Project generator
This article will focus on a specific software product designed for the development of large software and information systems. This product is called “Project Generator”, and it is based on the instrumental approach to programming, when the process of developing software systems is considered as an object of automation. This topic was quite fashionable somewhere in the 70-80s of the last century, but in our opinion, this approach is not outdated today. At least, our creative team for many years managed to develop industrial automated systems for various purposes using their own tools .
In the following sections of the article, we will consider some technical aspects of our approach to instrumental support for the development of large software and information systems, taking into account the historical development of our own views on this issue. For the part of the audience that our “self-digging” will find it overly zealous, we suggest immediately proceeding to the “Current Situation” section, where, in summing up all the material, we will try to articulate as clearly as possible what we are proposing to evaluate and discuss to a wide community of developers.
The project generator was laid down more than a quarter of a century ago, when the development team was forced, for well-known reasons, to complete work on projects in aviation design bureaus and begin to look for the application of the acquired experience in other areas.
Working on several projects in the banking sector, it turned out that we had to write several systems consisting of many similar elements that differ only in the composition of the parameters. The systems being developed were built on the then still new technology of a two-level client-server: workstation - server - database. Each element of the system at the client workstation in general implemented a screen with a data entry form, several tables and several buttons or menu items to perform certain actions and, possibly, switch to another screen. In the client-server protocol, it was necessary to program the transmission of the corresponding data and the reception of the server response. The server provided for the procedure for obtaining query parameters, their analysis, performing the required queries to the database, transmitting the results in the form of a response to a client’s request.
Thus, the work was carried out as if in two dimensions. One of them is the development of new such fragments, which we called procedures. New procedures appeared during the development, as well as during the refinement of the problem. Old procedures were modified.
Here, the word “procedure” is not used in the sense, for example, of Pascal, i.e. something like a subroutine, function, etc. Rather, it is a kind of program code template.
The second dimension is the technology itself for implementing the procedures. The protocol was changed, various security subsystems were connected, which led to the need to change the program code of all previously implemented procedures at once, both in client and server programs.
In addition, with a large number of procedures, it became a problem to maintain the integrity of the project in terms of compliance of client and server programs with the protocol of their interaction. For example, if a new parameter was added in a request, the corresponding edits must be performed consistently in two different programs - in the client and in the server.
In connection with the foregoing, an idea arose to automate this process. By that time, we had experience implementing syntactic analysis programs for complex languages (the Fakir conceptual programming system with a hierarchical description of algebraic models, analytical formula calculations, and other irrelevant tasks now).
As a result, a project description language was developed consisting of a heading with various project parameters and a set of procedure descriptions. Each procedure had a unique name, a list of input parameters, a list of requests to the server with a specification of input and output parameters and the type of response — a table or one set, as well as a list of the provided actions that can be performed in the context of this procedure.
The named data types used in the procedures were specified as part of the project in its description. The description was naturally controlled for the correspondence of different components in composition to types.
Such a description was fed to the input of the project generator, which built the project model in memory, its analysis for integrity. Further, on the basis of the model, the texts of programs that implement client and server program modules were generated.
Client programs in the simplest case were generated in a finished form, but in special cases it was possible to order manual software inserts to perform special actions not provided for in the described simple project model.
The project programs themselves were implemented in C language. The server in those days was on the VAX VMS platform, client programs on the IBM PC running MS DOS (but were also provided on the VAX VMS). Server queries were written on a preprocessor over C, which understood SQL queries embedded in the text of a C program.
The project description also included a description of the database tables in terms of the types described. This allowed in the project description to formulate simplified queries to the database on a subset of the SQL language with their full parsing for compliance with a given database schema. More complex queries were implemented in server programs using preprocessor tools.
The described technology has taken root and has stood the test of time for a decade. With its help, a fair number of projects in various fields were done.
The project model was improved, complicated. Software and hardware platforms were changing. Clients and servers began to function in MS Windows and Linux.
The development in the above two dimensions made it possible to separate the work of analysts from the work of system programmers. The analyst focused on applied tasks, and the system programmer on operating systems, protocols, languages, etc.
The main advantage of this technology is a significant reduction in the code written by the system developer. The description of one procedure can take several tens of lines, and the generated C program code is usually an order of magnitude larger. Changing system software does not affect the code of the application developer, such changes are taken into account in new versions of the generator.
Using the project generator made it possible to implement complex large-scale projects with a minimum number of developers, often one person, and this was done by people who were not knowledgeable in the intricacies of programming, but who had mathematical training and experience in developing systems. Those. not a programmer, but an analyst could independently lay down a complex project and bring it to a working state without involving system programmers.
To ensure the convenience of development, various auxiliary functions for designing the project were constantly improved in the generator. In addition to the text of the programs, numerous batch files were generated to perform translation and assembly of all program components for different platforms. Generated database creation and modification utilities. The procedure for generating installation packages for transfer to the customer was automated.
A slight terminological confusion should be noted. The project description language described above was often designated as a non-procedural language, in the sense that it did not have program operators, as in C, Pascal, etc. And the procedures mentioned in the project language are completely different concepts.
As appetite increased during eating in the early 2000s, there was an understanding that it was necessary to improve the technology used to develop projects further.
Firstly, the framework of the project model itself, as a set of types, a database and a set of query procedures, has become tight.
Secondly, the use of the C language in server programs, and sometimes in client programs, has become tiring. Too low a level for the analyst is to delve into the details and subtleties of passing parameters, pointers, zero-bytes, etc.
On the other hand, projects have appeared in which it was necessary to write not simple queries to the database for the needs of banking accounting, but voluminous programs with complex data structures . In such projects, the effect of automatic generation of program text was reduced, since a lot of manual code had to be written.
With the transition to the window interface, an opportunity arose, and, as a consequence, the need to display in client programs not only tables with texts and numbers, but also all sorts of other content in the form of pictures, drawings.
In this regard, it was necessary to complicate the client-server interaction protocol. All this became an incentive to develop a completely new project generator.
The new development was based on the concept of a structural document. A document in the context of a project generator occupies one of the central concepts. At the conversational level, a document is a database of the network structure in the program memory.
The network structure of the document (database) assumes that tables are stored in it, between the lines of which one-to-many relationships are established. This is an old, forgotten concept of network structure databases that we used in long-standing designs.
The main idea was that the client program receives information from the server not in the form of several tuples and tables, but in the form of an arbitrary document fixed for this request structure. And, symmetrically, the client, fulfilling the request, also sends a document in general form.
Thus, the server must be able to read the input document from the protocol, restoring its structure in memory. Further, based on the received document, execute a certain program, now called business logic, in which interaction with a database (real, not in memory) is assumed. As a result, the program must generate an output document for transmission to the client program according to the protocol.
The client program should provide a program for generating the contents of the application window based on the received data.
The initial project assumed, like previous versions of the generator, the use of the C language for writing the bodies of server requests, as well as programs for creating the contents of the application window. As an experimental tool, a relatively simple programming language was developed, designed in simple cases to replace the C language. This language was part of the description language of the project as a whole and received the conventional name of the base language of the generator.
The basic concepts of a base language are listed below.
The description of the named data type is a string of a given fixed length, numbers of different digits, an enumerated type, a mask type (bitmask with named components), structure, and, finally, the document mentioned above.
A procedure (an analogue of a function in C) with parameters of the indicated types, including documents.
The main standard operators are assignment, conditional operator, for loop, while loop, procedure call, expressions. Everything is very similar to ordinary standard languages. For a document type, procedures for manipulating its components automatically become available.
The result was devastating - after some time in the current projects the share of C programs rapidly decreased to insignificant sizes. Somehow it turned out that the project developers began to write exclusively in this language, not only the project model, but all the programs both on the client and on the server.
The apotheosis of this unexpected process was the writing of the generator itself in its base language.
Initially, the structure of the generator assumed at the input a description of the project, a set of texts of manual programs in C, and a database preprocessor for C. The output is a set of resulting C programs and scripts for translating, assembling, distributing, and other useful actions.
The generator structure at this stage of development had the form in the figure below.

With the advent of the basic language, the structure of the generator became the following. Two components were distinguished in the generator: the C-code generator from the project model and the C-code generator from texts in the base language.
The project model contains high-level entities such as server, application, server port, security subsystem, application window type, dialog, and many other useful things. All these model entities in the process of generating the project generate the C programs that implement them.
The developer also writes his pieces of C-programs, which, according to certain rules, are included in the resulting set of C-programs of the project.
Now part of the manual C programs has become possible to replace with equivalent programs in the base language, which are more easily integrated with the project model.
Thus, with the advent of the basic language, the structure of the generator acquired the form depicted in the following figure.

In the process of developing the base language, the volume of input texts on it grew, and in C - decreased. And as the model description language develops, the amount of code in the base language also decreases, being replaced by short and succinct descriptions of model entities.
Due to the complexity of the model component of the project description, the idea arose to generate not the C-code from the model, but the code in the base language. This simplified the generator itself, since there was no need to monitor the intricacies of addressing in C for the implementation of model entities. The translator of the base language in C monitors all this.
As a result, the structure of the generator was as follows.
The base language is a part of the project description generator language that implements a universal programming language. The developer using the project generator has the ability to write regular programs in this language, but as part of a project.
Unlike C, there is no way to write and broadcast a separate program in the base language. Even if your program consists of several dozens of operators, you should still describe a project in which your program will be the only component, as a utility-type package - a console application.
In a more complex case, a program in the base language may consist of several packages.
A package is one of the basic concepts of a generator (and base) language. A package has a unique name within the project, is declared as a package of some type and, as a rule, is presented as a separate file with the package program text.
A project description is a project description file with a title and an ordered list of packages.
The generator contains a large set of so-called system packages of various types, which are written by the developers of the generator and can be used explicitly or implicitly through model entities in your projects. Developer packages do not have to match the names of system packages.
Here is an example of a simple project like “Hello world”. We will not consider the project directory structure here. In our case, we must create two files - a description of the project and a description of the utility as part of the project, having come up with names for them.
Let the project name be hello, the name of the utility in the project is world. Then we need to create two text files hello.gen and world.utility.
Hello.gen file:
World.utility file:
As a result of the generation and assembly of such a project, the executable module world.exe (for MS Window) or world (for Unix) will be obtained. At startup, the program prints the string “Hello world!” In the console.
Consider a more complex example, in which, in addition to the utility package, a simple package of type package is used.
Pkgexample.gen file:
Mypkg.package file:
Myutl.utility file:
In this case, as part of the project, we have two packages - the mypkg software package and the myutl utility.
In the mypkg package, in the section of external specifications (up to the implementation keyword), a description of the t_myint type is derived from the base int type (a 32-bit integer), and a specification of the sum procedure with two input parameters a, b of type t_myint and one output parameter with the same type.
Everything that is written after the implementaion keyword is available only inside the package.
The localsum procedure has a similar heading, like the external sum procedure, but begins with the keyword fproc, which means that it is a local object. After the heading, instead of a semicolon, there is a block of statements in curly brackets, very similar to that in C. Inside the block, there is one assignment operator. Unlike vulgar equality, the assignment here is given by the characters “: =”.
The generator’s developers, as people with a basic mathematical education, were pained to look at such constructions in C-like languages as a = a + 1. It was decided to use algal-pascal notation in such operators.
After the local localsum procedure, the body of the sum external procedure declared in the specifications section is located. The description of the previously specified procedure is similar to the description of the local procedure, but with the keyword fprocdecl and an exact copy of the parameters. Next is the body block of the procedure in which the local procedure call localsum is located.
Myutl still has a single main section with a statement block in curly braces. The main section in the utility must be in exactly one instance at the end of the package. This is an analogue of the main function in the C language. The statements of this block are executed when the utility starts.
There are three operators in the block. The first operator is a description of the three variables p, q, r, and the first two are initialized with constant expressions. Variable types are specified in the form of a package name followed by a dot followed by the type name defined in this package.
The second operator is a call to the sum procedure from the mypkg package, which, like the types, is specified with a point expression.
The third operator is debug printing to the console.
Such elaborate programming of calculating the sum of two integer constants was done solely to demonstrate as many possibilities of the base language as possible with the minimum size of the text presented to the public.
A more complex example demonstrates working with a document type.
File docexample.gen:
Doc.package file:
Doctest.utility file:
The docexample project contains two packages - doc.package and doctest.utility.
The doc package describes the character types t_orgname, t_addr, t_phone, t_empname in UTF-8 encoding with the specified lengths.
Type orgs - document (dqueue keyword). It describes two types of records org and emp - organization and employee. In parentheses are listed components of records of the indicated types. In essence, this is similar to the description of a database with two tables and the specified columns in them.
The network structure is defined by relationships between one-to-many records. Such relationships are introduced as sets. So, the org_emp set introduces a relationship between the organization and the employee, many employees can work in the organization, but each employee works in no more than one organization. The owner keyword sets the record owner type for the set. The member keyword sets a member type for a set.
A collection without an owner (in our case orgs_org) is called singular; it exists in a single copy in a document (its owner is conditionally the entire document / database).
The document-type declaration automatically declares the record-types of such a document with the names matching the names of the records. In doing so, keep in mind the uniqueness of type names within a package.
In addition, for each record and for each set, procedures for manipulating these objects are automatically generated and made available.
So, for an org record, an org_cre procedure is created with two parameters: a link to the document, an output variable of the record type to obtain a link to the created record instance.
An org_emp_ins procedure is created for the org_emp set with three parameters: a reference to an instance of type org — the owner records of the set, a reference to an instance of type emp — records of the set member, an integer — the position in the set (negative numbers — numbering from the end of the set).
An org_emp_mem procedure is also created for the org_emp set with three parameters: a reference to an instance of type org — the owner records of the set, an integer — a position in the set, and an output parameter — a link to an instance of type emp — records of a member.
For the org_emp set, an org_emp_next procedure is created with one parameter of type emp (input and output) to move to the next element in the set.
The multifunctional expressions isnull (...) and isnotnull (...) apply to variables such as document records.
This project uses the rand and rand_test system packages to generate random test data.
To demonstrate the power of parsing, consider another example project.
Calc.gen file:
Calc.utility file:
The development of a calculator utility is shown, at the input of which an expression is supplied, at the output, the calculated value of the expression.
Using the tlex parsing system package allows solving the task of parsing an expression in a very simple and minimal amount of code, using the wide built-in capabilities of this package. This example shows how easy and compact it is to solve parsing issues.
The project involves the tlex system package - lexical parsing in a string. Parsing is done using the recursive descent method. Each nonterminal symbol of a grammar corresponds to a procedure in a parsing program.
The grammar should be reduced to such a way that, according to the results of finding out which terminal symbol is located in the reading position, one can decide which grammar rule to use for parsing. Bringing it to this form is not difficult for most existing languages. To do this, it is enough to define a sublanguage that allows texts that are incorrect from the point of view of the initial grammar. In the future, based on the constructed parsing tree (in one form or another), one can check the correctness.
In fact, this is always done in real translators, since real programs are not described by context-free grammars. KS grammar can hardly describe a language in which the use of various objects (types, procedures, variables) without their description is prohibited. So this kind of check is done anyway.
In our case, the analysis is performed in the calc utility for the input parameter string of the program call in the console. If exactly one parameter is not specified, an error message is displayed. If the parameter is set, then it is parsed with the calculation of the result. Upon successful analysis, the result of the calculation is printed in the console. If an error occurs, a diagnostic message is issued with information in which position of the text the error was detected.
Grammar in words. An additive expression is a sequence of multiplicative expressions separated by operation signs + or -. A multiplicative expression is a sequence of factors separated by operation signs * or /. A multiplier is an additive expression in parentheses or a number.
The additive expression corresponds to the syn_add procedure, the multiplicative expression corresponds to syn_mul, and the multiplier corresponds to syn_fact.
Parameters of syntax procedures: buf - text to be analyzed, xlex - lexical analysis context (including reading position), dval - output parameter - calculated value.
Used lexical procedures of the tlex package.
Function tlex.sample - checks in the current position the presence of the sample presented in the parameter. If the pattern begins with a letter, then the recognized text must match the pattern as a whole, and not contain the pattern as a substring. Those. if we check for the availability of the proc sample, the procdecl text in the read position will not give an affirmative result. When recognizing any token, all space characters, line ends, tabs, etc. are skipped. Comments in the style of C and C ++ are also skipped.
Tlex.sample_err procedure - checks the tlex.sample procedure for the presence of a sample, in the absence initiates a fatal error with a message text containing information about the reading position of the analyzed string.
Such pairs of functions / procedures are present in the tlex package for many types of tokens. The function allows you to check for the presence of a token, the procedure checks and in the absence initiates an error.
Procedure tlex.double - checks at the current position for the presence of a decimal number in the form of 123.456. The NOSIGN parameter prohibits the + - sign at the vocabulary level; we recognize these characters at the grammar level. The NOFRAC parameter enables numbers with or without a decimal point.
The previous section provides sample projects that demonstrate some of the core language features. Note that this is not a reference, not a guide to the language, and not even a set of examples for training. This is just an introduction text.
If the reader gets to this place, he has a very logical question - what is in this basic language that which is not in other languages, and why did you need to spend energy and money for its implementation?
Firstly, the base language is part of a complete generator language describing projects. There are many different constructions in the generator language for describing model entities such as a database, sql query, server, server port, application, application screen layout, dialog, configuration file, json conversion for arbitrary data types, an abstract set of related tables for mappings in different environments (dom-model, gtk, qt), etc. This list is constantly updated, obsolete entities die off, new ones appear. And all these constructions are implemented mainly in the base language. In the early stages of generator development, model designs were implemented directly in C. Using the base language facilitated the integration of models and language.
Secondly, the generator is intended (and only then gives significant advantages) for the implementation of large projects, when the amount of program code is measured in hundreds of thousands of lines. Work with large projects is fundamentally different from the development of small programs up to several thousand lines in size. In a small program, a developer can keep in his head all the information about its structure. In a large program, this is not possible. In the process of modifying such programs, excess unused code will inevitably increase. To counter this process, the generator takes numerous measures and code checks.
In the headings of the procedures, formal parameters are specified as input, input and output, only output. During the translation of the body of the procedure, this specification is checked for correctness. For example, if a certain parameter is declared output, and in the body of the procedure there is a path in the operator tree in which the variable is used to read before it is assigned a value, then this situation leads to an error diagnosis. In this case, information on the inputs and outputs of other procedures called in this procedure is used. If the variable has the type of structure, then such an analysis is carried out for each of its components at any level.
For structural documents, you can order a complete set of all operations provided for all its records and sets. This will result in significant redundant code. It is possible (and necessary) to explicitly set the list of all required operations for each record and set. In this case, operations that were not used in the project will be identified and appropriate diagnostics will be issued. Moreover, if, for example, the operation of creating a record is not used, then this is also treated as an error. Or for a set there is an operation of inclusion in a set and no longer used, then an error is also generated.
At the time of writing this text, there was just a process of deleting some obsolete entities in the project model (old servers and applications are replaced by new ones). In the document representing the project model in the generator code at the time of the simultaneous existence of old and new objects, there were about 250 types of records and more than 800 types of sets. After deleting old entities, the number of records decreased to 190, sets to 580. It is clear that manually tracking the use of so many objects and operations with them is extremely difficult.
As an illustration, we present data on one real, but already completed, project in the field of financial activity. The project on the generator contained 1294 files in total 203829 lines. In the resulting C code, there were 4605 files with 2608812 lines. The project has 23 different types of servers, 29 ports through which they receive requests, 11 applications, 27 utilities (console programs), and this is only in one, but the largest project in the entire system. This system included 7 projects, interconnected by means of export-import of individual packages. The division of the system into 7 different generator projects was done to reduce their volume. Managing such an economy without paranoid means of integrity verification is very problematic.
The project generator throughout the entire time of working on it developed as an internal project in the development team. In the process of working on applied projects, our customers in some cases had the opportunity to use the generator for their own developments, one way or another connected with our project (and maybe not only, it is difficult to control). While working on projects, the statement of the problem was clarified, new needs for the tool arose, which were implemented in the next versions of the generator. As it was said at the beginning, it was development in two dimensions, applied and instrumental. Those. the generator developed along with the next (next) project. Periodically, there was talk about making the generator itself a software product for the general public.
Currently, the generator has tools for working with database management systems Oracle, Postgres, MySql, MS Sql, Sqlite of different versions. Working with databases involves describing the database schema using generator tools, writing sql queries in a special language (a fairly representative subset of sql is used) with full syntactic and semantic control of the query text in the database schema. There are tools for specifying alternatives for different types of databases. And you can write the so-called dynamic queries, which without control will be transferred to the database.
The servers are transferred to modern network tools - Epoll on Unix and I / O Completion on MS Windows.
Until recently, applications were developed using a single interface model (the so-called window layouts), which had two implementations - Microsoft WIN32 GUI and GTK-3 for Unix. Maintaining one model for these two systems has become increasingly difficult due to the underdeveloped tools in the WIN32 GUI. Therefore, two different approaches are currently being developed - GTK-3 and Qt-5. The models are different, but very similar. So far, no decision has been made to separate them, or try to combine them with individual exceptions in different implementations.
Actively developing the export of Java Script packages for use in WEB development. In the browser, you can receive data in the json format from the server and use the functions for manipulating the types described in the project, for example, with a structural document, generated for Java Script.
For WEB development, a fairly representative subset of the HTML language with inserts in the base language is implemented (similar to PHP). At the same time, HTML markup is monitored for the correctness of nesting tags. And, of course, the inserts in the base language are subject to total control, as is customary throughout the generator.
Implemented exporting packages to the Java language mainly for the development of component systems on mobile platforms (Android).
In the following sections of the article, we will consider some technical aspects of our approach to instrumental support for the development of large software and information systems, taking into account the historical development of our own views on this issue. For the part of the audience that our “self-digging” will find it overly zealous, we suggest immediately proceeding to the “Current Situation” section, where, in summing up all the material, we will try to articulate as clearly as possible what we are proposing to evaluate and discuss to a wide community of developers.
A historical excursion to understand the motivation of developers
The project generator was laid down more than a quarter of a century ago, when the development team was forced, for well-known reasons, to complete work on projects in aviation design bureaus and begin to look for the application of the acquired experience in other areas.
Working on several projects in the banking sector, it turned out that we had to write several systems consisting of many similar elements that differ only in the composition of the parameters. The systems being developed were built on the then still new technology of a two-level client-server: workstation - server - database. Each element of the system at the client workstation in general implemented a screen with a data entry form, several tables and several buttons or menu items to perform certain actions and, possibly, switch to another screen. In the client-server protocol, it was necessary to program the transmission of the corresponding data and the reception of the server response. The server provided for the procedure for obtaining query parameters, their analysis, performing the required queries to the database, transmitting the results in the form of a response to a client’s request.
Thus, the work was carried out as if in two dimensions. One of them is the development of new such fragments, which we called procedures. New procedures appeared during the development, as well as during the refinement of the problem. Old procedures were modified.
Here, the word “procedure” is not used in the sense, for example, of Pascal, i.e. something like a subroutine, function, etc. Rather, it is a kind of program code template.
The second dimension is the technology itself for implementing the procedures. The protocol was changed, various security subsystems were connected, which led to the need to change the program code of all previously implemented procedures at once, both in client and server programs.
In addition, with a large number of procedures, it became a problem to maintain the integrity of the project in terms of compliance of client and server programs with the protocol of their interaction. For example, if a new parameter was added in a request, the corresponding edits must be performed consistently in two different programs - in the client and in the server.
In connection with the foregoing, an idea arose to automate this process. By that time, we had experience implementing syntactic analysis programs for complex languages (the Fakir conceptual programming system with a hierarchical description of algebraic models, analytical formula calculations, and other irrelevant tasks now).
As a result, a project description language was developed consisting of a heading with various project parameters and a set of procedure descriptions. Each procedure had a unique name, a list of input parameters, a list of requests to the server with a specification of input and output parameters and the type of response — a table or one set, as well as a list of the provided actions that can be performed in the context of this procedure.
The named data types used in the procedures were specified as part of the project in its description. The description was naturally controlled for the correspondence of different components in composition to types.
Such a description was fed to the input of the project generator, which built the project model in memory, its analysis for integrity. Further, on the basis of the model, the texts of programs that implement client and server program modules were generated.
Client programs in the simplest case were generated in a finished form, but in special cases it was possible to order manual software inserts to perform special actions not provided for in the described simple project model.
The project programs themselves were implemented in C language. The server in those days was on the VAX VMS platform, client programs on the IBM PC running MS DOS (but were also provided on the VAX VMS). Server queries were written on a preprocessor over C, which understood SQL queries embedded in the text of a C program.
The project description also included a description of the database tables in terms of the types described. This allowed in the project description to formulate simplified queries to the database on a subset of the SQL language with their full parsing for compliance with a given database schema. More complex queries were implemented in server programs using preprocessor tools.
The described technology has taken root and has stood the test of time for a decade. With its help, a fair number of projects in various fields were done.
The project model was improved, complicated. Software and hardware platforms were changing. Clients and servers began to function in MS Windows and Linux.
The development in the above two dimensions made it possible to separate the work of analysts from the work of system programmers. The analyst focused on applied tasks, and the system programmer on operating systems, protocols, languages, etc.
The main advantage of this technology is a significant reduction in the code written by the system developer. The description of one procedure can take several tens of lines, and the generated C program code is usually an order of magnitude larger. Changing system software does not affect the code of the application developer, such changes are taken into account in new versions of the generator.
Using the project generator made it possible to implement complex large-scale projects with a minimum number of developers, often one person, and this was done by people who were not knowledgeable in the intricacies of programming, but who had mathematical training and experience in developing systems. Those. not a programmer, but an analyst could independently lay down a complex project and bring it to a working state without involving system programmers.
To ensure the convenience of development, various auxiliary functions for designing the project were constantly improved in the generator. In addition to the text of the programs, numerous batch files were generated to perform translation and assembly of all program components for different platforms. Generated database creation and modification utilities. The procedure for generating installation packages for transfer to the customer was automated.
A slight terminological confusion should be noted. The project description language described above was often designated as a non-procedural language, in the sense that it did not have program operators, as in C, Pascal, etc. And the procedures mentioned in the project language are completely different concepts.
Transition from a non-procedural project model to a universal programming language
As appetite increased during eating in the early 2000s, there was an understanding that it was necessary to improve the technology used to develop projects further.
Firstly, the framework of the project model itself, as a set of types, a database and a set of query procedures, has become tight.
Secondly, the use of the C language in server programs, and sometimes in client programs, has become tiring. Too low a level for the analyst is to delve into the details and subtleties of passing parameters, pointers, zero-bytes, etc.
On the other hand, projects have appeared in which it was necessary to write not simple queries to the database for the needs of banking accounting, but voluminous programs with complex data structures . In such projects, the effect of automatic generation of program text was reduced, since a lot of manual code had to be written.
With the transition to the window interface, an opportunity arose, and, as a consequence, the need to display in client programs not only tables with texts and numbers, but also all sorts of other content in the form of pictures, drawings.
In this regard, it was necessary to complicate the client-server interaction protocol. All this became an incentive to develop a completely new project generator.
The new development was based on the concept of a structural document. A document in the context of a project generator occupies one of the central concepts. At the conversational level, a document is a database of the network structure in the program memory.
The network structure of the document (database) assumes that tables are stored in it, between the lines of which one-to-many relationships are established. This is an old, forgotten concept of network structure databases that we used in long-standing designs.
The main idea was that the client program receives information from the server not in the form of several tuples and tables, but in the form of an arbitrary document fixed for this request structure. And, symmetrically, the client, fulfilling the request, also sends a document in general form.
Thus, the server must be able to read the input document from the protocol, restoring its structure in memory. Further, based on the received document, execute a certain program, now called business logic, in which interaction with a database (real, not in memory) is assumed. As a result, the program must generate an output document for transmission to the client program according to the protocol.
The client program should provide a program for generating the contents of the application window based on the received data.
The initial project assumed, like previous versions of the generator, the use of the C language for writing the bodies of server requests, as well as programs for creating the contents of the application window. As an experimental tool, a relatively simple programming language was developed, designed in simple cases to replace the C language. This language was part of the description language of the project as a whole and received the conventional name of the base language of the generator.
The basic concepts of a base language are listed below.
The description of the named data type is a string of a given fixed length, numbers of different digits, an enumerated type, a mask type (bitmask with named components), structure, and, finally, the document mentioned above.
A procedure (an analogue of a function in C) with parameters of the indicated types, including documents.
The main standard operators are assignment, conditional operator, for loop, while loop, procedure call, expressions. Everything is very similar to ordinary standard languages. For a document type, procedures for manipulating its components automatically become available.
The result was devastating - after some time in the current projects the share of C programs rapidly decreased to insignificant sizes. Somehow it turned out that the project developers began to write exclusively in this language, not only the project model, but all the programs both on the client and on the server.
The apotheosis of this unexpected process was the writing of the generator itself in its base language.
Project generator architectures at different stages of its development
Initially, the structure of the generator assumed at the input a description of the project, a set of texts of manual programs in C, and a database preprocessor for C. The output is a set of resulting C programs and scripts for translating, assembling, distributing, and other useful actions.
The generator structure at this stage of development had the form in the figure below.
With the advent of the basic language, the structure of the generator became the following. Two components were distinguished in the generator: the C-code generator from the project model and the C-code generator from texts in the base language.
The project model contains high-level entities such as server, application, server port, security subsystem, application window type, dialog, and many other useful things. All these model entities in the process of generating the project generate the C programs that implement them.
The developer also writes his pieces of C-programs, which, according to certain rules, are included in the resulting set of C-programs of the project.
Now part of the manual C programs has become possible to replace with equivalent programs in the base language, which are more easily integrated with the project model.
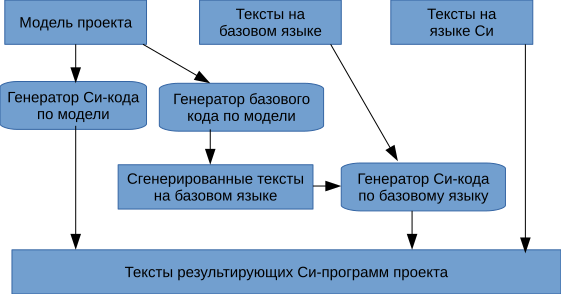
Thus, with the advent of the basic language, the structure of the generator acquired the form depicted in the following figure.
In the process of developing the base language, the volume of input texts on it grew, and in C - decreased. And as the model description language develops, the amount of code in the base language also decreases, being replaced by short and succinct descriptions of model entities.
Due to the complexity of the model component of the project description, the idea arose to generate not the C-code from the model, but the code in the base language. This simplified the generator itself, since there was no need to monitor the intricacies of addressing in C for the implementation of model entities. The translator of the base language in C monitors all this.
As a result, the structure of the generator was as follows.
Basic concepts of the generator base language
The base language is a part of the project description generator language that implements a universal programming language. The developer using the project generator has the ability to write regular programs in this language, but as part of a project.
Unlike C, there is no way to write and broadcast a separate program in the base language. Even if your program consists of several dozens of operators, you should still describe a project in which your program will be the only component, as a utility-type package - a console application.
In a more complex case, a program in the base language may consist of several packages.
A package is one of the basic concepts of a generator (and base) language. A package has a unique name within the project, is declared as a package of some type and, as a rule, is presented as a separate file with the package program text.
A project description is a project description file with a title and an ordered list of packages.
The generator contains a large set of so-called system packages of various types, which are written by the developers of the generator and can be used explicitly or implicitly through model entities in your projects. Developer packages do not have to match the names of system packages.
Here is an example of a simple project like “Hello world”. We will not consider the project directory structure here. In our case, we must create two files - a description of the project and a description of the utility as part of the project, having come up with names for them.
Let the project name be hello, the name of the utility in the project is world. Then we need to create two text files hello.gen and world.utility.
Hello.gen file:
Hidden text
project hello
/version="01.001"
utility world
World.utility file:
Hidden text
utility world:"world"
main
{ dprint("Hello world!");
}
As a result of the generation and assembly of such a project, the executable module world.exe (for MS Window) or world (for Unix) will be obtained. At startup, the program prints the string “Hello world!” In the console.
Consider a more complex example, in which, in addition to the utility package, a simple package of type package is used.
Pkgexample.gen file:
Hidden text
project pkgexample
/version="01.001"
package mypkg
utility myutl
Mypkg.package file:
Hidden text
package mypkg
type t_myint : int;
fprocdecl sum(t_myint a,t_myint b,out t_myint c);
implementation
fproc localsum(t_myint x,t_myint y,out t_myint z)
{ z := x+y;
}
fprocdecl sum(t_myint a,t_myint b,out t_myint c)
{ call localsum(a,b,c);
}
Myutl.utility file:
Hidden text
utility myutl:"myutl"
main
{ var
mypkg.t_myint p := 3,
mypkg.t_myint q := 5,
mypkg.t_myint r;
call mypkg.sum(p,q,r);
dprint("p=",p," q=",q," r=",r,"\n");
}
In this case, as part of the project, we have two packages - the mypkg software package and the myutl utility.
In the mypkg package, in the section of external specifications (up to the implementation keyword), a description of the t_myint type is derived from the base int type (a 32-bit integer), and a specification of the sum procedure with two input parameters a, b of type t_myint and one output parameter with the same type.
Everything that is written after the implementaion keyword is available only inside the package.
The localsum procedure has a similar heading, like the external sum procedure, but begins with the keyword fproc, which means that it is a local object. After the heading, instead of a semicolon, there is a block of statements in curly brackets, very similar to that in C. Inside the block, there is one assignment operator. Unlike vulgar equality, the assignment here is given by the characters “: =”.
The generator’s developers, as people with a basic mathematical education, were pained to look at such constructions in C-like languages as a = a + 1. It was decided to use algal-pascal notation in such operators.
After the local localsum procedure, the body of the sum external procedure declared in the specifications section is located. The description of the previously specified procedure is similar to the description of the local procedure, but with the keyword fprocdecl and an exact copy of the parameters. Next is the body block of the procedure in which the local procedure call localsum is located.
Myutl still has a single main section with a statement block in curly braces. The main section in the utility must be in exactly one instance at the end of the package. This is an analogue of the main function in the C language. The statements of this block are executed when the utility starts.
There are three operators in the block. The first operator is a description of the three variables p, q, r, and the first two are initialized with constant expressions. Variable types are specified in the form of a package name followed by a dot followed by the type name defined in this package.
The second operator is a call to the sum procedure from the mypkg package, which, like the types, is specified with a point expression.
The third operator is debug printing to the console.
Such elaborate programming of calculating the sum of two integer constants was done solely to demonstrate as many possibilities of the base language as possible with the minimum size of the text presented to the public.
A more complex example demonstrates working with a document type.
File docexample.gen:
Hidden text
project docexample
/version="01.001"
package doc
utility doctest
Doc.package file:
Hidden text
package doc
type t_orgname : char8[100];
type t_addr : char8[100];
type t_phone : char8[30];
type t_empname : char8[100];
type orgs : dqueue
(
record org
( t_orgname orgname,
t_addr addr,
t_phone phone
);
record emp
( t_empname empname1,
t_empname empname2,
t_empname empname3,
t_addr addr,
t_phone phone
);
set orgs_org member org;/oper=(mem,next)
set org_emp owner org member emp;/oper=(mem,next)
);
procdecl fill(orgs porgs);
implementation
procdecl fill(orgs porgs)
{ var
int iorg;
rand.init();
for ( iorg := 0; iorg < 6; iorg += 1 )
{ var
org xorg,
int iemp;
org_cre(porgs,xorg);
rand_test.firm8(xorg.orgname);
rand_test.addr8(false,xorg.addr);
rand_test.phone(xorg.phone);
orgs_org_ins(porgs,xorg,-1);
for ( iemp := 0; iemp < 8; iemp += 1 )
{ var
emp xemp;
emp_cre(xorg.xdoc,xemp);
rand_test.name8(xemp.empname1,xemp.empname2,xemp.empname3);
rand_test.addr8(true,xemp.addr);
rand_test.phone(xemp.phone);
org_emp_ins(xorg,xemp,-1);
}
}
}
Doctest.utility file:
Hidden text
utility doctest:"doctest"
proc test(doc.orgs porgs)
{ call doc.fill(porgs);
{ var
doc.org xorg;
doc.orgs_org_mem(porgs,0,xorg);
while ( isnotnull(xorg) )
{ dprint("\n");
dprint(U"Наименование: ",xorg.orgname,"\n");
dprint(U"Адрес: ",xorg.addr,"\n");
dprint(U"Телефон: ",xorg.phone,"\n");
var
doc.emp xemp;
doc.org_emp_mem(xorg,0,xemp);
while ( isnotnull(xemp) )
{ dprint("\n");
dprint(U" Фамилия: ",xemp.empname1,"\n");
dprint(U" Имя: ",xemp.empname2,"\n");
dprint(U" Отчество: ",xemp.empname3,"\n");
dprint(U" Адрес: ",xemp.addr,"\n");
dprint(U" Телефон: ",xemp.phone,"\n");
doc.org_emp_next(xemp);
}
doc.orgs_org_next(xorg);
}
}
}
main
{ varobj
doc.orgs porgs;
call test(porgs);
}
The docexample project contains two packages - doc.package and doctest.utility.
The doc package describes the character types t_orgname, t_addr, t_phone, t_empname in UTF-8 encoding with the specified lengths.
Type orgs - document (dqueue keyword). It describes two types of records org and emp - organization and employee. In parentheses are listed components of records of the indicated types. In essence, this is similar to the description of a database with two tables and the specified columns in them.
The network structure is defined by relationships between one-to-many records. Such relationships are introduced as sets. So, the org_emp set introduces a relationship between the organization and the employee, many employees can work in the organization, but each employee works in no more than one organization. The owner keyword sets the record owner type for the set. The member keyword sets a member type for a set.
A collection without an owner (in our case orgs_org) is called singular; it exists in a single copy in a document (its owner is conditionally the entire document / database).
The document-type declaration automatically declares the record-types of such a document with the names matching the names of the records. In doing so, keep in mind the uniqueness of type names within a package.
In addition, for each record and for each set, procedures for manipulating these objects are automatically generated and made available.
So, for an org record, an org_cre procedure is created with two parameters: a link to the document, an output variable of the record type to obtain a link to the created record instance.
An org_emp_ins procedure is created for the org_emp set with three parameters: a reference to an instance of type org — the owner records of the set, a reference to an instance of type emp — records of the set member, an integer — the position in the set (negative numbers — numbering from the end of the set).
An org_emp_mem procedure is also created for the org_emp set with three parameters: a reference to an instance of type org — the owner records of the set, an integer — a position in the set, and an output parameter — a link to an instance of type emp — records of a member.
For the org_emp set, an org_emp_next procedure is created with one parameter of type emp (input and output) to move to the next element in the set.
The multifunctional expressions isnull (...) and isnotnull (...) apply to variables such as document records.
This project uses the rand and rand_test system packages to generate random test data.
To demonstrate the power of parsing, consider another example project.
Calc.gen file:
Hidden text
project calc
/version="01.001"
utility calc
Calc.utility file:
Hidden text
utility calc:"Calculator"
type t_double : double;
/frac=6
procspec syn_add(string7 buf,tlex.t_lex xlex,out t_double dval);
proc syn_fact(string7 buf,tlex.t_lex xlex,out t_double dval)
{ dval := 0.0;
if ( tlex.sample(buf,xlex,"(") )
{ call syn_add(buf,xlex,dval);
tlex.sample_err(buf,xlex,")");
}
else if ( tlex.double(buf,xlex,NOSIGN,NOFRAC,NOEXPON,dval) )
;
else
tlex.message(buf,xlex,"syntax error");
}
proc syn_mul(string7 buf,tlex.t_lex xlex,out t_double dval)
{ call syn_fact(buf,xlex,dval);
for ( ; ; )
{ var
t_double dval1;
if ( tlex.sample(buf,xlex,"*") )
{ call syn_fact(buf,xlex,dval1);
dval *= dval1;
}
else if ( tlex.sample(buf,xlex,"/") )
{ call syn_fact(buf,xlex,dval1);
dval /= dval1;
}
else
break;
}
}
proc syn_add(string7 buf,tlex.t_lex xlex,out t_double dval)
{ var
bool minus;
if ( tlex.sample(buf,xlex,"+") )
;
else if ( tlex.sample(buf,xlex,"-") )
minus := true;
call syn_mul(buf,xlex,dval);
if ( minus )
dval := -dval;
for ( ; ; )
{ var
t_double dval1;
if ( tlex.sample(buf,xlex,"+") )
{ call syn_mul(buf,xlex,dval1);
dval += dval1;
}
else if ( tlex.sample(buf,xlex,"-") )
{ call syn_mul(buf,xlex,dval1);
dval -= dval1;
}
else
break;
}
}
proc syn(string7 buf,tlex.t_lex xlex,out t_double dval)
{ call syn_add(buf,xlex,dval);
tlex.eof_err(buf,xlex);
}
main
{ if ( utl.argc(xutl.yutl) <> 2 )
error U"Не задан параметр";
var
tlex.t_lex xlex,
t_double dval;
call syn(utl.argv7(xutl.yutl,1),xlex,dval);
dprint("result=",dval,"\n");
}
The development of a calculator utility is shown, at the input of which an expression is supplied, at the output, the calculated value of the expression.
Using the tlex parsing system package allows solving the task of parsing an expression in a very simple and minimal amount of code, using the wide built-in capabilities of this package. This example shows how easy and compact it is to solve parsing issues.
The project involves the tlex system package - lexical parsing in a string. Parsing is done using the recursive descent method. Each nonterminal symbol of a grammar corresponds to a procedure in a parsing program.
The grammar should be reduced to such a way that, according to the results of finding out which terminal symbol is located in the reading position, one can decide which grammar rule to use for parsing. Bringing it to this form is not difficult for most existing languages. To do this, it is enough to define a sublanguage that allows texts that are incorrect from the point of view of the initial grammar. In the future, based on the constructed parsing tree (in one form or another), one can check the correctness.
In fact, this is always done in real translators, since real programs are not described by context-free grammars. KS grammar can hardly describe a language in which the use of various objects (types, procedures, variables) without their description is prohibited. So this kind of check is done anyway.
In our case, the analysis is performed in the calc utility for the input parameter string of the program call in the console. If exactly one parameter is not specified, an error message is displayed. If the parameter is set, then it is parsed with the calculation of the result. Upon successful analysis, the result of the calculation is printed in the console. If an error occurs, a diagnostic message is issued with information in which position of the text the error was detected.
Grammar in words. An additive expression is a sequence of multiplicative expressions separated by operation signs + or -. A multiplicative expression is a sequence of factors separated by operation signs * or /. A multiplier is an additive expression in parentheses or a number.
The additive expression corresponds to the syn_add procedure, the multiplicative expression corresponds to syn_mul, and the multiplier corresponds to syn_fact.
Parameters of syntax procedures: buf - text to be analyzed, xlex - lexical analysis context (including reading position), dval - output parameter - calculated value.
Used lexical procedures of the tlex package.
Function tlex.sample - checks in the current position the presence of the sample presented in the parameter. If the pattern begins with a letter, then the recognized text must match the pattern as a whole, and not contain the pattern as a substring. Those. if we check for the availability of the proc sample, the procdecl text in the read position will not give an affirmative result. When recognizing any token, all space characters, line ends, tabs, etc. are skipped. Comments in the style of C and C ++ are also skipped.
Tlex.sample_err procedure - checks the tlex.sample procedure for the presence of a sample, in the absence initiates a fatal error with a message text containing information about the reading position of the analyzed string.
Such pairs of functions / procedures are present in the tlex package for many types of tokens. The function allows you to check for the presence of a token, the procedure checks and in the absence initiates an error.
Procedure tlex.double - checks at the current position for the presence of a decimal number in the form of 123.456. The NOSIGN parameter prohibits the + - sign at the vocabulary level; we recognize these characters at the grammar level. The NOFRAC parameter enables numbers with or without a decimal point.
Subtotals
The previous section provides sample projects that demonstrate some of the core language features. Note that this is not a reference, not a guide to the language, and not even a set of examples for training. This is just an introduction text.
If the reader gets to this place, he has a very logical question - what is in this basic language that which is not in other languages, and why did you need to spend energy and money for its implementation?
Firstly, the base language is part of a complete generator language describing projects. There are many different constructions in the generator language for describing model entities such as a database, sql query, server, server port, application, application screen layout, dialog, configuration file, json conversion for arbitrary data types, an abstract set of related tables for mappings in different environments (dom-model, gtk, qt), etc. This list is constantly updated, obsolete entities die off, new ones appear. And all these constructions are implemented mainly in the base language. In the early stages of generator development, model designs were implemented directly in C. Using the base language facilitated the integration of models and language.
Secondly, the generator is intended (and only then gives significant advantages) for the implementation of large projects, when the amount of program code is measured in hundreds of thousands of lines. Work with large projects is fundamentally different from the development of small programs up to several thousand lines in size. In a small program, a developer can keep in his head all the information about its structure. In a large program, this is not possible. In the process of modifying such programs, excess unused code will inevitably increase. To counter this process, the generator takes numerous measures and code checks.
In the headings of the procedures, formal parameters are specified as input, input and output, only output. During the translation of the body of the procedure, this specification is checked for correctness. For example, if a certain parameter is declared output, and in the body of the procedure there is a path in the operator tree in which the variable is used to read before it is assigned a value, then this situation leads to an error diagnosis. In this case, information on the inputs and outputs of other procedures called in this procedure is used. If the variable has the type of structure, then such an analysis is carried out for each of its components at any level.
For structural documents, you can order a complete set of all operations provided for all its records and sets. This will result in significant redundant code. It is possible (and necessary) to explicitly set the list of all required operations for each record and set. In this case, operations that were not used in the project will be identified and appropriate diagnostics will be issued. Moreover, if, for example, the operation of creating a record is not used, then this is also treated as an error. Or for a set there is an operation of inclusion in a set and no longer used, then an error is also generated.
At the time of writing this text, there was just a process of deleting some obsolete entities in the project model (old servers and applications are replaced by new ones). In the document representing the project model in the generator code at the time of the simultaneous existence of old and new objects, there were about 250 types of records and more than 800 types of sets. After deleting old entities, the number of records decreased to 190, sets to 580. It is clear that manually tracking the use of so many objects and operations with them is extremely difficult.
As an illustration, we present data on one real, but already completed, project in the field of financial activity. The project on the generator contained 1294 files in total 203829 lines. In the resulting C code, there were 4605 files with 2608812 lines. The project has 23 different types of servers, 29 ports through which they receive requests, 11 applications, 27 utilities (console programs), and this is only in one, but the largest project in the entire system. This system included 7 projects, interconnected by means of export-import of individual packages. The division of the system into 7 different generator projects was done to reduce their volume. Managing such an economy without paranoid means of integrity verification is very problematic.
Current situation
The project generator throughout the entire time of working on it developed as an internal project in the development team. In the process of working on applied projects, our customers in some cases had the opportunity to use the generator for their own developments, one way or another connected with our project (and maybe not only, it is difficult to control). While working on projects, the statement of the problem was clarified, new needs for the tool arose, which were implemented in the next versions of the generator. As it was said at the beginning, it was development in two dimensions, applied and instrumental. Those. the generator developed along with the next (next) project. Periodically, there was talk about making the generator itself a software product for the general public.
Currently, the generator has tools for working with database management systems Oracle, Postgres, MySql, MS Sql, Sqlite of different versions. Working with databases involves describing the database schema using generator tools, writing sql queries in a special language (a fairly representative subset of sql is used) with full syntactic and semantic control of the query text in the database schema. There are tools for specifying alternatives for different types of databases. And you can write the so-called dynamic queries, which without control will be transferred to the database.
The servers are transferred to modern network tools - Epoll on Unix and I / O Completion on MS Windows.
Until recently, applications were developed using a single interface model (the so-called window layouts), which had two implementations - Microsoft WIN32 GUI and GTK-3 for Unix. Maintaining one model for these two systems has become increasingly difficult due to the underdeveloped tools in the WIN32 GUI. Therefore, two different approaches are currently being developed - GTK-3 and Qt-5. The models are different, but very similar. So far, no decision has been made to separate them, or try to combine them with individual exceptions in different implementations.
Actively developing the export of Java Script packages for use in WEB development. In the browser, you can receive data in the json format from the server and use the functions for manipulating the types described in the project, for example, with a structural document, generated for Java Script.
For WEB development, a fairly representative subset of the HTML language with inserts in the base language is implemented (similar to PHP). At the same time, HTML markup is monitored for the correctness of nesting tags. And, of course, the inserts in the base language are subject to total control, as is customary throughout the generator.
Implemented exporting packages to the Java language mainly for the development of component systems on mobile platforms (Android).