Storage of hierarchical structures. Symbiosis of Closure Table and Adjacency List
When we are faced with the task of storing and managing hierarchical data structures, we always have to choose from a rather limited set of patterns. In order to find the most suitable template, it is necessary to analyze the features of each method of data storage and processing and evaluate them taking into account the tasks and specifics of the DBMS used.
Suppose there is a task, to provide users with the opportunity to leave comments on publications. Comments should have a tree structure, users should be able to leave one or more comments on the post, and also respond to any comments of other users. That is, we need a comment system similar to what we can see on Habrahabr. For some reason, ready-made solutions are not suitable for us, for example, because an additional very complex business logic is supposed to be integrated into the comment system.
Our goal is to develop our implementation, taking into account the requirements of our application.
So, consider the well-known ways of storing and working with trees. There are not so many of them:
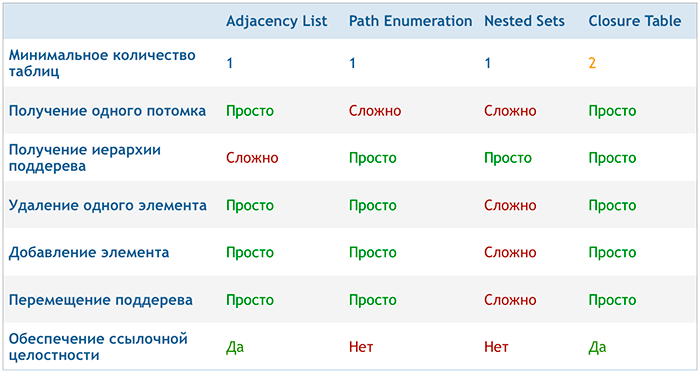
Details of the implementation of these patterns are well considered in the presentation of Bill Karwin .
The peculiarity of the Adjacency List method is that without the support of recursive DBMS queries, it is impossible to extract an arbitrary part of the hierarchy with one simple query. Therefore, in the context of using MySQL, this option does not suit us at all.
The “Path Enumeration” method (or as it is also called “Materialized Path”) obviously does not suit us either, due to the low performance of SQL SELECT queries, since it is assumed to use the LIKE operator and search by templates of the form: '1/2/3 /4%'. Storing a certain set in the form of a string with delimiters is hardly appropriate in the world of relational databases.
Perhaps the most interesting pattern for working with tree structures is Nested Sets. It may well be used for our task, but its implementation is rather complicated and it does not ensure data integrity. Failure to insert a new item into the hierarchy or when moving a subtree from one place to another can create big problems. The need to recalculate and change the values of part of the left and right indices of subtree elements when adding a new element is, without a doubt, a significant drawback of Nested Sets.
The last Closure Table method, based on our requirements, could be the best choice if it were not for one “but” - the lack of an easy way to build a sorted tree from a flat list of links received by the query.
Let's take a closer look at this template for working with tree data structures.
The connection diagram of the elements of the Closure Table tree is as follows:

Suppose we have a hierarchy of comments that corresponds to the above connection scheme: Comments
table: CommentsTree

table:

You can get a list of all the elements of the part of the tree that we need with the following query (extract the tree starting from ` commentsTree`.`idAncestor` = 1):
As a result, we get:

Everything is simple! But the extracted rows need to be converted into a sorted tree hierarchy. That is what we need. Alas, the data to convert this set into the form we need is not enough.
How do we solve this problem?
There is a rather original way with which you can get a sorted tree hierarchy from a database right away, with just one query. Well-known developer Bill Karwin proposed a very elegant option for solving the problem of extracting a sorted tree:
As a result, we get what we need:

But, as it is not difficult to notice, this method will only work correctly if the length of the idAncestor identifiers for all lines that meet the query condition is the same. Pay attention to the following fragment of the SQL query: “GROUP_CONCAT (tableStructure.idAncestor ORDER BY tableStructure.level DESC) AS structure”. Sorting strings containing the sets “12,14,28” and “13,119,12” will be incorrect from the point of view of our task. That is, if all the identifiers in the requested part of the tree are the same length, then the sorting is correct, and if this is not so, then the structure of the tree will be violated. You can reduce the number of incorrect sorts by setting the origin of identifiers from a large integer, for example, 1,000,000, by specifying AUTO_INCREMENT = 1000000 in the SQL query when creating the table.
In order to completely get rid of this problem, you can specify the ZEROFILL parameter for the idAncestor identifier column, in which case the DBMS will automatically add the UNSIGNED attribute and the identifiers will look something like this: 0000000004, 0000000005, 0000000194.
For some tasks, without a doubt, you can use this way. But let's still try to avoid using two JOINs when working with two tables, the GROUP_CONCAT () function, and even the ZEROFILL parameter.
Let's take another look at the Closure Table method. In the flat list of links of the hierarchical structure, which we receive with just one query, we obviously lack information on the connection of each element with its parent, so that we can build a sorted tree. Therefore, let's add the idNearestAncestor field to the commentsTree table and save the link to the element that is the closest ancestor there.
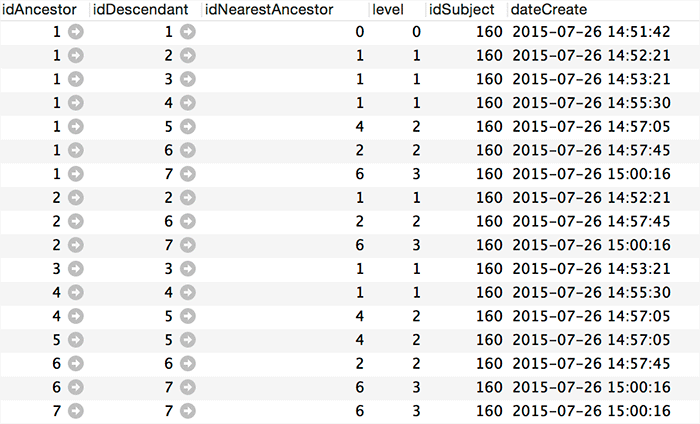
Thus, we got a symbiosis of the two methods “Closure Table” and “Adjacency List”. Now forming a properly sorted hierarchical structure is a trivial task. And most importantly, we found a solution that fully meets the requirements.
With the following query we will get the data necessary for building the tree:
The “Closure Table” template is often criticized for the fact that it is necessary to store in the database the connection of each element of the tree with all its ancestors, as well as the link of each element to itself. The deeper the element is in the hierarchy, the more records in the table need to be made. Obviously, adding new elements to the end of a deep tree hierarchy will be less effective than inserting elements near the root of the tree. In addition, it is worth noting that for storing trees, the Closure Table method requires more space in the database than any other method.
In order to objectively evaluate the significance of these comments, they should be considered in the context of the specifics of a real project. For example, performance degradation when adding a new item to the two-tailed or thousandth level may be insignificant or non-critical for the application to work, or, even more likely, such a situation will never happen at all. As a rule, in real life there is no need for hierarchical structures of great nesting. In addition, in most cases, the fundamental parameter is the speed of data extraction, not recording. The amount of disk space that the tree structure may require is hardly worth considering, as other consumers of this resource are much more significant, for example, logging site visitors.
An example of my implementation of a tree comment system based on the "Closure Table" and "Adjacency List" methods on github.
Materials used
Suppose there is a task, to provide users with the opportunity to leave comments on publications. Comments should have a tree structure, users should be able to leave one or more comments on the post, and also respond to any comments of other users. That is, we need a comment system similar to what we can see on Habrahabr. For some reason, ready-made solutions are not suitable for us, for example, because an additional very complex business logic is supposed to be integrated into the comment system.
Our goal is to develop our implementation, taking into account the requirements of our application.
What is important to us?
- Minimize the number of database queries. In particular, a single query should be sufficient to retrieve the comment thread.
- To get high performance, therefore, database queries, especially for reading, should be simple and execute quickly even with a large amount of data.
- Store comment text and hierarchical tree structure in different tables.
- To be able to sort the comments extracted from the database so that as a result they can be displayed in a natural form as a tree hierarchical structure or, even better, to immediately extract the sorted tree from the database.
- Control the depth of nesting of comments.
- Ensure data integrity.
- Take into account the specifics of MySQL. As you know, this DBMS does not support recursive queries. Recursion in this DBMS is possible only in stored procedures with nesting restrictions - no more than 255 levels.
- The requirements are quite reasonable and relevant for many projects.
So, consider the well-known ways of storing and working with trees. There are not so many of them:
Details of the implementation of these patterns are well considered in the presentation of Bill Karwin .
The peculiarity of the Adjacency List method is that without the support of recursive DBMS queries, it is impossible to extract an arbitrary part of the hierarchy with one simple query. Therefore, in the context of using MySQL, this option does not suit us at all.
The “Path Enumeration” method (or as it is also called “Materialized Path”) obviously does not suit us either, due to the low performance of SQL SELECT queries, since it is assumed to use the LIKE operator and search by templates of the form: '1/2/3 /4%'. Storing a certain set in the form of a string with delimiters is hardly appropriate in the world of relational databases.
Perhaps the most interesting pattern for working with tree structures is Nested Sets. It may well be used for our task, but its implementation is rather complicated and it does not ensure data integrity. Failure to insert a new item into the hierarchy or when moving a subtree from one place to another can create big problems. The need to recalculate and change the values of part of the left and right indices of subtree elements when adding a new element is, without a doubt, a significant drawback of Nested Sets.
The last Closure Table method, based on our requirements, could be the best choice if it were not for one “but” - the lack of an easy way to build a sorted tree from a flat list of links received by the query.
Let's take a closer look at this template for working with tree data structures.
The connection diagram of the elements of the Closure Table tree is as follows:
Suppose we have a hierarchy of comments that corresponds to the above connection scheme: Comments
table: CommentsTree
table:
You can get a list of all the elements of the part of the tree that we need with the following query (extract the tree starting from ` commentsTree`.`idAncestor` = 1):
SELECT
`tableData`.`idEntry`,
`tableData`.`content`,
`tableTree`.`idAncestor`,
`tableTree`.`idDescendant`,
`tableTree`.`level`,
`tableTree`.`idSubject`
FROM `comments` AS `tableData`
JOIN `commentsTree` AS `tableTree`
ON `tableData`.`idEntry` = `tableTree`.`idDescendant`
WHERE `tableTree`.`idAncestor` = 1
As a result, we get:
Everything is simple! But the extracted rows need to be converted into a sorted tree hierarchy. That is what we need. Alas, the data to convert this set into the form we need is not enough.
How do we solve this problem?
Option 1. Make the DBMS sort the tree
There is a rather original way with which you can get a sorted tree hierarchy from a database right away, with just one query. Well-known developer Bill Karwin proposed a very elegant option for solving the problem of extracting a sorted tree:
SELECT
`tableData`.`idEntry`,
`tableData`.`content`,
`tableTree`.`level`,
`tableTree`.`idAncestor`,
`tableTree`.`idDescendant`,
GROUP_CONCAT(`tableStructure`.`idAncestor`) AS `structure`
FROM
`comments` AS `tableData`
JOIN `commentsTree` AS `tableTree`
ON `tableData`.`idEntry` = `tableTree`.`idDescendant`
JOIN `commentsTree` AS `tableStructure`
ON `tableStructure`.`idDescendant` = `tableTree`.`idDescendant`
WHERE `tableTree`.`idAncestor` = 1
GROUP BY `tableData`.`idEntry`
ORDER BY `structure`
As a result, we get what we need:
But, as it is not difficult to notice, this method will only work correctly if the length of the idAncestor identifiers for all lines that meet the query condition is the same. Pay attention to the following fragment of the SQL query: “GROUP_CONCAT (tableStructure.idAncestor ORDER BY tableStructure.level DESC) AS structure”. Sorting strings containing the sets “12,14,28” and “13,119,12” will be incorrect from the point of view of our task. That is, if all the identifiers in the requested part of the tree are the same length, then the sorting is correct, and if this is not so, then the structure of the tree will be violated. You can reduce the number of incorrect sorts by setting the origin of identifiers from a large integer, for example, 1,000,000, by specifying AUTO_INCREMENT = 1000000 in the SQL query when creating the table.
In order to completely get rid of this problem, you can specify the ZEROFILL parameter for the idAncestor identifier column, in which case the DBMS will automatically add the UNSIGNED attribute and the identifiers will look something like this: 0000000004, 0000000005, 0000000194.
For some tasks, without a doubt, you can use this way. But let's still try to avoid using two JOINs when working with two tables, the GROUP_CONCAT () function, and even the ZEROFILL parameter.
Option 2. The symbiosis of the two methods “Closure Table” and “Adjacency List”
Let's take another look at the Closure Table method. In the flat list of links of the hierarchical structure, which we receive with just one query, we obviously lack information on the connection of each element with its parent, so that we can build a sorted tree. Therefore, let's add the idNearestAncestor field to the commentsTree table and save the link to the element that is the closest ancestor there.
Thus, we got a symbiosis of the two methods “Closure Table” and “Adjacency List”. Now forming a properly sorted hierarchical structure is a trivial task. And most importantly, we found a solution that fully meets the requirements.
With the following query we will get the data necessary for building the tree:
SELECT
`tableData`.`idEntry`,
`tableData`.`content`,
`tableTree`.`idAncestor`,
`tableTree`.`idDescendant`,
`tableTree`.`idNearestAncestor`,
`tableTree`.`level`,
`tableTree`.`idSubject`
FROM `comments` AS `tableData`
JOIN `commentsTree` AS `tableTree`
ON `tableData`.`idEntry` = `tableTree`.`idDescendant`
WHERE `tableTree`.`idAncestor` = 1
Criticism of the Closure Table
The “Closure Table” template is often criticized for the fact that it is necessary to store in the database the connection of each element of the tree with all its ancestors, as well as the link of each element to itself. The deeper the element is in the hierarchy, the more records in the table need to be made. Obviously, adding new elements to the end of a deep tree hierarchy will be less effective than inserting elements near the root of the tree. In addition, it is worth noting that for storing trees, the Closure Table method requires more space in the database than any other method.
In order to objectively evaluate the significance of these comments, they should be considered in the context of the specifics of a real project. For example, performance degradation when adding a new item to the two-tailed or thousandth level may be insignificant or non-critical for the application to work, or, even more likely, such a situation will never happen at all. As a rule, in real life there is no need for hierarchical structures of great nesting. In addition, in most cases, the fundamental parameter is the speed of data extraction, not recording. The amount of disk space that the tree structure may require is hardly worth considering, as other consumers of this resource are much more significant, for example, logging site visitors.
An example of my implementation of a tree comment system based on the "Closure Table" and "Adjacency List" methods on github.
Materials used
- Presentation of Bill Karwin. http://www.slideshare.net/billkarwin/models-for-hierarchical-data
- A discussion of sorting trees on stackoverflow. http://stackoverflow.com/questions/8252323/mysql-closure-table-hierarchical-database-how-to-pull-information-out-in-the-c , http://stackoverflow.com/questions/192220/ what-is-the-most-efficient-elegant-way-to-parse-a-flat-table-into-a-tree
- MySQL Documentation