Import open geo data from OpenGeoDB into Elasticsearch
- Transfer
- Tutorial
Have you ever wondered, having found a neat public database, how good it would be to include it in your application in order to optimize any functionality, even if only slightly? Of course! This post will tell you how to use Logstash to turn an external data set into the desired format, check the result in Kibana and make sure that the data is correctly indexed in Elasticsearch so that it can be used under heavy loads on live servers.
OpenGeoDB is a German site that contains geo data for Germany in SQL and CSV formats. Since we want to store data in Elasticsearch, SQL is not suitable for us, just like CSV. However, despite this, we can use Logstash to convert and index data into Elasticsearch. The file we are about to index contains a list of cities in Germany, including all their postal codes. This data is available for download from the OpenGeoDB website (download file) under a public domain license .
We are interested in the fields name, lat, lon, area, population and license tag . We will return to them soon ...
The next step is to put the data in Elasticsearch. First of all, we will configure Logstash. Copy the config below to the opengeodb.conf file. Note that we use the “csv” filter (comma-separated values), even though the delimiter is a tab, not a comma.
Before proceeding, note that this is how we will run Logstash to index the data. Elasticsearch must be running.
At this stage, quite a lot of things happen (indexing can take a minute or more, it all depends on your equipment). The first thing you can pay attention to is that the Logstash configuration does not use input with the “file” instruction. This is because this input method behaves like “tail -f” on UNIX systems, that is, it expects new data to be added to the file. Our file, on the contrary, has a fixed size, so it would be more reasonable to read all its data using the input “stdin”.
The filter section consists of six steps. Let's take a closer look at them and explain what each of them does.
The output section is only available in Logtash since version 1.4, so make sure you have at least a version. In the previous version, you need to explicitly specify the output of "elasticsearch_http". Looking ahead, I’ll say that there will be only one “elasticsearch” output and you can specify protocol => http to use HTTP through port 9200 to connect to Elasticsearch.
You can use this, for example, for such purposes:
All this is very good, but it does not help us to improve existing applications. We need to go deeper.
Let's digress for a moment and see what useful things can be done with this data. We have cities, postal codes ... and many cases in web applications where it is necessary to enter these particular data.
A good example is the checkout process. Not every store has user data in advance. This can be a store in which orders are often one-time or even an order can be made without registration. In this case, it may be appropriate to help the user expedite the checkout process. In this case, the “free” bonus will be to prevent the loss of an order or cancellation due to the difficulties of placing an order.
Elasticsearch has a very fast prefix search functionality called “completion opinester”. But this search has a drawback. You need to slightly supplement your data before indexing, but for this we have Logstash. In order to better understand this example, you may need to read the introduction to the “completion opinester” .
Suppose we want to help the user enter the name of the city in which he or she lives. We would also like to provide a list of zip codes to make it easier to find the one that fits your chosen city. You can also do the opposite, first letting the user enter a zip code, and then automatically fill out information about the city.
It's time to make a few changes to Logstash's configuration to get it working. Let's start with a simple configuration inside the filter. Add this configuration snippet to your opengeodb.conf, immediately after step 5 and before step 6.
Logstash will now write the data in a structure compatible with the “completion≤sester” when it will index the data again. However, you also need to configure the field matching pattern so that the tooltip function is configured in Elaticsearch as well. Therefore, you also need to explicitly specify the template in the Logstash settings in the output> elastichsearch section.
This template is very similar to the default Logstash template, but suggest and geo_point fields are added.
Now it's time to delete the old data (including the index) and start reindexing
Now it is possible to fulfill the request to the soot
And here is the result:
Now, as you may have noticed, it is logical to use the population of the city as its weight. Big cities will be at a tip higher than small cities. The returned result contains the name of the city and all its zip codes, which can be used to automatically fill out the form (especially if only one zip code is found).
And that’s all for today! However, remember that this is not only suitable for public databases. I am absolutely sure that somewhere, deep inside your company, someone has already collected useful data that is just waiting to be supplemented and used in your applications. Ask your colegs. You will find such databases in any company.
Thanks.
Download data
I will assume that you already have the latest version of Elasticsearch and Logstash installed. I will use Elasticsearch 1.1.0 and Logstash 1.4.0 in the following examples.OpenGeoDB is a German site that contains geo data for Germany in SQL and CSV formats. Since we want to store data in Elasticsearch, SQL is not suitable for us, just like CSV. However, despite this, we can use Logstash to convert and index data into Elasticsearch. The file we are about to index contains a list of cities in Germany, including all their postal codes. This data is available for download from the OpenGeoDB website (download file) under a public domain license .
Data format
After reviewing the data, you can see that they consist of the following columns:- loc_id: unique identifier (inside the database)
- ags: state administrative code
- ascii: short name in capital letters
- name: entity name
- lat: latitude (coordinates)
- lon: longitude (coordinates)
- amt: not used
- plz: zip code (if more than one, then separated by a comma)
- vorwahl: phone code
- einwohner: population
- flaeche: square
- kz: car license plate series
- typ: administrative unit type
- level: an integer that determines the location of the terrain in the hierarchy
- of: identifier of the area of which this area is a part
- invalid: column is invalid
We are interested in the fields name, lat, lon, area, population and license tag . We will return to them soon ...
Indexing entries in Elasticsearch
use csv logstash filter
The next step is to put the data in Elasticsearch. First of all, we will configure Logstash. Copy the config below to the opengeodb.conf file. Note that we use the “csv” filter (comma-separated values), even though the delimiter is a tab, not a comma.
input {
stdin {}
}
filter {
# Step 1, possible dropping
if [message] =~ /^#/ {
drop {}
}
# Step 2, splitting
csv {
# careful... there is a "tab" embedded in the next line:
# if you cannot copy paste it, press ctrl+V and then the tab key to create the control sequence
# or maybe just tab, depending on your editor
separator => ' '
quote_char => '|' # arbitrary, default one is included in the data and does not work
columns => [ 'id', 'ags', 'name_uc', 'name', 'lat', 'lon', 'official_description', 'zip', 'phone_area_code', 'population', 'area', 'plate', 'type', 'level', 'of', 'invalid' ]
}
# Step 3, possible dropping
if [level] != '6' {
drop {}
}
# Step 4, zip code splitting
if [zip] =~ /,/ {
mutate {
split => [ "zip", "," ]
}
}
# Step 5, lat/lon love
if [lat] and [lon] {
# move into own location object for additional geo_point type in ES
# copy field, then merge to create array for bettermap
mutate {
rename => [ "lat", "[location][lat]", "lon", "[location][lon]" ]
add_field => { "lonlat" => [ "%{[location][lon]}", "%{[location][lat]}" ] }
}
}
# Step 6, explicit conversion
mutate {
convert => [ "population", "integer" ]
convert => [ "area", "integer" ]
convert => [ "[location][lat]", "float" ]
convert => [ "[location][lon]", "float" ]
convert => [ "[lonlat]", "float" ]
}
}
output {
elasticsearch {
host => 'localhost'
index => 'opengeodb'
index_type => "locality"
flush_size => 1000
protocol => 'http'
}
}
Before proceeding, note that this is how we will run Logstash to index the data. Elasticsearch must be running.
cat DE.tab | logstash-1.4.0/bin/logstash -f opengeodb.conf
At this stage, quite a lot of things happen (indexing can take a minute or more, it all depends on your equipment). The first thing you can pay attention to is that the Logstash configuration does not use input with the “file” instruction. This is because this input method behaves like “tail -f” on UNIX systems, that is, it expects new data to be added to the file. Our file, on the contrary, has a fixed size, so it would be more reasonable to read all its data using the input “stdin”.
The filter section consists of six steps. Let's take a closer look at them and explain what each of them does.
step 1 - ignore comments
The first step is to get rid of the comments. They can be identified by the pound symbol at the beginning of the line. This is necessary because the first line in our file is just such a comment that contains the column names. We do not need to index them.step 2 - disassemble csv
The second step does all the hard work of parsing the CSV. You need to redefine “separator” with the value “tab” (tab), “quote_char” has one quotation mark by default, which is present in the values of our data and therefore must be replaced by another character. The property “columns” defines the names of the columns that will be used later as field names.Attention! When copying a file from here, you will need to replace the “separator” character, since instead of a tab, it will be copied as a few spaces. If the script does not work properly, check this first.
step 3 - skip unnecessary entries
We only need records that display information about cities (those with a “level” field of 6). We simply ignore the rest of the entries.step 4 - process the zip code
The fourth step is for proper postal code processing. If the record has more than one zip code (such as in large cities), then they are all contained in one field, but separated by commas. To save them as an array, and not as a single large line, we use the mutate filter to separate the values of this field. Here, for example, the content of this data in the form of an array of numbers will allow us to use a search on a range of numerical values.step 5 - geo data structure
The fifth step will save the geo data in a more convenient format. When reading from the DE.dat file, separate lat and lon fields are created. However, the meaning in these fields is only when they are stored together. This step writes both fields to two data structures. One looks like the Elasticsearch type geo_point , and as a result, the structure {"location": {"lat": x, "lon": y}}. The other looks like a simple array and contains longitude and latitude (in that order!). So we can use the Kibana bettermap component to display the coordinates.step 6 - explicit casting of fields to type
The last filter step explicitly assigns data types to certain fields. Thus, Elasticsearch will be able to perform numerical operations with them in the future.The output section is only available in Logtash since version 1.4, so make sure you have at least a version. In the previous version, you need to explicitly specify the output of "elasticsearch_http". Looking ahead, I’ll say that there will be only one “elasticsearch” output and you can specify protocol => http to use HTTP through port 9200 to connect to Elasticsearch.
We use Kibana and Elasticsearch for data visualization.
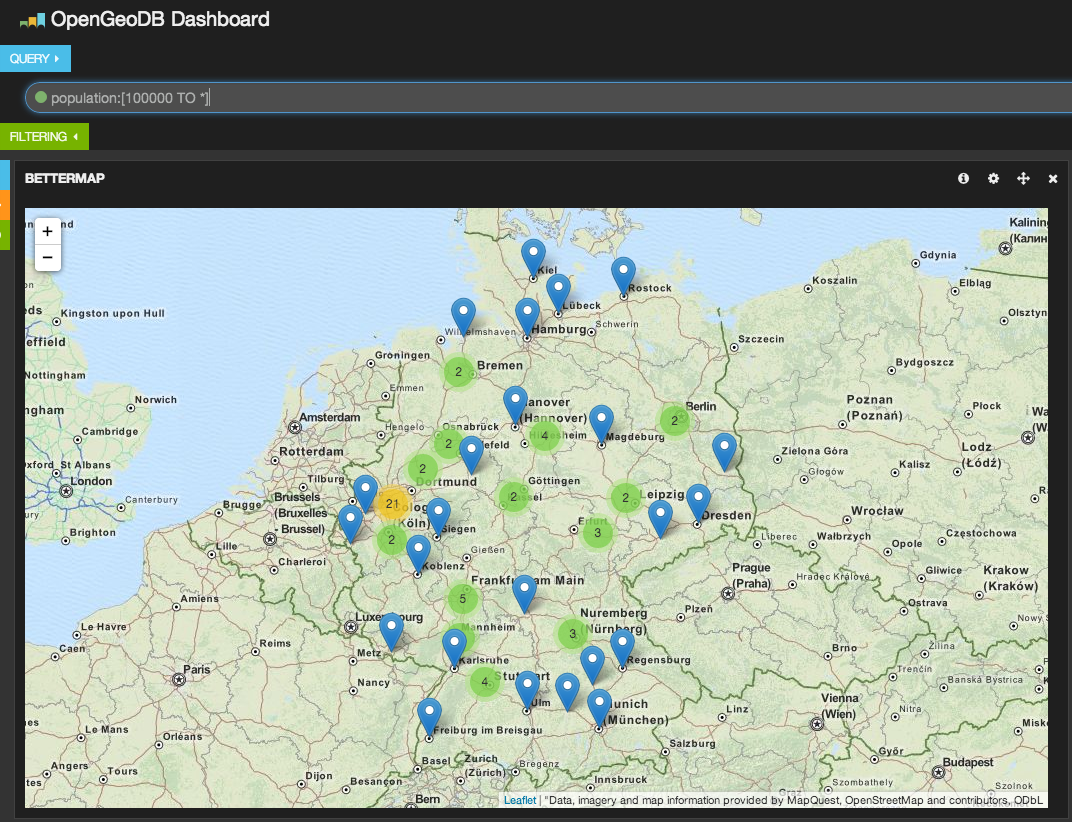
When the data is indexed, we can use Kibana for further analysis. Using the bettermap widget and a simple search query like population: [10000 TO *] we can display every big city in Germany.You can use this, for example, for such purposes:
- Find the cities with the largest population
- Find cities that use the common series of car license plates (for example, GT is used in and around Gütersloh)
- Use the aggregation script to find areas with the most dense or sparse population per square kilometer. You can also pre-calculate these figures in Logstash.
All this is very good, but it does not help us to improve existing applications. We need to go deeper.
Set up auto-completion
Let's digress for a moment and see what useful things can be done with this data. We have cities, postal codes ... and many cases in web applications where it is necessary to enter these particular data.
A good example is the checkout process. Not every store has user data in advance. This can be a store in which orders are often one-time or even an order can be made without registration. In this case, it may be appropriate to help the user expedite the checkout process. In this case, the “free” bonus will be to prevent the loss of an order or cancellation due to the difficulties of placing an order.
Elasticsearch has a very fast prefix search functionality called “completion opinester”. But this search has a drawback. You need to slightly supplement your data before indexing, but for this we have Logstash. In order to better understand this example, you may need to read the introduction to the “completion opinester” .
Tips
Suppose we want to help the user enter the name of the city in which he or she lives. We would also like to provide a list of zip codes to make it easier to find the one that fits your chosen city. You can also do the opposite, first letting the user enter a zip code, and then automatically fill out information about the city.
It's time to make a few changes to Logstash's configuration to get it working. Let's start with a simple configuration inside the filter. Add this configuration snippet to your opengeodb.conf, immediately after step 5 and before step 6.
# Step 5 and a half
# create a prefix completion field data structure
# input can be any of the zips or the name field
# weight is the population, so big cities are preferred when the city name is entered
mutate {
add_field => [ "[suggest][input]", "%{name}" ]
add_field => [ "[suggest][output]", "%{name}" ]
add_field => [ "[suggest][payload][name]", "%{name}" ]
add_field => [ "[suggest][weight]", "%{population}" ]
}
# add all the zips to the input as well
mutate {
merge => [ "[suggest][input]", zip ]
convert => [ "[suggest][weight]", "integer" ]
}
# ruby filter to put an array into the event
ruby {
code => 'event["[suggest][payload][data]"] = event["zip"]'
}
Logstash will now write the data in a structure compatible with the “completion≤sester” when it will index the data again. However, you also need to configure the field matching pattern so that the tooltip function is configured in Elaticsearch as well. Therefore, you also need to explicitly specify the template in the Logstash settings in the output> elastichsearch section.
# change the output to this in order to include an index template
output {
elasticsearch {
host => 'localhost'
index => 'opengeodb'
index_type => "locality"
flush_size => 1000
protocol => 'http'
template_name => 'opengeodb'
template => '/path/to/opengeodb-template.json'
}
}
This template is very similar to the default Logstash template, but suggest and geo_point fields are added.
{
"template" : "opengeodb",
"settings" : {
"index.refresh_interval" : "5s"
},
"mappings" : {
"_default_" : {
"_all" : {"enabled" : true},
"dynamic_templates" : [ {
"string_fields" : {
"match" : "*",
"match_mapping_type" : "string",
"mapping" : {
"type" : "string",
"index" : "analyzed",
"omit_norms" : true,
"fields" : {
"raw" : {"type": "string", "index" : "not_analyzed", "ignore_above" : 256}
}
}
}
} ],
"properties" : {
"@version": { "type": "string", "index": "not_analyzed" },
"location" : { "type" : "geo_point" },
"suggest" : { "type": "completion", "payloads" : true, "analyzer" : "whitespace" }
}
}
}
}
Now it's time to delete the old data (including the index) and start reindexing
curl -X DELETE localhost:9200/opengeodb
cat DE.tab | logstash-1.4.0/bin/logstash -f opengeodb.conf
Now it is possible to fulfill the request to the soot
curl -X GET 'localhost:9200/opengeodb/_suggest?pretty' -d '{
"places" : {
"text" : "B",
"completion" : {
"field" : "suggest"
}
}
}'
And here is the result:
{
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"places" : [ {
"text" : "B",
"offset" : 0,
"length" : 1,
"options" : [ {
"text" : "Berlin",
"score" : 3431675.0, "payload" : {"data":["Berlin","10115","10117","10119","10178","10179","10243","10245","10247","10249","10315","10317","10318","10319","10365","10367","10369","10405","10407","10409","10435","10437","10439","10551","10553","10555","10557","10559","10585","10587","10589","10623","10625","10627","10629","10707","10709","10711","10713","10715","10717","10719","10777","10779","10781","10783","10785","10787","10789","10823","10825","10827","10829","10961","10963","10965","10967","10969","10997","10999","12043","12045","12047","12049","12051","12053","12055","12057","12059","12099","12101","12103","12105","12107","12109","12157","12159","12161","12163","12165","12167","12169","12203","12205","12207","12209","12247","12249","12277","12279","12305","12307","12309","12347","12349","12351","12353","12355","12357","12359","12435","12437","12439","12459","12487","12489","12524","12526","12527","12529","12555","12557","12559","12587","12589","12619","12621","12623","12627","12629","12679","12681","12683","12685","12687","12689","13051","13053","13055","13057","13059","13086","13088","13089","13125","13127","13129","13156","13158","13159","13187","13189","13347","13349","13351","13353","13355","13357","13359","13403","13405","13407","13409","13435","13437","13439","13442","13465","13467","13469","13503","13505","13507","13509","13581","13583","13585","13587","13589","13591","13593","13595","13597","13599","13627","13629","14050","14052","14053","14055","14057","14059","14089","14109","14129","14163","14165","14167","14169","14193","14195","14197","14199"]}
}, {
"text" : "Bremen",
"score" : 545932.0, "payload" : {"data":["Bremen","28195","28203","28205","28207","28209","28211","28213","28215","28217","28219","28237","28239","28307","28309","28325","28327","28329","28355","28357","28359","28717","28719","28755","28757","28759","28777","28779","28197","28199","28201","28259","28277","28279"]}
}, {
"text" : "Bochum",
"score" : 388179.0, "payload" : {"data":["Bochum","44787","44789","44791","44793","44795","44797","44799","44801","44803","44805","44807","44809","44866","44867","44869","44879","44892","44894"]}
}, {
"text" : "Bielefeld",
"score" : 328012.0, "payload" : {"data":["Bielefeld","33602","33604","33605","33607","33609","33611","33613","33615","33617","33619","33647","33649","33659","33689","33699","33719","33729","33739"]}
}, {
"text" : "Bonn",
"score" : 311938.0, "payload" : {"data":["Bonn","53111","53113","53115","53117","53119","53121","53123","53125","53127","53129","53173","53175","53177","53179","53225","53227","53229"]}
} ]
} ]
}
Now, as you may have noticed, it is logical to use the population of the city as its weight. Big cities will be at a tip higher than small cities. The returned result contains the name of the city and all its zip codes, which can be used to automatically fill out the form (especially if only one zip code is found).
And that’s all for today! However, remember that this is not only suitable for public databases. I am absolutely sure that somewhere, deep inside your company, someone has already collected useful data that is just waiting to be supplemented and used in your applications. Ask your colegs. You will find such databases in any company.
From translator
This is my first translation. Therefore, I am grateful in advance to everyone who will help improve it and point out my mistakes.Thanks.