Local number formatting speed
I. Objective
In one of the scripts, I ran into the need to format large numbers for readability . I found several recipes on how to divide the number into groups by rank , but doubts about performance were expressed in discussions. I decided to conduct several tests.
II. Solution options
Suppose we have a variable with a number.
var i = 100000;
You can turn its output into
100,000(or into 100 000, or into 100.000) in the following ways.1. Regex by regular expression
There are several options, this one seemed to me the most compact:
i.toString().replace( /\B(?=(?:\d{3})+$)/g, ',' );
2. Using an object Intl
Namely, the
format()constructor method NumberFormat. Two options are possible.but. By default:
var fn_undef = newIntl.NumberFormat();
fn_undef.format(i);
b. Forced locale:
var fn_en_US = newIntl.NumberFormat('en-US');
fn_en_US.format(i);
3. Using the method Number.toLocaleString()
This method has much in common with the previous one, as can be understood from the descriptions. Also consider two options.
but. By default:
i.toLocaleString();
b. Forced locale:
i.toLocaleString('en-US');
This method seems the shortest and most convenient, but in fact it turns out to be the most insidious.
III. Tests
Imagine that we need to display a table with a large number of formatted numbers, in which case the difference in the speed of the methods will be important. Let's try to test a cycle with hundreds of thousands of operations on several engines and in different runtime environments.
1. Node.js 4.1.0
Unfortunately, the locale
ru-RUis not supported in this version of Node.js (or I don’t know how to add its support), so for consistency I had to use the locale everywhere en-US. First, the script defines the variables and, for illustration, displays formatting in all ways (five identical results). Then five test cycles follow, showing elapsed time after each.
Code for Node.js
'use strict';
var i = 100000;
const fn_undef = newIntl.NumberFormat();
const fn_en_US = newIntl.NumberFormat('en-US');
console.log( i.toString().replace( /\B(?=(?:\d{3})+$)/g, ',' ) );
console.log( fn_undef.format(i) );
console.log( fn_en_US.format(i) );
console.log( i.toLocaleString() );
console.log( i.toLocaleString('en-US') );
var time = process.hrtime();
while (i-- > 0) {
i.toString().replace( /\B(?=(?:\d{3})+$)/g, ',' );
}
console.log(process.hrtime(time));
i = 100000;
time = process.hrtime();
while (i-- > 0) {
fn_undef.format(i);
}
console.log(process.hrtime(time));
i = 100000;
time = process.hrtime();
while (i-- > 0) {
fn_en_US.format(i);
}
console.log(process.hrtime(time));
i = 100000;
time = process.hrtime();
while (i-- > 0) {
i.toLocaleString();
}
console.log(process.hrtime(time));
i = 100000;
time = process.hrtime();
while (i-- > 0) {
i.toLocaleString('en-US');
}
console.log(process.hrtime(time));
The function for profiling
hrtimeproduces a time difference as a tuple of two numbers in an array: the number of seconds and nanoseconds. Example output (excluding initial illustrations):
[ 0, 64840650 ]
[ 0, 473762595 ]
[ 0, 470775460 ]
[ 0, 514655925 ]
[ 14, 120328524 ]
As we see, the first option is the fastest. The next two are almost no different from each other, but slower than the first one by an order of magnitude. The fourth way is even a little slower. But the latter is abnormally slow.
Here is manifested a significant difference between the methods
Intl.NumberFormat.format()and Number.toLocaleString(): the first we once Asking locale in constructor, in the second we ask it in each call. When determining the locale, the interpreter performs quite resource-intensive operations described in the help . In the first case, he performs them once and for the entire duration of the formatter, in the second case, he produces them anew one hundred thousand times. A subtle difference in code, but very significant for runtime.We can draw a preliminary conclusion: if you know the desired locale in advance, it is better to use regular expression replacement. If the locale is unpredictable, it is better to use the method
Intl.NumberFormat.format()without force setting the locale. If we test this code (replacing the profiling function) in browsers, we will see that for them this conclusion is correct.
2. Browsers
Run this code in the consoles.
Code for browsers
var i = 100000;
const fn_undef = newIntl.NumberFormat();
const fn_en_US = newIntl.NumberFormat('en-US');
console.log( i.toString().replace( /\B(?=(?:\d{3})+$)/g, ',' ) );
console.log( fn_undef.format(i) );
console.log( fn_en_US.format(i) );
console.log( i.toLocaleString() );
console.log( i.toLocaleString('en-US') );
var time = Date.now();
while (i-- > 0) {
i.toString().replace( /\B(?=(?:\d{3})+$)/g, ',' );
}
console.log(Date.now() - time);
i = 100000;
time = Date.now();
while (i-- > 0) {
fn_undef.format(i);
}
console.log(Date.now() - time);
i = 100000;
time = Date.now();
while (i-- > 0) {
fn_en_US.format(i);
}
console.log(Date.now() - time);
i = 100000;
time = Date.now();
while (i-- > 0) {
i.toLocaleString();
}
console.log(Date.now() - time);
i = 100000;
time = Date.now();
while (i-- > 0) {
i.toLocaleString('en-US');
}
console.log(Date.now() - time);
Now you have to compare the milliseconds, but it will be quite clear.
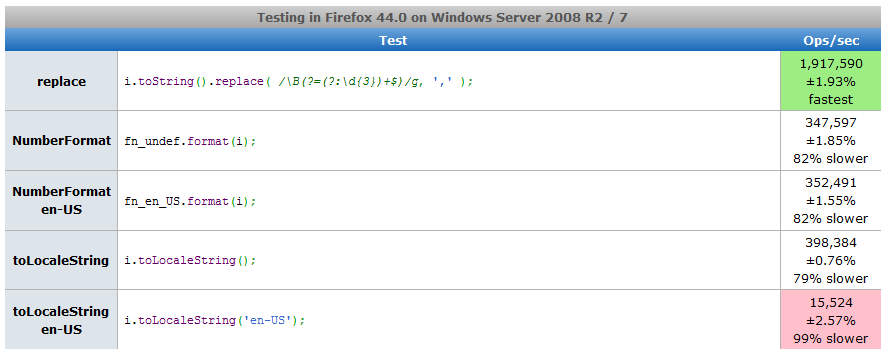
but. Chrome 47.0.2515.0
8054352860418699b. Firefox 44.0a1
2187247304397177at. IE 11.0.14
2153283553262837384We see that Chrome in the latter method lagged behind Node.js, Firefox was twice as fast in the same problematic place, and in IE 11 the penultimate method was much closer to the latter in speed (i.e., omitting the locale does not save this option much IE).
Finally, for greater objectivity and for the convenience of those wishing to check, I added a page on jsperf.com . My latest edition of the tests produced the following:
Screenshots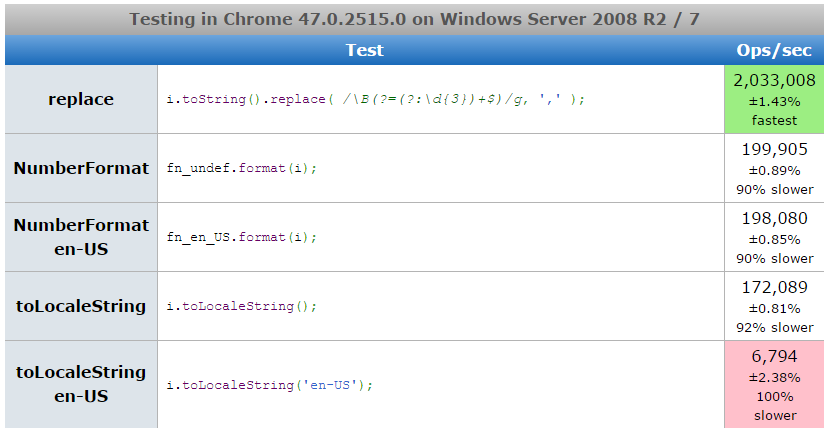

The code there is simplified, because the site takes on the main work of running the cycles. You can experiment by editing the code and adding your own test variants.
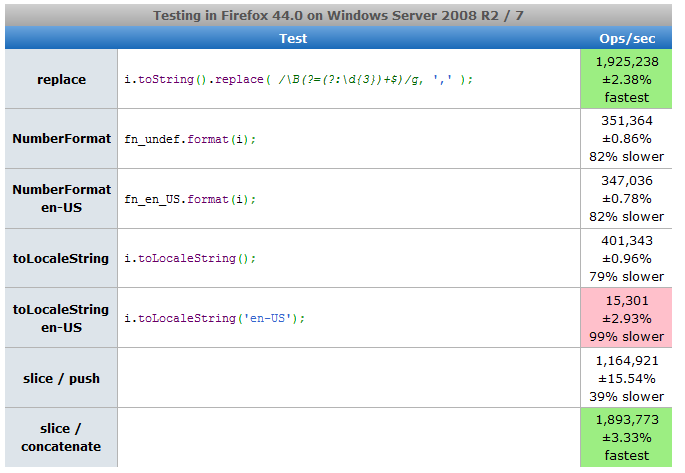
PS Two more ways were added in the comments. They, although significantly more voluminous in code, in many test cases are even faster than regular expression replacements (tests on Node and in browser consoles: one , two ). Added a test page with all seven ways . She gives me:
Screenshots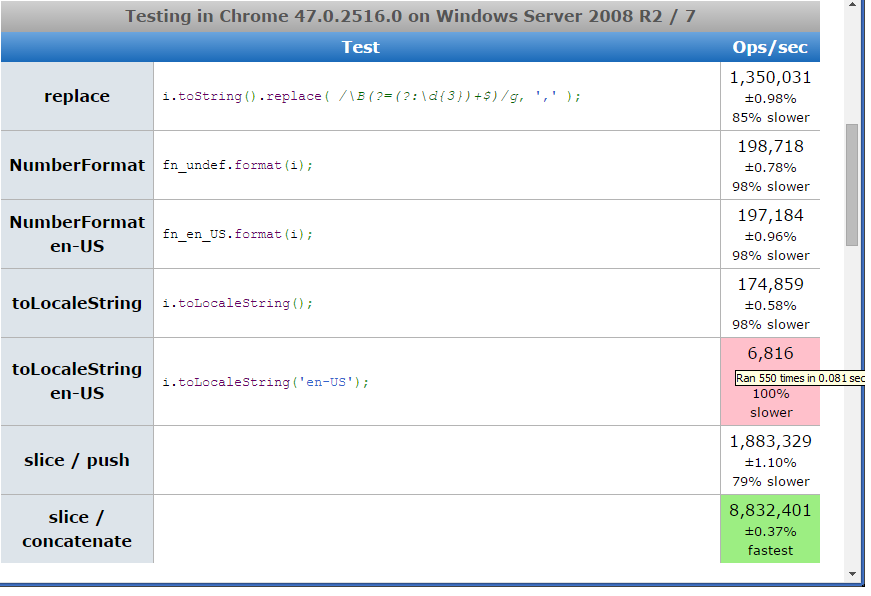
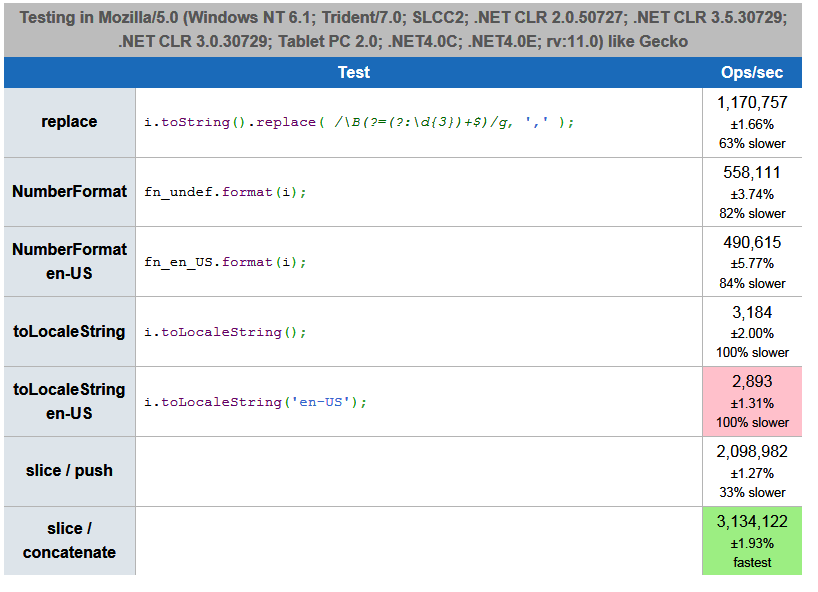
PS 2 Two more functions appeared, made new tests ( one , two ) and added them to jsperf.com. At the same time, I slightly corrected the code with the regular expression, taking out compilation from the loop: even though it is said on MDN that literal regular expressions are not recompiled in the loops, I’m not sure if they are defined outside the loop or even inside (in Perl an additional flag that prohibits recompiling a regular expression that does not change in the loop, I don’t know how JS behaves in these cases). In any case, tests in Node.js and browsers showed a slight increase in speed when taking the regular out of the loop. According to the results of new tests, out of nine methods, the new four, “mathematical”, definitely win, but at the same time, different “mathematical” methods win in each browser. My new results:
Screenshots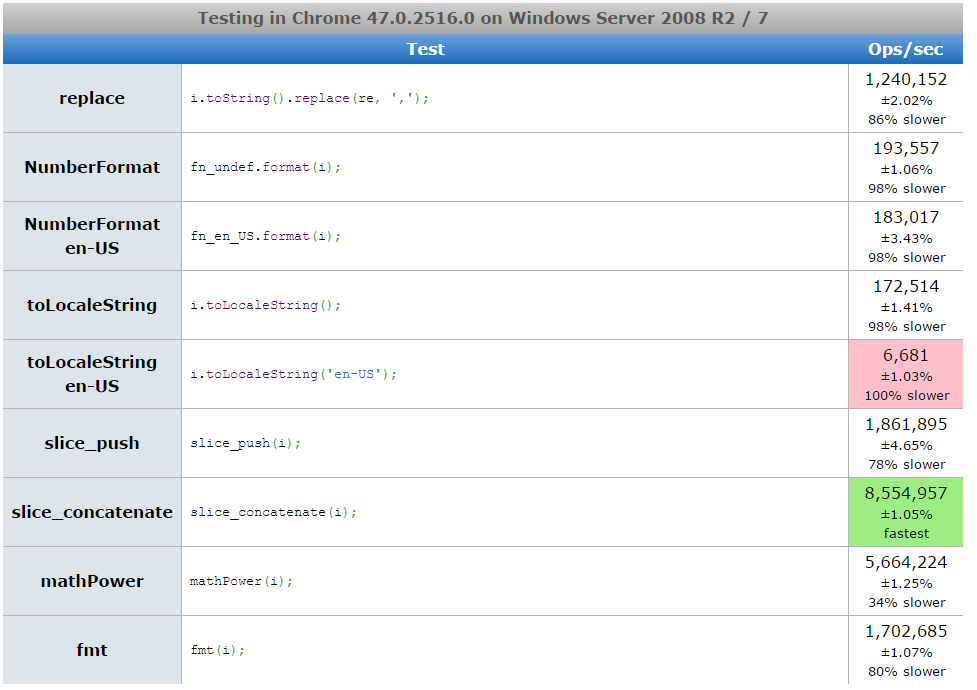
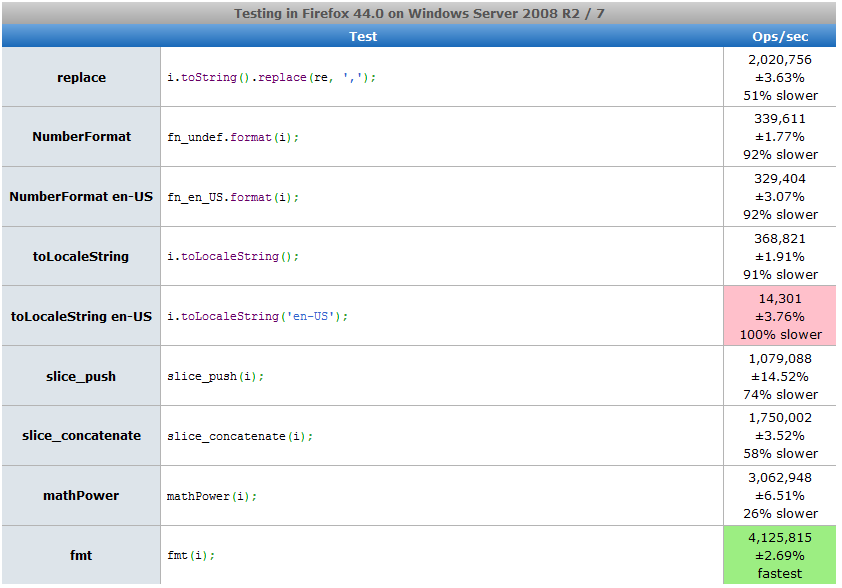
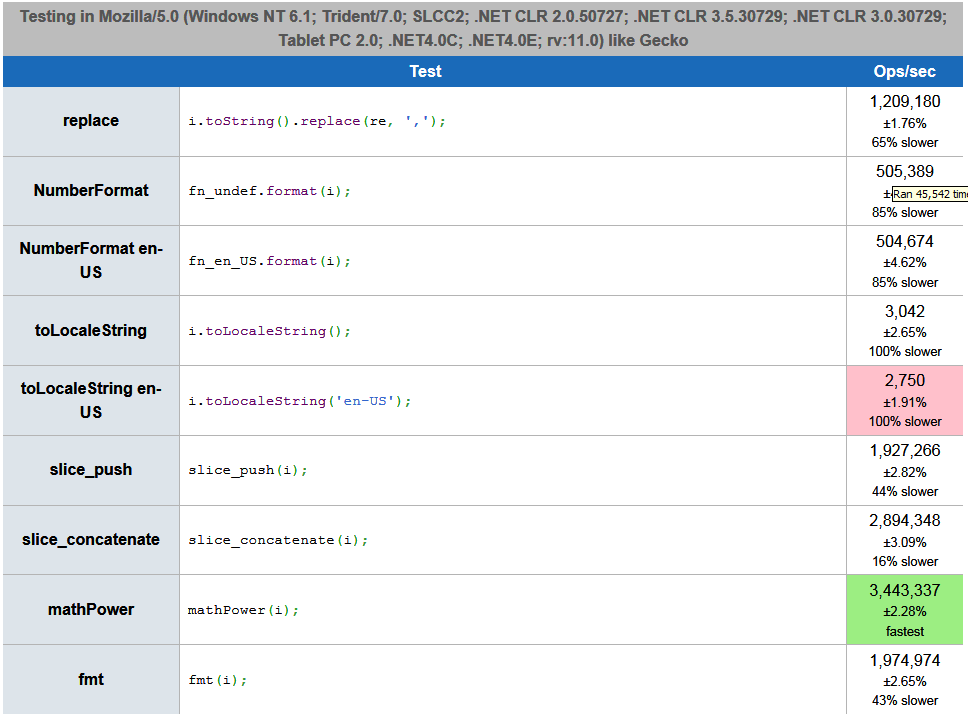
PS 3 Another +1 function: a new table (already ten options), my indicators .
PS 4 I decided to add the most linear option - iterating over all possible integer lengths in a safe range
Number.MAX_SAFE_INTEGERwith concatenating the string character by character and inserting a separator in the right places. This is the eleventh option (function exhaustion()), and it turned out to be quite fast, and even took first place in tests on Firefox.