How neural network graphics helped
In 1943, American neuropsychologists McCallock and Pitts developed a computer model of a neural network, and in 1958 the first working single-layer network recognized some letters. Now, neural networks are just not used for what: to predict the exchange rate, diagnose diseases, autopilots and build graphics in computer games. Just about the last and talk.
Evgeny Tumanov works as a Deep Learning Engineer at NVIDIA. Based on the results of his speech at the HighLoad ++ conference, we prepared a story about the use of Machine Learning and Deep Learning in graphics. Machine learning does not end with NLP, Computer Vision, recommendation systems, and search tasks. Even if you are not very familiar with this area, you can apply the best practices from the article in your field or industry.
The story will consist of three parts. We will review the tasks in the graph that are solved with the help of machine learning, get the main idea, and describe the case of applying this idea in a specific task, and specifically in the rendering of clouds .
Let's analyze two groups of tasks. To begin with, we briefly denote them.
Real-World or render engine :
The second group of tasks is now conventionally called the " Heavy algorithm ". We include such tasks as rendering complex objects, such as clouds, and physical simulations : water, smoke.
Our goal is to understand the fundamental difference between the two groups. Let's consider the tasks in more detail.
Creation of believable animations: locomotion, facial animation
In the last few years, many articles have appeared , where researchers offer new ways to generate beautiful animations. Using the work of artists is expensive, and replacing them with an algorithm would be very beneficial for everyone. A year ago, at NVIDIA, we were working on a project in which we were engaged in facial animation of characters in games: synchronizing the hero's face with the audio track of speech. We tried to “revive” the face so that every point on it moved, and above all the lips, because this is the most difficult moment in the animation. Manually an artist to do this expensively and for a long time. What are the options to solve this problem and make a dataset for it ?
The first option is to identify vowels: the mouth opens on vowels, the vowels closes. This is a simple algorithm, but too simple. In games, we want more quality. The second option is to get people to read different texts and write down their faces, and then compare the letters that they pronounce with facial expressions. This is a good idea, and we did so in a joint project with Remedy Entertainment . The only difference is that in the game we are not showing a video, but a 3D model of dots. To assemble a dataset, you need to understand how specific points on the face move. We took actors, asked to read texts with different intonations, shot on very good cameras from different angles, after which we restored the 3D model of faces on each frame, and predicted the position of the points on the face by sound.
Render Image Post-Processing: supersampling, anti-aliasing
Consider a case from a specific game: we have an engine that generates images in different resolutions. We want to render the image in a resolution of 1000 × 500 pixels, and show the player 2000 × 1000 - this will be prettier. How to assemble a dataset for this task?
First render the image in high resolution, then lower the quality, and then try to train the system to convert the image from low resolution to high resolution.
Slowmotion: frame interpolation
We have a video, and we want the network to add frames in the middle - to interpolate frames. The idea is obvious - to shoot a real video with a large number of frames, remove intermediate ones and try to predict what was removed by the network.
Material Generation
We will not dwell much on the generation of materials. Its essence is that we take, for example, a piece of wood at several angles of illumination, and interpolate the view from other angles.
We examined the first group of problems. The second is fundamentally different. We will talk about the rendering of complex objects, such as clouds, later, but now we will deal with physical simulations.
Physical simulations of water and smoke
Imagine a pool in which moving solid objects are located. We want to predict the movement of fluid particles. There are particles in the pool at time t , and at time t + Δt we want to get their position. For each particle, we call a neural network and get an answer where it will be on the next frame.
To solve the problem, we use the Navier-Stokes equation , which describes the motion of a fluid. For a plausible, physically correct simulation of water, we will have to solve the equation or approximation to it. This can be done in a computational way, of which many have been invented over the past 50 years: the SPH, FLIP, or Position Based Fluid algorithm.
The difference between the first group of tasks from the second
In the first group, the teacher for the algorithm is something above: a recording from real life, as in the case of individuals, or something from the engine, for example, rendering pictures. In the second group of problems, we use the method of computational mathematics. From this thematic division, an idea grows.
main idea
We have a computationally complex task that is long, hard and hard to solve by the classical computing university method. To solve it and accelerate, perhaps even losing a little in quality, we need:
This is a general methodology and the main idea is a recipe on how to find application for machine learning. What should you do to make this idea useful? There is no exact answer - use creativity, look at your work and find it. I do graphics, and am not so familiar with other fields, but I can imagine that in the academic environment - in physics, chemistry, robotics - you can definitely find application. If you solve a complex physical equation in your workplace, then you may also find application for this idea. For clarity, consider a specific case.
Cloud rendering task
We were engaged in this project at NVIDIA six months ago: the task is to draw a physically correct cloud, which is represented as the density of liquid droplets in space.
It will not be possible to impose a texture and render on the cloud, because water droplets are difficult geometrically located in 3d space and are complex in themselves: they practically do not absorb color, but reflect it, anisotropically - in all directions in different ways.
If you look at a drop of water, which the sun shines on, and the vectors from the eye and the sun on a drop are parallel, then a large peak of light intensity will be observed. This explains the physical phenomenon that everyone has seen: in sunny weather, one of the borders of the cloud is very bright, almost white. We are looking at the border of the cloud, and the line of sight and the vector from this border to the sun are almost parallel.

The cloud is a physically complex object and its rendering by the classical algorithm requires a lot of time. We will talk about the classical algorithm a bit later. Depending on the parameters, the process can take hours or even days. Imagine that you are an artist and draw a film with special effects. You have a complicated scene with different lighting that you want to play with. We drew one cloud topology - I don’t like it, and you want to redraw it and get an answer right there. It is important to get an answer from one parameter change as quickly as possible. This is problem. Therefore, let's try to speed up this process.
Classic solution
To solve the problem, you need to solve this complicated equation.

The equation is harsh, but let's understand its physical meaning. Consider a beam pierced by a cloud piercing a cloud. How does light enter the camera in this direction? Firstly, the light can reach the point of exit of the ray from the cloud, and then propagate along this ray inside the cloud.
For the second method of "light propagation along the direction" is the integral term of the equation. Its physical meaning is as follows.
Consider the segment inside the cloud on the ray - from the entry point to the exit point. Integration is carried out precisely over this segment, and for each point on it we consider the so-called Indirect light energy L (x, ω) - the meaning of the integral I 1 - indirect lighting at a point. It appears due to the fact that drops in different ways reflect sunlight. Accordingly, a huge amount of mediated rays from surrounding droplets comes to the point. I 1 is the integral over the sphere that surrounds a point on the ray. In the classical algorithm, it is counted using the Monte Carlo method . The classic algorithm.
How to consider the Monte Carlo estimate I 1 we will not analyze, because it is difficult and not so important. Suffice it to say that this is the longest and most difficult part in the whole algorithm.
We connect neural networks
From the main idea and description of the classical algorithm, there follows a recipe on how to apply neural networks to this task. The hardest thing is to calculate the Monte Carlo score. It gives a number that means indirect lighting at a point, and this is exactly what we want to predict.

We have decided on the exit, now we will understand the entrance - from which information it will be clear what is the magnitude of the indirect light at the point. This is light that is reflected from the many droplets of water that surround the point. The light topology is strongly influenced by the density topology around the point, the direction to the source and the direction to the camera.
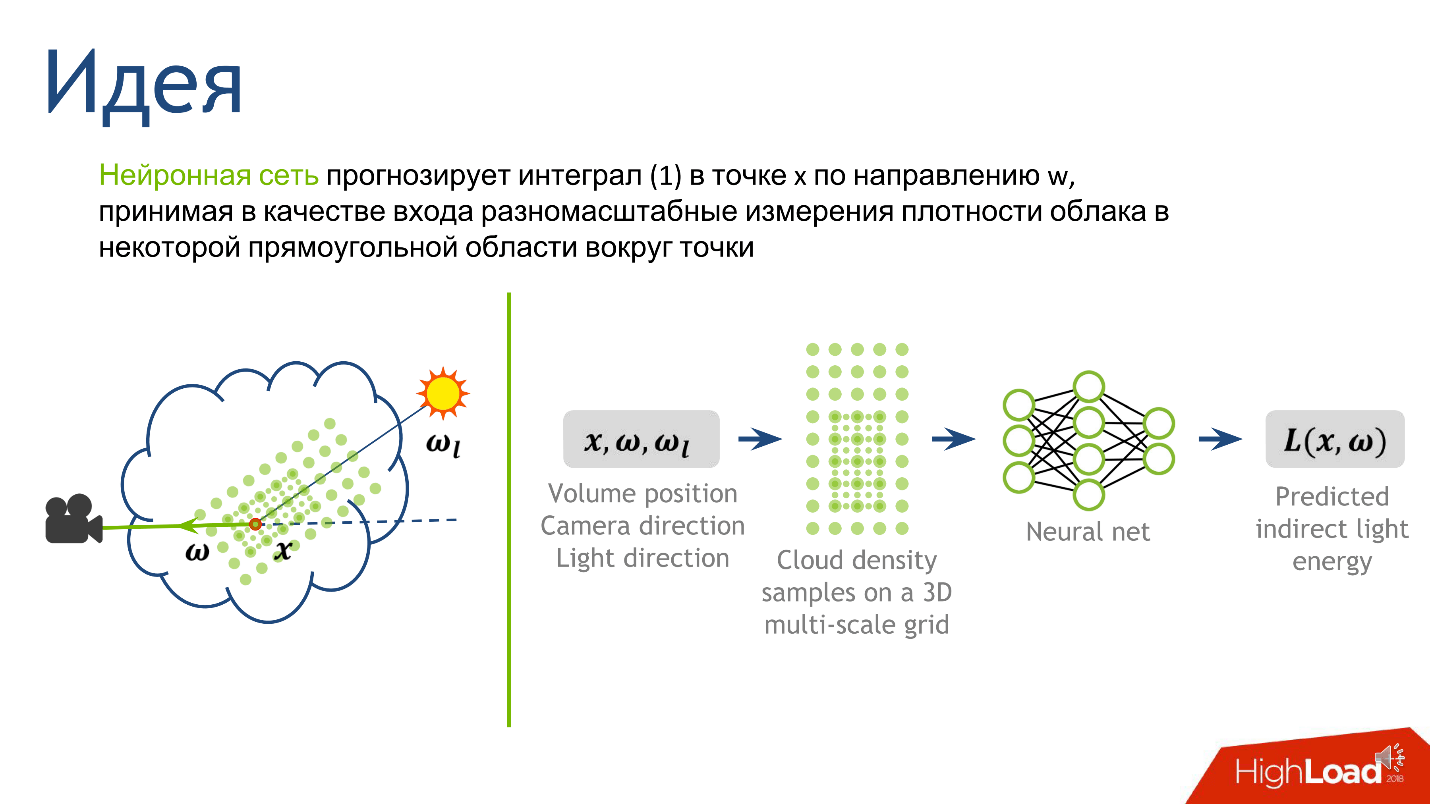
To construct the entrance to the neural network, we describe the local density. This can be done in many ways, but we focused on the article.Deep Scattering: Rendering Atmospheric Clouds with Radiance Predicting Neural Networks, Kallwcit et al. 2017 and many ideas came from there.
Briefly, the method of local representation of density around a point looks like this.
This approach gives us the most detailed description of a small area - the closer to the point, the more detailed the description. Decided on the output and input of the network, it remains to understand how to train it.
Training
We will generate 100 different clouds with different topologies. We will simply render them using the classical algorithm, write down what the algorithm receives in the very line where it performs Monte Carlo integration, and write down properties that correspond to the point. So we get a dataset on which to learn.

What to teach, or network architecture
Network architecture for this task is not the most crucial moment, and if you do not understand anything - do not worry - this is not the most important thing I wanted to convey. We used the following architecture: for each point there are 10 tensors, each of which is calculated on an increasingly large-scale grid. Each of these tensors falls into the corresponding block.
A fully connected layer without activation is just multiplication by a matrix. To the result of multiplying by the matrix we add the output from the previous residual-block , and only then apply activation.
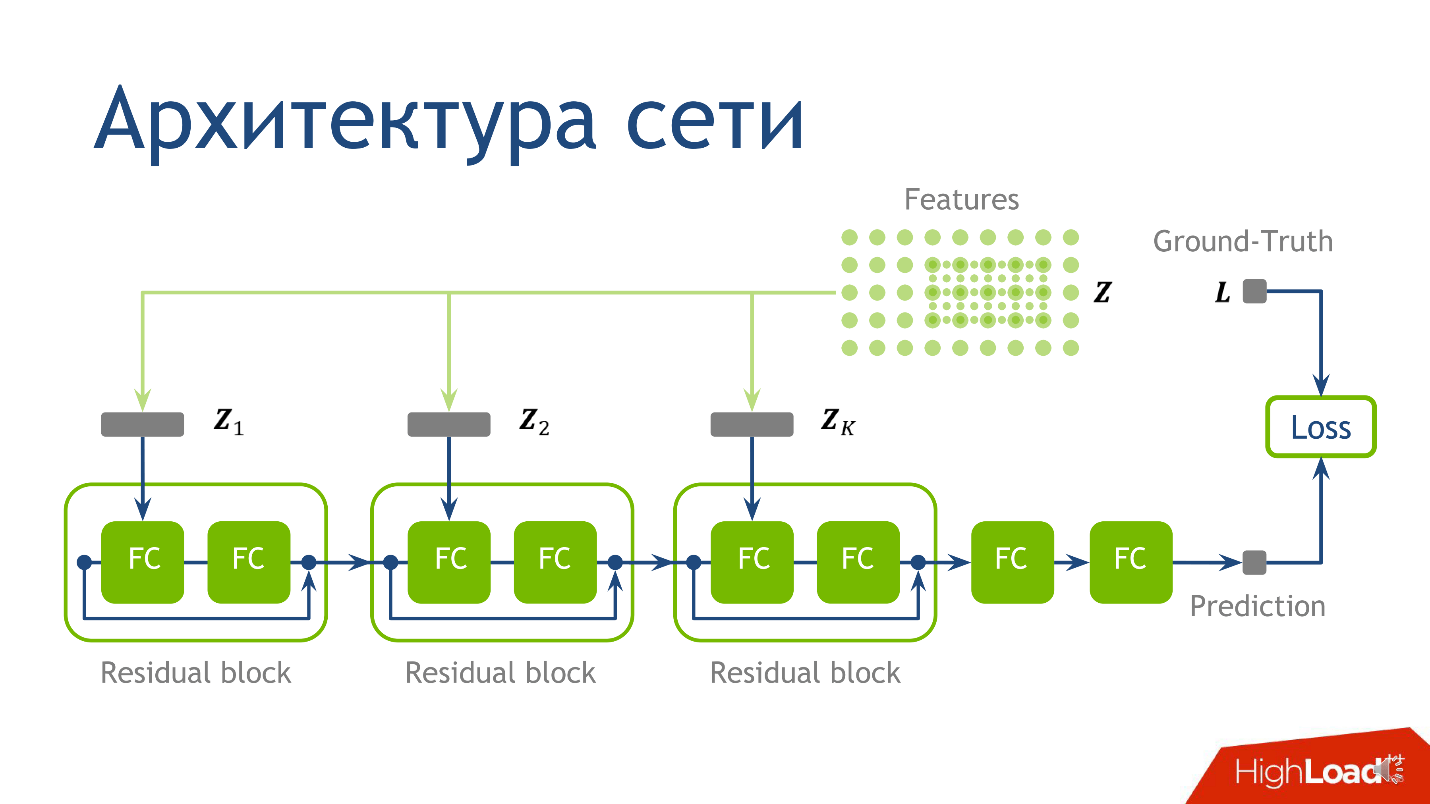
We take a point, count the values on each of the grids, put the obtained tensors in the corresponding residual block - and you can conduct inference of the neural network - production-mode of the network. We did this and made sure that we get pictures of clouds.
results
The first observation - we got what we wanted: a neural network call, compared to the Monte Carlo estimation, works faster, which is already good.
But there is another observation on the results of training - it is convergence in the number of samples. What is it about?

When rendering a picture, let's cut it into small tiles - squares of pixels, say 16 * 16. Consider one image tile without loss of generality. When we render this tile, for each pixel from the camera we release a lot of rays corresponding to one pixel, and add a little bit of noise to the rays so that they are slightly different. These rays are called anti-aliasing and are invented to reduce noise in the final image.
There are still samples that correspond to the connection with the light sources. They appear when we connect a point with a light source, for example, with the sun. This is easy to do, because the sun is the rays falling on the earth parallel to each other. For example, the sky, as a light source, is much more complicated, because it appears as an infinitely distant sphere, which has a color function in the direction. If the vector looks straight vertically into the sky, then the color is blue. The lower the brighter. At the bottom of the sphere is usually a neutral color imitating the earth: green, brown.
When we connect a point with the sky to understand how much light comes into it, we always release a few rays to get an answer that converges to the truth. We release more than one ray to get a better grade. Therefore for the wholepipeline rendering needs so many samples.
When we trained the neural network, we noticed that it learns a much more average solution. If we fix the number of samples, we see that the classical algorithm converges to the left row of the picture column, and the network learns to the right. This does not mean that the original method is bad - we just converge faster. When we increase the number of samples, the original method will be closer and closer to what we get.
Our main result that we wanted to get is an increase in rendering speed. For a specific cloud in a specific resolution with sample parameters, we see that the pictures obtained by the network and the classical method are almost identical, but we get the right picture 800 times faster.

Implementation
There is an Open Source program for 3D modeling - Blender , which implements the classic algorithm. We ourselves did not write an algorithm, but used this program: we trained in Blender, writing down everything that we needed for the algorithm. Production was also done in the program: we trained the network in TensorFlow , transferred it to C ++ using TensorRT, and we already integrated the TensorRT network into Blender, because its code is open.
Since we did everything for Blender, our solution has all the features of the program: we can render any kind of scene and a lot of clouds. The clouds in our solution are set by creating a cube, inside which we determine the density function in a specific way for 3D programs. We optimized this process - cache density. If a user wants to draw the same cloud on a pile of different setups of a scene: under different lighting conditions, with different objects on the stage, then he does not need to constantly recalculate the cloud density. What happened, you can watch the video .
Finally, I repeat once again the main idea that I wanted to convey:if in your work you think something long and hard as a specific computational algorithm, and this does not suit you - find the hardest place in the code, replace it with a neural network, and perhaps this will help you.
Evgeny Tumanov works as a Deep Learning Engineer at NVIDIA. Based on the results of his speech at the HighLoad ++ conference, we prepared a story about the use of Machine Learning and Deep Learning in graphics. Machine learning does not end with NLP, Computer Vision, recommendation systems, and search tasks. Even if you are not very familiar with this area, you can apply the best practices from the article in your field or industry.
The story will consist of three parts. We will review the tasks in the graph that are solved with the help of machine learning, get the main idea, and describe the case of applying this idea in a specific task, and specifically in the rendering of clouds .
Supervised DL / ML in graphics, or teacher training in graphics
Let's analyze two groups of tasks. To begin with, we briefly denote them.
Real-World or render engine :
- Creation of believable animations: locomotion, facial animation.
- Post-processing rendered images: supersampling, anti-aliasing.
- Slowmotion: frame interpolation.
- Generation of materials.
The second group of tasks is now conventionally called the " Heavy algorithm ". We include such tasks as rendering complex objects, such as clouds, and physical simulations : water, smoke.
Our goal is to understand the fundamental difference between the two groups. Let's consider the tasks in more detail.
Creation of believable animations: locomotion, facial animation
In the last few years, many articles have appeared , where researchers offer new ways to generate beautiful animations. Using the work of artists is expensive, and replacing them with an algorithm would be very beneficial for everyone. A year ago, at NVIDIA, we were working on a project in which we were engaged in facial animation of characters in games: synchronizing the hero's face with the audio track of speech. We tried to “revive” the face so that every point on it moved, and above all the lips, because this is the most difficult moment in the animation. Manually an artist to do this expensively and for a long time. What are the options to solve this problem and make a dataset for it ?
The first option is to identify vowels: the mouth opens on vowels, the vowels closes. This is a simple algorithm, but too simple. In games, we want more quality. The second option is to get people to read different texts and write down their faces, and then compare the letters that they pronounce with facial expressions. This is a good idea, and we did so in a joint project with Remedy Entertainment . The only difference is that in the game we are not showing a video, but a 3D model of dots. To assemble a dataset, you need to understand how specific points on the face move. We took actors, asked to read texts with different intonations, shot on very good cameras from different angles, after which we restored the 3D model of faces on each frame, and predicted the position of the points on the face by sound.
Render Image Post-Processing: supersampling, anti-aliasing
Consider a case from a specific game: we have an engine that generates images in different resolutions. We want to render the image in a resolution of 1000 × 500 pixels, and show the player 2000 × 1000 - this will be prettier. How to assemble a dataset for this task?
First render the image in high resolution, then lower the quality, and then try to train the system to convert the image from low resolution to high resolution.
Slowmotion: frame interpolation
We have a video, and we want the network to add frames in the middle - to interpolate frames. The idea is obvious - to shoot a real video with a large number of frames, remove intermediate ones and try to predict what was removed by the network.
Material Generation
We will not dwell much on the generation of materials. Its essence is that we take, for example, a piece of wood at several angles of illumination, and interpolate the view from other angles.
We examined the first group of problems. The second is fundamentally different. We will talk about the rendering of complex objects, such as clouds, later, but now we will deal with physical simulations.
Physical simulations of water and smoke
Imagine a pool in which moving solid objects are located. We want to predict the movement of fluid particles. There are particles in the pool at time t , and at time t + Δt we want to get their position. For each particle, we call a neural network and get an answer where it will be on the next frame.
To solve the problem, we use the Navier-Stokes equation , which describes the motion of a fluid. For a plausible, physically correct simulation of water, we will have to solve the equation or approximation to it. This can be done in a computational way, of which many have been invented over the past 50 years: the SPH, FLIP, or Position Based Fluid algorithm.
The difference between the first group of tasks from the second
In the first group, the teacher for the algorithm is something above: a recording from real life, as in the case of individuals, or something from the engine, for example, rendering pictures. In the second group of problems, we use the method of computational mathematics. From this thematic division, an idea grows.
main idea
We have a computationally complex task that is long, hard and hard to solve by the classical computing university method. To solve it and accelerate, perhaps even losing a little in quality, we need:
- find the most time-consuming place in the task where the code lasts the longest;
- see what this line produces;
- try to predict the result of a line using a neural network or any other machine learning algorithm.
This is a general methodology and the main idea is a recipe on how to find application for machine learning. What should you do to make this idea useful? There is no exact answer - use creativity, look at your work and find it. I do graphics, and am not so familiar with other fields, but I can imagine that in the academic environment - in physics, chemistry, robotics - you can definitely find application. If you solve a complex physical equation in your workplace, then you may also find application for this idea. For clarity, consider a specific case.
Cloud rendering task
We were engaged in this project at NVIDIA six months ago: the task is to draw a physically correct cloud, which is represented as the density of liquid droplets in space.
A cloud is a physically complex object, a suspension of liquid droplets that cannot be modeled as a solid object.
It will not be possible to impose a texture and render on the cloud, because water droplets are difficult geometrically located in 3d space and are complex in themselves: they practically do not absorb color, but reflect it, anisotropically - in all directions in different ways.
If you look at a drop of water, which the sun shines on, and the vectors from the eye and the sun on a drop are parallel, then a large peak of light intensity will be observed. This explains the physical phenomenon that everyone has seen: in sunny weather, one of the borders of the cloud is very bright, almost white. We are looking at the border of the cloud, and the line of sight and the vector from this border to the sun are almost parallel.
The cloud is a physically complex object and its rendering by the classical algorithm requires a lot of time. We will talk about the classical algorithm a bit later. Depending on the parameters, the process can take hours or even days. Imagine that you are an artist and draw a film with special effects. You have a complicated scene with different lighting that you want to play with. We drew one cloud topology - I don’t like it, and you want to redraw it and get an answer right there. It is important to get an answer from one parameter change as quickly as possible. This is problem. Therefore, let's try to speed up this process.
Classic solution
To solve the problem, you need to solve this complicated equation.
The equation is harsh, but let's understand its physical meaning. Consider a beam pierced by a cloud piercing a cloud. How does light enter the camera in this direction? Firstly, the light can reach the point of exit of the ray from the cloud, and then propagate along this ray inside the cloud.
For the second method of "light propagation along the direction" is the integral term of the equation. Its physical meaning is as follows.
Consider the segment inside the cloud on the ray - from the entry point to the exit point. Integration is carried out precisely over this segment, and for each point on it we consider the so-called Indirect light energy L (x, ω) - the meaning of the integral I 1 - indirect lighting at a point. It appears due to the fact that drops in different ways reflect sunlight. Accordingly, a huge amount of mediated rays from surrounding droplets comes to the point. I 1 is the integral over the sphere that surrounds a point on the ray. In the classical algorithm, it is counted using the Monte Carlo method . The classic algorithm.
- Render a picture from pixels, and produce a ray that goes from the center of the camera to a pixel and then further.
- We cross the beam with the cloud, we find the entry and exit points.
- We consider the last term of the equation: to cross, connect with the sun.
- Getting started importance sampling
How to consider the Monte Carlo estimate I 1 we will not analyze, because it is difficult and not so important. Suffice it to say that this is the longest and most difficult part in the whole algorithm.
We connect neural networks
From the main idea and description of the classical algorithm, there follows a recipe on how to apply neural networks to this task. The hardest thing is to calculate the Monte Carlo score. It gives a number that means indirect lighting at a point, and this is exactly what we want to predict.
We have decided on the exit, now we will understand the entrance - from which information it will be clear what is the magnitude of the indirect light at the point. This is light that is reflected from the many droplets of water that surround the point. The light topology is strongly influenced by the density topology around the point, the direction to the source and the direction to the camera.
To construct the entrance to the neural network, we describe the local density. This can be done in many ways, but we focused on the article.Deep Scattering: Rendering Atmospheric Clouds with Radiance Predicting Neural Networks, Kallwcit et al. 2017 and many ideas came from there.
Briefly, the method of local representation of density around a point looks like this.
- Fix a fairly small constant . Let it be the mean free path in the cloud.
- Draw around a point on our segment a volumetric rectangular grid of a fixed size , say 5 * 5 * 9. At the center of this cube will be our point. The grid spacing is a small fixed constant. At the grid nodes we will measure the density of the cloud.
- Let's increase the constant by 2 times , draw a bigger grid, and do the same - measure the density at the nodes of the grid.
- Repeat the previous step several times . We did this 10 times, and after the procedure we got 10 grids - 10 tensors, each of which stores the cloud density, and each of the tensors covers an increasingly large neighborhood around the point.
This approach gives us the most detailed description of a small area - the closer to the point, the more detailed the description. Decided on the output and input of the network, it remains to understand how to train it.
Training
We will generate 100 different clouds with different topologies. We will simply render them using the classical algorithm, write down what the algorithm receives in the very line where it performs Monte Carlo integration, and write down properties that correspond to the point. So we get a dataset on which to learn.
What to teach, or network architecture
Network architecture for this task is not the most crucial moment, and if you do not understand anything - do not worry - this is not the most important thing I wanted to convey. We used the following architecture: for each point there are 10 tensors, each of which is calculated on an increasingly large-scale grid. Each of these tensors falls into the corresponding block.
- First into the first regular fully connected layer .
- After exiting the first fully connected layer, in the second fully connected layer, which does not have activation.
A fully connected layer without activation is just multiplication by a matrix. To the result of multiplying by the matrix we add the output from the previous residual-block , and only then apply activation.
We take a point, count the values on each of the grids, put the obtained tensors in the corresponding residual block - and you can conduct inference of the neural network - production-mode of the network. We did this and made sure that we get pictures of clouds.
results
The first observation - we got what we wanted: a neural network call, compared to the Monte Carlo estimation, works faster, which is already good.
But there is another observation on the results of training - it is convergence in the number of samples. What is it about?
When rendering a picture, let's cut it into small tiles - squares of pixels, say 16 * 16. Consider one image tile without loss of generality. When we render this tile, for each pixel from the camera we release a lot of rays corresponding to one pixel, and add a little bit of noise to the rays so that they are slightly different. These rays are called anti-aliasing and are invented to reduce noise in the final image.
- We release several anti-aliasing rays for each pixel.
- On the inside of the beam from the camera, in the cloud, on a segment, we calculate n samples of points at which we want to conduct a Monte Carlo assessment, or call a network for them.
There are still samples that correspond to the connection with the light sources. They appear when we connect a point with a light source, for example, with the sun. This is easy to do, because the sun is the rays falling on the earth parallel to each other. For example, the sky, as a light source, is much more complicated, because it appears as an infinitely distant sphere, which has a color function in the direction. If the vector looks straight vertically into the sky, then the color is blue. The lower the brighter. At the bottom of the sphere is usually a neutral color imitating the earth: green, brown.
When we connect a point with the sky to understand how much light comes into it, we always release a few rays to get an answer that converges to the truth. We release more than one ray to get a better grade. Therefore for the wholepipeline rendering needs so many samples.
When we trained the neural network, we noticed that it learns a much more average solution. If we fix the number of samples, we see that the classical algorithm converges to the left row of the picture column, and the network learns to the right. This does not mean that the original method is bad - we just converge faster. When we increase the number of samples, the original method will be closer and closer to what we get.
Our main result that we wanted to get is an increase in rendering speed. For a specific cloud in a specific resolution with sample parameters, we see that the pictures obtained by the network and the classical method are almost identical, but we get the right picture 800 times faster.
Implementation
There is an Open Source program for 3D modeling - Blender , which implements the classic algorithm. We ourselves did not write an algorithm, but used this program: we trained in Blender, writing down everything that we needed for the algorithm. Production was also done in the program: we trained the network in TensorFlow , transferred it to C ++ using TensorRT, and we already integrated the TensorRT network into Blender, because its code is open.
Since we did everything for Blender, our solution has all the features of the program: we can render any kind of scene and a lot of clouds. The clouds in our solution are set by creating a cube, inside which we determine the density function in a specific way for 3D programs. We optimized this process - cache density. If a user wants to draw the same cloud on a pile of different setups of a scene: under different lighting conditions, with different objects on the stage, then he does not need to constantly recalculate the cloud density. What happened, you can watch the video .
Finally, I repeat once again the main idea that I wanted to convey:if in your work you think something long and hard as a specific computational algorithm, and this does not suit you - find the hardest place in the code, replace it with a neural network, and perhaps this will help you.
Neural networks and artificial intelligence are one of the new topics that we will discuss at Saint HighLoad ++ 2019 in April. We have already received several applications on this topic, and if you have a cool experience, not necessarily on neural networks, submit an application for a report before March 1 . We will be glad to see you among our speakers.
To keep abreast of how the program is formed and what reports are accepted, subscribe to the newsletter . In it, we only publish thematic collections of reports, article digests and new videos.