Data integrity in microservice architecture - how to ensure it without distributed transactions and rigid connectivity
Hello. As you may know, I used to write more and more about vaults, Vertica, big data vaults, and other analytic things. Now all other databases, not only analytical, but also OLTP (PostgreSQL) and NOSQL (MongoDB, Redis, Tarantool) have fallen into my area of responsibility.
This situation allowed me to look at an organization that has several databases as an organization that has one distributed heterogeneous (heterogeneous) database. A single distributed heterogeneous database consisting of a heap of PostgreSQL, Redis and Mong ... And, perhaps, from one or two Vertica bases.
The work of this single distributed database generates a bunch of interesting tasks. First of all, from a business point of view, it is important that everything is normal with the data moving through such a database. I specifically do not use the term integrity, consistency, because the term is complex, and in different nuances of considering a DBMS (A C ID and C AP theorem) it has a different meaning.
The situation with a distributed base is exacerbated if the company is trying to switch to the microservice architecture. Under the cat, I tell you how to ensure data integrity in a microservice architecture without distributed transactions and tight connectivity. (And at the very end I explain why I chose this illustration for the article).

According to Chris Richardson (one of the most famous evangelists of microservice architecture), there are two approaches to working with databases in this architecture: a shared database and a database-per-service.

Shared database is a good first step, a great solution for a small company without ambitious growth plans. At the same time, this pattern itself is an anti-pattern from the point of view of microservice architecture, since two services sharing a common base cannot be independently tested and scaled. Those. these services are more likely - one service that turns into a monolith.
The database-per-service pattern assumes that each service has its own database. A service can access data from another service only through the API (in a broad sense), without directly connecting to its database.
The database-per-service pattern allows the teams of the respective services to select databases as they like. Someone knows how to use MongoDB, someone believes in PostgreSQL, someone needs Redis (the risk of data loss when shutting down is acceptable for this service), and someone generally stores data in CSV files on disk (and why and no?).
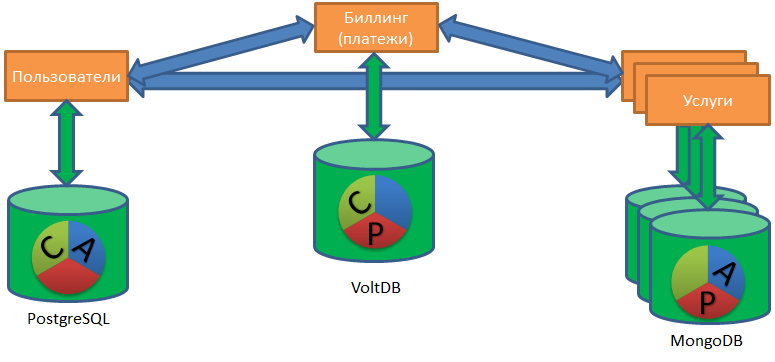
Working with such a "zoo" database raises the task of restoring data to a completely new level of complexity.
ACID and microservice architecture
Let's look at the task of restoring order through the prism of the classic database system ACID requirements: let's expand the essence of each letter of the abbreviation, and illustrate the difficulties with this letter in the microservice architecture.
(A) CID - Atomicity. Atomicity is all or nothing.
According to the requirement of Atomicity, it is necessary to perform all steps (with possible repetitions), in case of failure of an important step, to cancel the executed ones.
The following illustration demonstrates the test process of buying a VIP service: money is reserved in billing (1), the bonus service is connected to the user (2), the user type is changed to Pro (3), the reserved money in billing is written off (4). All four steps must either be executed or not executed.
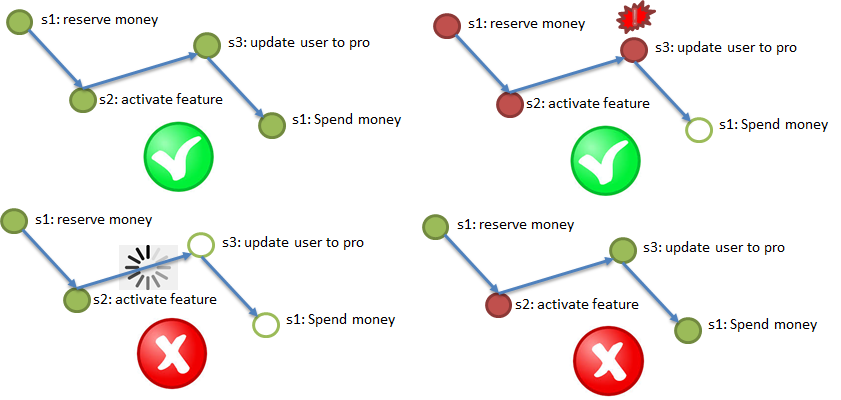
In this case, it is impossible to hang in the middle of the process, therefore asynchrony is preferable, in the extreme case - synchronism with the built-in timeout.
A (C) ID - Consistency. Consistency - each step should not contradict the boundary conditions.
Classic examples of conditions for, for example, sending money from client A in service 1 to client B in service 2: as a result of such sending money should not be less (money should not be lost when sending) or more (it is unacceptable to send the same money to two users at the same time). To comply with this requirement, you need to encode the conditions somewhere and check the data for the conditions (ideally, without additional requests).

ACI (D) - Durability. The requirement of Durability means that the effects of operations do not disappear.
Under Polyglot persistence conditions, the service can operate on a database that can “lose” the data recorded in it. Such a focus can be obtained even from solid bases like PostgreSQL, if asynchronous replication is enabled there. The illustration shows how changes recorded in the Master, but not reaching the Slave by asynchronous replication, can be destroyed by burning the Master server. To meet the Durability requirement, you need to be able to diagnose and repair such losses.
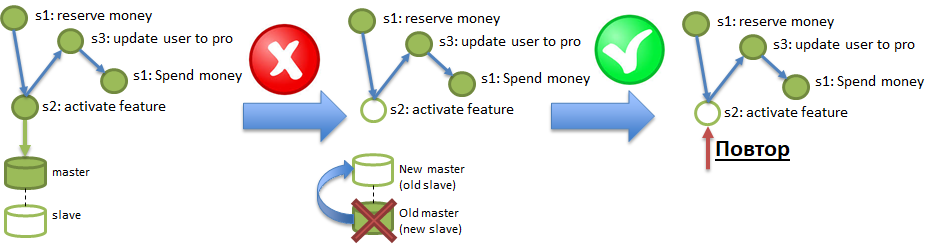
And where is I, you ask?
And nowhere. Isolation in the environment of several independent asynchronous services is a technical requirement. Modern research has shown that real business processes can be implemented without isolation. Isolation simplifies thinking by minimizing parallelism (the development of parallel computing is more difficult for a programmer), but microservice architecture is inherently massively parallel, isolation in such an environment is redundant.
There are many approaches to achieve compliance with the above requirements. The most widely known algorithm is distributed transactions, provided by the so-called two-phase commit (2PC). Unfortunately, the implementation of two-phase commits requires rewriting all the services involved. And the most serious: this algorithm is not very productive. The illustrations from recent studies show that this algorithm shows a certain performance on a distributed base of two servers, but as the number of servers grows, the performance does not grow linearly ... Or rather, it does not grow at all.

One of the main advantages of the microservice architecture is the ability to increase performance linearly just by adding more and more servers. It turns out that if a two-phase commit is used to ensure distributed integrity, then this process will become a bottleneck, a limiter for productivity growth, despite the increase in the number of servers.
How can we ensure distributed integrity (ACiD requirements) without two-phase commits, with the ability to scale linearly in performance?
Modern research (for example, An Evaluation of Distributed Concurrency Control. VLDB 2017 ) claims that the so-called “optimistic approach” can help. The difference between a two-phase commit and a generalized “optimistic approach” can be illustrated by the difference between the old Soviet store (with a counter) and a modern supermarket, such as Auchan. In a store with a counter, every customer is considered suspicious and served with maximum control. From here turns and conflicts. And in the supermarket, the buyer is by default considered to be honest, he is given the opportunity to go to the shelves and fill the carts. Of course, there are monitoring tools for catching crooks (cameras, guards), but most buyers never have to deal with them.
Therefore, the supermarket can be scaled, expanded, simply by putting more cashiers. It is the same with the microservice architecture: if distributed integrity is provided by the “optimistic approach”, when only processes where something went wrong are additionally loaded with checks. And normal processes go without additional checks.
Important. The “optimistic approach” includes several algorithms. I would like to tell you about the saga - the algorithm for maintaining distributed integrity, recommended by Chris Richardson.
Sagi - Algorithm Elements
The saga algorithm has two options. Therefore, first I would like to universally describe the required elements of the algorithm so that the description is suitable for both variants.
Element 1. A reliable persistent channel for event delivery between services, guaranteeing "at least once delivery". Those. if step 2 of the process is successfully completed, then the notification (event) of this should reach step 3 at least once, repeated deliveries are acceptable, but nothing should be lost. “Persistent” means that the channel must keep notifications for some time (2-3 days, a week) so that the service, which has lost the last changes due to the loss of the base (see the example about Durability, in the illustration is step 2), could restore these changes, having “replayed” events from the channel.
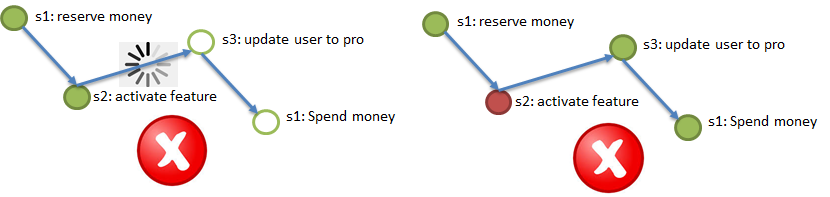
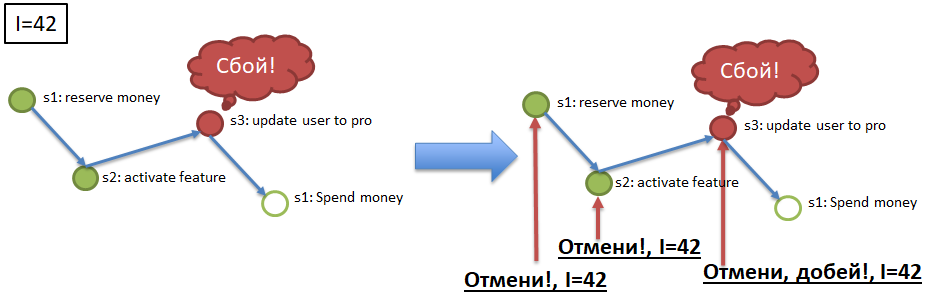
Element 2.Idempotency of service calls through the use of a unique idempotency key. Imagine that I (the user) initiate the process of buying a VIP package (see the example for Atomicity). At the beginning of the process, I am given a unique key, idempotency key, for example, 42. Next, each of the steps (1 → 2 → 3 → 4) should be called with the key of idempotency. The paragraph above mentions the possibility of re-entering the same message in the service (in step). The service (step) should automatically be able to ignore the repeated arrival of the processed event, checking for repetition using the idempotency key. That is, if all services (process steps) are idempotent, then to meet the requirements of Atomicity and Durability, it is enough to forward them to the steps corresponding to the events from the channels. The steps that missed the events will execute them, and the steps that have already completed the events

Element 3. Cancellation of calls to services (steps) by key idempotency.
To ensure Atomicity (see example), if a process with key idempotency 42, for example, stopped / fell in step 3, then you must cancel the successful execution of steps 1 and 2 for key 42. To do this, each mandatory process step must have a “compensating” step , API method that cancels the execution of a mandatory step for the specified idempotency key (42). The implementation of compensating calls is a difficult but necessary element in the refinement of services as part of the implementation of the saga algorithm.
The above three elements are relevant for both variants of the implementation of the sag: orchestrated and choreographic.
Orchestrated sagas
A simpler and more obvious algorithm for orchestrated sagas is easier to understand and implement. In his excellent article, kevteev described the algorithm and the process of implementing the mechanism of orchestrated sagas in Avito. Their algorithm assumes the existence of a controlling service, “orchestrating” the calls of services within the framework of the serviced business processes. The same controlling service may have its own database (for example, PostgreSQL), acting as a reliable persistent event delivery channel (element 1).
Choreographic sagas
With choreographic saga smarter. Here, a reliable data channel should act as a data bus that implements the following requirements: at least once delivery. Those. Each step of each process should receive a command to trigger from the bus, and throw the same message on the successful implementation, on the start of the next step, so that he also read it from the bus and continue the process. In this case, each message may be several subscribers.
In the choreographic saga, there should also be a controlling service, a saga service, but much more “lightweight”. The service should be aware of the business processes registered in the system, the composition of the steps involved in each process. He also has to listen to the bus, monitor the performance of each process (each key of idempotency), and only if something went wrong, either throw "repetitions" of specific steps, or throw "cancellations", "compensations" for the completed steps.
Nuances
One of the most important nuances of the sagas, distinguishing them from classical transactions, is a departure from linearity, consistency, and the obligatory nature of each step. The saga is not necessarily a linear chain of events, this can be a directed graph: a new user registration event can spawn several steps in parallel (sending sms, registering a login, generating a password, sending a letter), some of which may be optional. In the first approximation, it seems that in such an “extensive” saga with optional steps it is difficult to determine the completion of the saga (process), but in fact everything is simple: the saga (process) is completed when all the required steps are completed, in any order.

The second nuance, characteristic rather for choreographic sagas, but also possible for orchestrated ones, consists in choosing an approach to registering business processes, types of sagas in the sagas service. The example for Atomicity describes a process of four consecutive required steps.
Who registered this process, indicated all steps, placed dependencies and obligatory steps? The obvious, but old-fashioned answer is that the registration of the process must be carried out centrally, in the service sagas. But this answer is not very consistent with the microservice architecture. In the microservice architecture, it is more promising, more productive and more quickly to register the processes from the bottom up. Those. not to prescribe all the nuances of the process in the service of the sagas, but to enable individual services to “fit in” with existing processes, indicating their commitment / non-obligation and obligatory predecessors.
Those. The process of registering a user in a saga service may initially consist of three steps, and then, during the development of the system, seven more steps will fit in there, and one step will be written out, and there will be nine of them. Such an “anarchic” and “decentralized” scheme is difficult for testing, for implementing a rigorous and coordinated process, but it is much more convenient for Agile teams, for continuous multidirectional product evolution.
Actually here. With a serious statement, I think it is worth finishing, but the article turned out to be too big.
Here is a link to the presentation of this material, a report on this topic I did on Highload Siberia 2018.
UPD - and video from the conference:
Epilogue
Finally I would like to try to explain everything listed above in a more figurative language.
What is the saga originally? This is a plot, this is an adventure from the Middle Ages ... Or from the Game of Thrones. An event occurs (a battle, a wedding, someone dies), the message about it flies through the world through messengers, through post pigeons, through merchants. When the message comes to those interested (in a week, in a month, in a year), they react: they send armies, declare war, execute someone, and new messages fly.
There is no controlling authority over the sequence of actions. No transactions, no rollback, in the sense of canceling the action, as if it never existed. All grown-up, every action takes place forever. It can be compensated, but it is precisely the action (murder) and compensation (payment for the head, vira), and not the abolition of death.
Events go on for a long time, come from different sources, actions take place in parallel, rather than strictly sequentially. And quite often new participants suddenly appear in the story who decide to take part (dragons fly;)) ... and some of the old participants die suddenly.
So it goes. It seems a mess and chaos, but everything works, the internal consistency of the world is not broken, the plot develops and is consistent ... Although sometimes unpredictable.