About Web 3.0 and more
The topic raised around Web 2.0 is now very popular and has many interesting resources devoted to it. And what will Web 3.0 be like then?
First about Web 2.0
There are several main aspects of this phenomenon
1. Web services
2. AJAX
3. Web syndication
4. Mash-up
5. Tags (tags)
In the article “Tim O'Reilly, What is Web 2.0“ (Computerra, October 11, 2005) a map of Web 2.0 is shown.
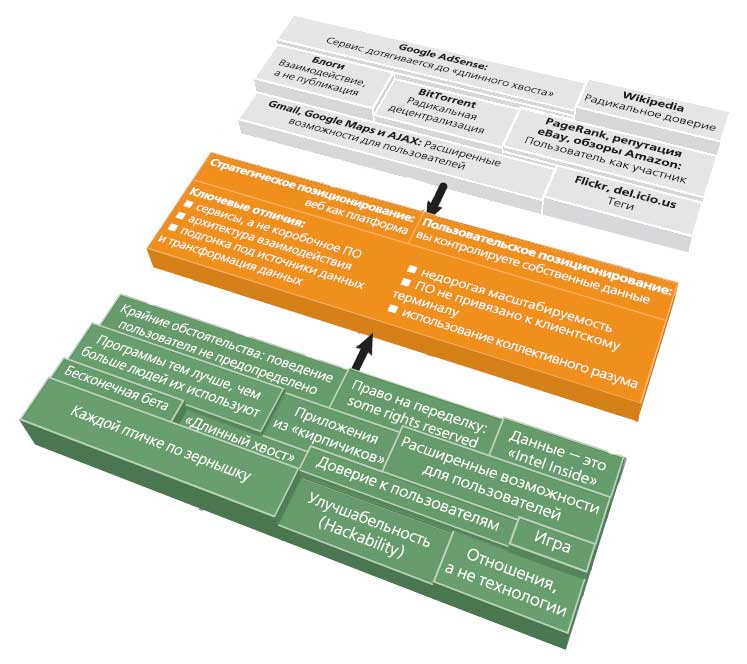
But after Web 2.0 there will be Web 3.0.
What kind of monster will it be?
On the Web, Web 3.0 means the following:
Thus, this is a transition from the issuance of information on request to the issuance of information on the needs of the client
So far, the following development option for this scheme is possible:
Changing the processing of search queries from users, the search engine will know information about the user, because collect user data and analyze it. It may be necessary to log in before entering a query into the search box, after which the system will identify the user and will know about his needs, after entering a search query, for example, “Tours to Egypt”, along with a search on the Internet, a search by user’s data and on his blog posts. When issuing results, data from the questionnaire and user records are also taken into account. That is, if a user went to such a resort in Egypt last year and did not like it, and wrote about it on his blog, then this is taken into account when issuing the result.
What is very interesting, if we compare the latest data on the development of Yandex:
-
Blog search development - Yandex purchase of the MyKrug service
- Launch of the Ya.ru service in a test version
I think this scheme can soon translate Yandex into reality.
So wait for the arrival of Web 3.0
First about Web 2.0
There are several main aspects of this phenomenon
1. Web services
2. AJAX
3. Web syndication
4. Mash-up
5. Tags (tags)
In the article “Tim O'Reilly, What is Web 2.0“ (Computerra, October 11, 2005) a map of Web 2.0 is shown.
But after Web 2.0 there will be Web 3.0.
What kind of monster will it be?
On the Web, Web 3.0 means the following:
Web 3.0 is a system that can give a clear and maximally complete answer to a simple request like this: “I am looking for a warm resort to relax during my holidays; I have $ 3,000 for it. And by the way, I will have an 11-year-old child with me. ” Under current conditions, the search for such information may take more than one hour: you have to look through the lists of flights, hotels, and car rental companies. In the conditions of "Web 3.0", the user, ideally, should immediately receive a complete package of information as professionally and efficiently as if an agent of a travel company did it.
Thus, this is a transition from the issuance of information on request to the issuance of information on the needs of the client
So far, the following development option for this scheme is possible:
Changing the processing of search queries from users, the search engine will know information about the user, because collect user data and analyze it. It may be necessary to log in before entering a query into the search box, after which the system will identify the user and will know about his needs, after entering a search query, for example, “Tours to Egypt”, along with a search on the Internet, a search by user’s data and on his blog posts. When issuing results, data from the questionnaire and user records are also taken into account. That is, if a user went to such a resort in Egypt last year and did not like it, and wrote about it on his blog, then this is taken into account when issuing the result.
What is very interesting, if we compare the latest data on the development of Yandex:
-
Blog search development - Yandex purchase of the MyKrug service
- Launch of the Ya.ru service in a test version
I think this scheme can soon translate Yandex into reality.
So wait for the arrival of Web 3.0