 && fr[0]!=s)
}I admit, it was not easy to get such a concise text, the syntax there is not trivial, even with the knowledge of C, it's not easy to understand ...
This is a remarkable result, the speed really goes off scale, for a total of ~ 60 milliseconds, but surprisingly, this solution is faster than only 15% of the answers on the same site.
Where's the prologue
I find that this forgotten language for working with regular expressions provides us with a Perl Compatible Regular Expression library .
This is how it can be implemented, but pre-process the template string with a separate predicate.
pat([],[]).
pat(['*'|T],['.*'|Tpat]):-pat(T,Tpat),!.
pat(['?'|T],['.'|Tpat]):-pat(T,Tpat),!.
pat([Ch|T],[Ch|Tpat]):-pat(T,Tpat).
isMatch(S,P):-
atom_chars(P,Pstr),pat(Pstr,PatStr),!,
atomics_to_string(PatStr,Pat),
term_string(S,Str),
re_matchsub(Pat, Str, re_match{0:Str},[bol(true),anchored(true)]).
And the lead time is excellent:
isMatch(aa,a)->ok:0.08794403076171875/sec
isMatch(aa,*)->ok:0.0/sec
isMatch(cb,?a)->ok:0.0/sec
isMatch(adceb,*a*b)->ok:0.0/sec
isMatch(acdcb,a*c?b)->ok:0.0/sec
isMatch(aab,c*a*b)->ok:0.0/sec
isMatch(mississippi,m??*ss*?i*pi)->ok:0.0/sec
isMatch(abefcdgiescdfimde,ab*cd?i*de)->ok:0.0/sec
isMatch(zacabz,*a?b*)->ok:0.0/sec
isMatch(leetcode,*e*t?d*)->ok:0.0009980201721191406/sec
isMatch(aaaa,***a)->ok:0.0/sec
isMatch(b,*?*?*)->ok:0.0/sec
isMatch(aaabababaaabaababbbaaaabbbbbbabbbbabbbabbaabbababab,*ab***ba**b*b*aaab*b)->ok:0.26383304595947266/sec
isMatch(abbbbbbbaabbabaabaa,*****a*ab)->ok:0.0009961128234863281/sec
isMatch(babaaababaabababbbbbbaabaabbabababbaababbaaabbbaaab,***bba**a*bbba**aab**b)->ok:0.20287489891052246/secBUT, there are some restrictions, another test brought:
Not enough resources: match_limit
Goal (directive) failed: user:assert_are_equal(isMatch(aaaabaaaabbbbaabbbaabbaababbabbaaaababaaabbbbbbaabbbabababbaaabaabaaaaaabbaabbbbaababbababaabbbaababbbba,'*****b*aba***babaa*bbaba***a*aaba*b*aa**a*b**ba***a*a*'),false)As a conclusion
Total only questions left. You can realize everything, but speed is lame.
Transparent solutions are not effective?
Someone implemented declarative regular expressions, what mechanisms are there?
And how do you call such challenges, there is a task that can be solved, and where is it the perfect solution?