What is GitOps?
- Transfer
Note perev. : After the recent publication of material on pull and push methods in GitOps, we saw interest in this model as a whole, however, there were very few Russian-language publications on this topic (they simply aren’t on the hub). Therefore, we are pleased to bring to your attention a translation of another article - albeit almost a year ago! - from the company Weaveworks, the head of which coined the term "GitOps". The text explains the essence of the approach and the key differences from existing ones.

A year ago, we published an introduction to GitOps . Then we talked about how the Weaveworks team launched Kubernetes-based SaaS, and developed a set of prescriptive best practices for deploying, managing, and monitoring in a cloud native environment.
The article turned out to be popular. Other people started talking about GitOps, began to publish new tools for git push , development , secrets , functions , continuous integration , etc. A large number of publications and use cases of GitOps have appeared on our site . But some people still have questions. The model differs from the traditional infrastructure as code and continuous delivery ( continuous delivery mail )? Is it mandatory to use Kubernetes?
Soon, we realized that a new description was needed, offering:
In this article, we tried to cover all of these topics. In it you will find an updated introduction to GitOps and a look at it from the side of developers and CI / CD. We mainly focus on Kubernetes, although the model can be generalized.
Imagine Alice. She runs Family Insurance, a company that offers health, car, real estate, and travel insurance policies for people who are too busy to understand the nuances of their contracts on their own. Her business began as a side project when Alice worked at the bank as a data scientist. Once she realized that she could use advanced computer algorithms to more efficiently analyze data and form insurance packages. Investors funded the project, and now her company brings in more than $ 20 million a year and is growing rapidly. Currently, 180 people work in various positions in it. Among them, a technology team that develops, maintains a site, a database and analyzes the client base.
Bob's team is deploying production systems in the cloud. Their main applications run on GKE, taking advantage of Kubernetes on Google Cloud. In addition, they use various tools for working with data and analytics in their work.
Family Insurance was not going to use containers, but was infected with enthusiasm for Docker. Soon, company experts discovered that GKE makes it easy and easy to deploy clusters to test new features. Jenkins for CI and Quay were added to organize the container registry, scripts for Jenkins were written that push or new containers and configurations in GKE.
Some time has passed. Alice and Bob were disappointed in the performance of the chosen approach and its impact on the business. The introduction of containers did not increase productivity as much as the team hoped. Sometimes deployments broke, and it was unclear if the code changes were to blame. It also turned out to be difficult to track changes in configs. Often it was necessary to create a new cluster and move applications into it, since it was the easiest way to eliminate the mess into which the system turned. Alice was afraid that the situation would worsen as the application developed (in addition, a new project based on machine learning was brewing). Bob automated most of the work and did not understand why the pipeline is still unstable, does not scale well and requires manual intervention from time to time?
Then they learned about GitOps. This decision turned out to be exactly what they needed to confidently move forward.
Alice and Bob have heard about workflows based on Git, DevOps, and infrastructure as code for years. The uniqueness of GitOps is that it brings a number of best practices - categorical and normative - to implement these ideas in the context of Kubernetes. This topic has been raised repeatedly , including on the Weaveworks blog .
Family Insurance decides to implement GitOps. The company now has an automated operating model compatible with Kubernetes that combines speed with stability , as they:
GitOps are two things:
If you are not familiar with version control systems and the Git-based workflow, we strongly recommend that you study them. At first, working with branches and pull requests may seem like black magic, but the pros are worth the effort. Here is a good article to get you started.
In our story, Alice and Bob turned to GitOps after working with Kubernetes for a while. Indeed, GitOps is closely linked to Kubernetes - it is an operational model for the infrastructure and applications based on Kubernetes.
Here are some key features:
When an administrator makes configuration changes, the Kubernetes orchestrator will apply them to the cluster until its state approaches the new configuration . This model works for any Kubernetes resource and extends with Custom Resource Definitions (CRDs). Therefore, Kubernetes deployments have the following wonderful properties:
We've learned enough about Kubernetes to explain how GitOps works.
Let's get back to Family Insurance teams related to microservices. What do they usually have to do? Look at the list below (if any points in it seem strange or unfamiliar - please postpone criticism and stay with us). These are just examples of Jenkins-based workflows. There are many other processes when working with other tools.
The main thing is that we see that each update ends with changes to the configuration files and Git repositories. These changes in Git lead to the fact that the “GitOps operator” updates the cluster:
1. Workflow: “ Build Jenkins - master branch ”.
Task list:
2. Jenkins build - release or hotfix branch :
3. Jenkins build - develop or feature branch :
4. Adding a new client :
We repeat again: all the desired properties of the cluster should be observable in the cluster itself .
A few examples of divergence:
A few examples:
GitOps combines Git with Kubernetes' excellent convergence engine, offering a model for operation.
GitOps allows us to declare that only those systems that can be described and observed can be automated and controlled .
GitOps is not only Kubernetes. We want the whole system to be managed declaratively and to use convergence. By an entire system we mean a set of environments working with Kubernetes - for example, “dev cluster 1”, “production”, etc. Each environment includes machines, clusters, applications, as well as interfaces for external services that provide data, monitoring and etc.
Note how important Terraform is in this case for bootstrapping. Kubernetes needs to be deployed somewhere, and using Terraform means that we can use the same GitOps workflows to create the control layer that underlies Kubernetes and applications. This is a good best practice.
Much attention is paid to applying GitOps concepts to layers over Kubernetes. Currently there are GitOps-type solutions for Istio, Helm, Ksonnet, OpenFaaS and Kubeflow, as well as, for example, for Pulumi, which create a layer for developing applications for cloud native.
As stated, GitOps are two things:
For many, GitOps is primarily a Git push-based workflow. We like him too. But this is not all: let's now look at the CI / CD pipelines.
GitOps offers a continuous deployment mechanism that eliminates the need for separate “deployment management systems." Kubernetes does all the work for you.
Avoid using Kubectl to upgrade the cluster, and especially scripts to group kubectl commands. Instead, with a GitOps pipeline, a user can upgrade their Kubernetes cluster through Git.
Benefits include:
GitOps improves on existing CI / CD models.
The modern CI server is an instrument for orchestration. In particular, it is an instrument for orchestrating CI pipelines. They include build, test, merge to trunk, etc. CI servers automate the management of complex multi-step pipelines. A common temptation is to create a script for the Kubernetes update set and execute it as a pipeline element for pushing changes to the cluster. Indeed, this is what many experts do. However, this is not optimal, and here's why.
CI must be used to make updates to the trunk, and the Kubernetes cluster must change itself based on these updates in order to manage the CD “internally”. We call it a pull model for CD, unlike the CI push model. The CD is part of a runtime orchestration .
Do not use the CI server to orchestrate direct updates in Kubernetes as a set of CI tasks. This is the anti-pattern that we already talked about on our blog.
Let's get back to Alice and Bob.
What problems did they encounter? Bob's CI server applies the changes to the cluster, but if it falls in the process, Bob will not know what state the cluster is (or should be) in and how to fix it. The same is true if successful.
Let's assume that Bob’s team put together a new image and then patched their deployments to deploy the image (all from the CI pipeline).
If the image builds normally, but the pipeline falls, the team will have to find out:
Organizing a Git-based workflow does not guarantee that Bob’s team will not encounter these problems. They can still be mistaken with the push push of the commit, with a tag or some other parameter; however, this approach is still much closer to an explicit all-or-nothing.
To summarize, this is why CI servers should not handle CDs:
Примечание о Helm'e: если вы хотите использовать Helm, мы рекомендуем объединить его с GitOps-оператором, таким как Flux-Helm. Это поможет обеспечить конвергентность. Сам по себе Helm не является ни детерминированым, ни атомарным.
Alice and Bob's team implements GitOps and discovers that it has become much easier to work with software products, maintain high performance and stability. Let's end this article with illustrations showing what their new approach looks like. Keep in mind that we are mainly talking about applications and services, however GitOps can be used to manage the entire platform.
Look at the following chart. She presents Git and the container image repository as shared resources for two orchestrated life cycles:

GitOps provides the powerful upgrade guarantees needed by any modern CI / CD tool:
This is important because it offers an exploitation model for cloud native developers.
Imagine lots of clusters scattered across different clouds and lots of services with your own teams and deployment plans. GitOps offers a scale-invariant model for managing all this abundance.
Read also in our blog:
A year ago, we published an introduction to GitOps . Then we talked about how the Weaveworks team launched Kubernetes-based SaaS, and developed a set of prescriptive best practices for deploying, managing, and monitoring in a cloud native environment.
The article turned out to be popular. Other people started talking about GitOps, began to publish new tools for git push , development , secrets , functions , continuous integration , etc. A large number of publications and use cases of GitOps have appeared on our site . But some people still have questions. The model differs from the traditional infrastructure as code and continuous delivery ( continuous delivery mail )? Is it mandatory to use Kubernetes?
Soon, we realized that a new description was needed, offering:
- A large number of examples and stories;
- The specific definition of GitOps;
- Comparison with traditional continuous delivery.
In this article, we tried to cover all of these topics. In it you will find an updated introduction to GitOps and a look at it from the side of developers and CI / CD. We mainly focus on Kubernetes, although the model can be generalized.
Meet GitOps
Imagine Alice. She runs Family Insurance, a company that offers health, car, real estate, and travel insurance policies for people who are too busy to understand the nuances of their contracts on their own. Her business began as a side project when Alice worked at the bank as a data scientist. Once she realized that she could use advanced computer algorithms to more efficiently analyze data and form insurance packages. Investors funded the project, and now her company brings in more than $ 20 million a year and is growing rapidly. Currently, 180 people work in various positions in it. Among them, a technology team that develops, maintains a site, a database and analyzes the client base.
Bob's team is deploying production systems in the cloud. Their main applications run on GKE, taking advantage of Kubernetes on Google Cloud. In addition, they use various tools for working with data and analytics in their work.
Family Insurance was not going to use containers, but was infected with enthusiasm for Docker. Soon, company experts discovered that GKE makes it easy and easy to deploy clusters to test new features. Jenkins for CI and Quay were added to organize the container registry, scripts for Jenkins were written that push or new containers and configurations in GKE.
Some time has passed. Alice and Bob were disappointed in the performance of the chosen approach and its impact on the business. The introduction of containers did not increase productivity as much as the team hoped. Sometimes deployments broke, and it was unclear if the code changes were to blame. It also turned out to be difficult to track changes in configs. Often it was necessary to create a new cluster and move applications into it, since it was the easiest way to eliminate the mess into which the system turned. Alice was afraid that the situation would worsen as the application developed (in addition, a new project based on machine learning was brewing). Bob automated most of the work and did not understand why the pipeline is still unstable, does not scale well and requires manual intervention from time to time?
Then they learned about GitOps. This decision turned out to be exactly what they needed to confidently move forward.
Alice and Bob have heard about workflows based on Git, DevOps, and infrastructure as code for years. The uniqueness of GitOps is that it brings a number of best practices - categorical and normative - to implement these ideas in the context of Kubernetes. This topic has been raised repeatedly , including on the Weaveworks blog .
Family Insurance decides to implement GitOps. The company now has an automated operating model compatible with Kubernetes that combines speed with stability , as they:
- found that the team has doubled productivity and no one is going crazy;
- stopped servicing scripts. Instead, they can now concentrate on new features and improve engineering methods - for example, introduce canary roll-outs and improve testing;
- improved deployment process - now it rarely breaks;
- got the opportunity to recover deployments after partial failures without manual intervention;
- purchased used to increase confidence in delivery systems. Alice and Bob found that the team can be divided into groups that work in microservices and work in parallel;
- can make 30-50 changes to the project every day by the efforts of each group and try new techniques;
- they are easily attracted to the project by new developers who have the ability to roll updates on production using pull requests in a few hours;
- easily audited within SOC2 (for compliance of service providers with requirements for secure data management; read more, for example, here - approx. transl.) .
What happened
GitOps are two things:
- Operation model for Kubernetes and cloud native. It provides a set of best practices for deploying, managing, and monitoring containerized clusters and applications. Elegant definition in a single slide from Luis Faceira :

- The path to creating a developer-oriented environment for managing applications. We apply the Git workflow to both exploitation and development. Please note that this is not just about Git push, but about organizing the entire set of CI / CD and UI / UX tools.
A few words about Git
If you are not familiar with version control systems and the Git-based workflow, we strongly recommend that you study them. At first, working with branches and pull requests may seem like black magic, but the pros are worth the effort. Here is a good article to get you started.
How Kubernetes Works
In our story, Alice and Bob turned to GitOps after working with Kubernetes for a while. Indeed, GitOps is closely linked to Kubernetes - it is an operational model for the infrastructure and applications based on Kubernetes.
What does Kubernetes give users?
Here are some key features:
- In the Kubernetes model, everything can be described in a declarative form.
- The Kubernetes API server accepts such a declaration as input, and then constantly tries to bring the cluster to the state described in the declaration.
- Declarations are sufficient to describe and manage a wide variety of workloads — “applications.”
- As a result, changes to the application and the cluster are due to:
- changes to container images;
- changes to the declarative specification;
- errors in the environment - for example, container crashes.
Kubernetes' great convergence abilities
When an administrator makes configuration changes, the Kubernetes orchestrator will apply them to the cluster until its state approaches the new configuration . This model works for any Kubernetes resource and extends with Custom Resource Definitions (CRDs). Therefore, Kubernetes deployments have the following wonderful properties:
- Automation : Kubernetes updates provide a mechanism to automate the process of applying changes correctly and in a timely manner.
- Convergence : Kubernetes will continue to attempt updates until success.
- Idempotency : repeated applications of convergence produce the same result.
- Determinism : with sufficient resources, the state of the updated cluster depends only on the desired state.
How GitOps Works
We've learned enough about Kubernetes to explain how GitOps works.
Let's get back to Family Insurance teams related to microservices. What do they usually have to do? Look at the list below (if any points in it seem strange or unfamiliar - please postpone criticism and stay with us). These are just examples of Jenkins-based workflows. There are many other processes when working with other tools.
The main thing is that we see that each update ends with changes to the configuration files and Git repositories. These changes in Git lead to the fact that the “GitOps operator” updates the cluster:
1. Workflow: “ Build Jenkins - master branch ”.
Task list:
- Jenkins push tagged images in Quay;
- Jenkins push'it config and Helm charts to the master storage bucket;
- The cloud function copies the config and charts from the master storage bucket to the master git repository;
- The GitOps statement updates the cluster.
2. Jenkins build - release or hotfix branch :
- Jenkins push 'untagged images in Quay;
- Jenkins pushes the config and Helm charts to the bucket of staging storage;
- The cloud function copies the config and charts from the bucket of the staging storage to the Git repository staging;
- The GitOps statement updates the cluster.
3. Jenkins build - develop or feature branch :
- Jenkins push 'untagged images in Quay;
- Jenkins pushes the config and Helm charts to the develop storage bucket;
- The cloud function copies the config and charts from the develop storage bucket to the develop git repository;
- The GitOps statement updates the cluster.
4. Adding a new client :
- A manager or administrator (LCM / ops) calls Gradle to initially deploy and configure network load balancers (NLBs);
- LCM / ops commits a new config to prepare deployment for updates;
- The GitOps statement updates the cluster.
Short Description of GitOps
- Describe the desired state of the entire system using declarative specifications for each environment (in our history, the Bob team defines the entire system configuration in Git).
- The git repository is the only source of truth regarding the desired state of the entire system.
- All changes to the desired state are made through commits in Git.
- All desired cluster parameters are also observable in the cluster itself. Thus, we can determine whether the desired and observed states coincide (converge, converge ) or differ ( diverge , diverge ).
- If the desired and observed states are different, then:
- There is a convergence mechanism that sooner or later automatically synchronizes the target and observed states. Inside the cluster, Kubernetes does this.
- The process starts immediately with a “change committed” notification.
- After some configurable period of time, a diff alert can be sent if the states are different.
- Thus, all commits in Git trigger verifiable and idempotent updates in the cluster.
- Rollback is a convergence to a previously desired state.
- Convergence is final. About its onset testify:
- Lack of "diff" alerts for a certain period of time.
- A converged alert (for example, webhook, Git writeback event).
What is divergence?
We repeat again: all the desired properties of the cluster should be observable in the cluster itself .
A few examples of divergence:
- Change in the configuration file due to merging branches in Git.
- A change in the configuration file due to a commit in Git made by the GUI client.
- Multiple changes in the desired state due to PR in Git with the subsequent assembly of the container image and changes to the config.
- Cluster state change due to an error, resource conflict leading to “bad behavior”, or just an accidental deviation from the original state.
What is a convergence mechanism?
A few examples:
- For containers and clusters, the convergence mechanism provides Kubernetes.
- The same mechanism can be used to manage Kubernetes-based applications and designs (e.g., Istio and Kubeflow).
- The mechanism for managing the working interaction between Kubernetes, image repositories and Git is provided by the Weave Flux GitOps operator , which is part of the Weave Cloud .
- For base machines, the convergence mechanism must be declarative and autonomous. From our own experience, we can say that Terraform is closest to this definition, but still requires human control. In this sense, GitOps extends the tradition of Infrastructure as Code.
GitOps combines Git with Kubernetes' excellent convergence engine, offering a model for operation.
GitOps allows us to declare that only those systems that can be described and observed can be automated and controlled .
GitOps is for the entire cloud native stack (e.g. Terraform, etc.)
GitOps is not only Kubernetes. We want the whole system to be managed declaratively and to use convergence. By an entire system we mean a set of environments working with Kubernetes - for example, “dev cluster 1”, “production”, etc. Each environment includes machines, clusters, applications, as well as interfaces for external services that provide data, monitoring and etc.
Note how important Terraform is in this case for bootstrapping. Kubernetes needs to be deployed somewhere, and using Terraform means that we can use the same GitOps workflows to create the control layer that underlies Kubernetes and applications. This is a good best practice.
Much attention is paid to applying GitOps concepts to layers over Kubernetes. Currently there are GitOps-type solutions for Istio, Helm, Ksonnet, OpenFaaS and Kubeflow, as well as, for example, for Pulumi, which create a layer for developing applications for cloud native.
Kubernetes CI / CD: comparing GitOps with other approaches
As stated, GitOps are two things:
- The operational model for Kubernetes and cloud native described above.
- The path to organizing a developer-centric application management environment.
For many, GitOps is primarily a Git push-based workflow. We like him too. But this is not all: let's now look at the CI / CD pipelines.
GitOps Provides Continuous Deployment (CD) for Kubernetes
GitOps offers a continuous deployment mechanism that eliminates the need for separate “deployment management systems." Kubernetes does all the work for you.
- Updating the application requires updating in Git. This is a transactional upgrade to the desired state. The “deployment” is then carried out within the cluster by Kubernetes itself based on an updated description.
- Due to the specifics of Kubernetes, these updates are convergent. This provides a mechanism for continuous deployment in which all updates are atomic.
- Note: Weave Cloud offers a GitOps operator that integrates Git and Kubernetes and allows you to run a CD by matching the desired and current state of the cluster.
Without kubectl and scripts
Avoid using Kubectl to upgrade the cluster, and especially scripts to group kubectl commands. Instead, with a GitOps pipeline, a user can upgrade their Kubernetes cluster through Git.
Benefits include:
- Correctness . A group of updates can be applied, converged and finally validated, which brings us closer to the goal of atomic deployment. On the contrary, the use of scripts does not give any guarantees of convergence (more on this below).
- Security . Quoting Kelsey Hightower: “Limit access to the Kubernetes cluster to automation tools and administrators who are responsible for debugging or maintaining it.” See also my publication on security and compliance, as well as an article on hacking Homebrew by stealing credentials from a carelessly written Jenkins script.
- User experience . Kubectl exposes the mechanics of the Kubernetes object model, which is quite complex. Ideally, users should interact with the system at a higher level of abstraction. Here I will again refer to Kelsey and recommend looking at such a resume .
The difference between CI and CD
GitOps improves on existing CI / CD models.
The modern CI server is an instrument for orchestration. In particular, it is an instrument for orchestrating CI pipelines. They include build, test, merge to trunk, etc. CI servers automate the management of complex multi-step pipelines. A common temptation is to create a script for the Kubernetes update set and execute it as a pipeline element for pushing changes to the cluster. Indeed, this is what many experts do. However, this is not optimal, and here's why.
CI must be used to make updates to the trunk, and the Kubernetes cluster must change itself based on these updates in order to manage the CD “internally”. We call it a pull model for CD, unlike the CI push model. The CD is part of a runtime orchestration .
Why CI Servers Should Not Make CDs Through Direct Updates in Kubernetes
Do not use the CI server to orchestrate direct updates in Kubernetes as a set of CI tasks. This is the anti-pattern that we already talked about on our blog.
Let's get back to Alice and Bob.
What problems did they encounter? Bob's CI server applies the changes to the cluster, but if it falls in the process, Bob will not know what state the cluster is (or should be) in and how to fix it. The same is true if successful.
Let's assume that Bob’s team put together a new image and then patched their deployments to deploy the image (all from the CI pipeline).
If the image builds normally, but the pipeline falls, the team will have to find out:
- Has the update been deployed?
- Are we starting a new build? Will this lead to unnecessary side effects - with the ability to get two assemblies of the same immutable image?
- Should we wait for the next update before starting the assembly?
- What exactly went wrong? What steps need to be repeated (and which ones are safe to repeat)?
Organizing a Git-based workflow does not guarantee that Bob’s team will not encounter these problems. They can still be mistaken with the push push of the commit, with a tag or some other parameter; however, this approach is still much closer to an explicit all-or-nothing.
To summarize, this is why CI servers should not handle CDs:
- Update scripts are not always deterministic; it’s easy to make mistakes in them.
- CI servers do not convert to a declarative cluster model.
- Сложно гарантировать идемпотентность. Пользователи должны разбираться в глубокой семантике системы.
- Сложнее провести восстановление после частичного сбоя.
Примечание о Helm'e: если вы хотите использовать Helm, мы рекомендуем объединить его с GitOps-оператором, таким как Flux-Helm. Это поможет обеспечить конвергентность. Сам по себе Helm не является ни детерминированым, ни атомарным.
GitOps как лучший способ осуществлять Continuous Delivery для Kubernetes
Alice and Bob's team implements GitOps and discovers that it has become much easier to work with software products, maintain high performance and stability. Let's end this article with illustrations showing what their new approach looks like. Keep in mind that we are mainly talking about applications and services, however GitOps can be used to manage the entire platform.
Operation Model for Kubernetes
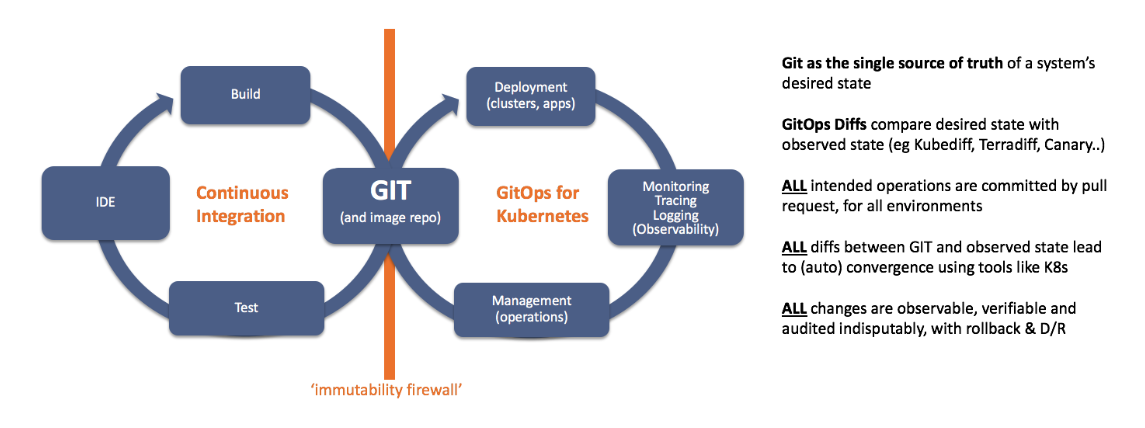
Look at the following chart. She presents Git and the container image repository as shared resources for two orchestrated life cycles:
- A continuous integration pipeline that reads and writes files to Git and can update the container image repository.
- Pipeline Runtime GitOps, combining deployment with control and observability. It reads and writes files to Git and can load container images.
Каковы основные выводы?
- Разделение проблем: Обратите внимание, что оба пайплайна могут обмениваться данными, только обновляя Git или репозиторий образов. Другими словами, существует сетевой экран между CI и runtime-средой. Мы называем его «брандмауэром неизменяемости» (immutability firewall), поскольку все обновления репозиториев создают новые версии. Для дополнительной информации по данной теме обратитесь к слайдам 72-87 этой презентации.
- Можно использовать любой CI- и Git-сервер: GitOps работает с любыми компонентами. Вы можете продолжать использовать свои любимые CI- и Git-серверы, репозитории образов и наборы тестов. Почти все остальные инструменты для Continuous Delivery на рынке требуют собственного CI-/Git-сервера или хранилища образов. Это может стать ограничивающим фактором в развитии cloud native. В случае GitOps вы можете использовать привычные инструменты.
- События как инструмент интеграции: Как только данные в Git обновляются, Weave Flux (или оператор Weave Cloud) извещает об этом runtime. Всякий раз, когда Kubernetes принимает набор изменений, Git обновляется. Это обеспечивает простую модель интеграции для организации рабочих процессов для GitOps, как показано ниже.
Заключение
GitOps provides the powerful upgrade guarantees needed by any modern CI / CD tool:
- automation;
- convergence;
- idempotency;
- determinism.
This is important because it offers an exploitation model for cloud native developers.
- Traditional tools for managing and monitoring systems are associated with operating teams operating within the framework of a runbook (a set of routine procedures and operations - approx. Transl.) Tied to a specific deployment.
- In managing cloud native systems, monitoring tools are the best way to evaluate deployment results so that the development team can quickly respond to them.
Imagine lots of clusters scattered across different clouds and lots of services with your own teams and deployment plans. GitOps offers a scale-invariant model for managing all this abundance.
PS from the translator
Read also in our blog:
Only registered users can participate in the survey. Please come in.
Did you know about GitOps before the appearance of these two translations on the hub?
- 22.4% Yes, I knew everything 11
- 34.6% Only superficially 17
- 42.8% No 21