The architecture of the meta-server mobile online shooter Tacticool
Another report from Pixonic DevGAMM Talks - this time from our colleagues from PanzerDog. Lead Software Engineer of the company Pavel Platto dismantled the game's meta-server with a service-oriented architecture, told what solutions and technologies were chosen, what and how they scale, and what difficulties they had to face. The text of the report, slides and links to other presentations from the mitap, as always, under the cut.
First I want to demonstrate a small trailer for our game:
The report will consist of 3 parts. In the first, I will talk about what technologies we have chosen and why, in the second, how our meta-server works, and in the third I will talk about the various supporting infrastructure that we use and how we have implemented the update without downtime. .

Technological stack
Meta-server is hosted on Amazon and written in Elixir language. This is a functional programming language with an actor computation model. Since we do not have Ops, programmers are involved in the operation, and most of the infrastructure is described in the form of code using HashiCorp's Terraform.
At the moment, Tacticool is at the stage of open beta test, the meta-server is in development a little over a year and in operation for almost a year. Let's see how it all began.

When I joined the company, we already had the basic functionality implemented as a monolith on a mixture of C / C ++ and PostageSQL stores. This implementation had some problems.
First, because of the low-level C, there were quite a few elusive bugs. For example, for some players, matchmaking was tightly suspended due to incorrect resetting of the array before re-using it. Of course, to find the relationship of these two events was quite difficult. And since the state from several threads was modified throughout the code, it was not without Race conditions.
A parallel processing of a large number of tasks was also out of the question, because the server started at the start about 10 workflow processes that were blocked when querying Amazon or the database. And even if we forget about these blocking requests, the service began to crumble on a couple of hundreds of connections that did not perform any operations other than ping. In addition, the service was impossible to scale horizontally.
After a couple of weeks spent searching for and fixing the most critical bugs, we decided that it was easier to rewrite everything from scratch than to try to fix all the shortcomings of the current solution.
And when you start from scratch, it makes sense to try to choose a language that will help avoid some of the previous problems. We had three candidates:

C # got to the list of "an acquaintance", because Our client and game server are written in Unity and the most experience in the team was with this programming language. Go and Elixir were considered, because these are modern and quite popular languages created for developing server applications.
The problems of the previous iteration helped us determine the criteria for evaluating candidates.
The first criterion was the convenience of working with asynchronous operations. In C #, convenient work with asynchronous operations did not appear on the first attempt. This led to the fact that we have a “zoo” of solutions, which, in my opinion, still stand a little to the side. In Go and Elixir, this problem was taken into account when designing these languages, they both use lightweight flows (in Go they are gorutines, in Elixir they are processes). These streams have a much smaller overhead projector than the system ones, and since we can create them by tens and hundreds of thousands, we don’t feel sorry for blocking them.
The second criterion was the ability to work with competitive processes. C # out of the box does not offer anything other than routepools and shared memory, access to which needs to be protected using various synchronization primitives. Go has a less error-prone model in the form of gorutin and channels. Elixir, on the other hand, offers an actorless model with no shared memory and communication through messaging. The lack of shared memory made it possible to implement in the runtime such technologies that are useful for a competitive environment of execution, such as honest displacing multitasking and garbage collection without stopping the world.
The third criterion was the availability of tools for working with immutable data types. All my development experience has shown that quite a large part of the bugs are related to incorrect data changes. The solution for this exists long ago - immutable data types. In C #, you can create these types of data, but at the cost of a ton of boilerplate. In Go, this is generally not possible. And in Elixir, all data types are immutable.
And the last criterion was the number of specialists. Here the results are obvious. In the end, we opted for Elixir.
With the choice of hosting everything was much easier. Game servers have already been hosted by us at Amazon GameLift, in addition, Amazon offers a large number of services that would allow us to reduce development time.
We have completely “surrendered” to the cloud and are not deploying any third-party solutions ourselves — the database, the message queue — all of this is managed by Amazon. In my opinion, this is the only solution for a small team that wants to develop an online game, and not an infrastructure for it.
With the choice of technology figured out, let's move on to how the meta-server works.
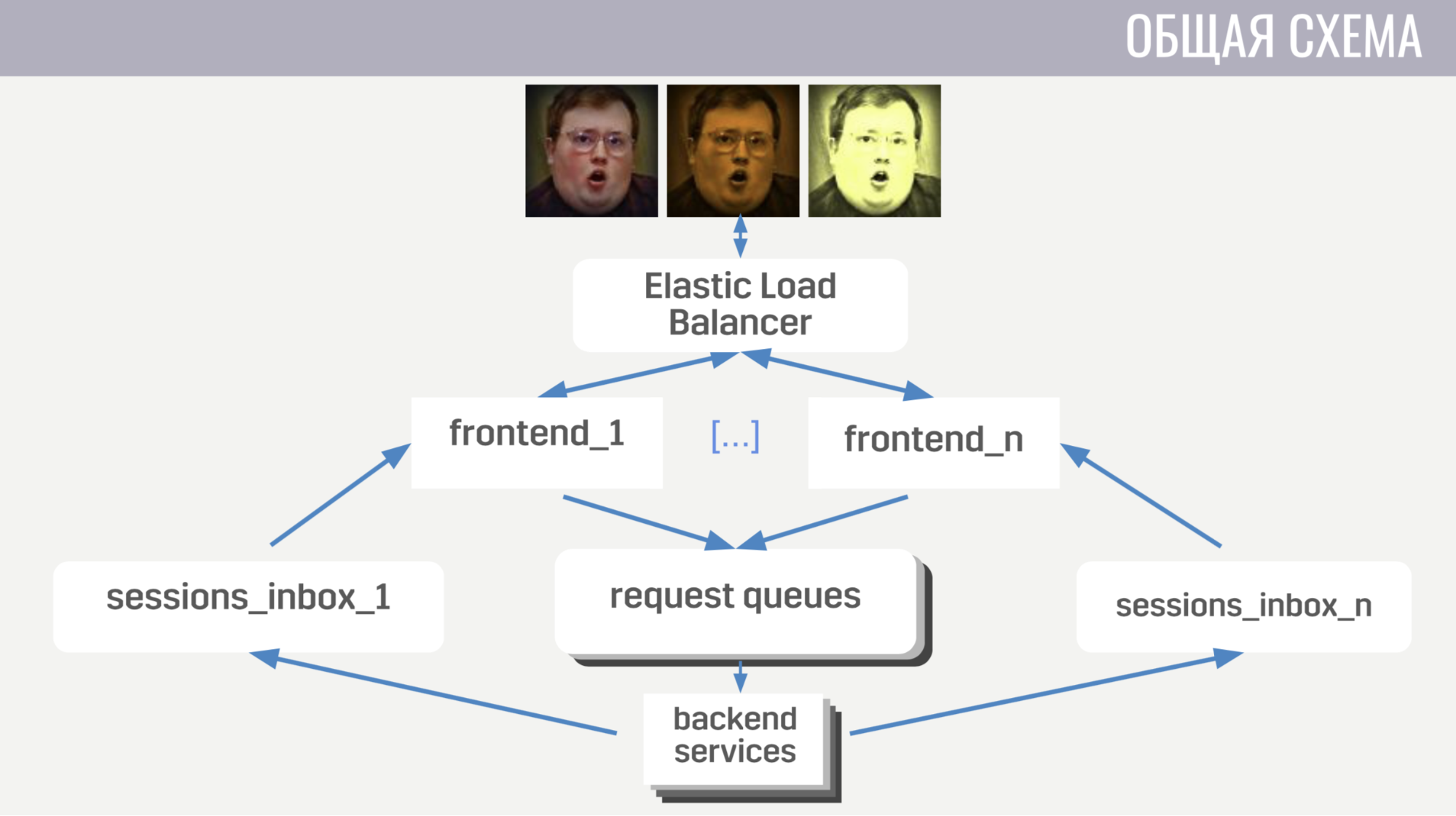
In general terms, clients connect to the load balancer at Amazon using web socket connections; The balancer scatters these connections between several frontend instances, the frontend sends client requests to backends. But the frontend and backend communicate indirectly through message queues. For each type of message there is a separate queue and the frontend, by the type of messages, determines where to write it, and the backends listen to these queues.
In order for the backend to send a response to a request to the client, or some event, a separate queue is attached to each front end (specially allocated for it). And in each request, the backend gets the frontend identifier to determine which queue to write the response to. If he needs to send an event, he accesses the database to find out which frontend instance is connected to the client.
With the general scheme of everything, let's get to the details.

First, I will talk about some of the features of client-server interaction. We use our binary protocol because it is quite efficient and saves traffic. Secondly, for any operations with an account that change it, the server sends to the client not these changes, but the full (updated) version of this account. This is a little less efficient, but it still doesn’t take up so much space and makes life much easier for us both on the client and on the server. Also, the frontend ensures that the client performs no more than one request at a time. This allows you to catch bugs on the client, for example, when it goes to another screen before the player sees the result of the previous operation.
Now a little about how the frontend works.

A frontend is, in essence, a web server that listens to web socket connections. For each session, two processes are created. The first process serves the web socket connection itself, and the second is the state machine that describes the current state of the client. Based on this state, it determines whether requests from the client are valid. For example, almost all requests cannot be executed until authorization is complete. Since there is no state on the frontend except for these sessions, it is very easy to add new frontend instances, but it is a bit more difficult to delete old ones. Before deleting, you must let all clients complete their current requests and ask them to reconnect to another instance.
Now how the backend looks like. At the moment it consists of five services.
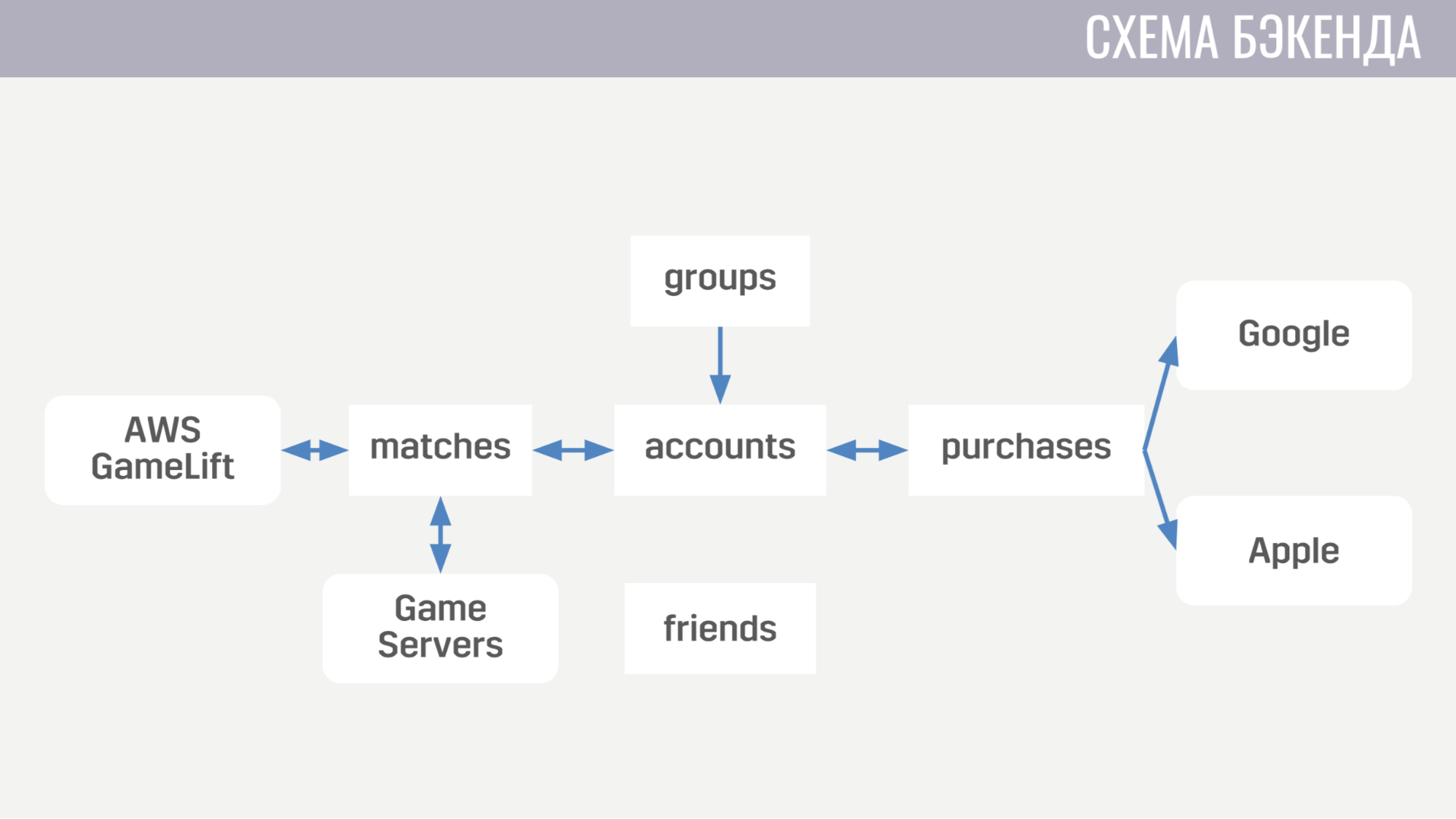
First deals with everything related to accounts - from purchases for in-game currency to completing quests. The second works with everything related to matches - it directly interacts with GameLift and game servers. The third service is shopping for real money. The fourth and fifth are responsible for social interaction - one for friends, the other for the game of party.
Each of the back-end services from an architectural point of view looks absolutely identical. They are a set of pipelines, each of which processes one type of message. Pipeline consists of two elements: producer and consumer.

The producer’s sole task is to read messages from the queue. Therefore, it is implemented completely in a general form and for each pipeline we only need to specify how many producers there are, from which queue to read and how many consumer'ov each producer will serve. Consumer is implemented for each pipeline separately and is a module with the only mandatory function that accepts one message, does all the necessary work and returns a list of messages that need to be sent to other services to the client, or to the game server. The producer also implements back pressure so that with a sharp increase in the number of messages there is no overload, and it requests no more messages than it has free consumers.
Backend services do not contain any state, so it is easy for us to add and remove old instances. The only thing you need to do before deleting is to ask the producers to stop reading new messages and give the consumer a little time to finish processing the active messages.
How does the interaction with GameLift'om. GameLift consists of several parts. Of those that we use, this is the matchmaker FlexMatch, the queue of placements, which determines in which particular region to place the gaming session with these players, and the fleets themselves, consisting of game servers.
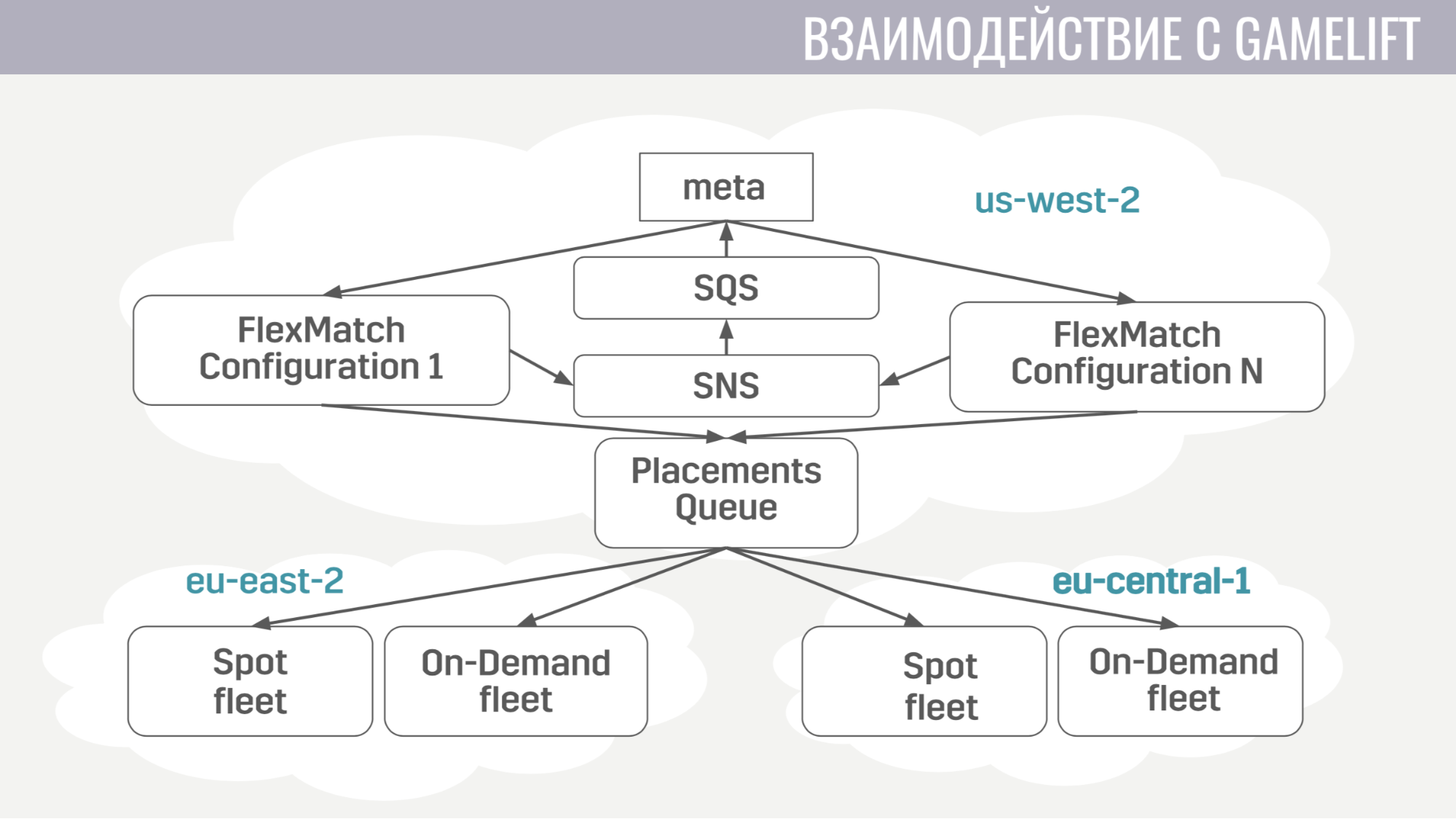
How does this interaction occur? Meta directly communicates only with the matchmaker, sends him requests to find a match. And he notifies Meta about all events during matchmaking through the same message queues. And as soon as he finds a suitable group of players to start a match, he sends an application to the queue for postings, which in turn selects a server for them.
Interaction meta with the game server is extremely simple. The game server needs information about accounts, bots, and the map, and all this information is sent to the queue by the queue created specifically for this match in a single message.

When the game server is activated, it starts listening to this queue and receives all the data it needs. At the end of the match, he sends his results to the general queue that meta listens to.
We now turn to the additional infrastructure that we use.

Deploying services is quite simple. They all work in docker containers, and for orchestration we use Amazon ECS. It is much simpler than Kubernetes, of course, less sophisticated, but it performs the tasks that we need from it. Namely: scaling services and rolling releases, when we need to fill in some bugfix.
And the last service we also use is AWS Fargate. It saves us from the need to independently manage the cluster of machines that run our docker containers.

We use DynamoDB as our primary storage. First of all, we chose it because it is very easy to exploit and scale. We also use Redis as additional storage through the managed Amazon ElasiCache service. We use it for the global player rating task and for caching basic account data in situations where we need to return data on hundreds of game accounts to the client at once (for example, in the same rating table or in the list of friends).
For storing configs, meta-gameplay mechanics, descriptions of weapons, heroes, etc. we use a JSON file that we enclose in the images of the services that need it. Because it is much easier for us to roll out a new version of the service with updated data (if any bug was discovered) than to make a solution that will dynamically update this data from some external storage in runtime.
For logging and monitoring, we use quite a lot of services.
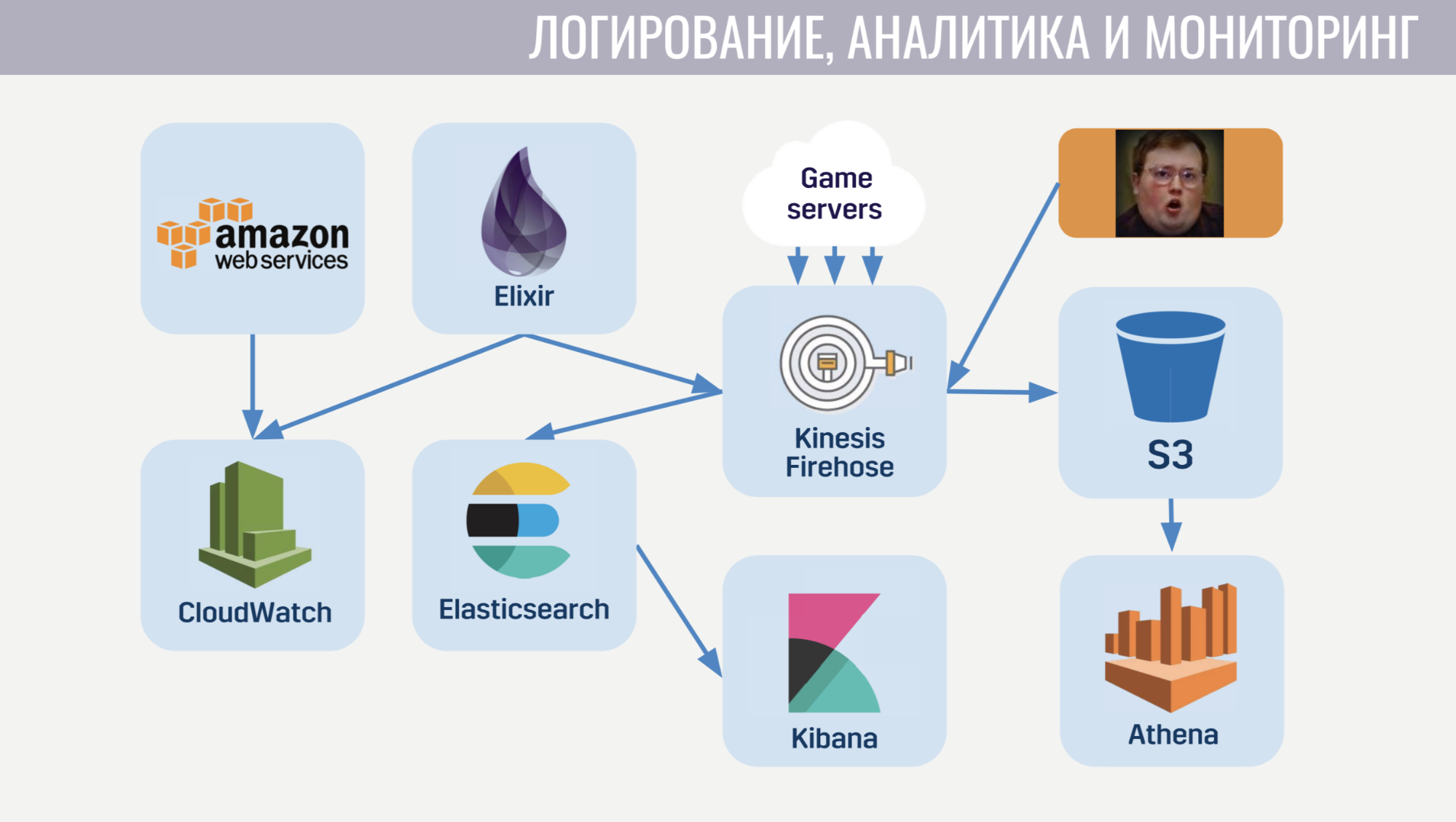
Let's start with CloudWatch. This is a monitoring service in which metrics from all Amazonian services flow. Therefore, we decided to send metrics from our meta-server there too. And for logging, we use a common approach both on the client and on the game server and on the meta server. All logs we send to the Amazon service Kinesis Firehose, which in turn shifts them to Elasticseach and S3.
In Elasticseach, we store only relatively fresh data and with the help of Kibana we look for errors, solve some of the problems of game analytics and build operational dashboards, for example, with the CCU schedule and the number of new installations. In S3 there are all historical data and we use them through the Athena service, which provides a SQL interface over the data in S3.
Now a little about how we use Terraform.

Terraform is a tool that allows you to declare the infrastructure declaratively and with any change in the description, it automatically determines the actions that must be performed to bring your infrastructure to an updated form. Thus, having a single description, we get an almost identical environment for staging and production. Also, these environments are completely isolated, because they are deployed under different accounts. The only significant drawback of Terraform for us is the incomplete support for GameLift.
I’ll also tell you how we implemented the update without downtime.

When we release updates, we pick up a copy of most resources: services, message queues, some labels in the database. And those players who download the new version of the game will connect to this updated cluster. But those players who have not yet been updated can continue to play the old version of the game for some time, connecting to the old cluster.
How we implemented it. First, using the modular mechanism in Terraform. We selected a module in which we described all versioned resources. And these modules can be imported several times, with different parameters. Accordingly, for each version we import this module, indicating the number of this version. Also, the lack of a scheme in DynamoDB helped us, which makes it possible to perform data migration not during an update, but to postpone them for each account until its owner logs into the new version of the game. And in the balancer, we simply indicate for each version of the rule, so that he knows where to route the players with different versions.
Finally, a couple of things that we have learned. First, the configuration of the entire infrastructure must be automated. Those. we set up some things with our hands for some time, but sooner or later we were mistaken in the settings, because of what fakapu happened.

And the last - for each element of your infrastructure you need to have either a replica or a backup copy. And if for some reason it is not done, then it is this thing that will ever let us down.
- Does it bother you that autoscaling can zaskeilitsya too much up due to some kind of error and you will get a lot of money?
- For autoscaling, limits are set anyway. We will not put too big a limit, so as not to get a lot of money. This is a basic solution + monitoring. You can set alerts if something zaskeylilos too much.
- At the moment you have any limits? Relative to current infrastructure as a percentage.
- Now we have a stage of open beta test in 11 countries, so not so big CCU to at least somehow evaluate. Now the infrastructure is too overprovisioned for the number of people we have.
- And there are no limits yet?
- There are, they are just 10-100 times larger than the SSU with us. Do not do less.
- You said that you have a queue between the front and backend - this is very unusual. Why not directly?
“We wanted stateless services to easily implement a backprese mechanism so that the service does not request more messages than it has free handlers. Also, for example, when the handler fills, the queue will issue the same message to another handler - maybe something will work out.
- Does the queue persist somehow?
- Yes. This is Amazon SQS service.
- Regarding the queues: how many channels do you have during the game? Do you have a certain number of channels for every match?
- It is created relatively little. Most of the queues, such as request queues, are static. There is a queue of requests for authorization, there is a queue at the start of the match. From the dynamically created queues, we only have queues for each frontend (it starts up for incoming messages for customers) and for each match we create one queue. In this service, it costs almost nothing, they have every request is the same. Those. Any request to SQS (create a queue, read something from it) is the same and at the same time we do not delete these queues to save, they themselves are then deleted. And the fact that they exist does not cost us anything.
- In this architecture, it will not be your limit?
- Not.
First I want to demonstrate a small trailer for our game:
The report will consist of 3 parts. In the first, I will talk about what technologies we have chosen and why, in the second, how our meta-server works, and in the third I will talk about the various supporting infrastructure that we use and how we have implemented the update without downtime. .
Technological stack
Meta-server is hosted on Amazon and written in Elixir language. This is a functional programming language with an actor computation model. Since we do not have Ops, programmers are involved in the operation, and most of the infrastructure is described in the form of code using HashiCorp's Terraform.
At the moment, Tacticool is at the stage of open beta test, the meta-server is in development a little over a year and in operation for almost a year. Let's see how it all began.
When I joined the company, we already had the basic functionality implemented as a monolith on a mixture of C / C ++ and PostageSQL stores. This implementation had some problems.
First, because of the low-level C, there were quite a few elusive bugs. For example, for some players, matchmaking was tightly suspended due to incorrect resetting of the array before re-using it. Of course, to find the relationship of these two events was quite difficult. And since the state from several threads was modified throughout the code, it was not without Race conditions.
A parallel processing of a large number of tasks was also out of the question, because the server started at the start about 10 workflow processes that were blocked when querying Amazon or the database. And even if we forget about these blocking requests, the service began to crumble on a couple of hundreds of connections that did not perform any operations other than ping. In addition, the service was impossible to scale horizontally.
After a couple of weeks spent searching for and fixing the most critical bugs, we decided that it was easier to rewrite everything from scratch than to try to fix all the shortcomings of the current solution.
And when you start from scratch, it makes sense to try to choose a language that will help avoid some of the previous problems. We had three candidates:
- C #;
- Go;
- Elixir.
C # got to the list of "an acquaintance", because Our client and game server are written in Unity and the most experience in the team was with this programming language. Go and Elixir were considered, because these are modern and quite popular languages created for developing server applications.
The problems of the previous iteration helped us determine the criteria for evaluating candidates.
The first criterion was the convenience of working with asynchronous operations. In C #, convenient work with asynchronous operations did not appear on the first attempt. This led to the fact that we have a “zoo” of solutions, which, in my opinion, still stand a little to the side. In Go and Elixir, this problem was taken into account when designing these languages, they both use lightweight flows (in Go they are gorutines, in Elixir they are processes). These streams have a much smaller overhead projector than the system ones, and since we can create them by tens and hundreds of thousands, we don’t feel sorry for blocking them.
The second criterion was the ability to work with competitive processes. C # out of the box does not offer anything other than routepools and shared memory, access to which needs to be protected using various synchronization primitives. Go has a less error-prone model in the form of gorutin and channels. Elixir, on the other hand, offers an actorless model with no shared memory and communication through messaging. The lack of shared memory made it possible to implement in the runtime such technologies that are useful for a competitive environment of execution, such as honest displacing multitasking and garbage collection without stopping the world.
The third criterion was the availability of tools for working with immutable data types. All my development experience has shown that quite a large part of the bugs are related to incorrect data changes. The solution for this exists long ago - immutable data types. In C #, you can create these types of data, but at the cost of a ton of boilerplate. In Go, this is generally not possible. And in Elixir, all data types are immutable.
And the last criterion was the number of specialists. Here the results are obvious. In the end, we opted for Elixir.
With the choice of hosting everything was much easier. Game servers have already been hosted by us at Amazon GameLift, in addition, Amazon offers a large number of services that would allow us to reduce development time.
We have completely “surrendered” to the cloud and are not deploying any third-party solutions ourselves — the database, the message queue — all of this is managed by Amazon. In my opinion, this is the only solution for a small team that wants to develop an online game, and not an infrastructure for it.
With the choice of technology figured out, let's move on to how the meta-server works.
In general terms, clients connect to the load balancer at Amazon using web socket connections; The balancer scatters these connections between several frontend instances, the frontend sends client requests to backends. But the frontend and backend communicate indirectly through message queues. For each type of message there is a separate queue and the frontend, by the type of messages, determines where to write it, and the backends listen to these queues.
In order for the backend to send a response to a request to the client, or some event, a separate queue is attached to each front end (specially allocated for it). And in each request, the backend gets the frontend identifier to determine which queue to write the response to. If he needs to send an event, he accesses the database to find out which frontend instance is connected to the client.
With the general scheme of everything, let's get to the details.
First, I will talk about some of the features of client-server interaction. We use our binary protocol because it is quite efficient and saves traffic. Secondly, for any operations with an account that change it, the server sends to the client not these changes, but the full (updated) version of this account. This is a little less efficient, but it still doesn’t take up so much space and makes life much easier for us both on the client and on the server. Also, the frontend ensures that the client performs no more than one request at a time. This allows you to catch bugs on the client, for example, when it goes to another screen before the player sees the result of the previous operation.
Now a little about how the frontend works.
A frontend is, in essence, a web server that listens to web socket connections. For each session, two processes are created. The first process serves the web socket connection itself, and the second is the state machine that describes the current state of the client. Based on this state, it determines whether requests from the client are valid. For example, almost all requests cannot be executed until authorization is complete. Since there is no state on the frontend except for these sessions, it is very easy to add new frontend instances, but it is a bit more difficult to delete old ones. Before deleting, you must let all clients complete their current requests and ask them to reconnect to another instance.
Now how the backend looks like. At the moment it consists of five services.
First deals with everything related to accounts - from purchases for in-game currency to completing quests. The second works with everything related to matches - it directly interacts with GameLift and game servers. The third service is shopping for real money. The fourth and fifth are responsible for social interaction - one for friends, the other for the game of party.
Each of the back-end services from an architectural point of view looks absolutely identical. They are a set of pipelines, each of which processes one type of message. Pipeline consists of two elements: producer and consumer.
The producer’s sole task is to read messages from the queue. Therefore, it is implemented completely in a general form and for each pipeline we only need to specify how many producers there are, from which queue to read and how many consumer'ov each producer will serve. Consumer is implemented for each pipeline separately and is a module with the only mandatory function that accepts one message, does all the necessary work and returns a list of messages that need to be sent to other services to the client, or to the game server. The producer also implements back pressure so that with a sharp increase in the number of messages there is no overload, and it requests no more messages than it has free consumers.
Backend services do not contain any state, so it is easy for us to add and remove old instances. The only thing you need to do before deleting is to ask the producers to stop reading new messages and give the consumer a little time to finish processing the active messages.
How does the interaction with GameLift'om. GameLift consists of several parts. Of those that we use, this is the matchmaker FlexMatch, the queue of placements, which determines in which particular region to place the gaming session with these players, and the fleets themselves, consisting of game servers.
How does this interaction occur? Meta directly communicates only with the matchmaker, sends him requests to find a match. And he notifies Meta about all events during matchmaking through the same message queues. And as soon as he finds a suitable group of players to start a match, he sends an application to the queue for postings, which in turn selects a server for them.
Interaction meta with the game server is extremely simple. The game server needs information about accounts, bots, and the map, and all this information is sent to the queue by the queue created specifically for this match in a single message.
When the game server is activated, it starts listening to this queue and receives all the data it needs. At the end of the match, he sends his results to the general queue that meta listens to.
We now turn to the additional infrastructure that we use.
Deploying services is quite simple. They all work in docker containers, and for orchestration we use Amazon ECS. It is much simpler than Kubernetes, of course, less sophisticated, but it performs the tasks that we need from it. Namely: scaling services and rolling releases, when we need to fill in some bugfix.
And the last service we also use is AWS Fargate. It saves us from the need to independently manage the cluster of machines that run our docker containers.
We use DynamoDB as our primary storage. First of all, we chose it because it is very easy to exploit and scale. We also use Redis as additional storage through the managed Amazon ElasiCache service. We use it for the global player rating task and for caching basic account data in situations where we need to return data on hundreds of game accounts to the client at once (for example, in the same rating table or in the list of friends).
For storing configs, meta-gameplay mechanics, descriptions of weapons, heroes, etc. we use a JSON file that we enclose in the images of the services that need it. Because it is much easier for us to roll out a new version of the service with updated data (if any bug was discovered) than to make a solution that will dynamically update this data from some external storage in runtime.
For logging and monitoring, we use quite a lot of services.
Let's start with CloudWatch. This is a monitoring service in which metrics from all Amazonian services flow. Therefore, we decided to send metrics from our meta-server there too. And for logging, we use a common approach both on the client and on the game server and on the meta server. All logs we send to the Amazon service Kinesis Firehose, which in turn shifts them to Elasticseach and S3.
In Elasticseach, we store only relatively fresh data and with the help of Kibana we look for errors, solve some of the problems of game analytics and build operational dashboards, for example, with the CCU schedule and the number of new installations. In S3 there are all historical data and we use them through the Athena service, which provides a SQL interface over the data in S3.
Now a little about how we use Terraform.
Terraform is a tool that allows you to declare the infrastructure declaratively and with any change in the description, it automatically determines the actions that must be performed to bring your infrastructure to an updated form. Thus, having a single description, we get an almost identical environment for staging and production. Also, these environments are completely isolated, because they are deployed under different accounts. The only significant drawback of Terraform for us is the incomplete support for GameLift.
I’ll also tell you how we implemented the update without downtime.
When we release updates, we pick up a copy of most resources: services, message queues, some labels in the database. And those players who download the new version of the game will connect to this updated cluster. But those players who have not yet been updated can continue to play the old version of the game for some time, connecting to the old cluster.
How we implemented it. First, using the modular mechanism in Terraform. We selected a module in which we described all versioned resources. And these modules can be imported several times, with different parameters. Accordingly, for each version we import this module, indicating the number of this version. Also, the lack of a scheme in DynamoDB helped us, which makes it possible to perform data migration not during an update, but to postpone them for each account until its owner logs into the new version of the game. And in the balancer, we simply indicate for each version of the rule, so that he knows where to route the players with different versions.
Finally, a couple of things that we have learned. First, the configuration of the entire infrastructure must be automated. Those. we set up some things with our hands for some time, but sooner or later we were mistaken in the settings, because of what fakapu happened.
And the last - for each element of your infrastructure you need to have either a replica or a backup copy. And if for some reason it is not done, then it is this thing that will ever let us down.
Questions from the audience
- Does it bother you that autoscaling can zaskeilitsya too much up due to some kind of error and you will get a lot of money?
- For autoscaling, limits are set anyway. We will not put too big a limit, so as not to get a lot of money. This is a basic solution + monitoring. You can set alerts if something zaskeylilos too much.
- At the moment you have any limits? Relative to current infrastructure as a percentage.
- Now we have a stage of open beta test in 11 countries, so not so big CCU to at least somehow evaluate. Now the infrastructure is too overprovisioned for the number of people we have.
- And there are no limits yet?
- There are, they are just 10-100 times larger than the SSU with us. Do not do less.
- You said that you have a queue between the front and backend - this is very unusual. Why not directly?
“We wanted stateless services to easily implement a backprese mechanism so that the service does not request more messages than it has free handlers. Also, for example, when the handler fills, the queue will issue the same message to another handler - maybe something will work out.
- Does the queue persist somehow?
- Yes. This is Amazon SQS service.
- Regarding the queues: how many channels do you have during the game? Do you have a certain number of channels for every match?
- It is created relatively little. Most of the queues, such as request queues, are static. There is a queue of requests for authorization, there is a queue at the start of the match. From the dynamically created queues, we only have queues for each frontend (it starts up for incoming messages for customers) and for each match we create one queue. In this service, it costs almost nothing, they have every request is the same. Those. Any request to SQS (create a queue, read something from it) is the same and at the same time we do not delete these queues to save, they themselves are then deleted. And the fact that they exist does not cost us anything.
- In this architecture, it will not be your limit?
- Not.
More reports from Pixonic DevGAMM Talks
- Using Consul to scale stateful services (Ivan Bubnov, DevOps at BIT.GAMES);
- CICD: Seamless Deploy on Distributed Cluster Systems without Downtime (Egor Panov, Pixonic System Administrator);
- Practice using the model of actors in the back-platform platform of the Quake Champions game (Roman Rogozin, backend developer of Saber Interactive);
- How ECS, C # Job System and SRP change the approach to architecture (Valentin Simonov, Field Engineer in Unity);
- KISS principle in development (Konstantin Gladyshev, Lead Game Programmer at 1C Game Studios);
- General game logic on the client and server (Anton Grigoriev, Deputy Technical Officer in Pixonic).
- Cucumber in the cloud: using BDD scripts for load testing a product (Anton Kosyakin, Technical Product Manager in ALICE Platform).