Ray: Distributed system for using AI
- Transfer
Hello colleagues.
We hope before the end of August to begin translating a small, but truly basic book on the implementation of the capabilities of AI in the Python language.

Mr. Gift, perhaps, does not need additional advertising (for the curious - the profile of the master on GitHub):

The article offered today will briefly describe the Ray library developed at the University of California (Berkeley) and the small petit mentioned in the book of Gift. We hope that as an early teaser - what we need. Welcome under cat
As the algorithms and techniques of machine learning develop, more and more machine learning applications are required to run on multiple machines at once, and they cannot do without parallelism. However, the infrastructure for performing machine learning on clusters is still being formed situationally. Now there are already good solutions (for example, parameter servers or search for hyper parameters) and high-quality distributed systems (for example, Spark or Hadoop), originally created not for working with AI, but practitioners often create infrastructure for their own distributed systems from scratch. The mass of excess efforts is spent for it.
As an example, consider a conceptually simple algorithm, say, Evolutionary strategies for learning with reinforcement.. On the pseudocode, this algorithm fits into about a dozen lines, and its implementation in Python is a little more. However, to effectively use this algorithm on a larger machine or cluster, much more complex software engineering is required. In the implementation of this algorithm from the authors of this article - thousands of lines of code, here it is necessary to define communication protocols, strategies for serializing and deserializing messages, as well as various ways of processing data.
One of Ray's goals- help a practitioner to transform a prototype algorithm that runs on a laptop into a high-performance distributed application that works effectively on a cluster (or on a single multi-core machine) by adding relatively few lines of code. Such a framework should, in terms of performance, have all the advantages of a manually optimized system and not require the user to think about planning, data transfer and machine failures.
Free AI framework
Linking with other deep learning frameworks: Ray is fully compatible with such deep learning frameworks as TensorFlow, PyTorch and MXNet, so in many applications it is completely natural to use one or more other deep learning frameworks with Ray (for example, TensorFlow and PyTorch are actively used in reinforcement learning libraries in our libraries).
Communication with other distributed systems : Today, many popular distributed systems are used, however, most of them were designed without taking into account the tasks associated with AI, and therefore do not have the required performance to support AI and do not have an API for expressing applied aspects of AI. In modern distributed systems there are no (one or the other, depending on the system) such necessary possibilities:

A simple example of nested parallelism. In our application, two experiments are performed in parallel (each of them is a long-term task), and several parallel processes are modeled in each experiment (each process is also a task).
There are two main ways to use Ray: through its low-level APIs and through high-level libraries. High-level libraries are built on top of low-level APIs. Currently, they include Ray RLlib (a scalable library for training with reinforcements) and Ray.tune , an effective library for distributed search of hyperparameters.
Ray API Low Level
The goal of the Ray API is to provide a natural expression of the most common computational patterns and applications, not limited to fixed patterns like MapReduce.
Dynamic task graphs
The base primitive in the application (task) Ray is a dynamic task graph. It is very different from the computational graph in TensorFlow. While in TensorFlow, the computational graph represents a neural network and is executed many times in each individual application, in Ray, the task graph corresponds to the whole application and is executed only once. The task graph is not known in advance. It is built dynamically while the application is running, and the execution of one task can initiate the execution of many other tasks.
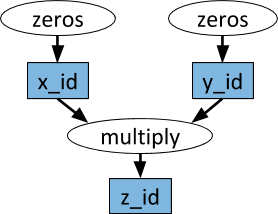
An example of a computational graph. Tasks are shown in white ovals, and objects are shown in blue rectangles. The arrows indicate that some tasks depend on objects, while others create objects.
Arbitrary Python functions can be performed as tasks, and, in an arbitrary order, they can depend on the output of other tasks. See example below.
Actors
With the help of remote functions alone and the above-described handling of tasks, it is impossible to ensure that several tasks simultaneously work on the same shared changeable state. Such a problem in machine learning arises in different contexts, where the state of the simulator, the weights in the neural network, something completely different can be shared. Actor abstraction is used in Ray to encapsulate a mutable state that is shared between multiple tasks. Here is an illustrative example showing how this is done with an Atari simulator.
With all the simplicity of the actor is very flexible in use. For example, an actor can encapsulate a simulator or a neural network policy, it can also be used for distributed learning (as, for example, with a parameter server) or to provide policies in a live application.
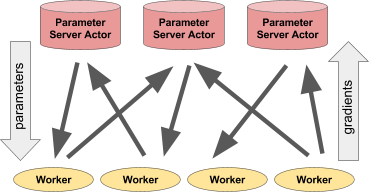
Left: Actor issues predictions / actions to a certain number of client processes. Right: Many parameter server actors perform distributed learning for multiple workflows.
Parameter
server example The parameter server can be implemented as a Ray actor as follows:
Here is a more complete example .
To instantiate a parameter server, do this.
To create four long-running workers, constantly retrieving and updating parameters, let's do this.
Ray
Ray RLlib High Level Libraries are a scalable reinforcement learning library designed for use on multiple machines. It can be used with the sample training scripts as well as through the Pytho API. Currently it includes implementations of algorithms:
Work is also underway on the implementation of other algorithms. RLlib is fully compatible with OpenAI gym .
Ray.tune is an effective library for distributed search of hyper parameters . It provides an API in Python for solving deep learning, reinforced learning, and other tasks that require large computing power. Here is an illustrative example of this kind:
Current results can be dynamically visualized using special tools, for example, Tensorboard and VisKit from rllab (or directly read JSON logs). Ray.tune supports grid search, random search, and more nontrivial early stop algorithms, such as HyperBand.
Read more about Ray
We hope before the end of August to begin translating a small, but truly basic book on the implementation of the capabilities of AI in the Python language.
Mr. Gift, perhaps, does not need additional advertising (for the curious - the profile of the master on GitHub):
The article offered today will briefly describe the Ray library developed at the University of California (Berkeley) and the small petit mentioned in the book of Gift. We hope that as an early teaser - what we need. Welcome under cat
As the algorithms and techniques of machine learning develop, more and more machine learning applications are required to run on multiple machines at once, and they cannot do without parallelism. However, the infrastructure for performing machine learning on clusters is still being formed situationally. Now there are already good solutions (for example, parameter servers or search for hyper parameters) and high-quality distributed systems (for example, Spark or Hadoop), originally created not for working with AI, but practitioners often create infrastructure for their own distributed systems from scratch. The mass of excess efforts is spent for it.
As an example, consider a conceptually simple algorithm, say, Evolutionary strategies for learning with reinforcement.. On the pseudocode, this algorithm fits into about a dozen lines, and its implementation in Python is a little more. However, to effectively use this algorithm on a larger machine or cluster, much more complex software engineering is required. In the implementation of this algorithm from the authors of this article - thousands of lines of code, here it is necessary to define communication protocols, strategies for serializing and deserializing messages, as well as various ways of processing data.
One of Ray's goals- help a practitioner to transform a prototype algorithm that runs on a laptop into a high-performance distributed application that works effectively on a cluster (or on a single multi-core machine) by adding relatively few lines of code. Such a framework should, in terms of performance, have all the advantages of a manually optimized system and not require the user to think about planning, data transfer and machine failures.
Free AI framework
Linking with other deep learning frameworks: Ray is fully compatible with such deep learning frameworks as TensorFlow, PyTorch and MXNet, so in many applications it is completely natural to use one or more other deep learning frameworks with Ray (for example, TensorFlow and PyTorch are actively used in reinforcement learning libraries in our libraries).
Communication with other distributed systems : Today, many popular distributed systems are used, however, most of them were designed without taking into account the tasks associated with AI, and therefore do not have the required performance to support AI and do not have an API for expressing applied aspects of AI. In modern distributed systems there are no (one or the other, depending on the system) such necessary possibilities:
- Support tasks at the level of milliseconds and support the execution of millions of tasks per second
- Nested parallelism (parallelization of tasks within tasks, for example, parallel simulations when searching for hyperparameters) (see the following figure)
- Arbitrary dependencies between tasks, dynamically during execution (for example, to not have to wait, adjusting to the pace of slow workers)
- Tasks that operate on a shared variable state (for example, weights in neural networks or a simulator)
- Heterogeneous resource support (CPU, GPU, etc.)
A simple example of nested parallelism. In our application, two experiments are performed in parallel (each of them is a long-term task), and several parallel processes are modeled in each experiment (each process is also a task).
There are two main ways to use Ray: through its low-level APIs and through high-level libraries. High-level libraries are built on top of low-level APIs. Currently, they include Ray RLlib (a scalable library for training with reinforcements) and Ray.tune , an effective library for distributed search of hyperparameters.
Ray API Low Level
The goal of the Ray API is to provide a natural expression of the most common computational patterns and applications, not limited to fixed patterns like MapReduce.
Dynamic task graphs
The base primitive in the application (task) Ray is a dynamic task graph. It is very different from the computational graph in TensorFlow. While in TensorFlow, the computational graph represents a neural network and is executed many times in each individual application, in Ray, the task graph corresponds to the whole application and is executed only once. The task graph is not known in advance. It is built dynamically while the application is running, and the execution of one task can initiate the execution of many other tasks.
An example of a computational graph. Tasks are shown in white ovals, and objects are shown in blue rectangles. The arrows indicate that some tasks depend on objects, while others create objects.
Arbitrary Python functions can be performed as tasks, and, in an arbitrary order, they can depend on the output of other tasks. See example below.
# Определяем две удаленные функции. При вызове этих функций создаются задачи,# выполняемые удаленно.@ray.remotedefmultiply(x, y):return np.dot(x, y)
@ray.remotedefzeros(size):return np.zeros(size)
# Параллельно запускаем две задачи. Они сразу же возвращают футуры,# и эти задачи выполняются в фоновом режиме.
x_id = zeros.remote((100, 100))
y_id = zeros.remote((100, 100))
# Запускаем третью задачу. Она не будет назначена, пока первые две задачи # не завершатся.
z_id = multiply.remote(x_id, y_id)
# Получаем результат. Он останется заблокирован до тех пор, пока не завершится третья задача.
z = ray.get(z_id)Actors
With the help of remote functions alone and the above-described handling of tasks, it is impossible to ensure that several tasks simultaneously work on the same shared changeable state. Such a problem in machine learning arises in different contexts, where the state of the simulator, the weights in the neural network, something completely different can be shared. Actor abstraction is used in Ray to encapsulate a mutable state that is shared between multiple tasks. Here is an illustrative example showing how this is done with an Atari simulator.
import gym
@ray.remoteclassSimulator(object):def__init__(self):
self.env = gym.make("Pong-v0")
self.env.reset()
defstep(self, action):return self.env.step(action)
# Создаем симулятор, он запускает удаленный процесс, который, в свою очередь,# запустит все методы этого актора
simulator = Simulator.remote()
observations = []
for _ in range(4):
# Совершаем в симулятор действие 0. Этот вызов не приводит к блокировке # и возвращает футуру
observations.append(simulator.step.remote(0))With all the simplicity of the actor is very flexible in use. For example, an actor can encapsulate a simulator or a neural network policy, it can also be used for distributed learning (as, for example, with a parameter server) or to provide policies in a live application.
Left: Actor issues predictions / actions to a certain number of client processes. Right: Many parameter server actors perform distributed learning for multiple workflows.
Parameter
server example The parameter server can be implemented as a Ray actor as follows:
@ray.remoteclassParameterServer(object):def__init__(self, keys, values):# Эти значения будут изменяться, поэтому необходимо создать локальную копию.
values = [value.copy() for value in values]
self.parameters = dict(zip(keys, values))
defget(self, keys):return [self.parameters[key] for key in keys]
defupdate(self, keys, values):# Эта функция обновления выполняет сложение с имеющимися значениями, но # функцию обновления можно определять произвольноfor key, value in zip(keys, values):
self.parameters[key] += valueHere is a more complete example .
To instantiate a parameter server, do this.
parameter_server = ParameterServer.remote(initial_keys, initial_values)
To create four long-running workers, constantly retrieving and updating parameters, let's do this.
@ray.remotedefworker_task(parameter_server):whileTrue:
keys = ['key1', 'key2', 'key3']
# Получаем наиболее актуальные параметры
values = ray.get(parameter_server.get.remote(keys))
# Вычисляем некоторые обновления параметров
updates = …
# Обновляем параметры
parameter_server.update.remote(keys, updates)
# Запускаем 4 долгосрочные задачиfor _ in range(4):
worker_task.remote(parameter_server)Ray
Ray RLlib High Level Libraries are a scalable reinforcement learning library designed for use on multiple machines. It can be used with the sample training scripts as well as through the Pytho API. Currently it includes implementations of algorithms:
- A3C
- DQN
- Evolutionary strategies
- PPO
Work is also underway on the implementation of other algorithms. RLlib is fully compatible with OpenAI gym .
Ray.tune is an effective library for distributed search of hyper parameters . It provides an API in Python for solving deep learning, reinforced learning, and other tasks that require large computing power. Here is an illustrative example of this kind:
from ray.tune import register_trainable, grid_search, run_experiments
# Функция для оптимизации. Гиперпараметры находятся в аргументе configdefmy_func(config, reporter):import time, numpy as np
i = 0whileTrue:
reporter(timesteps_total=i, mean_accuracy=(i ** config['alpha']))
i += config['beta']
time.sleep(0.01)
register_trainable('my_func', my_func)
run_experiments({
'my_experiment': {
'run': 'my_func',
'resources': {'cpu': 1, 'gpu': 0},
'stop': {'mean_accuracy': 100},
'config': {
'alpha': grid_search([0.2, 0.4, 0.6]),
'beta': grid_search([1, 2]),
},
}
})Current results can be dynamically visualized using special tools, for example, Tensorboard and VisKit from rllab (or directly read JSON logs). Ray.tune supports grid search, random search, and more nontrivial early stop algorithms, such as HyperBand.
Read more about Ray