Lean Big Data on 6 Google services
Hello Habr! I want to tell how we made our own Big Data.
Every startup wants to build something cheap, high-quality and flexible. Usually this does not happen, but we seem to have succeeded! Below is a description of our decision and a lot of my purely subjective opinion on this matter.
And yes, the secret is that 6 Google services are used and almost no native code was written.
What was needed?
I work in a fun Singaporean startup - Bubbly, which makes a voice social network. The trick is that you can use it without a smartphone, a good enough old nokia. The user calls a special number and can listen to messages, record their messages, etc. All voice, you do not even need to be able to read to use.
In Southeast Asia, we have tens of millions of users. But since it works through mobile operators, in other countries no one knows anything about us. These users generate a huge amount of activity that you want to register and analyze in every possible way:
- Make a beautiful dash board with key metrics updated online
- Monitor service operation and errors
- Do A \ B tests and analyze user behavior
- Report to our partners
- ...
In general, tasks that everyone needs and always practically.
Why reinvent the wheel?
It would seem - why build something if there are already ready-made solutions? Such motives led me:
1. I do not want to use Mixpanel (sorry gays!)
- If there is no complete control over the data, then there will always be a question that someone else's ready-made system does not answer. Yes, I know that there are Mixpanel export APIs and they allow a lot. But in fact, so many times already stumbled upon such situations. I want complete control.
- A bunch of all kinds of “Wishlist” will have to be screwed into someone else's proprietary product, which is not very convenient. For example, SMS-alert to the support manager, if something is broken. Or special reports to third-party partners. And such features you cannot predict in advance.
- It is really expensive! I know that many, instead of all the data, upload only a random sample there, in order to somehow reduce costs. But this is a very dubious happiness in itself.
2. If you really want your “own” solution, why not stir up Hadoop with all the stuffing?
- You need to raise the server and configure everything. Of course there is hosted Hadoop, where everything is already “configured”, but you still have to deal with these settings.
- Hadoop is just storage and queries. All other features will have to do yourself.
MySQL clearly does not fit the task, since we have too much data for it.
Briefly how it works for us
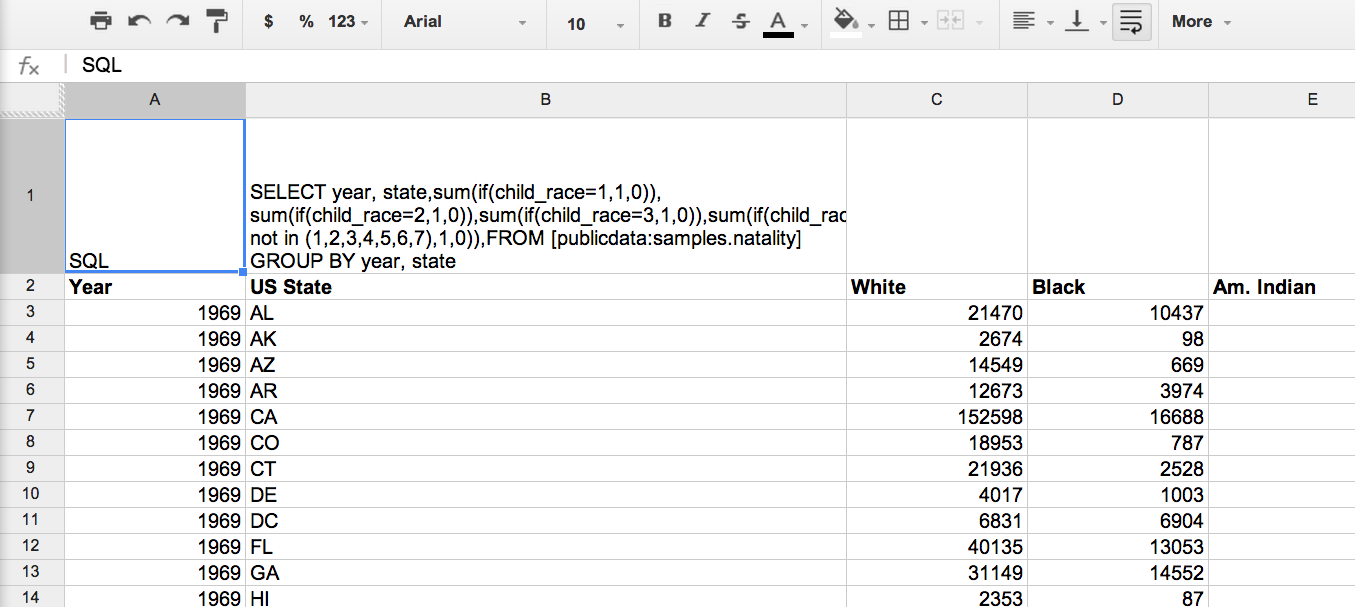
- We fill all the "events" from users from our servers in Google Big Query
- We use Google Spreadsheets for queries to Big Query and subsequent data processing. All logic sits in Spreadsheets and scripts attached to it.
- Next, visualize the received data using Google Charts.
- Host these graphics on Google Drive
- In a single "dash board" these charts are collected in Google Sites
- Finally, on top of the Google Sites is Google Analytics, which looks after the users of all this analytics.
The advantages of this approach (no, I’m not promoting Google for money, it's a pity )
Big Query - Pros
- This database can store a huge amount of data. The issue of scalability is not worth it.
- It costs a penny compared to other solutions. I write about the costs below separately.
- In fact, any request takes less than 20 seconds. This is very different from Hadoop, where the score is at best for minutes. For standard queries defined once and for all, the difference seems small. But if you look at the data “in free flight” (ad hoc) or repair something by trial and error, then even small pauses break the entire workflow and reduce the efficiency of the analyst’s work at times. But in life it turns out that you only do such tasks all day. A very important advantage of Big Query.
- Small buns like the web interface really help a lot.
Improvements:
I really wanted Big Query to make schemaless, just to add events to the system and not think about anything. Therefore, a piece of code was screwed to the loader, which checks the current table layout in Big Query and compares it with what it wants to load. If there are new columns, they are added to the table through the Big Query API.
Google Spreadsheets - Pros
There is nothing better than spreadsheets for data analysis. This is my axiom. Spreadsheets is better suited for this task than MS Excel (no matter how much I love it). The reasons are as follows:
- Works with Big Query out of the box ( Goolge Tutorial )
- Everything is in the cloud and scripts can update data on a schedule
- Cross-platform! It works equally under PC and Mac.
- Already have a bunch of useful features - email, etc.
Improvements: The
script from the tutorial has been slightly modified. Now he checks each sheet in spreadsheets. If “SQL” is written in cell A1, then in A2 lies a query for Big Query. The script will put the query results on the same sheet.
This is to avoid touching the code at all when using it. Created a new sheet, wrote a request, got the result.
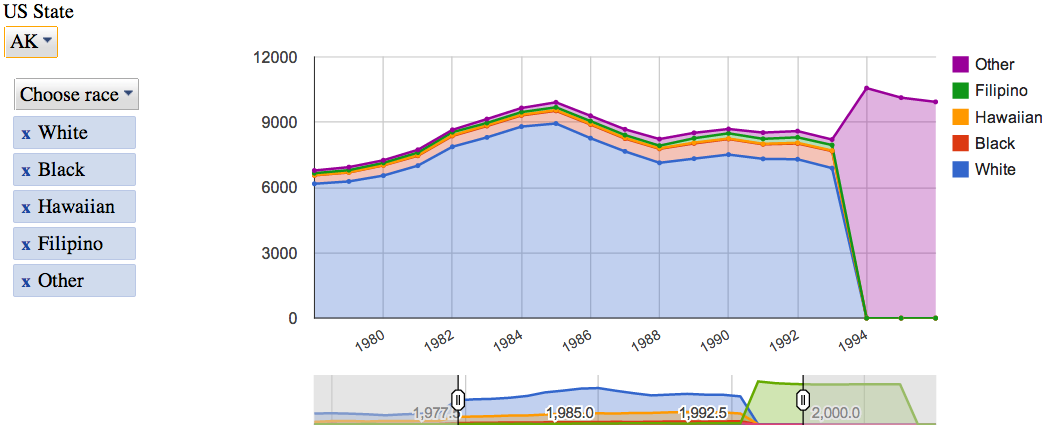
Google Charts - Pros
- There are a lot of visualization libraries, but there is a feeling that Google is more reliable and functional (unless of course they write Charts as Reader).
- Works with Spreadsheets out of the box ( tutorial from Google )
- They were bribed by their interactive controls, which allow even business people who use neither SQL nor Excel to play quite deeply with data.

Google Sites / Google Drive - Pros
- You can use Google’s developed system of access rights. You cannot give read-olny access to Dropbox, but you can.
- Google Sites has a wysiwyg editor, which I personally really like.
- After I built the whole system on Google services, I decided to use them to the end from the principle.
Google analytics
Recursion! Our Dash Board has about 30 users. Enough to analyze resource usage statistics. Google Sites, which is not surprising, integrates with Google Analytics in a couple of clicks. Website traffic objectively shows which data is most interesting in order to improve the system in this direction.
About Solution Costs
I believe that in any system the most expensive is the time required for development and the man-days spent on development and support. In this sense, this solution is ideal, since almost no code was written. The whole project was done by one person, in parallel with other tasks, and the first version was made in a month.
There are, of course, suspicions that the integration between Google services may break (their tutorial shows that this has already happened) and support efforts will be required. But I do not expect anything wrong.
As for direct costs, in the whole system only Big Query costs money. Paid data storage and data requests. But it's just a penny! We write 60 million events a day and have never paid more than 200 USD per month.
Important add-on to Big Query
Big Query scans the entire table by default. If all-time events are stored in one place, then requests become slower and more expensive over time.
The most recent data is always the most interesting, so we came to the monthly rotation of these tables. Every month, the events table is backed up in events_201401Jan, events_201402Feb, and so on.
To make queries convenient for such a structure, we expanded the SQL language a bit. Fortunately, everything controls its own script from Spreadsheets, and it can parse and process our requests as needed. Added the following commands:
- FROMDATASET dataset - queries in turn all the tables in the data set. This is in case you need to request data for the entire period of time
- FROMLAST table - queries the current table and the table for the last month. This is for queries that need data for the last 7 days, for example. So that at the beginning of the month the request returns a full 7 days, and not what is for the current month.
Future plans:
- Saw a script running SQL. I want him to know all sorts of useful transformations like PIVOT, etc.
- Jigsaw JavaScript for Google Charts. Ideally, I want to get rid of the need to touch the code at all. In order to, like in Excel pivot charts, switch the type of chart with one click, and which series on which axis, etc. But these are global plans.
- I want to experiment with nested data. We can sort all events from a separate user session on a server into one record. That is, the events within the session (the call in our case) will be the "children" of this session. In theory, this should simplify some confused queries.
How this all works can be seen in the example here .
I really want knowledgeable people to say their opinion. For this, this article was written.
PS I ask to write about errors in the text and my Englishisms in PM, I will correct everything.
PPS I'm not a programmer at all, so my code can be scary (but it works!). I will be glad to constructive criticism.