10 reasons for [not] using k8s
Today we will talk about Kubernetes, about the rake, which can be collected with its practical use, and about the developments that helped the author and which should help you. We will try to prove that without k8s in the modern world is nowhere. Opponents of the k8s will also provide excellent reasons why you should not switch to it. That is, in the story we will not only protect Kubernetes, but also scold him. Hence it appeared in the title [not] .
This article is based on the report of Ivan Glushkov ( gli ) at the DevOops 2017 conference. Ivan’s last two jobs were somehow related to Kubernetes: he worked in Post-coms, and in Machine Zone in infra-commands, and they touch Kubernetes very closely. Plus, Ivan leads the podcast DevZen. Further presentation will be conducted on behalf of Ivan.

First, I will go briefly on the area, why it is useful and important for many, why this HYIP occurs. Then I will tell about our experience in using technology. Well, then the findings.
In this article, all the slides are inserted as pictures, but sometimes you want to copy something. For example, there will be examples with configs. Slides in PDF can be downloaded here .
I will not tell everyone strictly: be sure to use Kubernetes. There are pros and cons, so if you come to look for cons, you will find them. Before you choose, look only at the pros, only at the minuses or in general, look at everything together. Pros will help me to show Simon Cat , and the black cat will cross the road when there is a minus.

So, why did this HYIP happen at all, why is X better than Y. Kubernetes is exactly the same system, and there are more of them than one thing. There are Puppet, Chef, Ansible, Bash + SSH, Terraform. My favorite SSH helps me now, why should I go somewhere. I think that there are many criteria, but I highlighted the most important ones.
The time from commit to release is a very good estimate, and the guys from Express 42 are great experts on this. Automation of the assembly, automation of the entire pipeline is a very good thing, you cannot praise it, it actually helps. Continuous Integration, Continuous Deployment. And, of course, how much effort you will spend on doing everything. Everything can be written in Assembler, as I say, the deployment system, too, but it will not add convenience.

I will not give a short introduction to Kubernetes, you know what it is. I will touch these areas a little further.
Why is all this so important for developers? Repeatability is important for them, that is, if they wrote some application, started the test, it will work for you, for the neighbor, and in production.
The second is a standardized environment: if you study Kubernetes and go to a neighboring company where there are Kubernetes, there will be all the same. Simplifying the testing procedure and Continuous Integration is not a direct consequence of using Kubernetes, but it still simplifies the task, so everything becomes more convenient.

For release developers a lot more advantages. Firstly, it is an immutable infrastructure.
Secondly, infrastructure as code that is stored somewhere. Thirdly, idempotency, the ability to add a release with one button. Kickback releases occur fairly quickly, and the introspection of the system is quite convenient. Of course, all this can be done in your system, written on the knee, but you can not always do it correctly, but in Kubernetes this is already implemented.
What is Kubernetes not, and what does it not allow to do? There are many misconceptions about this. Let's start with the containers. Kubernetes runs on top of them. Containers are not lightweight virtual machines, but a completely different entity. They are easy to explain with the help of this concept, but in fact it is wrong. The concept is completely different, it must be understood and accepted.
Secondly, Kubernetes does not make the application more secure. It does not automatically scale it.
You need to try hard to start Kubernetes, it will not be so that "pressed the button, and everything automatically worked." It will hurt.

Our experience. We want you and everyone else to break nothing. To do this, you need to look more around - and this is our side.

First, Kubernetes does not walk alone. When you build a structure that will fully manage releases and deployments, you need to understand that Kubernetes is one cube, and there should be 100 such cubes. In order to build all this, you need to study all this hard. Beginners who will come to your system will also study this stack, a huge amount of information.
Kubernetes is not the only important cube, there are many other important cubes around, without which the system will not work. That is, you need to worry very much about fault tolerance.

Because of this, Kubernetes is a minus. The system is complex, you need to take care of a lot.

But there are pluses. If a person has studied Kubernetes in one company, in another he will not stand hair on end because of the release system. As time goes by, when Kubernetes captures more space, the transition of people and learning will be easier. And for that - plus.


We use Helm. This is a system that is built on top of Kubernetes, a package manager reminds. You can click a button, say you want to install * Wine * on your system. Can be installed in Kubernetes. It works, automatically downloads, launches, and everything will work. It allows you to work with plug-ins, client-server architecture. If you will work with it, we recommend running one Tiller on the namespace. This isolates the namespace from each other, and breaking one will not break the other.

In fact, the system is very complex. A system that should be a higher-level abstraction and more simple and understandable does not really make it any clearer. For this minus.

Let's compare configs. Most likely, you also have some configs, if you run your system in production. We have our own system called BOOMer. I don't know why we called it that. It consists of Puppet, Chef, Ansible, Terraform and everything else, there is a large bottle.

Let's see how it works. Here is an example of a real configuration that is currently in production. What do we see here?
Firstly, we see where to launch the application, secondly, what to launch, and, thirdly, how to prepare it for launch. Concepts are already mixed in one bottle.

If we look further, due to the fact that we have added inheritance to make more complex configs, we need to look at what is in the common config that we refer to. Plus, we add network configuration, access rights, load planning. All this in one config, which we need in order to run a real application in production, we mix a bunch of concepts in one place.
It is very difficult, it is very wrong, and in this is a huge plus of Kubernetes, because in it you simply determine what to launch. The network configuration was performed during the installation of Kubernetes, the configuration of the entire provisioning is solved with the help of the docker - you have encapsulated, all problems are somehow divided, and in this case there is only your application in the config, and that's a plus.

Let's take a closer look. Here we have only one application. To earn a deployment, you need to work a lot more. First, you need to define the services. How do we get secrets, ConfigMap, access to Load Balancer.

Do not forget that you have several environments. There is a Stage / Prod / Dev. This all together is not a small piece, which I showed, but a huge set of configs, which is actually difficult. For this minus.

Helm-template for comparison. It completely repeats Kubernetes patterns, if there is any file in Kubernetes with the definition of deployment, the same will happen in Helm. Instead of specific values for the environment, you have templates that are substituted from values.
You have a separate template, separate values that should be substituted into this template.
Of course, you need to additionally determine the different infrastructure of Helm itself, despite the fact that in Kubernetes you have a lot of configuration files that you need to drag to Helm. This is all very difficult, for which a minus.
The system, which should simplify, in fact, complicates. For me, this is a clear minus. Either it is necessary to build on something else, or not to use.
Let's go deeper, we are not deep enough.

First, how we work with clusters. I read Google’s article “Borg, Omega, and Kubernetes,” which very strongly defend the concept that you need to have one large cluster. I was also behind this idea, but in the end, we left it. As a result of our disputes, we use four different clusters.
The first cluster is e2e, for testing Kubernetes itself and testing scripts that deploy environments, plug-ins, and so on. The second, of course, is prod and stage. These are standard concepts. Thirdly, this is the admin in which everything else has been downloaded - in particular, we have CI there, and it looks like this cluster will always be the biggest because of it.
There are a lot of testings: by commit, by merge, everyone makes a bunch of commits, so the clusters are just huge.

We tried to look at CoreOS, but did not use it. They have inside TF or CloudFormation, both of which make it very bad to understand what is inside a state. Because of this, problems arise when updating. When you want to update the settings of your Kubernetes, for example, its version, you may be faced with the fact that the update does not happen in the wrong way. This is a big stability issue. This is a minus.

Secondly, when you use Kubernetes, you need to download images from somewhere. This can be an internal source, a repository, or an external one. If internal, there are problems. I recommend using Docker Distribution because it is stable, it was made by Docker. But the price of support is still high. For it to work, you need to make it fault tolerant, because this is the only place from which your applications receive data for work.

Imagine that at the crucial moment when you found a production bug, your repository crashed - you cannot upgrade the application. You must make it fault tolerant, and from all possible problems that can only be.
Secondly, if the mass of teams, each has its own image, they accumulate very much and very quickly. You can kill your Docker Distribution. It is necessary to do the cleaning, delete the images, carry out information for users when and what you will clean.
Third, with large images, say, if you have a monolith, the size of the image will be very large. Imagine that you need to release at 30 nodes. 2 gigabytes per 30 nodes - calculate which stream, how fast it downloads to all nodes. I would like to press the button, and immediately released it. But no, you must first wait until the swing. We need to somehow speed up this download, and it all works from a single point.

With external repositories there are the same problems with the garbage collector, but most often this is done automatically. We use Quay. In the case of external repositories, these are third-party services, in which most of the images are public. To avoid public images, you need to provide access. We need secrets, access rights to the images, all this is specially customized. Of course, this can be automated, but in the case of a local launch of Cube on your system, you still have to configure it.

We use kops to install Kubernetes. This is a very good system, we are early users from the time when they did not write in a blog. It does not fully support CoreOS, works well with Debian, can automatically configure Kubernetes master nodes, works with addons, has the ability to make zero downtime during Kubernetes updates.
All these features are out of the box, for which a big and fat plus. Great system!


The links provide many options for setting up a network in Kubernetes. There are a lot of them, everyone has their own advantages and disadvantages. Kops only supports some of these options. You can, of course, tune in to work through CNI, but it is better to use the most popular and standard ones. They are tested by the community, and most likely stable.

We decided to use Calico. It worked well from scratch, without a lot of problems, it uses BGP, it is faster than encapsulation, it supports IP-in-IP, it allows you to work with multi-clones, for us this is a big plus.
Good integration with Kubernetes, with the help of labels delimits traffic. For this - plus.
I did not expect that Calico will reach the state when turned on, and everything works without problems.

High Availability, as I said, we do through kops, you can use 5-7-9 nodes, we use three. We sit on etcd v2, because of the bug were not updated on v3. Theoretically, this will speed up some processes. I don't know, doubt it.

A tricky moment, we have a special cluster for experimenting with scripts, automatic knurling through CI. We believe that we have protection from completely wrong actions, but for some special and complex releases, we make snapshots of all disks just in case, we do not make backups every day.


Authorization - the eternal question. We at Kubernetes use RBAC - role-based access. It is much better than ABAC, and if you set it up, then you know what I mean. Look at configs - be surprised.
We use Dex, an OpenID provider, which downloads all the information from some data source.
And in order to login to Kubernetes, there are two ways. You need to somehow register in .kube / config, where to go and what it can do. It is necessary to receive this config somehow. Either the user goes to the UI, where he logs in, gets configs, copies them in / config and works. This is not very convenient. We gradually moved to the fact that a person comes into the console, presses a button, logs in, and configs are automatically generated and added to the right place. So much more convenient, we decided to act in this way.

We use Active Directory as a data source. Kubernetes allows you to push information about a group through the entire authorization structure, which is translated into a namespace and role. Thus, we immediately distinguish between where a person can go, where he has no right to go and what he can release.

Most often, people need access to AWS. If you do not have Kubernetes, there is a machine running the application. It would seem that all you need is to get logs, see them and that's it. This is convenient when a person can log into his car and see how the application works. From the point of view of Kubernetes, everything works in containers. There is a command `kubectl exec` - get into the container in the application and see what happens there. Therefore, there is no need to go to AWS instances. We denied access for everyone except the infra team.
Moreover, we have banned long-playing admin keys, entry through roles. If there is an opportunity to use the role of admin - I am admin. Plus we added the rotation of the keys. It is convenient to configure through the awsudo command, this is a project on a githabe, I highly recommend it, it allows you to work as with a sudo command.



Quotas. Very nice stuff in Kubernetes, works right out of the box. You limit some namespace, say, by the number of objects, memory or CPU that you can consume. I think this is important and useful for everyone. We have not yet reached the memory and CPU, we use only the number of objects, but we will add all this.
Big and fat plus allows you to do a lot of tricky things.


Scaling. You cannot mix scaling inside Kubernetes and outside Kubernetes. Inside, Kubernetes does the scaling itself. It can increase pods automatically when there is a big load.
Here I am talking about the scaling of the Kubernetes instances themselves. This can be done using AWS Autoscaler, this is a project on a githabe. When you add a new pod and it cannot start because it lacks resources on all instances, AWS Autoscaler can automatically add nodes. Allows you to work on Spot-instances, we have not added this yet, but we will, it allows you to save a lot.


When you have a lot of users and applications from users, you need to somehow monitor them. This is usually telemetry, logs, some beautiful graphics.

For historical reasons, we had Sensu, he didn’t really fit for Kubernetes. A more metric-oriented project was needed. We looked at the whole TICK stack, especially InfluxDB. Good UI, SQL-like language, but lacked a few features. We switched to Prometheus.
He is good. Good query language, good alerts, and everything out of the box.

To send telemetry, we used Cernan. This is our own project written in Rust. This is the only project on Rust that has been in production for a year now. It has several concepts: there is a data source concept, you configure several sources. You configure where the data will merge. We have a configuration of filters, that is, the flowing data can be somehow processed. You can convert logs to metrics, metrics to logs, whatever you want.
Given that you have several inputs, several conclusions, and you show that where it is going, there is something like a large graph system, it turns out to be quite convenient.

We are now moving smoothly from the current Statsd / Cernan / Wavefront stack to Kubernetes. Theoretically, Prometheus wants to take data from applications itself, so all applications need to add an endpoint from which it will take metrics. Cernan is a transmission link, should work everywhere. There are two possibilities: you can run Kubernetes on each instance, you can use the Sidecar-concept, when there is another container in your data field that sends data. We do both.

At us right now all logs go to stdout / stderr. All applications are designed for this, so one of the critical requirements that we do not leave from this system. Cernan sends data to ElasticSearch, events from the entire Kubernetes system are sent there using Heapster. This is a very good system, I recommend.
After that, you can view all the logs in one place, for example, in the console. We use Kibana. There is a wonderful product Stern, just for the logs. It allows you to watch, paints different colors in different colors, can see when one died and the other restarted. Automatically picks up all logs. An ideal project, I highly recommend it, it’s fat plus Kubernetes, everything is fine here.


Secrets. We use S3 and KMS. We are thinking about switching to Vault or secrets in Kubernetes itself. They were in 1.7 able alpha, but something needs to be done about it.

We got to interesting. Development in Kubernetes is generally considered a little. Basically it says: "Kubernetes is an ideal system, everything is fine in it, let's move on."
But in fact, free cheese is only in a mousetrap, and for developers in Kubernetes - hell.

Not from the point of view that everything is bad, but from the fact that you need to look at things a little differently. I compare the development in Kubernetes with functional programming: until you touch it, you think in your imperative style, everything is fine. In order to develop in the functional area, it is necessary to turn the head a little bit on the other side - here it is the same.
You can develop, you can, but you need to look at it differently. First, understand the Docker Way concept. This is not that difficult, but to understand it completely is quite problematic. Most developers are used to saying that they are logging into their local, remote or virtual machine via SSH, they say: "Let me fix something here, podshamanyu."
You tell him that in Kubernetes this will not happen, because you only have the infrared. When you want to update the application, please make a new image that will work, and the old one, please do not touch it, it will simply die. I personally worked on introducing Kubernetes into different teams and I see horror in the eyes of people when they understand that all old habits will have to be completely discarded, come up with new, some new system, and this is very difficult.
Plus, you have to make a lot of choices: let's say, when you make any changes, if the development is local, you need to commit to the repository somehow, then the pipeline repository runs tests away, and then says, “Oh, there's a typo in one word,” you need everything do locally. Mount a folder in some way, go there, update the system, at least compile. If tests run locally inconveniently, then it can commit to CI at least to check for some local actions, and then send them to CI for verification. These choices are quite complicated.
It is especially difficult when you have a spreading application consisting of one hundred services, and in order for one of them to work, you need to ensure the work of all the others side by side. You need to either emulate the environment, or somehow run locally. This whole choice is not trivial, the developer needs to think a lot about it. Because of this, there is a negative attitude towards Kubernetes. Of course, he is good - but he is bad, because you need to think a lot and change your habits.
Therefore, here three fat cats ran across the road.


When we looked at Kubernetes, we tried to understand, maybe there are some convenient systems for development. In particular, there is such a thing as Deis, for sure you have heard about it all. It is very easy to use, and we checked, in fact, all simple projects are very easy to switch to Deis. But the problem is that more complex projects can not go to Deis.
As I said, we switched to Helm Charts. But the only problem that we see now is that you need a lot of good documentation. We need some How-tos, some FAQs in order for a person to quickly start, copy the current configs, paste in his own, change the names so that everything is correct. It is also important to understand in advance, and you need to do it all. I have here listed common development toolkits, I will not touch all this, except for the mini-cube.

Minikube is a very good system, in the sense that it is good that it is, but badly, that in this form. It allows you to run Kubernetes locally, allows you to see everything on your laptop, do not go anywhere on SSH, and so on.
I work on MacOS, I have a Mac, respectively, in order to run the local app, I need to run the docker locally. It can not be done in any way. As a result, you must either run the virtualbox, or xhyve. Both things are, in fact, emulating on top of my operating system. We use xhyve, but we recommend using VirtualBox, since there are a lot of bugs, they have to be bypassed.
But the very idea that there is virtualization, and inside virtualization, another level of abstraction is launched for virtualization, some kind of ridiculous, delusional. In general, it is good that it somehow works, but it would be better to complete it.


CI is not directly related to Kubernetes, but it is a very important system, especially if you have Kubernetes, if you integrate it, you can get very good results. We used Concourse for CI, a very rich functionality, you can build scary graphs, what, where, how it starts, what it depends on. But Concourse developers have a very strange attitude towards their product. For example, during the transition from one version to another, they broke backward compatibility and most of the plug-ins did not rewrite. Moreover, the documentation was not added, and when we tried to do something, nothing worked at all.
There is little documentation at all in all CIs, we have to read the code, and, in general, we have abandoned Concourse. We switched to Drone.io - it is small, very light, nimble, the functionality is much less, but more often it is enough. Yes, large and weighty dependency graphs - it would be convenient to have, but you can also work on small ones. Too little documentation, read the code, but it is ok.
Each stage of the pipeline works in its own docker-container, this allows you to greatly simplify the transition to Kubernetes. If there is an application that runs on a real machine, in order to add to the CI, use the docker container, and then go to Kubernetes easier.
We have an automatic release of the admin / stage cluster set up, while in the production cluster we are still afraid to add a setting. Plus there is a plugin system.
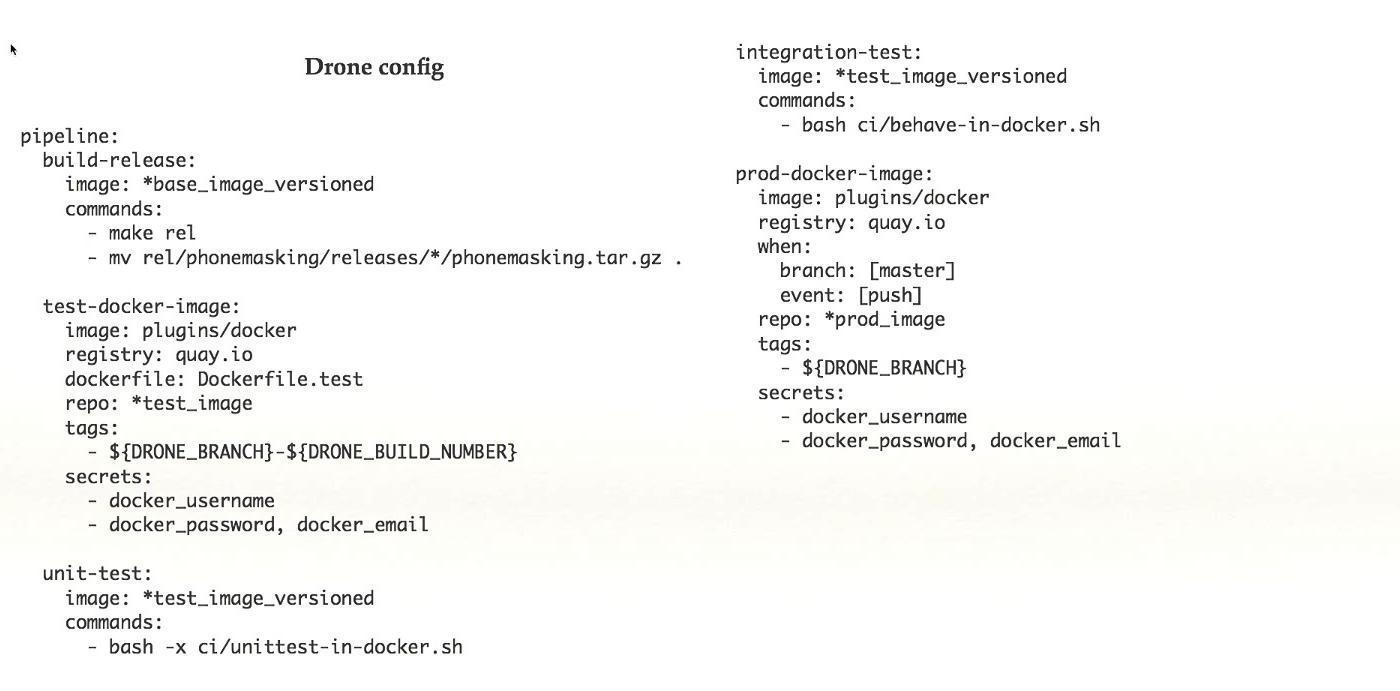
This is an example of a simple Drone-config. Taken from a ready-made working system, in this case there are five steps in the pipeline, each step does something: assembles, tests, and so on. With the feature set that is in the Drone, I think this is a good thing.

We argued a lot about how many clusters to have: one or more. When we came up with the idea of several clusters, we began to work further in this direction, created some scripts, put a bunch of other cubes to our Kubernetes. After that, they came to Google and asked for advice, did they do everything, maybe something needs to be fixed.
Google agreed that the idea of a single cluster does not apply to Kubernetes. There are many shortcomings, in particular, work with geolocation. It turns out that the idea is correct, but it is too early to talk about it. Maybe later. While Service Mesh can help.

In general, if you want to see how our system works, pay attention to Geodesic. This is a product similar to what we do. It is open source, a very similar design concept choice. We are thinking of joining together and possibly using them.

Yes, there are problems in our Kubernetes practice too.
There is a pain with local names, with certificates. There is a problem with the downloads of large images and their work, perhaps related to the file system, we have not dug there. There are already three different ways to install Kubernetes extensions. We have been working on this project for less than a year, and we already have three different ways, annual rings are growing.

Let's make all the cons.
So, I think that one of the main drawbacks is a large amount of information to study, not only new technologies, but also new concepts and habits. It’s like learning a new language: in principle, it’s easy, but it’s difficult to turn your head a little to all users. If you have not worked with such concepts before - it is hard to switch to Kubernetes.
Kubernetes will be just a small part of your system. Everyone thinks that they will install Kubernetes, and everything will work right away. No, this is a small cube, and there will be many such cubes.
Some applications are in principle difficult to run on Kubernetes - and it is better not to run. Also very heavy and large configuration files, and in concepts over Kubernetes they are even more difficult. All current solutions are raw.
All these cons, of course, disgusting.
Compromises and difficult transition create a negative image of Kubernetes, and I don’t know how to deal with it. We couldn’t overcome much, there are people who hate the whole movement, do not want and do not understand its advantages.
In order to run Minikube, your system, so that everything works, will have to try hard. As you can see, there are a lot of minuses, and those who do not want to work with Kubernetes have their own reasons. If you do not want to hear about the pros - close your eyes and ears, because they will go on.

The first plus - over time will have less and less to learn beginners. It often happens that when a newcomer comes into the system, he begins to pull out all his hair, because for the first 1-2 months he tries to figure out how to release all this, if the system is large and lives for a long time, many annual rings have grown. In Kubernetes, everything will be easier.
Secondly, Kubernetes does not do it himself, but lets make a short release cycle. A commit created CI, a CI created an image, automatically swapped, you pressed a button, and everything went into production. This greatly reduces the release time.
The following is code separation. Our system and most of your systems in one place collect configs of different levels, that is, you have an infrastructure code, a business code, all the logic is mixed in one place. In Kubernetes this will not be out of the box, choosing the right concept helps to avoid this in advance.
A large and very active community, which means a large number of changes. Most of what I mentioned over the past two years has become so stable that they can be produced in production. Perhaps some of them appeared early, but it was not very stable.
I consider it a great advantage that in one place you can see both application logs and Kubernetes logs with your application, which is invaluable. And there is no access to the node. When we removed user access to nodes, it immediately cuts off a large class of problems.

The second part of the advantages is a bit more conceptual. Most of the Kubernetes community see the technology part. But we saw the conceptual management part. After you go to Kubernetes, and if this is all set up correctly, the infrared command (or backend — I don’t know how you call it right) is no longer needed to release the applications.
The user wants to release the application, he will not come with a request for this, but simply launch a new pod, there is a command for this. Infracommand is not needed to investigate problems. Just look at the logs, our set of designs is not so big, there is a list according to which it is very easy to find the problem. Yes, support is sometimes needed if the problem is in Kubernetes, in instances, but most often there is a problem with applications.
We added Error Budget. This is the following concept: each team has statistics on how many problems occur in production. If there are too many problems, the team is cut releases, until some time has passed. This is good because the team will seriously ensure that their releases are very stable. Need new functionality - please release. Want to release at two in the morning - please. If after releases you have only “nines” in SLA - do what you want, everything is stable, you can do anything. However, if the situation is worse, most likely we will not allow releasing anything except fixes.
This is a handy thing for both the stability of the system and the mood within the team. We cease to be a “Police of Morals”, not letting us release late at night. Do what you want while you have a good budget of mistakes. This greatly reduces the tension within the company.
To contact me, you can use the mail or tweet: @gliush .
And at the end for you a lot of links, you can download everything yourself and see:
This article is based on the report of Ivan Glushkov ( gli ) at the DevOops 2017 conference. Ivan’s last two jobs were somehow related to Kubernetes: he worked in Post-coms, and in Machine Zone in infra-commands, and they touch Kubernetes very closely. Plus, Ivan leads the podcast DevZen. Further presentation will be conducted on behalf of Ivan.
First, I will go briefly on the area, why it is useful and important for many, why this HYIP occurs. Then I will tell about our experience in using technology. Well, then the findings.
In this article, all the slides are inserted as pictures, but sometimes you want to copy something. For example, there will be examples with configs. Slides in PDF can be downloaded here .
I will not tell everyone strictly: be sure to use Kubernetes. There are pros and cons, so if you come to look for cons, you will find them. Before you choose, look only at the pros, only at the minuses or in general, look at everything together. Pros will help me to show Simon Cat , and the black cat will cross the road when there is a minus.
So, why did this HYIP happen at all, why is X better than Y. Kubernetes is exactly the same system, and there are more of them than one thing. There are Puppet, Chef, Ansible, Bash + SSH, Terraform. My favorite SSH helps me now, why should I go somewhere. I think that there are many criteria, but I highlighted the most important ones.
The time from commit to release is a very good estimate, and the guys from Express 42 are great experts on this. Automation of the assembly, automation of the entire pipeline is a very good thing, you cannot praise it, it actually helps. Continuous Integration, Continuous Deployment. And, of course, how much effort you will spend on doing everything. Everything can be written in Assembler, as I say, the deployment system, too, but it will not add convenience.
I will not give a short introduction to Kubernetes, you know what it is. I will touch these areas a little further.
Why is all this so important for developers? Repeatability is important for them, that is, if they wrote some application, started the test, it will work for you, for the neighbor, and in production.
The second is a standardized environment: if you study Kubernetes and go to a neighboring company where there are Kubernetes, there will be all the same. Simplifying the testing procedure and Continuous Integration is not a direct consequence of using Kubernetes, but it still simplifies the task, so everything becomes more convenient.
For release developers a lot more advantages. Firstly, it is an immutable infrastructure.
Secondly, infrastructure as code that is stored somewhere. Thirdly, idempotency, the ability to add a release with one button. Kickback releases occur fairly quickly, and the introspection of the system is quite convenient. Of course, all this can be done in your system, written on the knee, but you can not always do it correctly, but in Kubernetes this is already implemented.
What is Kubernetes not, and what does it not allow to do? There are many misconceptions about this. Let's start with the containers. Kubernetes runs on top of them. Containers are not lightweight virtual machines, but a completely different entity. They are easy to explain with the help of this concept, but in fact it is wrong. The concept is completely different, it must be understood and accepted.
Secondly, Kubernetes does not make the application more secure. It does not automatically scale it.
You need to try hard to start Kubernetes, it will not be so that "pressed the button, and everything automatically worked." It will hurt.
Our experience. We want you and everyone else to break nothing. To do this, you need to look more around - and this is our side.
First, Kubernetes does not walk alone. When you build a structure that will fully manage releases and deployments, you need to understand that Kubernetes is one cube, and there should be 100 such cubes. In order to build all this, you need to study all this hard. Beginners who will come to your system will also study this stack, a huge amount of information.
Kubernetes is not the only important cube, there are many other important cubes around, without which the system will not work. That is, you need to worry very much about fault tolerance.
Because of this, Kubernetes is a minus. The system is complex, you need to take care of a lot.
But there are pluses. If a person has studied Kubernetes in one company, in another he will not stand hair on end because of the release system. As time goes by, when Kubernetes captures more space, the transition of people and learning will be easier. And for that - plus.
We use Helm. This is a system that is built on top of Kubernetes, a package manager reminds. You can click a button, say you want to install * Wine * on your system. Can be installed in Kubernetes. It works, automatically downloads, launches, and everything will work. It allows you to work with plug-ins, client-server architecture. If you will work with it, we recommend running one Tiller on the namespace. This isolates the namespace from each other, and breaking one will not break the other.
In fact, the system is very complex. A system that should be a higher-level abstraction and more simple and understandable does not really make it any clearer. For this minus.
Let's compare configs. Most likely, you also have some configs, if you run your system in production. We have our own system called BOOMer. I don't know why we called it that. It consists of Puppet, Chef, Ansible, Terraform and everything else, there is a large bottle.
Let's see how it works. Here is an example of a real configuration that is currently in production. What do we see here?
Firstly, we see where to launch the application, secondly, what to launch, and, thirdly, how to prepare it for launch. Concepts are already mixed in one bottle.
If we look further, due to the fact that we have added inheritance to make more complex configs, we need to look at what is in the common config that we refer to. Plus, we add network configuration, access rights, load planning. All this in one config, which we need in order to run a real application in production, we mix a bunch of concepts in one place.
It is very difficult, it is very wrong, and in this is a huge plus of Kubernetes, because in it you simply determine what to launch. The network configuration was performed during the installation of Kubernetes, the configuration of the entire provisioning is solved with the help of the docker - you have encapsulated, all problems are somehow divided, and in this case there is only your application in the config, and that's a plus.
Let's take a closer look. Here we have only one application. To earn a deployment, you need to work a lot more. First, you need to define the services. How do we get secrets, ConfigMap, access to Load Balancer.
Do not forget that you have several environments. There is a Stage / Prod / Dev. This all together is not a small piece, which I showed, but a huge set of configs, which is actually difficult. For this minus.
Helm-template for comparison. It completely repeats Kubernetes patterns, if there is any file in Kubernetes with the definition of deployment, the same will happen in Helm. Instead of specific values for the environment, you have templates that are substituted from values.
You have a separate template, separate values that should be substituted into this template.
Of course, you need to additionally determine the different infrastructure of Helm itself, despite the fact that in Kubernetes you have a lot of configuration files that you need to drag to Helm. This is all very difficult, for which a minus.
The system, which should simplify, in fact, complicates. For me, this is a clear minus. Either it is necessary to build on something else, or not to use.
Let's go deeper, we are not deep enough.
First, how we work with clusters. I read Google’s article “Borg, Omega, and Kubernetes,” which very strongly defend the concept that you need to have one large cluster. I was also behind this idea, but in the end, we left it. As a result of our disputes, we use four different clusters.
The first cluster is e2e, for testing Kubernetes itself and testing scripts that deploy environments, plug-ins, and so on. The second, of course, is prod and stage. These are standard concepts. Thirdly, this is the admin in which everything else has been downloaded - in particular, we have CI there, and it looks like this cluster will always be the biggest because of it.
There are a lot of testings: by commit, by merge, everyone makes a bunch of commits, so the clusters are just huge.
We tried to look at CoreOS, but did not use it. They have inside TF or CloudFormation, both of which make it very bad to understand what is inside a state. Because of this, problems arise when updating. When you want to update the settings of your Kubernetes, for example, its version, you may be faced with the fact that the update does not happen in the wrong way. This is a big stability issue. This is a minus.
Secondly, when you use Kubernetes, you need to download images from somewhere. This can be an internal source, a repository, or an external one. If internal, there are problems. I recommend using Docker Distribution because it is stable, it was made by Docker. But the price of support is still high. For it to work, you need to make it fault tolerant, because this is the only place from which your applications receive data for work.
Imagine that at the crucial moment when you found a production bug, your repository crashed - you cannot upgrade the application. You must make it fault tolerant, and from all possible problems that can only be.
Secondly, if the mass of teams, each has its own image, they accumulate very much and very quickly. You can kill your Docker Distribution. It is necessary to do the cleaning, delete the images, carry out information for users when and what you will clean.
Third, with large images, say, if you have a monolith, the size of the image will be very large. Imagine that you need to release at 30 nodes. 2 gigabytes per 30 nodes - calculate which stream, how fast it downloads to all nodes. I would like to press the button, and immediately released it. But no, you must first wait until the swing. We need to somehow speed up this download, and it all works from a single point.
With external repositories there are the same problems with the garbage collector, but most often this is done automatically. We use Quay. In the case of external repositories, these are third-party services, in which most of the images are public. To avoid public images, you need to provide access. We need secrets, access rights to the images, all this is specially customized. Of course, this can be automated, but in the case of a local launch of Cube on your system, you still have to configure it.
We use kops to install Kubernetes. This is a very good system, we are early users from the time when they did not write in a blog. It does not fully support CoreOS, works well with Debian, can automatically configure Kubernetes master nodes, works with addons, has the ability to make zero downtime during Kubernetes updates.
All these features are out of the box, for which a big and fat plus. Great system!
The links provide many options for setting up a network in Kubernetes. There are a lot of them, everyone has their own advantages and disadvantages. Kops only supports some of these options. You can, of course, tune in to work through CNI, but it is better to use the most popular and standard ones. They are tested by the community, and most likely stable.
We decided to use Calico. It worked well from scratch, without a lot of problems, it uses BGP, it is faster than encapsulation, it supports IP-in-IP, it allows you to work with multi-clones, for us this is a big plus.
Good integration with Kubernetes, with the help of labels delimits traffic. For this - plus.
I did not expect that Calico will reach the state when turned on, and everything works without problems.
High Availability, as I said, we do through kops, you can use 5-7-9 nodes, we use three. We sit on etcd v2, because of the bug were not updated on v3. Theoretically, this will speed up some processes. I don't know, doubt it.
A tricky moment, we have a special cluster for experimenting with scripts, automatic knurling through CI. We believe that we have protection from completely wrong actions, but for some special and complex releases, we make snapshots of all disks just in case, we do not make backups every day.
Authorization - the eternal question. We at Kubernetes use RBAC - role-based access. It is much better than ABAC, and if you set it up, then you know what I mean. Look at configs - be surprised.
We use Dex, an OpenID provider, which downloads all the information from some data source.
And in order to login to Kubernetes, there are two ways. You need to somehow register in .kube / config, where to go and what it can do. It is necessary to receive this config somehow. Either the user goes to the UI, where he logs in, gets configs, copies them in / config and works. This is not very convenient. We gradually moved to the fact that a person comes into the console, presses a button, logs in, and configs are automatically generated and added to the right place. So much more convenient, we decided to act in this way.
We use Active Directory as a data source. Kubernetes allows you to push information about a group through the entire authorization structure, which is translated into a namespace and role. Thus, we immediately distinguish between where a person can go, where he has no right to go and what he can release.
Most often, people need access to AWS. If you do not have Kubernetes, there is a machine running the application. It would seem that all you need is to get logs, see them and that's it. This is convenient when a person can log into his car and see how the application works. From the point of view of Kubernetes, everything works in containers. There is a command `kubectl exec` - get into the container in the application and see what happens there. Therefore, there is no need to go to AWS instances. We denied access for everyone except the infra team.
Moreover, we have banned long-playing admin keys, entry through roles. If there is an opportunity to use the role of admin - I am admin. Plus we added the rotation of the keys. It is convenient to configure through the awsudo command, this is a project on a githabe, I highly recommend it, it allows you to work as with a sudo command.
Quotas. Very nice stuff in Kubernetes, works right out of the box. You limit some namespace, say, by the number of objects, memory or CPU that you can consume. I think this is important and useful for everyone. We have not yet reached the memory and CPU, we use only the number of objects, but we will add all this.
Big and fat plus allows you to do a lot of tricky things.
Scaling. You cannot mix scaling inside Kubernetes and outside Kubernetes. Inside, Kubernetes does the scaling itself. It can increase pods automatically when there is a big load.
Here I am talking about the scaling of the Kubernetes instances themselves. This can be done using AWS Autoscaler, this is a project on a githabe. When you add a new pod and it cannot start because it lacks resources on all instances, AWS Autoscaler can automatically add nodes. Allows you to work on Spot-instances, we have not added this yet, but we will, it allows you to save a lot.
When you have a lot of users and applications from users, you need to somehow monitor them. This is usually telemetry, logs, some beautiful graphics.
For historical reasons, we had Sensu, he didn’t really fit for Kubernetes. A more metric-oriented project was needed. We looked at the whole TICK stack, especially InfluxDB. Good UI, SQL-like language, but lacked a few features. We switched to Prometheus.
He is good. Good query language, good alerts, and everything out of the box.
To send telemetry, we used Cernan. This is our own project written in Rust. This is the only project on Rust that has been in production for a year now. It has several concepts: there is a data source concept, you configure several sources. You configure where the data will merge. We have a configuration of filters, that is, the flowing data can be somehow processed. You can convert logs to metrics, metrics to logs, whatever you want.
Given that you have several inputs, several conclusions, and you show that where it is going, there is something like a large graph system, it turns out to be quite convenient.
We are now moving smoothly from the current Statsd / Cernan / Wavefront stack to Kubernetes. Theoretically, Prometheus wants to take data from applications itself, so all applications need to add an endpoint from which it will take metrics. Cernan is a transmission link, should work everywhere. There are two possibilities: you can run Kubernetes on each instance, you can use the Sidecar-concept, when there is another container in your data field that sends data. We do both.
At us right now all logs go to stdout / stderr. All applications are designed for this, so one of the critical requirements that we do not leave from this system. Cernan sends data to ElasticSearch, events from the entire Kubernetes system are sent there using Heapster. This is a very good system, I recommend.
After that, you can view all the logs in one place, for example, in the console. We use Kibana. There is a wonderful product Stern, just for the logs. It allows you to watch, paints different colors in different colors, can see when one died and the other restarted. Automatically picks up all logs. An ideal project, I highly recommend it, it’s fat plus Kubernetes, everything is fine here.
Secrets. We use S3 and KMS. We are thinking about switching to Vault or secrets in Kubernetes itself. They were in 1.7 able alpha, but something needs to be done about it.
We got to interesting. Development in Kubernetes is generally considered a little. Basically it says: "Kubernetes is an ideal system, everything is fine in it, let's move on."
But in fact, free cheese is only in a mousetrap, and for developers in Kubernetes - hell.
Not from the point of view that everything is bad, but from the fact that you need to look at things a little differently. I compare the development in Kubernetes with functional programming: until you touch it, you think in your imperative style, everything is fine. In order to develop in the functional area, it is necessary to turn the head a little bit on the other side - here it is the same.
You can develop, you can, but you need to look at it differently. First, understand the Docker Way concept. This is not that difficult, but to understand it completely is quite problematic. Most developers are used to saying that they are logging into their local, remote or virtual machine via SSH, they say: "Let me fix something here, podshamanyu."
You tell him that in Kubernetes this will not happen, because you only have the infrared. When you want to update the application, please make a new image that will work, and the old one, please do not touch it, it will simply die. I personally worked on introducing Kubernetes into different teams and I see horror in the eyes of people when they understand that all old habits will have to be completely discarded, come up with new, some new system, and this is very difficult.
Plus, you have to make a lot of choices: let's say, when you make any changes, if the development is local, you need to commit to the repository somehow, then the pipeline repository runs tests away, and then says, “Oh, there's a typo in one word,” you need everything do locally. Mount a folder in some way, go there, update the system, at least compile. If tests run locally inconveniently, then it can commit to CI at least to check for some local actions, and then send them to CI for verification. These choices are quite complicated.
It is especially difficult when you have a spreading application consisting of one hundred services, and in order for one of them to work, you need to ensure the work of all the others side by side. You need to either emulate the environment, or somehow run locally. This whole choice is not trivial, the developer needs to think a lot about it. Because of this, there is a negative attitude towards Kubernetes. Of course, he is good - but he is bad, because you need to think a lot and change your habits.
Therefore, here three fat cats ran across the road.
When we looked at Kubernetes, we tried to understand, maybe there are some convenient systems for development. In particular, there is such a thing as Deis, for sure you have heard about it all. It is very easy to use, and we checked, in fact, all simple projects are very easy to switch to Deis. But the problem is that more complex projects can not go to Deis.
As I said, we switched to Helm Charts. But the only problem that we see now is that you need a lot of good documentation. We need some How-tos, some FAQs in order for a person to quickly start, copy the current configs, paste in his own, change the names so that everything is correct. It is also important to understand in advance, and you need to do it all. I have here listed common development toolkits, I will not touch all this, except for the mini-cube.
Minikube is a very good system, in the sense that it is good that it is, but badly, that in this form. It allows you to run Kubernetes locally, allows you to see everything on your laptop, do not go anywhere on SSH, and so on.
I work on MacOS, I have a Mac, respectively, in order to run the local app, I need to run the docker locally. It can not be done in any way. As a result, you must either run the virtualbox, or xhyve. Both things are, in fact, emulating on top of my operating system. We use xhyve, but we recommend using VirtualBox, since there are a lot of bugs, they have to be bypassed.
But the very idea that there is virtualization, and inside virtualization, another level of abstraction is launched for virtualization, some kind of ridiculous, delusional. In general, it is good that it somehow works, but it would be better to complete it.
CI is not directly related to Kubernetes, but it is a very important system, especially if you have Kubernetes, if you integrate it, you can get very good results. We used Concourse for CI, a very rich functionality, you can build scary graphs, what, where, how it starts, what it depends on. But Concourse developers have a very strange attitude towards their product. For example, during the transition from one version to another, they broke backward compatibility and most of the plug-ins did not rewrite. Moreover, the documentation was not added, and when we tried to do something, nothing worked at all.
There is little documentation at all in all CIs, we have to read the code, and, in general, we have abandoned Concourse. We switched to Drone.io - it is small, very light, nimble, the functionality is much less, but more often it is enough. Yes, large and weighty dependency graphs - it would be convenient to have, but you can also work on small ones. Too little documentation, read the code, but it is ok.
Each stage of the pipeline works in its own docker-container, this allows you to greatly simplify the transition to Kubernetes. If there is an application that runs on a real machine, in order to add to the CI, use the docker container, and then go to Kubernetes easier.
We have an automatic release of the admin / stage cluster set up, while in the production cluster we are still afraid to add a setting. Plus there is a plugin system.
This is an example of a simple Drone-config. Taken from a ready-made working system, in this case there are five steps in the pipeline, each step does something: assembles, tests, and so on. With the feature set that is in the Drone, I think this is a good thing.
We argued a lot about how many clusters to have: one or more. When we came up with the idea of several clusters, we began to work further in this direction, created some scripts, put a bunch of other cubes to our Kubernetes. After that, they came to Google and asked for advice, did they do everything, maybe something needs to be fixed.
Google agreed that the idea of a single cluster does not apply to Kubernetes. There are many shortcomings, in particular, work with geolocation. It turns out that the idea is correct, but it is too early to talk about it. Maybe later. While Service Mesh can help.
In general, if you want to see how our system works, pay attention to Geodesic. This is a product similar to what we do. It is open source, a very similar design concept choice. We are thinking of joining together and possibly using them.
Yes, there are problems in our Kubernetes practice too.
There is a pain with local names, with certificates. There is a problem with the downloads of large images and their work, perhaps related to the file system, we have not dug there. There are already three different ways to install Kubernetes extensions. We have been working on this project for less than a year, and we already have three different ways, annual rings are growing.
Let's make all the cons.
So, I think that one of the main drawbacks is a large amount of information to study, not only new technologies, but also new concepts and habits. It’s like learning a new language: in principle, it’s easy, but it’s difficult to turn your head a little to all users. If you have not worked with such concepts before - it is hard to switch to Kubernetes.
Kubernetes will be just a small part of your system. Everyone thinks that they will install Kubernetes, and everything will work right away. No, this is a small cube, and there will be many such cubes.
Some applications are in principle difficult to run on Kubernetes - and it is better not to run. Also very heavy and large configuration files, and in concepts over Kubernetes they are even more difficult. All current solutions are raw.
All these cons, of course, disgusting.
Compromises and difficult transition create a negative image of Kubernetes, and I don’t know how to deal with it. We couldn’t overcome much, there are people who hate the whole movement, do not want and do not understand its advantages.
In order to run Minikube, your system, so that everything works, will have to try hard. As you can see, there are a lot of minuses, and those who do not want to work with Kubernetes have their own reasons. If you do not want to hear about the pros - close your eyes and ears, because they will go on.
The first plus - over time will have less and less to learn beginners. It often happens that when a newcomer comes into the system, he begins to pull out all his hair, because for the first 1-2 months he tries to figure out how to release all this, if the system is large and lives for a long time, many annual rings have grown. In Kubernetes, everything will be easier.
Secondly, Kubernetes does not do it himself, but lets make a short release cycle. A commit created CI, a CI created an image, automatically swapped, you pressed a button, and everything went into production. This greatly reduces the release time.
The following is code separation. Our system and most of your systems in one place collect configs of different levels, that is, you have an infrastructure code, a business code, all the logic is mixed in one place. In Kubernetes this will not be out of the box, choosing the right concept helps to avoid this in advance.
A large and very active community, which means a large number of changes. Most of what I mentioned over the past two years has become so stable that they can be produced in production. Perhaps some of them appeared early, but it was not very stable.
I consider it a great advantage that in one place you can see both application logs and Kubernetes logs with your application, which is invaluable. And there is no access to the node. When we removed user access to nodes, it immediately cuts off a large class of problems.
The second part of the advantages is a bit more conceptual. Most of the Kubernetes community see the technology part. But we saw the conceptual management part. After you go to Kubernetes, and if this is all set up correctly, the infrared command (or backend — I don’t know how you call it right) is no longer needed to release the applications.
The user wants to release the application, he will not come with a request for this, but simply launch a new pod, there is a command for this. Infracommand is not needed to investigate problems. Just look at the logs, our set of designs is not so big, there is a list according to which it is very easy to find the problem. Yes, support is sometimes needed if the problem is in Kubernetes, in instances, but most often there is a problem with applications.
We added Error Budget. This is the following concept: each team has statistics on how many problems occur in production. If there are too many problems, the team is cut releases, until some time has passed. This is good because the team will seriously ensure that their releases are very stable. Need new functionality - please release. Want to release at two in the morning - please. If after releases you have only “nines” in SLA - do what you want, everything is stable, you can do anything. However, if the situation is worse, most likely we will not allow releasing anything except fixes.
This is a handy thing for both the stability of the system and the mood within the team. We cease to be a “Police of Morals”, not letting us release late at night. Do what you want while you have a good budget of mistakes. This greatly reduces the tension within the company.
To contact me, you can use the mail or tweet: @gliush .
And at the end for you a lot of links, you can download everything yourself and see:
- Container-Native Networking - Comparison
- Continuous Delivery by Jez Humble, David Farley.
- Containers are not VMs
- Docker Distribution (image registry)
- Quay - Image Registry as a Service
- etcd-operator - Manager of etcd cluster atop Kubernetes
- Dex - OpenID Connect Identity (OIDC) and OAuth 2.0 Provider with Pluggable Connectors
- awsudo - sudo-like utility to manage AWS credentials
- Autoscaling-related components for Kubernetes
- Simon's cat
- Helm: Kubernetes package manager
- Geodesic: framework to create your own cloud platform
- Calico: Configuring IP-in-IP
- Sensu: Open-core monitoring system
- InfluxDB: Scalable datastore for metrics, events, and real-time analytics
- Cernan: Telemetry and logging aggregation server
- Prometheus: Open Source monitoring solution
- Heapster: Compute Resource Usage Analysis and Monitoring of Containers Clusters
- Stern: Multi pod and container log tailing for Kubernetes
- Minikube: tool to run Kubernetes locally
- Xyve docker machine driver xyve native OS X hypervisor
- Drone: Continuous Delivery Platform
- Borg, Omega and Kubernetes
- Container-Native Networking - Comparison
- Bug in minikube when working with xhyve driver.
Minute advertising. If you liked this report from the DevOops conference - note that the new DevOops 2018 will be held in St. Petersburg on October 14th, its program will also have a lot of interesting things. The site already has the first speakers and reports.