End2End-approach to understanding spoken language
There are several approaches to understanding a colloquial speech machine: the classic three-component approach (includes a speech recognition component, a natural language comprehension component and a component responsible for a certain business logic) and an End2End approach that involves four implementation models: direct, collaborative, multi-stage and multi-tasking . Let's consider all the pros and cons of these approaches, including those based on Google’s experiments, and analyze in detail why the End2End approach solves the problems of the classical approach.

We give the floor to the leading developer of the AI MTS center Nikita Semenov.
Hello! As a preface, I want to quote the well-known scientists Jan Lekun, Joshua Benjio and Jeffrey Hinton - these are three pioneers of artificial intelligence who have recently received one of the most prestigious awards in the field of information technology - the Turing Award. In one of the issues of Nature magazine in 2015, they released a very interesting article “Deep learning”, in which there was an interesting phrase: “Deep learning came with the promise of its capability to deal with raw signals without the need for hand-crafted features”. It is difficult to correctly translate it, but the meaning is something like this: "Deep learning has come with the promise of the ability to cope with raw signals without the need for manual creation of signs." In my opinion, for developers this is the main motivator of all existing ones.
So, let's start with the classic approach. When we talk about understanding speaking with a machine, we mean that we have a certain person who wants to control some services with the help of his voice or feels the need for some system to respond to his voice commands with some logic.
How is this problem solved? In the classic version, a system is used, which, as mentioned above, consists of three large components: a speech recognition component, a component for understanding a natural language, and a component responsible for a certain business logic. It is clear that at first the user creates a certain sound signal, which falls on the speech recognition component and turns from sound to text. Then the text falls into the component of understanding the natural language, from which a certain semantic structure is pulled out, which is necessary for the component responsible for business logic.
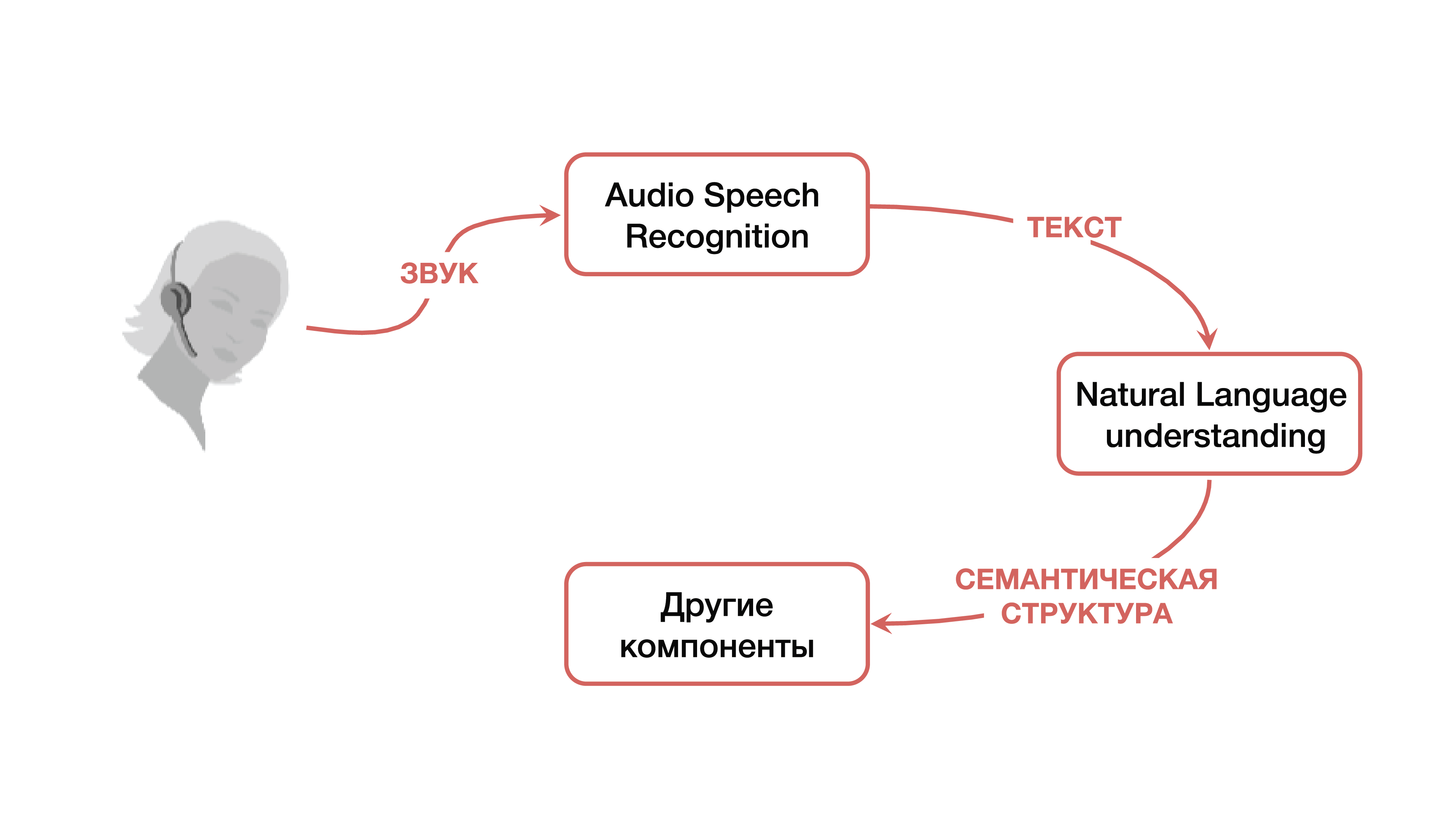
What is a semantic structure? This is a kind of generalization / aggregation of several tasks into one - for ease of understanding. The structure includes three important parts: the classification of the domain (a certain definition of the topic), the classification of intent (understanding what needs to be done) and the allocation of named entities to fill out cards that are necessary for specific business tasks in the next stage. To understand what a semantic structure is, you can consider a simple example, which Google most often cites. We have a simple request: "Please play some song of some artist."

The domain and subject matter in this request is music; intent - play a song; attributes of the “play a song” card - what kind of song, what kind of artist. Such a structure is the result of understanding a natural language.
If we talk about solving a complex and multi-stage problem of understanding colloquial speech, then, as I said, it consists of two stages: the first is speech recognition, the second is understanding natural language. The classical approach involves a complete separation of these stages. As a first step, we have a certain model that receives an acoustic signal at the input, and at the output, using linguistic and acoustic models and a lexicon, determines the most probable verbal hypothesis from this acoustic signal. This is a completely probabilistic story - it can be decomposed according to the well-known Bayes formula and obtain a formula that allows you to write the likelihood function of the sample and use the maximum likelihood method. We have a conditional probability of the signal X subject to the word sequence W,

The first stage we went through - we got a verbal hypothesis from the sound signal. Next comes the second component, which takes this very verbal hypothesis and tries to pull out the semantic structure described above.
We have the probability of the semantic structure S provided the verbal sequence W is at the input.

What is the bad thing about the classical approach, consisting of these two elements / steps, which are taught separately (i.e. we first train the model of the first element, and then the model of the second)?
We understood what the classical approach is, what problems it has. Let's try to solve these problems using the End2End approach.
By End2End we mean a model that will combine the various components into a single component. We will model using models that consist of encoder-decoder architecture containing modules of attention (attention). Such architectures are often used in speech recognition problems and in tasks related to the processing of a natural language, in particular, machine translation.
There are four options for the implementation of such approaches that could solve the problem posed before us by the classical approach: these are direct, collaborative, multi-stage and multi-tasking models.
The direct model takes on the input low-level raw attributes, i.e. low-level audio signal, and at the output we immediately get a semantic structure. That is, we get one module - the input of the first module from the classical approach and the output of the second module from the same classical approach. Just such a "black box". From here there are some pluses and some minuses. The model does not learn to fully transcribe the input signal - this is a clear plus, because we do not need to collect large, large markup, we do not need to collect a lot of audio signal, and then give it to the accessors for markup. We just need this audio signal and the corresponding semantic structure. And that’s all. This many times reduces the labor involved in marking up data. Probably the biggest minus of this approach is that the task is too complicated for such a "black box", who is trying to solve immediately, conditionally, two tasks. First, inside himself, he tries to build some kind of transcription, and then from this transcription reveal the very semantic structure. This raises a rather difficult task - to learn to ignore parts of transcription. And it is very difficult. This factor is a rather large and colossal minus of this approach.
If we talk about probabilities, then this model solves the problem of finding the most probable semantic structure S from the acoustic signal X with model parameters θ.
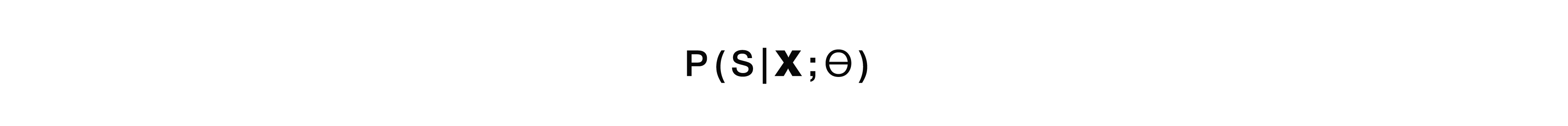
What is the alternative? This is a collaborative model. That is, some model is very similar to a straight line, but with one exception: the output for us already consists of verbal sequences and a semantic structure is simply concatenated to them. That is, at the input we have a sound signal and a neural network model, which at the output already gives both verbal transcription and semantic structure.
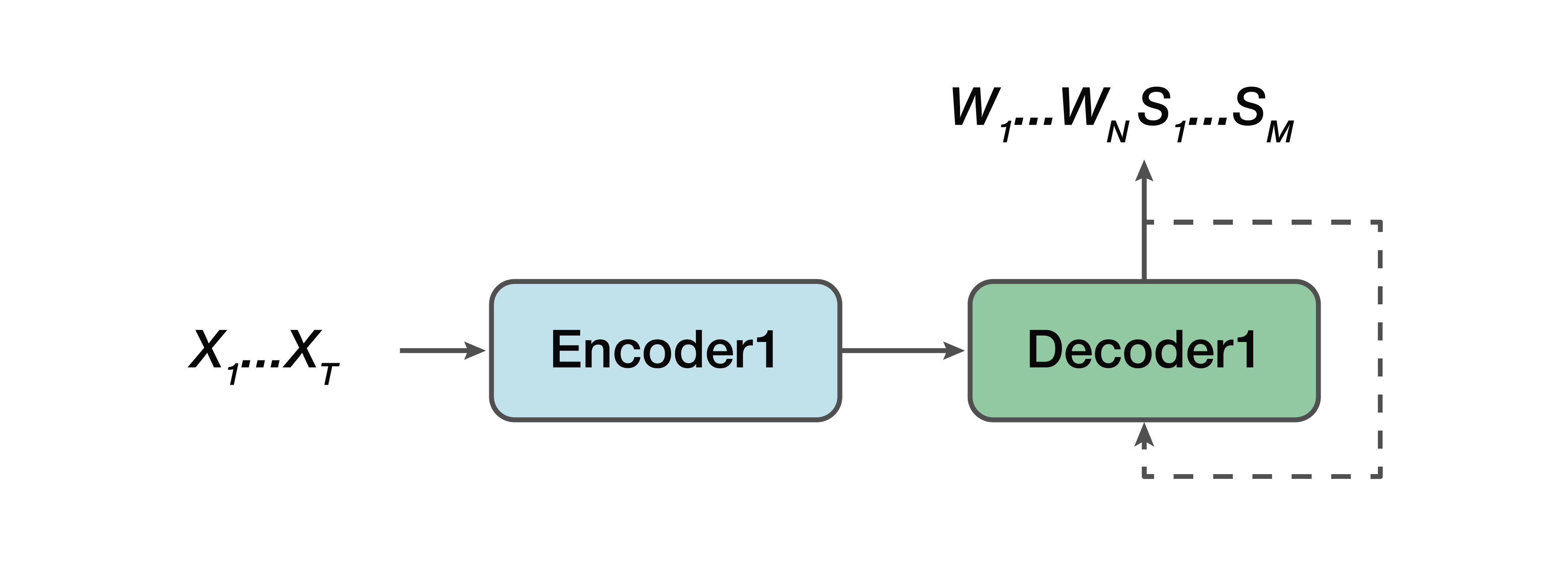
From the pros: we still have a simple encoder, a simple decoder. Learning is facilitated because the model does not try to solve two problems at once, as in the case of the direct model. One more advantage is that this dependence of the semantic structure on low-level sound attributes is still present. Because, again, one encoder, one decoder. And, accordingly, one of the pluses can be noted that there is a dependence in predicting this very semantic structure and its influence directly on transcription itself - which did not suit us in the classical approach.
Again, we need to find the most probable sequence of words W and the corresponding semantic structures S from the acoustic signal X with parameters θ.
The next approach is a multi-tasking model. Again, the encoder-decoder approach, but with one exception.
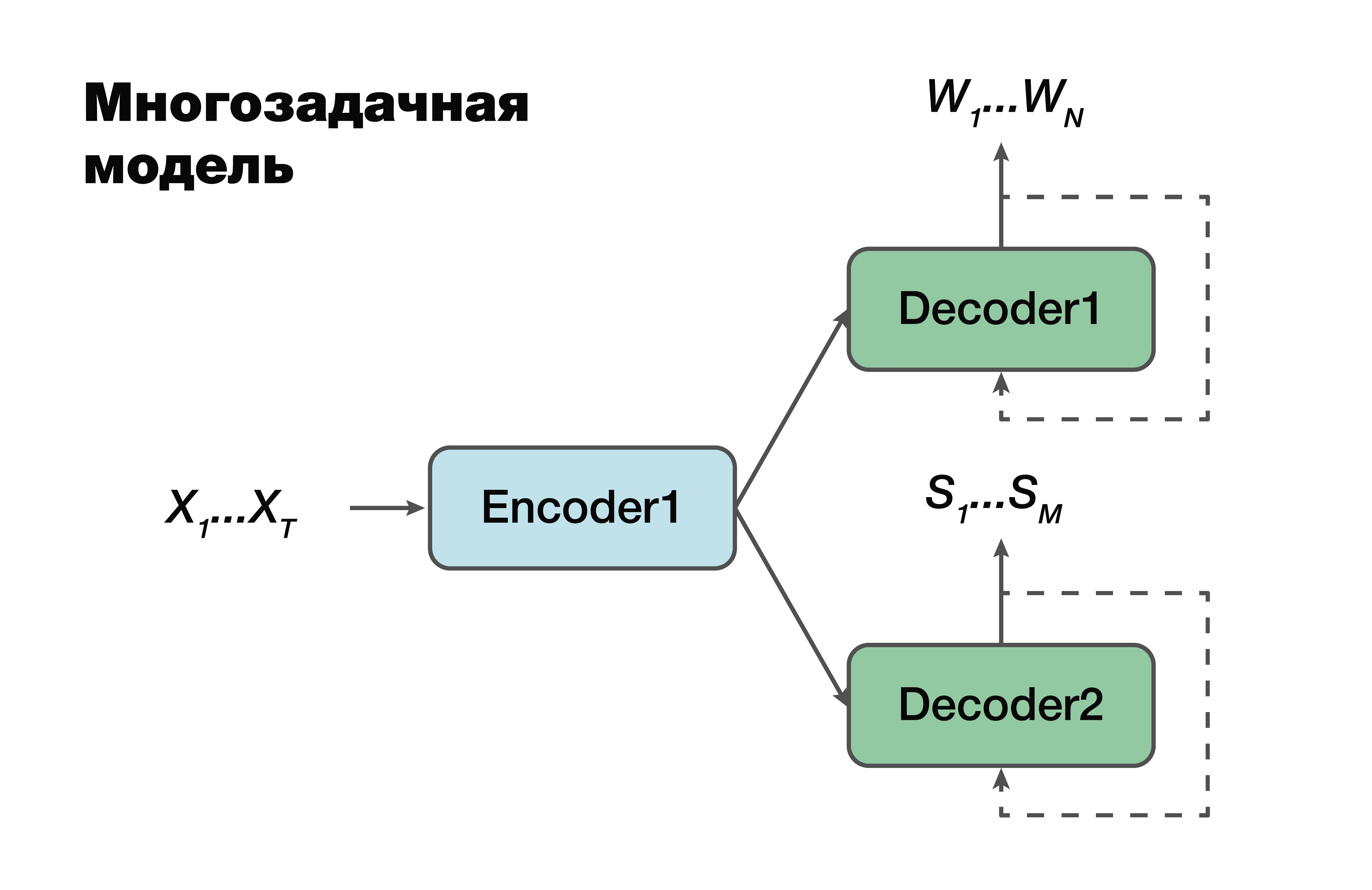
For each task, that is, to create a verbal sequence, to create a semantic structure, we have our own decoder that uses one common hidden representation that generates a single encoder. A very famous trick in machine learning, very often used in work. Solving two different problems at once helps to look for dependencies in the source data much better. And as a consequence of this - the best generalizing ability, since the optimal parameter is selected for several tasks at once. This approach is most suitable for tasks with less data. And decoders use one hidden vector space into which their encoder creates.

It is important to note that already in probability there is a dependence on the parameters of the encoder and decoder models. And these parameters are important.
We turn, in my opinion, to the most interesting approach: a multi-stage model. If you look very carefully, you can see that in fact this is the same two-component classical approach with one exception.
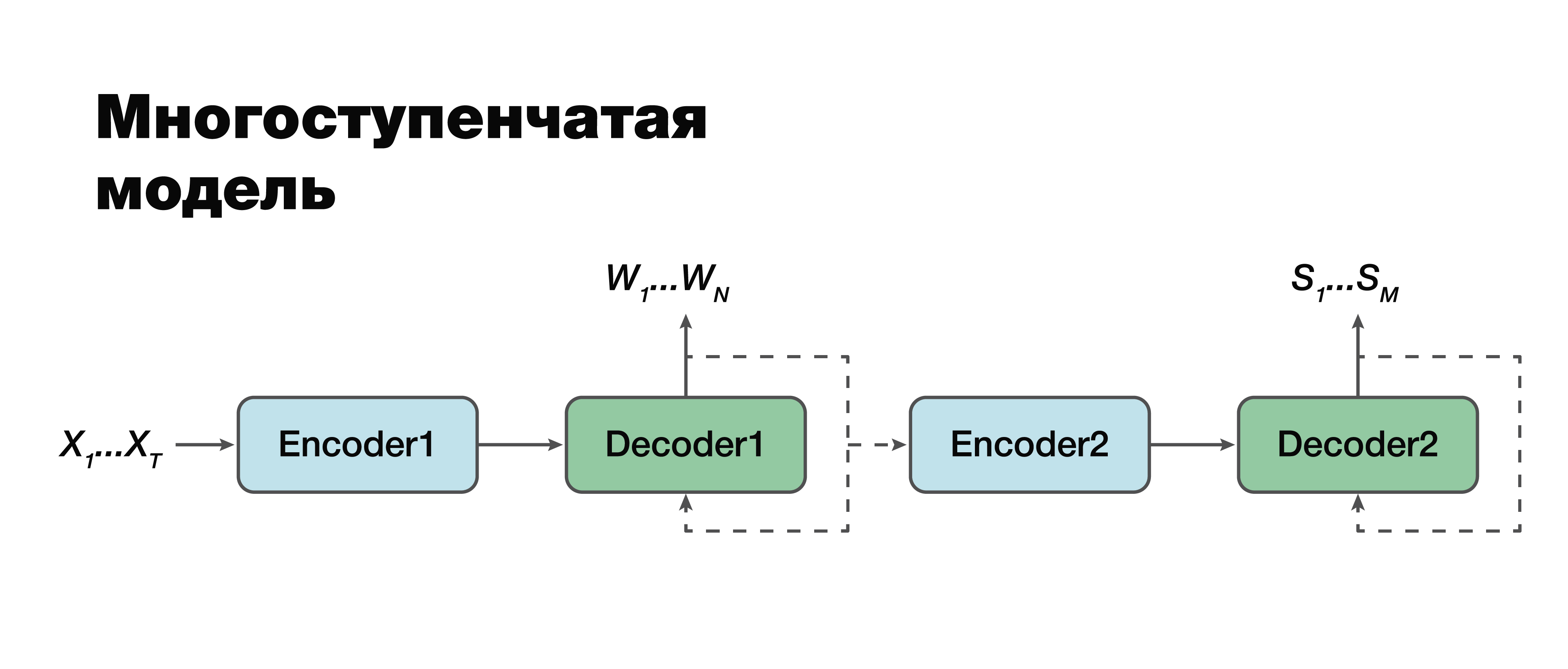
Here it is possible to establish a connection between the modules and make them single-module. Therefore, the semantic structure is considered conditionally dependent on transcription. There are two options for working with this model. We can individually train these two mini-blocks: the first and second encoder-decoder. Or combine them and train both tasks at the same time.
In the first case, the parameters for the two tasks are not related (we can train using different data). Suppose we have a large body of sound and the corresponding verbal sequences and transcriptions. We “drive” them, we train only the first part. We get in a good transcription simulation. Then we take the second part, we train on another case. We connect and get a solution that in this approach is 100% consistent with the classical approach, because we separately took and trained the first part and separately the second. And then we train the connected model on the case, which already contains triads of data: an audio signal, the corresponding transcription and the corresponding semantic structure. If we have such a case, we can retrain the model, individually trained on large buildings, for our specific small task and get the maximum gain in accuracy in such a tricky way. This approach allows us to take into account the importance of different parts of transcription and their influence on the prediction of semantic structure usingaccounting errors of the second stage in the first.
It is important to note that the final task is very similar to the classical approach with only one big difference: the second term of our function - the logarithm of the probability of the semantic structure - provided that the input acoustic signal X also depends on the parameters of the model of the first stage .

It is also important to note here that the second component depends on the parameters of the first and second models.
Now it’s worth deciding on the methodology for assessing accuracy. How, in fact, to measure this accuracy in order to take into account features that do not suit us in the classical approach? There are classic labels for these separate tasks. To evaluate speech recognition components, we can take the classic WER metric. This is a Word Error Rate. We consider, according to a not very complicated formula, the number of inserts, substitutions, permutations of the word and divide them by the number of all words. And we get a certain estimated characteristic of the quality of our recognition. For a semantic structure, componentwise, we can simply consider F1 score. This is also some classic metric for the classification problem. Here everything plus or minus is clear. There is fullness, there is accuracy. And this is just a harmonic mean between them.
But the question arises how to measure accuracy when the input transcription and the output argument do not match or when the output is audio data. Google has proposed a metric that will take into account the importance of predicting the first component of speech recognition by assessing the effect of this recognition on the second component itself. They called it Arg WER, that is, it weighs WER over the semantic structure entities.
Take the request: "Set the alarm for 5 hours." This semantic structure contains an argument such as “five hours”, an argument of the type “date time”. It is important to understand that if the speech recognition component produces this argument, then the error metric of this argument, that is, WER, is 0%. If this value does not correspond to five hours, then the metric has 100% WER. Thus, we simply consider the weighted average value for all the arguments and, in general, get a certain aggregated metric that estimates the importance of transcription errors that create the speech recognition component.
Let me give you an example of Google’s experiments that it conducted in one of its studies on this topic. They used data from five domains, five subjects: Media, Media_Control, Productivity, Delight, None - with the corresponding distribution of data on training test data sets. It is important to note that all models were trained from scratch. Cross_entropy was used, the beam search parameter was 8, the optimizer they used, of course, Adam. Considered, of course, on a large cloud of their TPU. What is the result? These are interesting numbers:
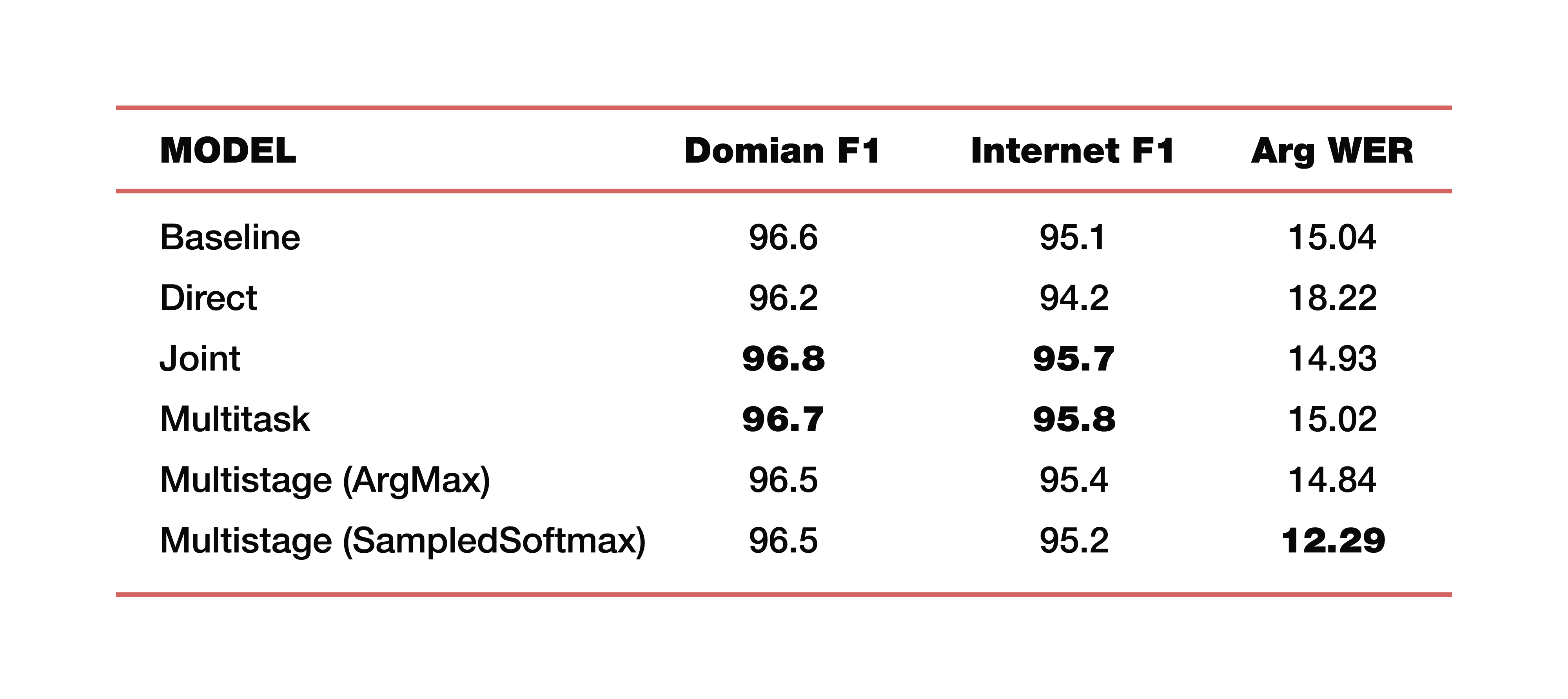
For understanding, Baseline is a classic approach that consists of two components, as we said at the very beginning. The following are examples of direct, connected, multitask, and multi-stage models.
How much are two multi-stage models? Just at the junction of the first and second parts, different layers were used. In the first case, this is ArgMax, in the second case, SampedSoftmax.
What you should pay attention to? The classical approach loses in all three metrics, which are an estimate of the direct collaboration of these two components. Yes, we are not interested in how well transcription is done there, we are only interested in how well the element that predicts the semantic structure works. It is evaluated by three metrics: F1 - by topic, F1 - by intent and ArgWer metric, which is considered by the arguments of entities. F1 is considered a weighted average between accuracy and completeness. That is, the standard is 100. ArgWer, on the contrary, is not a success, it is an error, that is, here the standard is 0.
It is worth noting that our coupled and multi-tasking models completely outperform all classification models for topics and intentions. And the model, which is multi-stage, has a very large increase in total ArgWer. Why is it important? Because in the tasks associated with understanding colloquial speech, the final action that will be performed in the component responsible for business logic is important. It does not directly depend on the transcriptions created by ASR, but on the quality of the ASR and NLU components working together. Therefore, a difference of almost three points in the argWER metric is a very cool indicator, which indicates the success of this approach. It is also worth noting that all approaches have comparable values by definition of topics and intentions.
I will give a couple of examples of the use of such algorithms for understanding conversational speech. Google, when talking about the tasks of understanding conversational speech, primarily notes the human-computer interfaces, that is, these are all sorts of virtual assistants such as Google Assistant, Apple Siri, Amazon Alexa, and so on. As a second example, it is worth mentioning such a task pool as Interactive Voice Response. That is, this is a certain story that is engaged in the automation of call centers.
So, we examined approaches with the possibility of using joint optimization, which helps the model focus on errors that are more important for SLUs. This approach to the task of understanding the spoken language greatly simplifies the overall complexity.
We have the opportunity to make a logical conclusion, that is, to obtain some kind of result, without the need for such additional resources as the lexicon, language models, analyzers, and so on (i.e. these are all factors that are inherent in the classical approach). The task is solved “directly”.
In fact, you can not stop there. And if now we have combined the two approaches, the two components of a common structure, then we can aim for more. Combine both the three components and the four - just continue to combine this logical chain and “push through” the importance of errors to a level lower, given the criticality already there. This will allow us to increase the accuracy of solving the problem.
We give the floor to the leading developer of the AI MTS center Nikita Semenov.
Hello! As a preface, I want to quote the well-known scientists Jan Lekun, Joshua Benjio and Jeffrey Hinton - these are three pioneers of artificial intelligence who have recently received one of the most prestigious awards in the field of information technology - the Turing Award. In one of the issues of Nature magazine in 2015, they released a very interesting article “Deep learning”, in which there was an interesting phrase: “Deep learning came with the promise of its capability to deal with raw signals without the need for hand-crafted features”. It is difficult to correctly translate it, but the meaning is something like this: "Deep learning has come with the promise of the ability to cope with raw signals without the need for manual creation of signs." In my opinion, for developers this is the main motivator of all existing ones.
Classic approach
So, let's start with the classic approach. When we talk about understanding speaking with a machine, we mean that we have a certain person who wants to control some services with the help of his voice or feels the need for some system to respond to his voice commands with some logic.
How is this problem solved? In the classic version, a system is used, which, as mentioned above, consists of three large components: a speech recognition component, a component for understanding a natural language, and a component responsible for a certain business logic. It is clear that at first the user creates a certain sound signal, which falls on the speech recognition component and turns from sound to text. Then the text falls into the component of understanding the natural language, from which a certain semantic structure is pulled out, which is necessary for the component responsible for business logic.
What is a semantic structure? This is a kind of generalization / aggregation of several tasks into one - for ease of understanding. The structure includes three important parts: the classification of the domain (a certain definition of the topic), the classification of intent (understanding what needs to be done) and the allocation of named entities to fill out cards that are necessary for specific business tasks in the next stage. To understand what a semantic structure is, you can consider a simple example, which Google most often cites. We have a simple request: "Please play some song of some artist."
The domain and subject matter in this request is music; intent - play a song; attributes of the “play a song” card - what kind of song, what kind of artist. Such a structure is the result of understanding a natural language.
If we talk about solving a complex and multi-stage problem of understanding colloquial speech, then, as I said, it consists of two stages: the first is speech recognition, the second is understanding natural language. The classical approach involves a complete separation of these stages. As a first step, we have a certain model that receives an acoustic signal at the input, and at the output, using linguistic and acoustic models and a lexicon, determines the most probable verbal hypothesis from this acoustic signal. This is a completely probabilistic story - it can be decomposed according to the well-known Bayes formula and obtain a formula that allows you to write the likelihood function of the sample and use the maximum likelihood method. We have a conditional probability of the signal X subject to the word sequence W,
The first stage we went through - we got a verbal hypothesis from the sound signal. Next comes the second component, which takes this very verbal hypothesis and tries to pull out the semantic structure described above.
We have the probability of the semantic structure S provided the verbal sequence W is at the input.
What is the bad thing about the classical approach, consisting of these two elements / steps, which are taught separately (i.e. we first train the model of the first element, and then the model of the second)?
- The natural language comprehension component works with the high-level verbal hypotheses that ASR generates. This is a big problem because the first component (ASR itself) works with low-level raw data and generates a high-level verbal hypothesis, and the second component takes the hypothesis as input - not the raw data from the original source, but the hypothesis that the first model gives - and builds its hypothesis over the hypothesis of the first stage. This is a rather problematic story, because it becomes too "conditional."
- The next problem: we can’t make any connection between the importance of words that are necessary to build the very semantic structure and what the first component prefers when constructing our verbal hypothesis. That is, if you rephrase, we get that the hypothesis has already been built. It is built on the basis of three components, as I said: the acoustic part (that which came into the input and is somehow modeled), the language part (completely models any language engrams - the probability of speech) and the lexicon (pronunciation of words). These are three large parts that need to be combined and some hypothesis found in them. But there is no way to influence the choice of the same hypothesis so that this hypothesis is important for the next stage (which, in principle, lies in the point that they learn completely separately and do not affect each other in any way).
End2End approach
We understood what the classical approach is, what problems it has. Let's try to solve these problems using the End2End approach.
By End2End we mean a model that will combine the various components into a single component. We will model using models that consist of encoder-decoder architecture containing modules of attention (attention). Such architectures are often used in speech recognition problems and in tasks related to the processing of a natural language, in particular, machine translation.
There are four options for the implementation of such approaches that could solve the problem posed before us by the classical approach: these are direct, collaborative, multi-stage and multi-tasking models.
Direct model
The direct model takes on the input low-level raw attributes, i.e. low-level audio signal, and at the output we immediately get a semantic structure. That is, we get one module - the input of the first module from the classical approach and the output of the second module from the same classical approach. Just such a "black box". From here there are some pluses and some minuses. The model does not learn to fully transcribe the input signal - this is a clear plus, because we do not need to collect large, large markup, we do not need to collect a lot of audio signal, and then give it to the accessors for markup. We just need this audio signal and the corresponding semantic structure. And that’s all. This many times reduces the labor involved in marking up data. Probably the biggest minus of this approach is that the task is too complicated for such a "black box", who is trying to solve immediately, conditionally, two tasks. First, inside himself, he tries to build some kind of transcription, and then from this transcription reveal the very semantic structure. This raises a rather difficult task - to learn to ignore parts of transcription. And it is very difficult. This factor is a rather large and colossal minus of this approach.
If we talk about probabilities, then this model solves the problem of finding the most probable semantic structure S from the acoustic signal X with model parameters θ.
Joint model
What is the alternative? This is a collaborative model. That is, some model is very similar to a straight line, but with one exception: the output for us already consists of verbal sequences and a semantic structure is simply concatenated to them. That is, at the input we have a sound signal and a neural network model, which at the output already gives both verbal transcription and semantic structure.
From the pros: we still have a simple encoder, a simple decoder. Learning is facilitated because the model does not try to solve two problems at once, as in the case of the direct model. One more advantage is that this dependence of the semantic structure on low-level sound attributes is still present. Because, again, one encoder, one decoder. And, accordingly, one of the pluses can be noted that there is a dependence in predicting this very semantic structure and its influence directly on transcription itself - which did not suit us in the classical approach.
Again, we need to find the most probable sequence of words W and the corresponding semantic structures S from the acoustic signal X with parameters θ.
Multitasking model
The next approach is a multi-tasking model. Again, the encoder-decoder approach, but with one exception.
For each task, that is, to create a verbal sequence, to create a semantic structure, we have our own decoder that uses one common hidden representation that generates a single encoder. A very famous trick in machine learning, very often used in work. Solving two different problems at once helps to look for dependencies in the source data much better. And as a consequence of this - the best generalizing ability, since the optimal parameter is selected for several tasks at once. This approach is most suitable for tasks with less data. And decoders use one hidden vector space into which their encoder creates.
It is important to note that already in probability there is a dependence on the parameters of the encoder and decoder models. And these parameters are important.
Multi-stage model
We turn, in my opinion, to the most interesting approach: a multi-stage model. If you look very carefully, you can see that in fact this is the same two-component classical approach with one exception.
Here it is possible to establish a connection between the modules and make them single-module. Therefore, the semantic structure is considered conditionally dependent on transcription. There are two options for working with this model. We can individually train these two mini-blocks: the first and second encoder-decoder. Or combine them and train both tasks at the same time.
In the first case, the parameters for the two tasks are not related (we can train using different data). Suppose we have a large body of sound and the corresponding verbal sequences and transcriptions. We “drive” them, we train only the first part. We get in a good transcription simulation. Then we take the second part, we train on another case. We connect and get a solution that in this approach is 100% consistent with the classical approach, because we separately took and trained the first part and separately the second. And then we train the connected model on the case, which already contains triads of data: an audio signal, the corresponding transcription and the corresponding semantic structure. If we have such a case, we can retrain the model, individually trained on large buildings, for our specific small task and get the maximum gain in accuracy in such a tricky way. This approach allows us to take into account the importance of different parts of transcription and their influence on the prediction of semantic structure usingaccounting errors of the second stage in the first.
It is important to note that the final task is very similar to the classical approach with only one big difference: the second term of our function - the logarithm of the probability of the semantic structure - provided that the input acoustic signal X also depends on the parameters of the model of the first stage .
It is also important to note here that the second component depends on the parameters of the first and second models.
Methodology for assessing the accuracy of approaches
Now it’s worth deciding on the methodology for assessing accuracy. How, in fact, to measure this accuracy in order to take into account features that do not suit us in the classical approach? There are classic labels for these separate tasks. To evaluate speech recognition components, we can take the classic WER metric. This is a Word Error Rate. We consider, according to a not very complicated formula, the number of inserts, substitutions, permutations of the word and divide them by the number of all words. And we get a certain estimated characteristic of the quality of our recognition. For a semantic structure, componentwise, we can simply consider F1 score. This is also some classic metric for the classification problem. Here everything plus or minus is clear. There is fullness, there is accuracy. And this is just a harmonic mean between them.
But the question arises how to measure accuracy when the input transcription and the output argument do not match or when the output is audio data. Google has proposed a metric that will take into account the importance of predicting the first component of speech recognition by assessing the effect of this recognition on the second component itself. They called it Arg WER, that is, it weighs WER over the semantic structure entities.
Take the request: "Set the alarm for 5 hours." This semantic structure contains an argument such as “five hours”, an argument of the type “date time”. It is important to understand that if the speech recognition component produces this argument, then the error metric of this argument, that is, WER, is 0%. If this value does not correspond to five hours, then the metric has 100% WER. Thus, we simply consider the weighted average value for all the arguments and, in general, get a certain aggregated metric that estimates the importance of transcription errors that create the speech recognition component.
Let me give you an example of Google’s experiments that it conducted in one of its studies on this topic. They used data from five domains, five subjects: Media, Media_Control, Productivity, Delight, None - with the corresponding distribution of data on training test data sets. It is important to note that all models were trained from scratch. Cross_entropy was used, the beam search parameter was 8, the optimizer they used, of course, Adam. Considered, of course, on a large cloud of their TPU. What is the result? These are interesting numbers:
For understanding, Baseline is a classic approach that consists of two components, as we said at the very beginning. The following are examples of direct, connected, multitask, and multi-stage models.
How much are two multi-stage models? Just at the junction of the first and second parts, different layers were used. In the first case, this is ArgMax, in the second case, SampedSoftmax.
What you should pay attention to? The classical approach loses in all three metrics, which are an estimate of the direct collaboration of these two components. Yes, we are not interested in how well transcription is done there, we are only interested in how well the element that predicts the semantic structure works. It is evaluated by three metrics: F1 - by topic, F1 - by intent and ArgWer metric, which is considered by the arguments of entities. F1 is considered a weighted average between accuracy and completeness. That is, the standard is 100. ArgWer, on the contrary, is not a success, it is an error, that is, here the standard is 0.
It is worth noting that our coupled and multi-tasking models completely outperform all classification models for topics and intentions. And the model, which is multi-stage, has a very large increase in total ArgWer. Why is it important? Because in the tasks associated with understanding colloquial speech, the final action that will be performed in the component responsible for business logic is important. It does not directly depend on the transcriptions created by ASR, but on the quality of the ASR and NLU components working together. Therefore, a difference of almost three points in the argWER metric is a very cool indicator, which indicates the success of this approach. It is also worth noting that all approaches have comparable values by definition of topics and intentions.
I will give a couple of examples of the use of such algorithms for understanding conversational speech. Google, when talking about the tasks of understanding conversational speech, primarily notes the human-computer interfaces, that is, these are all sorts of virtual assistants such as Google Assistant, Apple Siri, Amazon Alexa, and so on. As a second example, it is worth mentioning such a task pool as Interactive Voice Response. That is, this is a certain story that is engaged in the automation of call centers.
So, we examined approaches with the possibility of using joint optimization, which helps the model focus on errors that are more important for SLUs. This approach to the task of understanding the spoken language greatly simplifies the overall complexity.
We have the opportunity to make a logical conclusion, that is, to obtain some kind of result, without the need for such additional resources as the lexicon, language models, analyzers, and so on (i.e. these are all factors that are inherent in the classical approach). The task is solved “directly”.
In fact, you can not stop there. And if now we have combined the two approaches, the two components of a common structure, then we can aim for more. Combine both the three components and the four - just continue to combine this logical chain and “push through” the importance of errors to a level lower, given the criticality already there. This will allow us to increase the accuracy of solving the problem.