My catch for the week
The more a developer is working on an application in a team and the better his code is, the more often he reads out the work of his comrades. Today I will show what can be caught in one week in code written by very good developers. Under the cut is a collection of bright artifacts of our creativity (and some of my thoughts).
Comparators
There is a code:
@GetterclassDto{
private Long id;
}
// another classList<Long> readSortedIds(List<Dto> list){
List<Long> ids = list.stream().map(Dto::getId).collect(Collectors.toList());
ids.sort(new Comparator<Long>() {
publicintcompare(Long o1, Long o2){
if (o1 < o2) return -1;
if (o1 > o2) return1;
return0;
}
});
return ids;
}Someone will note that you can directly sort the stream, but I want to draw your attention to the comparator. The documentation for the Comparator::compareEnglish method is written in white:
Compares its two arguments for order. Returns to a negative integer, zero or a positive integer.
This behavior is implemented in our code. What is wrong? The fact is that the creators of Java very far-sightedly assumed that such a comparator would be needed by many and made it for us. We can only use it by simplifying our code:
List<Long> readSortedIds(List<Dto> list){
List<Long> ids = list.stream().map(Dto::getId).collect(Collectors.toList());
ids.sort(Comparator.naturalOrder());
return ids;
}Similarly, this code
List<Dto> sortDtosById(List<Dto> list){
list.sort(new Comparator<Dto>() {
publicintcompare(Dto o1, Dto o2){
if (o1.getId() < o2.getId()) return -1;
if (o1.getId() > o2.getId()) return1;
return0;
}
});
return list;
}with a slight movement of the hand turns into such
List<Dto> sortDtosById(List<Dto> list){
list.sort(Comparator.comparing(Dto::getId));
return list;
}By the way, in the new version of "Idea" you can do this:
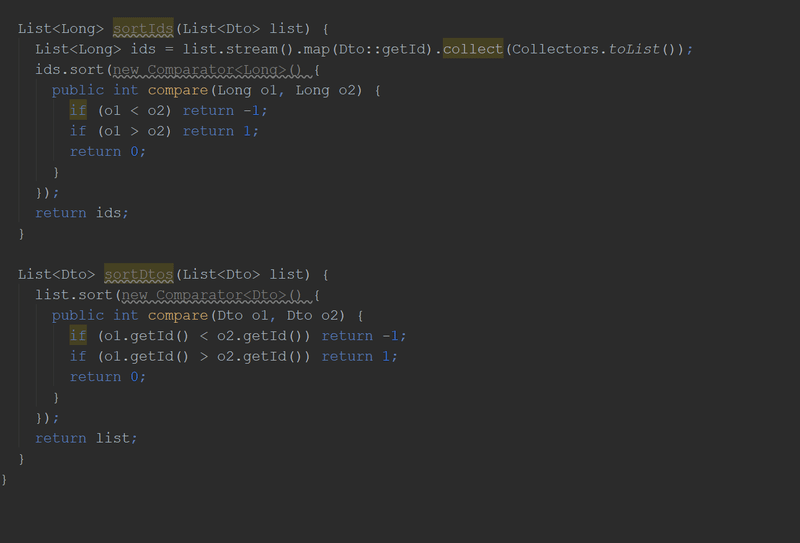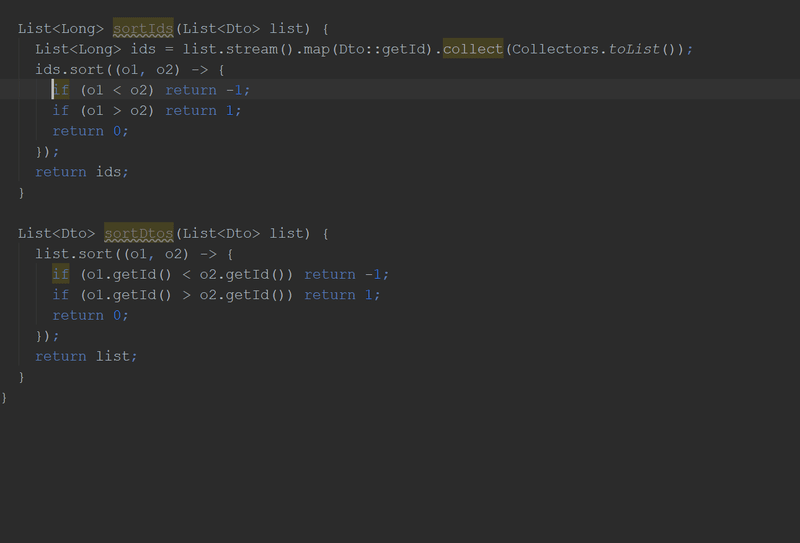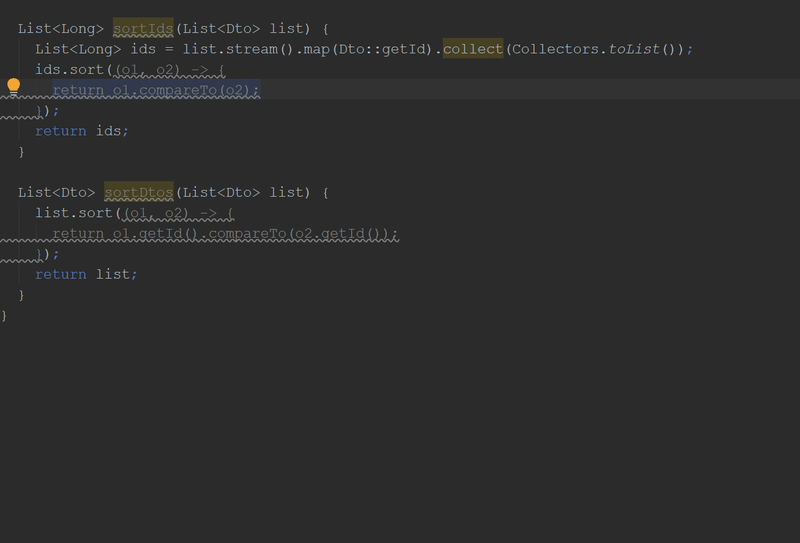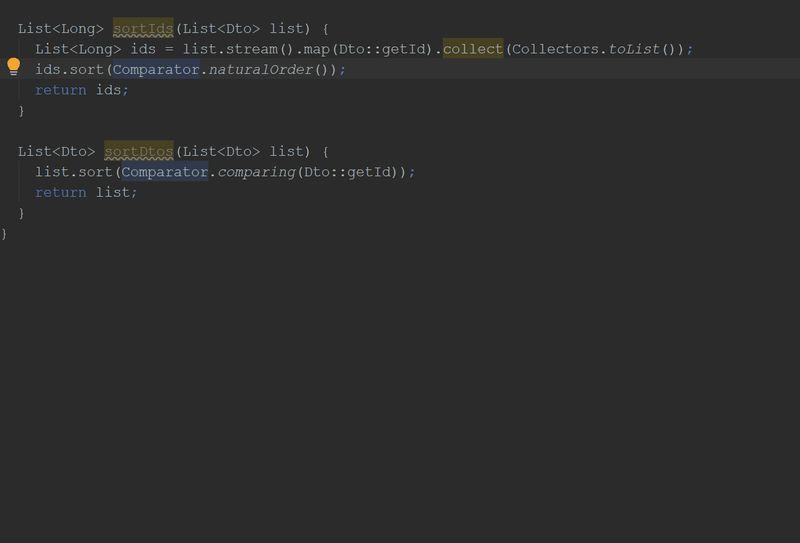
Abuse Optional
Probably each of us saw something like this:
List<UserEntity> getUsersForGroup(Long groupId){
Optional<Long> optional = Optional.ofNullable(groupId);
if (optional.isPresent()) {
return userRepository.findUsersByGroup(optional.get());
}
return Collections.emptyList();
}Often Optionalused to check the presence / absence of values, although it was not created for this. Tie with abuse and write easier:
List<UserEntity> getUsersForGroup(Long groupId){
if (groupId == null) {
return Collections.emptyList();
}
return userRepository.findUsersByGroup(groupId);
}Remember that Optional- this is not about the argument of the method or the field, but about the return value. That is why it is designed without serialization support.
void methods that change the state of the argument
Imagine this method:
@Component@RequiredArgsConstructorpublicclassContractUpdater{
privatefinal ContractRepository repository;
@TransactionalpublicvoidupdateContractById(Long contractId, Dto contractDto){
Contract contract = repository.findOne(contractId);
contract.setValue(contractDto.getValue());
repository.save(contract);
}
}Surely you have seen and written something like that many times. Here I do not like that the method changes the state of the entity, but does not return it. How do framework methods behave? For example, org.springframework.data.jpa.repository.JpaRepository::saveand javax.persistence.EntityManager::mergereturn value. Suppose after updating the contract we need to get it outside of the method update. It turns out something like this:
@TransactionalpublicvoidanotherMethod(Long contractId, Dto contractDto){
updateService.updateContractById(contractId, contractDto);
Contract contract = repositoroty.findOne(contractId);
doSmth(contract);
}Yes, we could pass the entity directly into the method UpdateService::updateContract, changing its signature, but it’s better to do this:
@Component@RequiredArgsConstructorpublicclassContractUpdater{
privatefinal ContractRepository repository;
@Transactionalpublic Contract updateContractById(Long contractId, Dto contractDto){
Contract contract = repository.findOne(contractId);
contract.setValue(contractDto.getValue());
return repository.save(contract);
}
}
//использование@TransactionalpublicvoidanotherMethod(Long contractId, Dto contractDto){
Contract contract = updateService.updateContractById(contractId, contractDto);
doSmth(contract);
}On the one hand, it helps to simplify the code, on the other hand, it helps with testing. In general, testing voidmethods for an unusually dreary task, which I will show using the same example:
@RunWith(MockitoJUnitRunner.class)
publicclassContractUpdaterTest{
@Mockprivate ContractRepository repository;
@InjectMocksprivate ContractUpdater updater;
@TestpublicvoidupdateContractById(){
Dto dto = new Dto();
dto.setValue("что-то там");
Long contractId = 1L;
when(repository.findOne(contractId)).thenReturn(new Contract());
updater.updateContractById(contractId, contractDto); //void//как проверить, что в контракт вписали значение из dto? - Примерно так:
ArgumentCaptor<Contract> captor = ArgumentCaptor.forClass(Contract.class);
verify(repository).save(captor.capture());
Contract updated = captor.getValue();
assertEquals(dto.getValue(), updated.getValue());
}
}But everything can be made easier if the method returns a value:
@RunWith(MockitoJUnitRunner.class)
publicclassContractUpdaterTest{
@Mockprivate ContractRepository repository;
@InjectMocksprivate ContractUpdater updater;
@TestpublicvoidupdateContractById(){
Dto dto = new Dto();
dto.setValue("что-то там");
Long contractId = 1L;
when(repository.findOne(contractId)).thenReturn(new Contract());
Contract updated = updater.updateContractById(contractId, contractDto);
assertEquals(dto.getValue(), updated.getValue());
}
}At one stroke, not only the challenge is checked ContractRepository::save, but also the correctness of the stored value.
Cycling
For fun, open your project and look for this:
lastIndexOf('.')With high probability, the whole expression looks like this:
String fileExtension = fileName.subString(fileName.lastIndexOf('.'));The thing about which no static analyzer can warn is about a newly invented bicycle. Gentlemen, if you solve a certain task related to the file name / extension or the path to it, exactly like reading / writing / copying, then in 9 cases out of 10 the problem has already been solved. Therefore, tie with bicycle construction and take ready (and proven) solutions:
import org.apache.commons.io.FilenameUtils;
//...
String fileExtension = FilenameUtils.getExtension(fileName);In this case, you save the time that would be spent on checking the suitability of the bike, and also get more advanced functionality (see the documentation FilenameUtils::getExtension).
Or this code, copying the contents of one file to another:
try {
FileChannel sc = new FileInputStream(src).getChannel();
FileChannel dc = new FileOutputStream(new File(targetName)).getChannel();
sc.transferTo(0, sc.size(), dc);
dc.close();
sc.close();
} catch (IOException ex) {
log.error("ой", ex);
}What circumstances can prevent us? Thousands of them:
- the destination can be a folder, not a file at all
- the source may be a folder
- the source and destination can be the same file
- destination cannot be created
- etc.
The sadness is that using self-writing about everything we already know during the copy.
If we do according to the mind
import org.apache.commons.io.FileUtils;
try {
FileUtils.copyFile(src, new File(targetName));
} catch (IOException ex) {
log.error("ой", ex);
}that part of the checks will be performed before the start of copying, and the possible exception will be more informative (see source FileUtils::copyFile).
Neglecting @ Nullable / @ NotNull
Suppose we have an entity:
@Entity@GetterpublicclassUserEntity{
@Idprivate Long id;
@Columnprivate String email;
@Columnprivate String petName;
}In our case, the column emailin the table is described as not null, unlike petName. That is, we can mark the fields with appropriate annotations:
import javax.annotation.Nullable;
import javax.annotation.NotNull;
//...@Column@NotNullprivate String email;
@Column@Nullableprivate String petName;At first glance, this looks like a hint to the developer, and this is true. At the same time, these annotations are a much more powerful tool than a regular label.
For example, they are understood by development environments, and if after adding annotations we try to do this:
booleancheckIfPetBelongsToUser(UserEnity user, String lostPetName){
return user.getPetName().equals(lostPetName);
}then the “Idea” will warn us of the danger of this message:
Method invocation 'equals' may produce 'NullPointerException'
In code
booleanhasEmail(UserEnity user){
boolean hasEmail = user.getEmail() == null;
return hasEmail;
}there will be another warning:
Condition 'user.getEmail () == null' is always 'false'
This helps the built-in censor to find possible errors and helps us better understand the execution of the code. For the same purpose, annotations are useful to arrange over the methods that return value, and their arguments.
If my arguments seem inconclusive, then look at the sources of any serious project, the same "Spring" - they are hung with annotations like a Christmas tree. And this is not a whim, but a harsh necessity.
The only drawback, it seems to me, is the need to constantly maintain annotations in the current state. Although, if you look it out, this is rather a blessing, because going back to the code time after time, we understand it all the better.
Inattention
There are no errors in this code, but there is a surplus:
Collection<Dto> dtos = getDtos();
Stream.of(1,2,3,4,5)
.filter(id -> {
List<Integer> ids = dtos.stream().map(Dto::getId).collect(toList());
return ids.contains(id);
})
.collect(toList());It is not clear why creating a new list of keys that is being searched for, if it does not change when you walk through the stream. Well, that the elements of all 5, and if they will be 100,500? And if the method getDtosreturns 100,500 objects (in the list!), Then what performance will this code have? No, so better like this:
Collection<Dto> dtos = getDtos();
Set<Integer> ids = dtos.stream().map(Dto::getId).collect(toSet());
Stream.of(1,2,3,4,5)
.filter(ids::contains)
.collect(toList());Also here:
static <T, Q extends Query> voidsetParams(
Map<String, Collection<T>> paramMap,
Set<String> notReplacedParams,
Q query){
notReplacedParams.stream()
.filter(param -> paramMap.keySet().contains(param))
.forEach(param -> query.setParameter(param, paramMap.get(param)));
}Obviously, the value returned by the expression is inParameterMap.keySet()unchanged, so it can be put into a variable:
static <T, Q extends Query> voidsetParams(
Map<String, Collection<T>> paramMap,
Set<String> notReplacedParams,
Q query){
Set<String> params = paramMap.keySet();
notReplacedParams.stream()
.filter(params::contains)
.forEach(param -> query.setParameter(param, paramMap.get(param)));
}By the way, such areas can be calculated using the check 'Object allocation in a loop'.
When static analysis is powerless
Eighth Java has died down long ago, but we all love streams. Some of us love them so much that they use them everywhere:
public Optional<EmailAdresses> getUserEmails(){
Stream<UserEntity> users = getUsers().stream();
if (users.count() == 0) {
return Optional.empty();
}
return users.findAny();
}A stream, as is known, is fresh before the call on it is completed, so a repeated call to a variable usersin our code will result in IllegalStateException.
Static analyzers do not yet know how to report such errors, therefore responsibility for their timely catching falls on the reviewer.
It seems to me that using type variables Stream, as well as passing them as arguments and returning from methods, is like walking through a minefield. Maybe lucky, maybe not. Hence the simple rule: any appearance Stream<T>in the code should be checked (and in the good, immediately cut out).
Simple types
Many believe that boolean, intetc., is only about performance. This is partly true, but beyond that, the simple not nulldefault type . If the integer entity field refers to a column that is declared in the table as not null, then it makes sense to use int, but not Integer. This is a kind of combo - and memory consumption is lower, and the code is simplified due to the uselessness of checks for null.
That's all. Remember that all of the above is not the ultimate truth, think with your head and intelligently approach the use of any advice.