Web Application Evolution
It’s fun for everyone to discuss “everything new is bad,” and for the last couple of years we have been enthusiastically discussing and trying NoSQL / NewSQL on the server and Angular / Knockout / Ember on the client. But these trends seem to be at an end. A great moment to sit down and think about what's next. As M. Andreessen said, "software is eating the world." At the same time, mobile / web apps eat regular apps. Therefore, it is especially interesting to figure out, but where is everything heading in the world of mobile and web applications? After all, they, it turns out, eat everyone at all. I believe the next Big Topic will be data synchronization, and here's why.
In a browser, developers are already building fully-fledged “normal” MVC applications. MVC architecture itself is not new (from the 1970s), but it only came to the web 10 years ago, along with Google Mail. It is interesting that initially the GMail project was perceived as a stray for geeks, but, as Larry Page said then, “normal users would look more like us in 10 years' time” . Well, it worked, and GMail now uses everything.
With the advent of HTML5, the browser already has its own data store (even two), its own business logic in JavaScript and its permanent connection to the server. Now, developers are trying to combine the best of two worlds: the availability and instant response of local applications and the constant "online mode" of web applications.

The main source of discomfort is server requests. This is especially felt on mobile devices. The irony is that wireless Internet crashes when it is most needed - on the road (in the subway), at public events and in the fields. At home and at work at the table, he runs smoothly, thanks a lot, just not much needed. And even then, in the same Yandex office, WiFi is not perfect - apparently, due to the concentration of geeks per square meter. At conferences like FOSDEM, WiFi never worked.
You might think that with LTE the problem will disappear. Unlikely. We see that throughput, storage capacity, chip density are growing exponentially, and RTT (server response time) and CPU frequency have improved very little over the past 10 years - due to physics. For mobile networks, physics is millions of tons of concrete, reinforcement and rock, and the properties of the radio spectrum that are not going anywhere. Saves data caching and background synchronization, the same GMail and here in front of everyone. Dropbox is also happy in this regard, but Evernote is not very happy - it is full of complaints about synchronization failures and data loss.

Let’s think it over. More data and logic is moving to the client. WebStorage, CoreData, IndexedDB. There is more data, more space on the client, and jogging to the server does not get any easier. Downloading data is simple, caching is even easier, and rocket science begins with synchronization. A failed mobile “saves” empty data to the server - oops, lost, the user is dissatisfied. The data is changed on several devices at once - oops, conflict, the user grinds his teeth. And how many more such oops will be. The new conditions on the client are already reminiscent of the conditions in "large" systems - a lot of pieces of equipment, a lot of data replicas, everything is constantly breaking everywhere and this is normal. It seems that the client will soon need tools from the arsenal of "big boys".
On the server, once it all started simply and logically - nothing portended trouble. There was one source of truth - the database (say, MySQL), there was one server with logic (say, PHP), and the client received a flat View and pulled the logic on the server through HTTP GET requests. At first, everyone scored the logic scaling simply - through the multiplication of stateless servers. The database gradually began to require replication (master-slave), then it was necessary to protect it with a cache (Memcache) and add pusher to send events to the client in real time. Then the situation began to complicate further. Hadoop was screwed somewhere, somewhere NoSQL, somewhere graph database - there were a lot of storages. Also, everything was overgrown with specialized services - analytics, search, mailing, etc. etc.
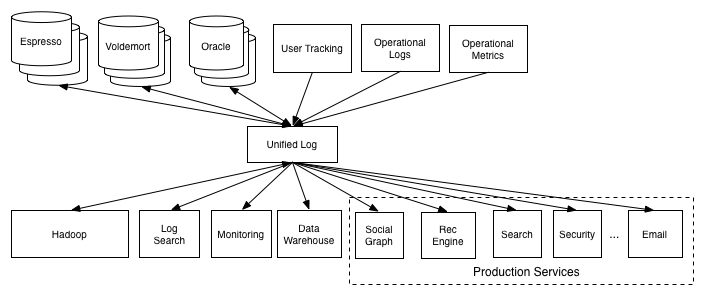
All this rapid multiplication of specialized systems also raised the problem of data synchronization. As the most successful solution for the "zoo", many mention Apache Kafka . In such an architecture, different data slices are stored in different systems that prefer to exchange events via the “bus”. Indeed, when integrating N systems, you can write either O (N * N) adapters or one common event queue. With N = 2..3, this nuance is still not very noticeable, but on LinkedIn, apparently, N is great.
And now two cigarette butts at the same time. Imagine the number of replicas of the same data in the system - both on the server and on the client side. Let's say MongoDB + Redis + Hadoop + WebStorage + CoreData. How to synchronize all this competently?
So what will be the future trends? No one will say for sure, but you can figure out what to look for. Indeed, new ideas appear extremely slowly and extremely rarely. For example, MongoDB uses master-slave replication via oplog, which differs from MySQL replication through the binlog only in incremental improvements and is based on the work of state machine replication from 1979-1984 by Leslie Lamport.
NoSQL systems - Riak, Voldemort, Cassandra, CouchDB try to make a significant step forward and squeeze something out of eventual consistency, causal order, logical and vector clocks - these approaches go back to the works of the same L.Lamport and C.Fidge of the late eighties.
The super-duper Operational transformation simultaneous editing technology from Google Wave and Docs was first described in 1989 by CA Ellis and SJ Gibbs and is now obsolete.
Fresh is not enough, but also comes across. Attempts by NoSQL vendors to try water with CRDT data structures are based on theories from the late 2000s - a very atypical freshman.
So, let's think about what will grow in a new environment. New trends will inevitably be determined by something already widely known in narrow circles. I can offer three main suspects.
The first and most promising trend is event-oriented and reactive architectures, as well as event sourcing. In these approaches, work in the system goes not only and not so much with the current state itself, but with operations that change it, which are objects of the "first category" - they are processed, transferred and stored separately from the state. Kafka and the common event bus I have already mentioned. If you think about it, then the logic of the client-side work is event-oriented. We add an event-oriented business logic here and an interesting puzzle begins to assemble.

The event-oriented approach, in particular, reduces the dependence on ACID transactions. The main argument for transactions is “what if we count money?” The irony is that in the financial industry itself, where they really count big money, before SQL was invented with transactions, they were completely calm without them for thousands of years. Bookkeeping with accounts and balances, in the form in which they took shape back in the Middle Ages, is a classic example of event sourcing: operations are recorded, reduced, and collected in a state. We see the same thing in the ancient Hawala settlement system. No ACID, pure eventual consistency. Books are writing, for example, about the developed financial system of the Spanish Empire, which has fought a loan for a hundred years. Letters from the capital to the outlying provinces turned around in a year. And nothing, goods were delivered, the army fought, balances were reduced. But my business partner recently went to the tax office three times, because they have “computers frozen”.
The second trend that may start to peck is the info-centric architecture. When data is stored anywhere and flows freely, it makes sense to implement applications not in the logic of the storage-connection location, but always dance from the data. Historical examples of infocentric networks - USENET and BitTorrent; in the first, messages are identified by the group name and their own id, and flow freely between the servers. In the second, data is generally identified by a hash, and participants mutually beneficially exchange data with each other. General principle: reliably identify data, then we build participants and network topology for them. This is especially important when participants are unreliable and constantly leave and come, which is very important for mobile clients.
About five years ago, there was an interesting exchange of views on the infocentricity of the Internet. TCP pioneer Van Jacobson has maintained that existing architectures have reached the limit of scalability and that you need to design an infocentric Internet from scratch. Another group of participants, from where I can recall Ion Stoica, generally held the position that HTTP was out of date, of course, but by adjusting the CDN infrastructure for HTTP, we can understand the URL as just an identifier for a piece of information, not a server-file path. Therefore, the HTTP + CDN doublet can be infocentric to the extent necessary to solve all the pressing problems with the spread of static in HTTP. And, perhaps, the guys were mostly right.
An interesting question is whether, by analogy, it is possible to capture the info-centricity for data in web applications without having to redesign the architecture from scratch.
And the third interesting trend that I already mentioned as a freshman is CRDT (Conflict-free Replicated Data Types). They have already begun to screw them into highly loaded NoSQL systems (I know about Cassandra and Riak for sure, but it seems like someone else was). The main idea of CRDT is to abandon the linearization of all operations in the system (this is the approach that MySQL uses for replication), and limit itself to the presence of a partial order with good properties (causal order). Accordingly, you can use only data structures and algorithms that do not break from the easy reordering of operations.
CRDT allows optimistic synchronization of multiple replicas, when the complete linearization of all operations is in principle impossible. The literature discusses options for how to implement basic data structures in CRDT - Set, Map, counter, text.
This is the most promising approach, which allows you to step a little further than the primitive last-writer-wins, dangerous potential data loss during competitive recording. The main difficulty, of course, is that the developer must understand the capabilities of CRDT in order to work with them. Which, in general, is true for any technology. Plus, not all data and algorithms can be decomposed into a CRDT basis. And the main benefit is the ability to solve synchronization issues at the zoo of replicas and data storages, with competitive write access.
The CRDT engine in the mobile application will allow you to fully work with data even in the absence of a permanent connection to the Internet, and only when a connection appears, synchronize without conflicts and data loss. Ideally, this can be completely invisible to the user. A kind of Dropbox / git for objects. Yes, Firebase, Meteor, Derby, Google Drive Realtime API - the move is in this direction. But the bomb, the level of MySQL or jQuery, it has not yet become - it means that something else is not ready.
If, for example, we mentally cross CRDT, information-centric and event-oriented, we get a hypothetical CRDT bus, which, unlike the same CORBA / DCOM / RMI, will allow not only accessing remote objects, but how to work with their local copies. At the same time, these local copies will not be a flat "cache", but full-fledged live replicas with the ability to record, which will be automatically synchronized.
What is not the architecture for web applications of the future?
And what actually happens on the client?
In a browser, developers are already building fully-fledged “normal” MVC applications. MVC architecture itself is not new (from the 1970s), but it only came to the web 10 years ago, along with Google Mail. It is interesting that initially the GMail project was perceived as a stray for geeks, but, as Larry Page said then, “normal users would look more like us in 10 years' time” . Well, it worked, and GMail now uses everything.
With the advent of HTML5, the browser already has its own data store (even two), its own business logic in JavaScript and its permanent connection to the server. Now, developers are trying to combine the best of two worlds: the availability and instant response of local applications and the constant "online mode" of web applications.
The main source of discomfort is server requests. This is especially felt on mobile devices. The irony is that wireless Internet crashes when it is most needed - on the road (in the subway), at public events and in the fields. At home and at work at the table, he runs smoothly, thanks a lot, just not much needed. And even then, in the same Yandex office, WiFi is not perfect - apparently, due to the concentration of geeks per square meter. At conferences like FOSDEM, WiFi never worked.
You might think that with LTE the problem will disappear. Unlikely. We see that throughput, storage capacity, chip density are growing exponentially, and RTT (server response time) and CPU frequency have improved very little over the past 10 years - due to physics. For mobile networks, physics is millions of tons of concrete, reinforcement and rock, and the properties of the radio spectrum that are not going anywhere. Saves data caching and background synchronization, the same GMail and here in front of everyone. Dropbox is also happy in this regard, but Evernote is not very happy - it is full of complaints about synchronization failures and data loss.
Let’s think it over. More data and logic is moving to the client. WebStorage, CoreData, IndexedDB. There is more data, more space on the client, and jogging to the server does not get any easier. Downloading data is simple, caching is even easier, and rocket science begins with synchronization. A failed mobile “saves” empty data to the server - oops, lost, the user is dissatisfied. The data is changed on several devices at once - oops, conflict, the user grinds his teeth. And how many more such oops will be. The new conditions on the client are already reminiscent of the conditions in "large" systems - a lot of pieces of equipment, a lot of data replicas, everything is constantly breaking everywhere and this is normal. It seems that the client will soon need tools from the arsenal of "big boys".
And what, in fact, is happening on the server?
On the server, once it all started simply and logically - nothing portended trouble. There was one source of truth - the database (say, MySQL), there was one server with logic (say, PHP), and the client received a flat View and pulled the logic on the server through HTTP GET requests. At first, everyone scored the logic scaling simply - through the multiplication of stateless servers. The database gradually began to require replication (master-slave), then it was necessary to protect it with a cache (Memcache) and add pusher to send events to the client in real time. Then the situation began to complicate further. Hadoop was screwed somewhere, somewhere NoSQL, somewhere graph database - there were a lot of storages. Also, everything was overgrown with specialized services - analytics, search, mailing, etc. etc.
All this rapid multiplication of specialized systems also raised the problem of data synchronization. As the most successful solution for the "zoo", many mention Apache Kafka . In such an architecture, different data slices are stored in different systems that prefer to exchange events via the “bus”. Indeed, when integrating N systems, you can write either O (N * N) adapters or one common event queue. With N = 2..3, this nuance is still not very noticeable, but on LinkedIn, apparently, N is great.
And now two cigarette butts at the same time. Imagine the number of replicas of the same data in the system - both on the server and on the client side. Let's say MongoDB + Redis + Hadoop + WebStorage + CoreData. How to synchronize all this competently?
And what does all this lead to?
So what will be the future trends? No one will say for sure, but you can figure out what to look for. Indeed, new ideas appear extremely slowly and extremely rarely. For example, MongoDB uses master-slave replication via oplog, which differs from MySQL replication through the binlog only in incremental improvements and is based on the work of state machine replication from 1979-1984 by Leslie Lamport.
NoSQL systems - Riak, Voldemort, Cassandra, CouchDB try to make a significant step forward and squeeze something out of eventual consistency, causal order, logical and vector clocks - these approaches go back to the works of the same L.Lamport and C.Fidge of the late eighties.
The super-duper Operational transformation simultaneous editing technology from Google Wave and Docs was first described in 1989 by CA Ellis and SJ Gibbs and is now obsolete.
Fresh is not enough, but also comes across. Attempts by NoSQL vendors to try water with CRDT data structures are based on theories from the late 2000s - a very atypical freshman.
So, let's think about what will grow in a new environment. New trends will inevitably be determined by something already widely known in narrow circles. I can offer three main suspects.
Common Bus and event-oriented
The first and most promising trend is event-oriented and reactive architectures, as well as event sourcing. In these approaches, work in the system goes not only and not so much with the current state itself, but with operations that change it, which are objects of the "first category" - they are processed, transferred and stored separately from the state. Kafka and the common event bus I have already mentioned. If you think about it, then the logic of the client-side work is event-oriented. We add an event-oriented business logic here and an interesting puzzle begins to assemble.
The event-oriented approach, in particular, reduces the dependence on ACID transactions. The main argument for transactions is “what if we count money?” The irony is that in the financial industry itself, where they really count big money, before SQL was invented with transactions, they were completely calm without them for thousands of years. Bookkeeping with accounts and balances, in the form in which they took shape back in the Middle Ages, is a classic example of event sourcing: operations are recorded, reduced, and collected in a state. We see the same thing in the ancient Hawala settlement system. No ACID, pure eventual consistency. Books are writing, for example, about the developed financial system of the Spanish Empire, which has fought a loan for a hundred years. Letters from the capital to the outlying provinces turned around in a year. And nothing, goods were delivered, the army fought, balances were reduced. But my business partner recently went to the tax office three times, because they have “computers frozen”.
Information-centric architectures
The second trend that may start to peck is the info-centric architecture. When data is stored anywhere and flows freely, it makes sense to implement applications not in the logic of the storage-connection location, but always dance from the data. Historical examples of infocentric networks - USENET and BitTorrent; in the first, messages are identified by the group name and their own id, and flow freely between the servers. In the second, data is generally identified by a hash, and participants mutually beneficially exchange data with each other. General principle: reliably identify data, then we build participants and network topology for them. This is especially important when participants are unreliable and constantly leave and come, which is very important for mobile clients.
About five years ago, there was an interesting exchange of views on the infocentricity of the Internet. TCP pioneer Van Jacobson has maintained that existing architectures have reached the limit of scalability and that you need to design an infocentric Internet from scratch. Another group of participants, from where I can recall Ion Stoica, generally held the position that HTTP was out of date, of course, but by adjusting the CDN infrastructure for HTTP, we can understand the URL as just an identifier for a piece of information, not a server-file path. Therefore, the HTTP + CDN doublet can be infocentric to the extent necessary to solve all the pressing problems with the spread of static in HTTP. And, perhaps, the guys were mostly right.
An interesting question is whether, by analogy, it is possible to capture the info-centricity for data in web applications without having to redesign the architecture from scratch.
CRDT types
And the third interesting trend that I already mentioned as a freshman is CRDT (Conflict-free Replicated Data Types). They have already begun to screw them into highly loaded NoSQL systems (I know about Cassandra and Riak for sure, but it seems like someone else was). The main idea of CRDT is to abandon the linearization of all operations in the system (this is the approach that MySQL uses for replication), and limit itself to the presence of a partial order with good properties (causal order). Accordingly, you can use only data structures and algorithms that do not break from the easy reordering of operations.
CRDT allows optimistic synchronization of multiple replicas, when the complete linearization of all operations is in principle impossible. The literature discusses options for how to implement basic data structures in CRDT - Set, Map, counter, text.
This is the most promising approach, which allows you to step a little further than the primitive last-writer-wins, dangerous potential data loss during competitive recording. The main difficulty, of course, is that the developer must understand the capabilities of CRDT in order to work with them. Which, in general, is true for any technology. Plus, not all data and algorithms can be decomposed into a CRDT basis. And the main benefit is the ability to solve synchronization issues at the zoo of replicas and data storages, with competitive write access.
The CRDT engine in the mobile application will allow you to fully work with data even in the absence of a permanent connection to the Internet, and only when a connection appears, synchronize without conflicts and data loss. Ideally, this can be completely invisible to the user. A kind of Dropbox / git for objects. Yes, Firebase, Meteor, Derby, Google Drive Realtime API - the move is in this direction. But the bomb, the level of MySQL or jQuery, it has not yet become - it means that something else is not ready.
If, for example, we mentally cross CRDT, information-centric and event-oriented, we get a hypothetical CRDT bus, which, unlike the same CORBA / DCOM / RMI, will allow not only accessing remote objects, but how to work with their local copies. At the same time, these local copies will not be a flat "cache", but full-fledged live replicas with the ability to record, which will be automatically synchronized.
What is not the architecture for web applications of the future?
Only registered users can participate in the survey. Please come in.
As a web developer, do you like the idea of “Dropbox / git for objects?”
- 21.7% nobody needs it 85
- 8.2% we already have 32
- 70% cool where give? 273