How to organize a CI / CD on a project: from setting tasks to setting up a deployment pipeline
- Tutorial
What is the key to successful configuration of Continuous Delivery on projects? Well coordinated work of development teams, testing and infrastructure engineers. Thank you, cap, as they say :) But how to implement it in practice? In this article we will share our experiences, how to organize and implement all this.
We have summarized the basics in one crib for yourself and share with you:
Experienced engineers are unlikely to learn something new from the article, but we hope that this information will be useful to novice specialists.

Each project has a number of requirements. It is important to understand all of them and not to be confused.
Business requirements determine what the system should do from a business point of view.
For example: the application should allow the user to sell tickets and additional services in order to increase sales of agents.
User requirements describe the goals and objectives of users who will work in the system to implement business requirements. User requirements are often presented as user cases.
For example: as a user, I need to sell services for miles.
Functional requirements- what the system should do. Determine the functionality (behavior) of the system, which must be created by developers in order for users to fulfill user requirements.
Non-functional requirements - how the system should work. This includes performance requirements, quality, limitations, usability, etc.
So, we described the types of requirements. Now we divide them into task types, decipher each type and describe how to describe it correctly.

Let's start with the most epic, that is, with Epic.
Epic is a common task in which all User Story are collected, taking into account the development time of the service. It describes the main purpose of a product or service. The main goal of Epic is to collect tasks and store them in one place regardless of what new requirements are put forward to the product. Epic is always more of a user story and may not even fit in one iteration.
The Epic Task Solution allows you to create a Minimal Viable Product MVP — the minimum viable product. In other words, what needs to be released in order to study and adapt the product based on feedback from end users.
How does Epic differ from User Story?
The difference between User story and Tech story is that Tech Story refers to the functional requirements that need to be considered and described in the task when developing a product. And in the role of consumers here are parts of the system.
Describing them is easy. The main thing to remember is why all this is done.

What information should be indicated when reporting a bug:
1. Title / Summary / Title briefly describes the nature of the error and indicates where the problem is located.
2. Description / Description contains the following steps:
• how to reproduce the error / steps to reproduce,
• the current result,
• the expected result.
3. Attachments / Attachments - all the necessary logs, screenshots, links to Kibana and other files.
4. Environment — the mark in which the error is played, and the category to which the problem relates. For example, a UI error, CORE error, SWS error, etc.
5. Priority / Priorityallows each team member to assess the seriousness of the problem, and the manager to see it in the list of first candidates for sprint.
And do not forget to set the correct priority level :)
Now that you have dealt with the general principles of operation, we will tell you how the deployment pipeline was organized.
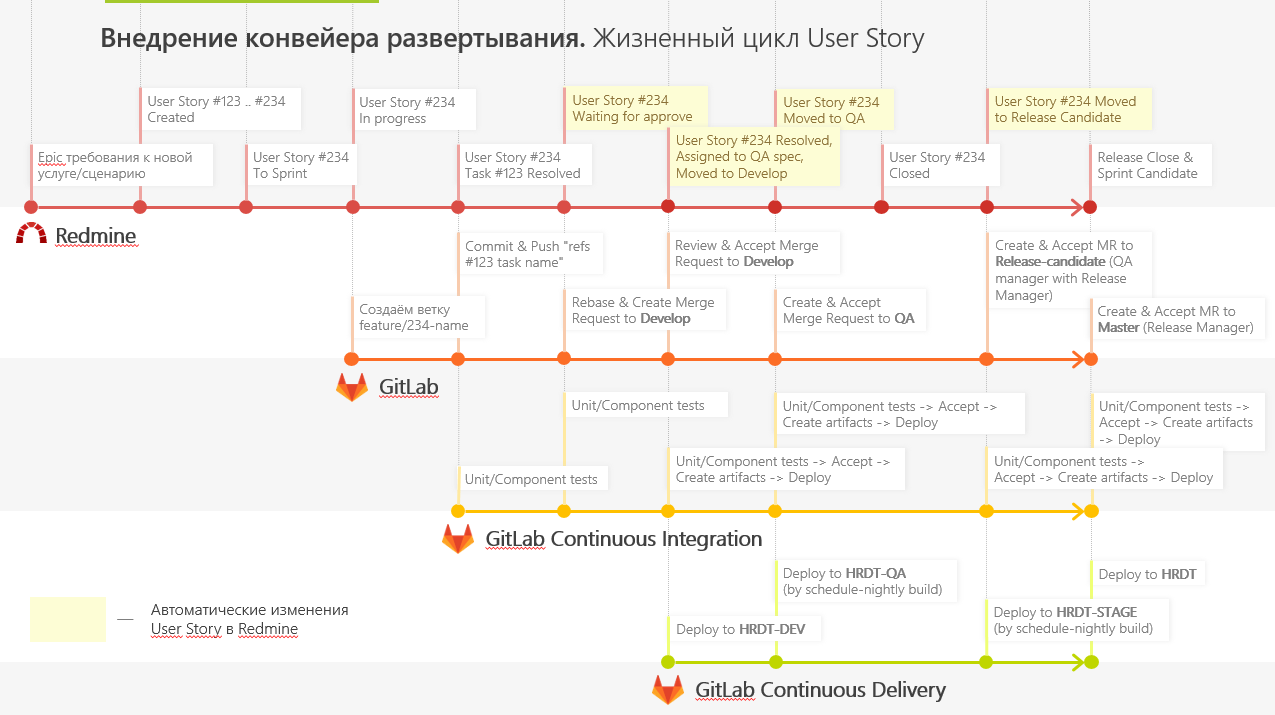
To speed up the delivery of our services to production, we are introducing a new deployment pipeline and using GitFlow to work with the code.
To do this quickly and dynamically, we deployed several GitLab-runners that run all the tasks for developers. Thanks to the GitLab Flow approach, we have several servers: Develop, QA, Release-candidate and Production.
Continuous Integration began to collect and run tests for each commit, run unit tests and integration tests, add artifacts with the application delivery.

Development happens like this:
If at some stage there are errors, then it is in this thread that we solve them, after which we post the result in Develop.
We also made a small plugin so that Redmine could tell us what stage the feature is at. This helps testers to assess at what stage you need to connect to the task, and developers - to correct errors. So they see at what stage the failure occurred, they can go to a specific branch and play it there.
We hope you find it useful.
We have summarized the basics in one crib for yourself and share with you:
- What are the requirements and how they are characterized ,
- Types of tasks and the order of their description in the Issue tracker ,
- How to make a User story and Tech story ,
- How to describe bugs ,
- Setting deployment pipeline .
Experienced engineers are unlikely to learn something new from the article, but we hope that this information will be useful to novice specialists.
What are the requirements and how they are characterized
Each project has a number of requirements. It is important to understand all of them and not to be confused.
Business requirements determine what the system should do from a business point of view.
For example: the application should allow the user to sell tickets and additional services in order to increase sales of agents.
User requirements describe the goals and objectives of users who will work in the system to implement business requirements. User requirements are often presented as user cases.
For example: as a user, I need to sell services for miles.
Functional requirements- what the system should do. Determine the functionality (behavior) of the system, which must be created by developers in order for users to fulfill user requirements.
Non-functional requirements - how the system should work. This includes performance requirements, quality, limitations, usability, etc.
Task types and order of their description in the Issue tracker
So, we described the types of requirements. Now we divide them into task types, decipher each type and describe how to describe it correctly.
Let's start with the most epic, that is, with Epic.
Epic is a common task in which all User Story are collected, taking into account the development time of the service. It describes the main purpose of a product or service. The main goal of Epic is to collect tasks and store them in one place regardless of what new requirements are put forward to the product. Epic is always more of a user story and may not even fit in one iteration.
The Epic Task Solution allows you to create a Minimal Viable Product MVP — the minimum viable product. In other words, what needs to be released in order to study and adapt the product based on feedback from end users.
How does Epic differ from User Story?
- Epic is just a great user history, the distinguishing feature of which is the presence of explicit value for the user.
- Starting to form user histories, i.e. collecting project requirements, we usually move from the general to the particular - first we decide on the project concept, select the main persons (users of the system), form the list of basic features, and further detail these features into separate wishes - User story.
The order of describing Epic is:
- Title / Summary Title - the name of the new functionality.
- Description / Description - written in a pattern:
The role of the user (as such and such a user, me ...) / User action (I want to do something ...) / The result of the action (to get a result that ...) / Interest or benefit (allow me get such benefits ...). - An example implementation plan or a brief description of the main User Stories that will be completed within Epic, taking into account the MVP.
- Attachments / Attachments - attach correspondence, technology and other necessary information.
How to make a User story and Tech story
The difference between User story and Tech story is that Tech Story refers to the functional requirements that need to be considered and described in the task when developing a product. And in the role of consumers here are parts of the system.
Describing them is easy. The main thing to remember is why all this is done.
The description of the User story is quite standard:
- Title / Summary / Title - a brief description of the new functionality or refinement in a language understandable to the customer.
- Description / Description includes the main goal and the desired result. As, <user role>, I <want to get>, with the goal of <result of actions>.
- Acceptance Criteria is a list of priority product criteria. That is, a measurable definition of what should be done with the product in order for it to be accepted by project stakeholders.
- Technical notes, models, layouts, structural schemes of pages.
- Attachments / Attachments - all the necessary technology, documents, correspondence with the customer.
How to describe bugs
What information should be indicated when reporting a bug:
1. Title / Summary / Title briefly describes the nature of the error and indicates where the problem is located.
2. Description / Description contains the following steps:
• how to reproduce the error / steps to reproduce,
• the current result,
• the expected result.
3. Attachments / Attachments - all the necessary logs, screenshots, links to Kibana and other files.
4. Environment — the mark in which the error is played, and the category to which the problem relates. For example, a UI error, CORE error, SWS error, etc.
5. Priority / Priorityallows each team member to assess the seriousness of the problem, and the manager to see it in the list of first candidates for sprint.
And do not forget to set the correct priority level :)
Now that you have dealt with the general principles of operation, we will tell you how the deployment pipeline was organized.
Deployment Pipeline Configuration
To speed up the delivery of our services to production, we are introducing a new deployment pipeline and using GitFlow to work with the code.
To do this quickly and dynamically, we deployed several GitLab-runners that run all the tasks for developers. Thanks to the GitLab Flow approach, we have several servers: Develop, QA, Release-candidate and Production.
Continuous Integration began to collect and run tests for each commit, run unit tests and integration tests, add artifacts with the application delivery.
Development happens like this:
- The developer adds a new feature in a separate branch (feature branch). After that, it creates a request to merge its branch with the main development branch (Merge Request to Develop branch).
- The request to merge is viewed by other developers, accept it (or not) and correct the comments. After merging into the main branch, a special environment is developed, on which the tests for elevation of the environment are performed.
- When all these stages are completed, the QA engineer takes the changes to his “QA” branch and conducts testing.
- If the QA engineer coordinates the work done, the changes are transferred to the Release-Candidate branch and deployed in an environment that is accessible to external users. In this environment, the customer performs acceptance and verification of technologies. Then we overtake everything in Production.
If at some stage there are errors, then it is in this thread that we solve them, after which we post the result in Develop.
We also made a small plugin so that Redmine could tell us what stage the feature is at. This helps testers to assess at what stage you need to connect to the task, and developers - to correct errors. So they see at what stage the failure occurred, they can go to a specific branch and play it there.
We hope you find it useful.