Impact analysis on the example of enterprise data warehouse infrastructure
In this article I want to talk about how you can solve the problem of impact analysis or impact analysis in a complex, multi-level infrastructure of a corporate data warehouse using the example of our DWH at Tinkoff Bank .

When working with DWH, everyone probably asked questions at least once:
The answer to this question is usually not easy, because you need to look at a dozen ETL processes, then get into the BI tool, find the reports you need, keep something in mind, remember that something is built by manual code there and all this translates into a big headache.
Even the most sometimes harmless change can affect, for example, a report that arrives in the mail to the chairman of the bank’s board every morning. I exaggerate a little, of course :)
Later in the article I will tell you how and with what help you can reduce headaches and quickly conduct impact analysis in the DWH infrastructure.
Before plunging into impact analysis, I will briefly describe what our DWH is like. In structure, our repository is more like Bill Inmon's Corporate Information Factory. There are many layers of data processing, target storefront groups and a normalized model represent the data warehouse presentation layer. All this works on MPP Greenplum DBMS . ETL storage building processes are developed at SAS Data Integration Studio . The bank uses SAP Business Object as a reporting platform. In front of the repository is ODS, implemented on Oracle DBMS. From my previous article about DataLake at Tinkoff Bank, we know that we are building ETLs on Hadoop on Informatica Big Data Edition.
As a rule, the task of analyzing the impact within one enterprise tool is not difficult. All tools have metadata and functionality to work with this metadata, such as, for example, getting a list of dependent objects from the selected object.
The whole complexity of impact analysis arises when the process goes beyond the scope of one tool. For example, in DWH, an environment consists of DBMS sources, DBH DBH, ETL, BI. Here, in order to reduce the headache, you need to be able to consolidate metadata from different tools and build dependencies between them. The task is new and there are industrial systems on the market to solve it.
It was important for us that such a system could build for us an entire complex tree, or rather a graph of our metadata, starting from Oracle tables in ODS and ending with reports in SAP (see Fig. 1).
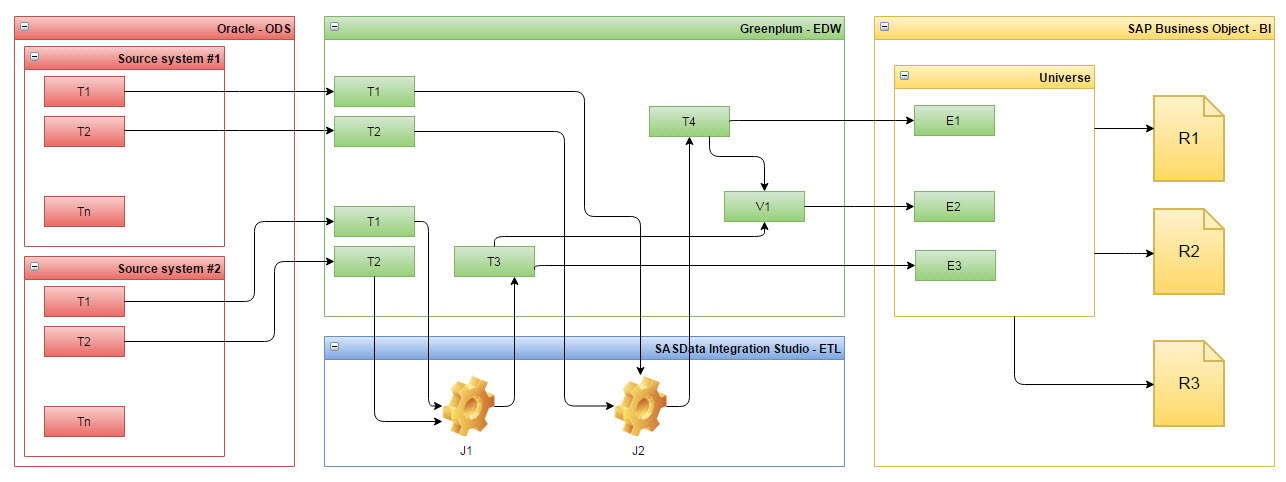
Fig. 1 Example of metadata dependencies from several systems, for example, systems in Tinkoff Bank.
The system was supposed to connect Greenplum objects with each other, as well as through SAS workstations, in which Greenplum tables act as data sources and receivers, and just connect the tables with the views built on them .
We chose Informatica Metadata Manager and successfully implemented the first metadata models at our place at Tinkoff Bank. Later in the article I will tell you how and what we learned to do using this tool.
Informatica Metadata Manager is essentially a large metadata repository that allows you to:
Now, in order and in more detail, about what the tool can do and how to prepare Informatica Metadata Manager.
The box with Informatica Metadata Manager comes with a certain set of models with which, if you have purchased a license, you can start working immediately after installing the product.
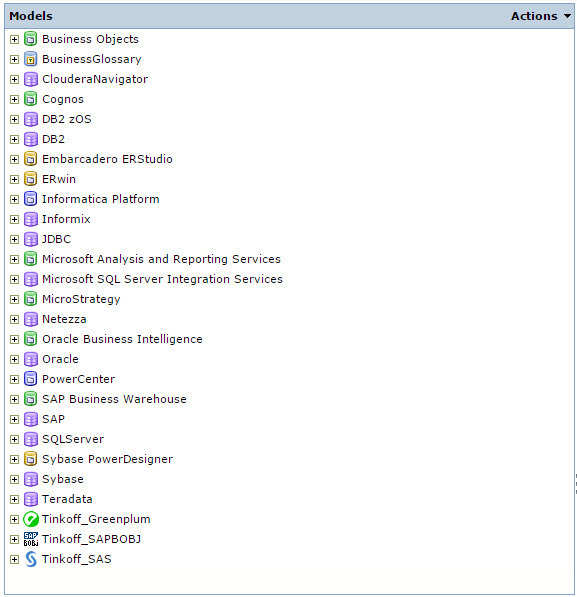
Fig. 2 Informatica Metadata Manager Models
In Figure 2 those models that do not start with the Tinkoff prefix go out of the box. A model in terms of Informatica Metadata Manager is a set of classes from which a certain hierarchy is built, which corresponds to the structure of the source metadata, i.e. some information system. For example, the Oracle DBMS metadata model in Informatica Metadata Manager is as follows, see Fig. 3. I think those who worked with Oracle DBMS in this hierarchy will see a lot of acquaintances from which they are used to working with.
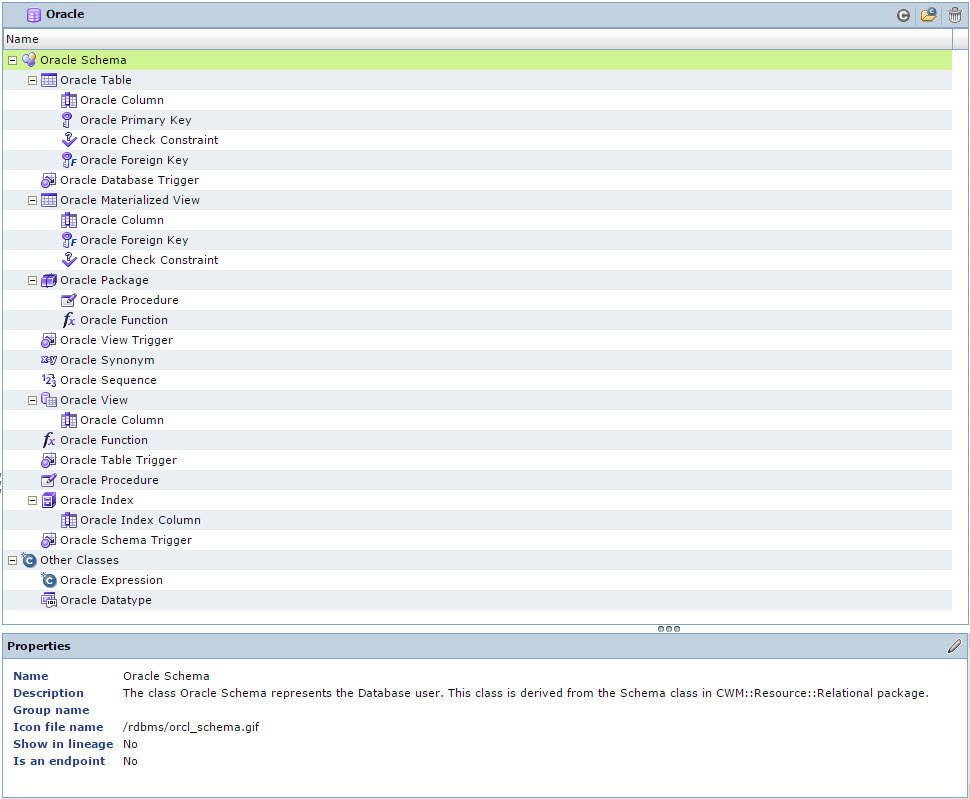
Fig. 3 Oracle DBMS metadata model The
Greenplum or SAS Data Integration Studio DBMS metadata models are not provided in the Informatica Metadata Manager, and we ourselves designed them for our tasks. It is very important to understand what problem the model should solve when you start working with a finished model or design your own. We got simple models (see Fig. 4 and Fig. 5), but at the same time, these models met our requirements. And our main requirement is to be able to build lineage from ODS tables that are in Oracle to reports that are built on universes in SAP Business Objects.
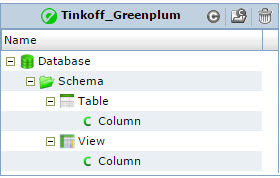
Fig. 4 Greenplum DBMS metadata model
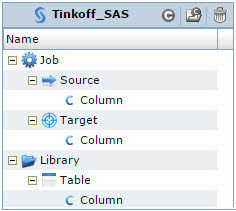
Fig. 5 SAS Data Integration Studio
metadata model Regarding the SAP Business Objects metadata model, a dilemma has arisen - to use a pre-configured model or to develop your own.
The finished model, or rather its first hierarchy level, looks like this - see. Fig. 6.
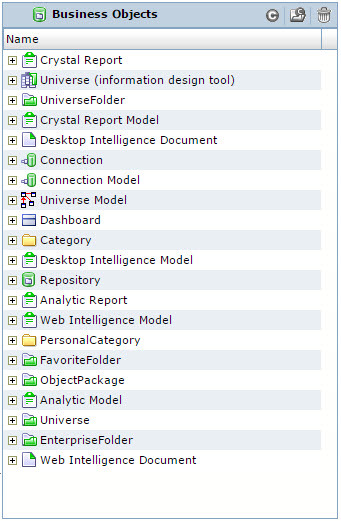
Fig. 6 Pre-configured Business Objects metadata model
Compared:
One criterion not in favor of its model was the fact that the metadata structure of SAP Business Objects was complex. But, for our audit of the BI platform, we use a third-party product - 360eyes , which we took as the source of SAP Business Objects metadata for Informatica Metadata Manager. The model turned out to be very simple, see Fig. 7, which met our stated requirements.
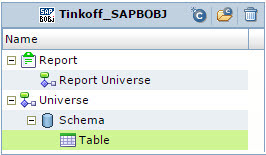
Fig. 7 SAP Business Objects Metadata Model
Models are created, now they need to be filled with metadata. The models that come in the box with Informatica Metadata Manager have their own pre-configured loaders that already know how to extract, for example, a list of tables and views from the Oracle DBMS dictionaries. For metadata models that you design yourself, the loader will have to be developed by yourself. But you shouldn’t be scared here, the process is quite transparent, and resembles the development of an ETL procedure for a clearly formulated TK. Based on your created model, Informatica Metadata Manager with a simple command will help you create a download template and now you have a set of CSV files that need to be filled with metadata of your system. Then it all depends on you and how much you know well and know how to work with the metadata of your systems. By the way, the process of getting metadata from your systems is probably
We wrote all the necessary code that we collected from pg_catalog Greenplum, from the SAS metadata and from the 360eyes repository, the data for the created loading templates and started the regular process. To update the metadata of Oracle, on which ODS runs, we used a pre-configured model (see. Fig. 3). Metadata in Informatica Metadata Manager is updated every night.
System metadata is regularly updated in the Informatica Metadata Manager repository, now you need to link the metadata objects of different systems to each other. For this, the Informatica Metadata Manager has the ability to write rules (Rule Set), the rules can work both within the model and between models. Rules are an XML file of simple structure:
The above correctly indicates that it is necessary to build a relationship within the SAPBOBJ model between objects of the "Universe" class and objects of the "Report Universe" class under the condition of equality of their name.
There are situations that metadata objects need to be linked together, but a rule cannot be developed for this relationship. A simple example: Representation “A” is built on table “B” and “C”. For such situations, Informatica Metadata Manager has the ability to load additional links, the so-called Enumerated Links. Enumerated Links is a CSV file in which the full paths are already written in the Informatica Metadata Manager repository to the two metadata objects that need to be linked. Using Enumerated Links, we build a relationship between tables and Greenplum views.
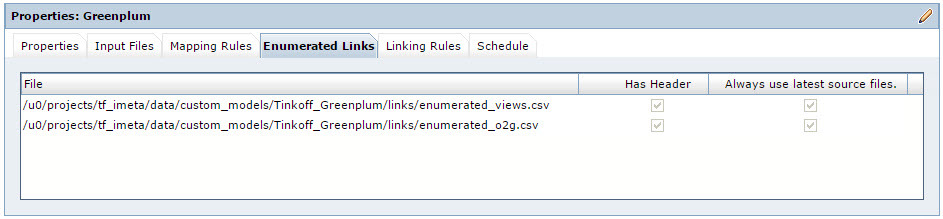
Fig. 8 Enumerated Links Properties
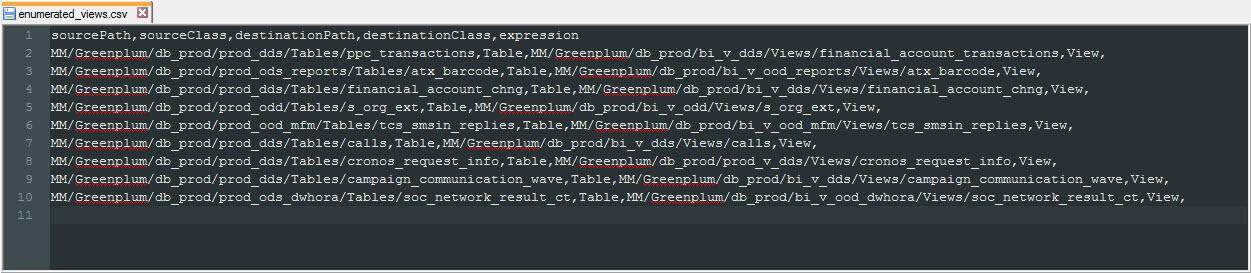
Fig. 9 CSV file for downloading Enumerated Links
In this case, we generate the CSV file for Enumerated Links ourselves, as well as the metadata for downloading, based on pg_catalog. Through Enumerated Links, in the Greenplum model, we associate objects of the "Table" class with objects of the "View" class. We form the connection by indicating the full path to the metadata object already in the Informatica Metadata Manager repository.
What did we get? The main thing that we got was the ability to build lineage on all metadata objects included in our DWH infrastructure, i.e. Perform impact analysis in two ways: Impact Upstream and Impact Downstream.
For example, we want to see what depends on the ODS table. We find the table we need, either in the model catalog, or using the search and run lineage on this table. We get such a beautiful picture, see Fig. 10. Here we see that a number of ETL processes on SAS depend on the selected table, as well as two Universe and seven reports in SAP Business Objects.
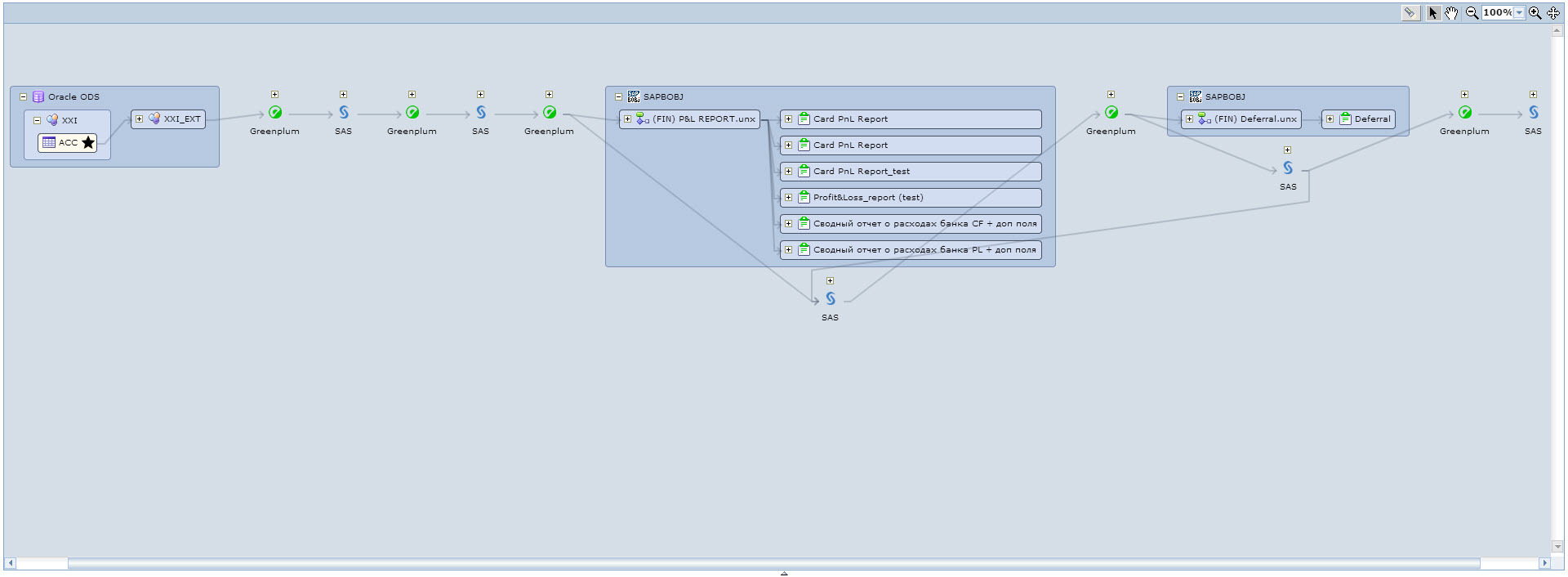
Fig. 10 Lineage from the ODS table
In the web interface, you can expand each area of the received lineage and from each object in the diagram you can start linage directly from this window.
Or, for example, we want to see the data of which tables are involved in the construction of the report. We find the necessary report and run lineage on it. We get the following beautiful picture, see Fig. 11. Here we see that the selected report is built on one Universe, which uses Greenplum tables from four schemes, which in turn are populated from ODS and some ETL processes on SAS.
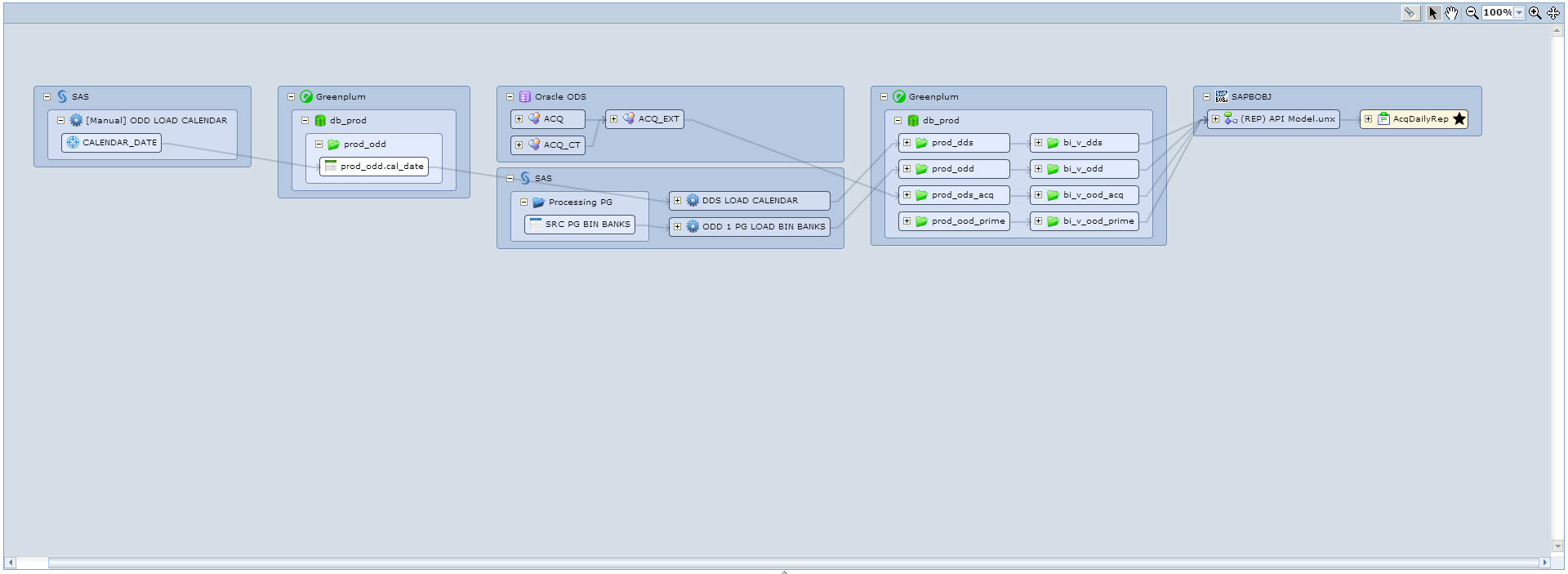
Fig. 11 Lineage from a report in SAP Business Objects
Each lineage result can be exported to Excel, which fully reflects all the dependencies on the selected metadata object.
We learned how to cook Informatica Metadata Manager. Then you only have to work, look for new options for its use, implement new models, connect new users.
What new models do we want to do:
Which users are connected and plan to connect:
Model Development:
Of the minuses that we encountered, this is a long construction of a full lineage (> 10 minutes) on objects with a large number of connections (> 1000). In general, Informatica Metadata Manager is a very flexible, easy-to-use tool and, in our opinion, is good at solving its tasks.
When working with DWH, everyone probably asked questions at least once:
- “What happens if you change the field in the table?”
- “What ETL processes will it affect?”
- “What reports will be affected?”
- “What business processes can be affected?”
The answer to this question is usually not easy, because you need to look at a dozen ETL processes, then get into the BI tool, find the reports you need, keep something in mind, remember that something is built by manual code there and all this translates into a big headache.
Even the most sometimes harmless change can affect, for example, a report that arrives in the mail to the chairman of the bank’s board every morning. I exaggerate a little, of course :)
Later in the article I will tell you how and with what help you can reduce headaches and quickly conduct impact analysis in the DWH infrastructure.
DWH at Tinkoff Bank
Before plunging into impact analysis, I will briefly describe what our DWH is like. In structure, our repository is more like Bill Inmon's Corporate Information Factory. There are many layers of data processing, target storefront groups and a normalized model represent the data warehouse presentation layer. All this works on MPP Greenplum DBMS . ETL storage building processes are developed at SAS Data Integration Studio . The bank uses SAP Business Object as a reporting platform. In front of the repository is ODS, implemented on Oracle DBMS. From my previous article about DataLake at Tinkoff Bank, we know that we are building ETLs on Hadoop on Informatica Big Data Edition.
Impact Analysis
As a rule, the task of analyzing the impact within one enterprise tool is not difficult. All tools have metadata and functionality to work with this metadata, such as, for example, getting a list of dependent objects from the selected object.
The whole complexity of impact analysis arises when the process goes beyond the scope of one tool. For example, in DWH, an environment consists of DBMS sources, DBH DBH, ETL, BI. Here, in order to reduce the headache, you need to be able to consolidate metadata from different tools and build dependencies between them. The task is new and there are industrial systems on the market to solve it.
It was important for us that such a system could build for us an entire complex tree, or rather a graph of our metadata, starting from Oracle tables in ODS and ending with reports in SAP (see Fig. 1).
Fig. 1 Example of metadata dependencies from several systems, for example, systems in Tinkoff Bank.
The system was supposed to connect Greenplum objects with each other, as well as through SAS workstations, in which Greenplum tables act as data sources and receivers, and just connect the tables with the views built on them .
We chose Informatica Metadata Manager and successfully implemented the first metadata models at our place at Tinkoff Bank. Later in the article I will tell you how and what we learned to do using this tool.
Informatica metadata manager
Informatica Metadata Manager is essentially a large metadata repository that allows you to:
- Model metadata, i.e. create metadata models, for example, DBMS, ETL tools, or even business applications
- Based on the models created or supplied in the kit, create metadata upload / update processes in your repository
- Create binding rules between metadata objects both within the model and between models
- Create relationships that cannot be matched by rules, both inside the model and cross-model
- Work in a visual web interface with the loaded metadata of your systems
Informatica Metadata Manager Models
Now, in order and in more detail, about what the tool can do and how to prepare Informatica Metadata Manager.
The box with Informatica Metadata Manager comes with a certain set of models with which, if you have purchased a license, you can start working immediately after installing the product.
Fig. 2 Informatica Metadata Manager Models
In Figure 2 those models that do not start with the Tinkoff prefix go out of the box. A model in terms of Informatica Metadata Manager is a set of classes from which a certain hierarchy is built, which corresponds to the structure of the source metadata, i.e. some information system. For example, the Oracle DBMS metadata model in Informatica Metadata Manager is as follows, see Fig. 3. I think those who worked with Oracle DBMS in this hierarchy will see a lot of acquaintances from which they are used to working with.
Fig. 3 Oracle DBMS metadata model The
Greenplum or SAS Data Integration Studio DBMS metadata models are not provided in the Informatica Metadata Manager, and we ourselves designed them for our tasks. It is very important to understand what problem the model should solve when you start working with a finished model or design your own. We got simple models (see Fig. 4 and Fig. 5), but at the same time, these models met our requirements. And our main requirement is to be able to build lineage from ODS tables that are in Oracle to reports that are built on universes in SAP Business Objects.
Fig. 4 Greenplum DBMS metadata model
Fig. 5 SAS Data Integration Studio
metadata model Regarding the SAP Business Objects metadata model, a dilemma has arisen - to use a pre-configured model or to develop your own.
The finished model, or rather its first hierarchy level, looks like this - see. Fig. 6.
Fig. 6 Pre-configured Business Objects metadata model
Compared:
| Criterion | Preset model | Own model |
|---|---|---|
| Completeness of the model | Excess | Optimal |
| Meets the originally formulated requirements | Probably answers | Answers |
| Cost of developing upload / update metadata | Is free | Depends on the complexity of the model and knowledge of the SAP Business Objects metadata structure |
| Model cost | License cost for metadata exchange options for SAP Business Objects | Is free |
One criterion not in favor of its model was the fact that the metadata structure of SAP Business Objects was complex. But, for our audit of the BI platform, we use a third-party product - 360eyes , which we took as the source of SAP Business Objects metadata for Informatica Metadata Manager. The model turned out to be very simple, see Fig. 7, which met our stated requirements.
Fig. 7 SAP Business Objects Metadata Model
Updating metadata in Informatica Metadata Manager
Models are created, now they need to be filled with metadata. The models that come in the box with Informatica Metadata Manager have their own pre-configured loaders that already know how to extract, for example, a list of tables and views from the Oracle DBMS dictionaries. For metadata models that you design yourself, the loader will have to be developed by yourself. But you shouldn’t be scared here, the process is quite transparent, and resembles the development of an ETL procedure for a clearly formulated TK. Based on your created model, Informatica Metadata Manager with a simple command will help you create a download template and now you have a set of CSV files that need to be filled with metadata of your system. Then it all depends on you and how much you know well and know how to work with the metadata of your systems. By the way, the process of getting metadata from your systems is probably
We wrote all the necessary code that we collected from pg_catalog Greenplum, from the SAS metadata and from the 360eyes repository, the data for the created loading templates and started the regular process. To update the metadata of Oracle, on which ODS runs, we used a pre-configured model (see. Fig. 3). Metadata in Informatica Metadata Manager is updated every night.
Binding rules in Informatica Metadata Manager
System metadata is regularly updated in the Informatica Metadata Manager repository, now you need to link the metadata objects of different systems to each other. For this, the Informatica Metadata Manager has the ability to write rules (Rule Set), the rules can work both within the model and between models. Rules are an XML file of simple structure:
The above correctly indicates that it is necessary to build a relationship within the SAPBOBJ model between objects of the "Universe" class and objects of the "Report Universe" class under the condition of equality of their name.
There are situations that metadata objects need to be linked together, but a rule cannot be developed for this relationship. A simple example: Representation “A” is built on table “B” and “C”. For such situations, Informatica Metadata Manager has the ability to load additional links, the so-called Enumerated Links. Enumerated Links is a CSV file in which the full paths are already written in the Informatica Metadata Manager repository to the two metadata objects that need to be linked. Using Enumerated Links, we build a relationship between tables and Greenplum views.
Fig. 8 Enumerated Links Properties
Fig. 9 CSV file for downloading Enumerated Links
In this case, we generate the CSV file for Enumerated Links ourselves, as well as the metadata for downloading, based on pg_catalog. Through Enumerated Links, in the Greenplum model, we associate objects of the "Table" class with objects of the "View" class. We form the connection by indicating the full path to the metadata object already in the Informatica Metadata Manager repository.
Impact Analysis in Informatica Metadata Manager
What did we get? The main thing that we got was the ability to build lineage on all metadata objects included in our DWH infrastructure, i.e. Perform impact analysis in two ways: Impact Upstream and Impact Downstream.
For example, we want to see what depends on the ODS table. We find the table we need, either in the model catalog, or using the search and run lineage on this table. We get such a beautiful picture, see Fig. 10. Here we see that a number of ETL processes on SAS depend on the selected table, as well as two Universe and seven reports in SAP Business Objects.
Fig. 10 Lineage from the ODS table
In the web interface, you can expand each area of the received lineage and from each object in the diagram you can start linage directly from this window.
Or, for example, we want to see the data of which tables are involved in the construction of the report. We find the necessary report and run lineage on it. We get the following beautiful picture, see Fig. 11. Here we see that the selected report is built on one Universe, which uses Greenplum tables from four schemes, which in turn are populated from ODS and some ETL processes on SAS.
Fig. 11 Lineage from a report in SAP Business Objects
Each lineage result can be exported to Excel, which fully reflects all the dependencies on the selected metadata object.
Results and plans for the future
We learned how to cook Informatica Metadata Manager. Then you only have to work, look for new options for its use, implement new models, connect new users.
What new models do we want to do:
- Banking systems sources
- Informatica Big Data Edition
- Hadoop (HDFS + Hive)
- Flume
Which users are connected and plan to connect:
- System Analysts DWH
- Owners of banking systems of sources
Model Development:
- Improve our SAP Business Objects model, add metadata objects such as measures and metrics
Of the minuses that we encountered, this is a long construction of a full lineage (> 10 minutes) on objects with a large number of connections (> 1000). In general, Informatica Metadata Manager is a very flexible, easy-to-use tool and, in our opinion, is good at solving its tasks.