Malicious machine learning as a diagnostic method
- Transfer

Hello to all!
Continuing to study the topic of deep learning , we once wanted to talk to you about why neural networks see sheep everywhere . This topic is discussed in the 9th chapter of the book by Francois Chollet.
Thus, we went to the wonderful research of the company “Positive Technologies”, presented at Habré , as well as to the excellent work of two MIT employees, who consider that “harmful machine learning” is not only a hindrance and problem, but also a wonderful diagnostic tool.
Next - under the cut.
Over the past few years, cases of malicious intervention have attracted considerable attention in the deep learning community. In this article, we would like to review this phenomenon in general terms and discuss how it fits into the broader context of machine learning reliability.
Malicious interventions: an intriguing phenomenon.
To delineate the space of our discussion, we give several examples of such malicious intervention. We think that the majority of researchers working in the MoD came across similar images:
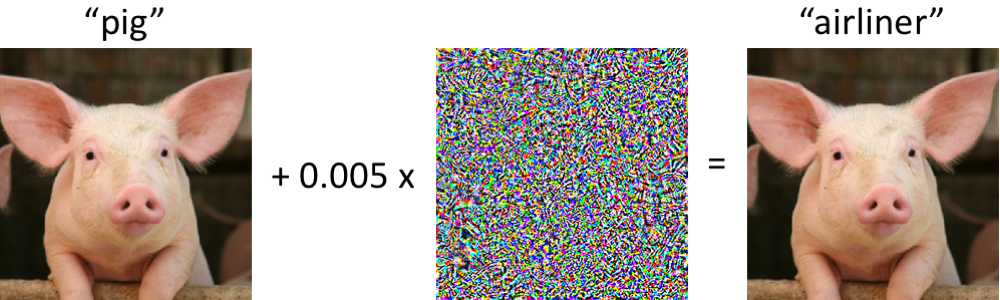
On the left is a piglet, correctly classified by the modern convolutional neural network as a piglet. As soon as we make minimal changes to the image (all pixels are in the range [0, 1], and each changes by no more than 0.005), the network now returns the airliner class with high confidence. Such attacks on trained classifiers have been known since at least 2004 ( link ), and the first works related to malicious interference with image classifiers date back to 2006 ( link ). Then this phenomenon began to attract much more attention from about 2013, when it turned out that neural networks were vulnerable to attacks of this kind (see here and here). Since then, many researchers have offered options for constructing malicious examples, as well as ways to increase the stability of classifiers against such pathological disturbances.
However, it is important to remember that it is not necessary to delve into neural networks in order to observe such malicious examples.
How resistant are malicious examples?
Perhaps the situation in which the computer confuses the pig with the airliner may at first be disturbing. However, it should be noted that the classifier used in this case ( the Inception-v3 network ) is not as fragile as it may seem at first glance. Although the network is surely mistaken when trying to classify a distorted piglet, this happens only in the case of specially selected violations.
The network is much more resistant to random perturbations of comparable magnitude. Therefore, the main question is precisely whether malicious disturbances cause the fragility of networks. If the damage per se is critically dependent on the control of each input pixel, then when classifying images in realistic conditions such malicious samples do not seem to be a serious problem.
Recent studies suggest otherwise: it is possible to ensure the stability of haze to various channel effects in specific physical scenarios. For example, malicious samples can be printed on a regular office printer, so the images on them, photographed by the camera of the smartphone, are still classified incorrectly.. You can also make stickers, because of which neural networks incorrectly classify various real scenes (see, for example, link1 , link2 and link3 ). Finally, recently, researchers have printed a bug on a 3D printer, which the standard Inception network, at virtually any viewing angle, mistakenly considers a rifle .
Preparation of attacks, provoking an erroneous classification
How to create such malicious disturbances? There are many approaches, but optimization makes it possible to reduce all these different methods to a generalized representation. As is known, classifier training is often formulated as finding model parameters
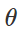 that allow minimizing the empirical loss function for a given set of examples.
that allow minimizing the empirical loss function for a given set of examples. :
: 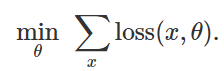
Therefore, in order to provoke an erroneous classification for a fixed model
and “harmless” input 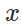 , it is natural to try to find a limited disturbance
, it is natural to try to find a limited disturbance  , such that the losses
, such that the losses  are maximized:
are maximized: 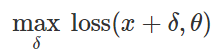
If we proceed from this formulation, many methods for creating malicious input can be considered as different optimization algorithms (separate gradient steps , projected gradient descent, etc.) for different sets of constraints (small-
 normal disturbance, small pixel changes, etc.). A number of examples are given in the following articles: link1 , link2 , link3 , link4 and link5 .
normal disturbance, small pixel changes, etc.). A number of examples are given in the following articles: link1 , link2 , link3 , link4 and link5 .As explained above, many successful methods for generating malicious samples work with a fixed target classifier. Therefore, the important question is: do these disturbances affect only the specific target model? What is interesting is not. When using many perturbation methods, the resulting malicious samples are transferred from the classifier to the classifier, trained with a different set of initial random values (random seeds) or different model architectures. Moreover, it is possible to create malicious samples that have only limited access to the target model (sometimes in this case they speak about “attacks on the black box principle”). See, for example, the following five articles: link1 , link2 , link3 , link4 andlink5 .
Not only pictures.
Malicious patterns are found not only in the classification of images. Similar phenomena are known in speech recognition , in question-answer systems , in training with reinforcement and solving other problems. As you already know, the study of malicious samples lasts for more than ten years: The
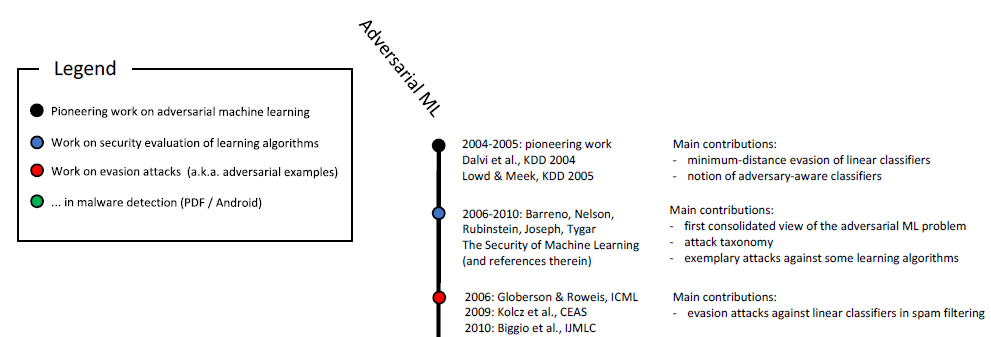
chronological scale of malicious machine learning (start). Full scale is shown in Fig. 6 in this study .
In addition, security-related applications are the natural environment for studying the harmful aspects of machine learning. If an attacker can trick the classifier and pass malicious input (say, spam or virus) harmless, then the spam detector or antivirus scanner that works on the basis of machine learning will be ineffective . It should be emphasized that these considerations are not purely academic. For example, the Google Safebrowsing team back in 2011 published a long-term study of how attackers tried to bypass their malware detection systems. Also see this article on malicious samples in the context of spam filtering in GMail mail.
Not only security
All the latest work on the study of malicious samples is clearly defined in the key of security. This is a valid point of view, but we believe that such samples should be considered in a wider context.
Reliability
First of all, malicious samples raise the question of the reliability of the entire system. Before we can reasonably argue about the properties of a classifier from a security point of view, we need to make sure that the mechanism provides good classification accuracy well. After all, if we are going to deploy our trained models in real-world scenarios, then they need to demonstrate a high degree of reliability when changing the distribution of basic data - regardless of whether these changes are due to malicious interference or only natural fluctuations.
In this context, malicious samples are a useful diagnostic tool for assessing the reliability of machine learning systems. In particular, the approach taking into account malicious samples allows one to go beyond the standard evaluation protocol, where a trained classifier is run through a carefully selected (and usually static) test suite.
So you can come to amazing conclusions. For example, it turns out that you can easily create malicious samples without even resorting to sophisticated optimization methods. In a recent paper, we show that cutting-edge image classifiers are surprisingly vulnerable to small pathological transitions or turns. (See here and here for other work on this topic.)

Therefore, even if one does not attach importance to, say, perturbations from the discharge ℓ∞ℓ∞, reliability problems are often still caused by rotations and transitions. In a broader sense, it is necessary to understand the reliability indicators of our classifiers before they can be integrated into larger systems as truly reliable components.
The concept of classifiers
To understand how a trained classifier works, it is necessary to find examples of its clearly successful or unsuccessful operations. In this case, malicious samples illustrate that trained neural networks often do not match our intuitive understanding of what it means to “learn” a particular concept. This is especially important in deep learning, where people often declare biologically plausible algorithms and networks whose success is not inferior to human (see, for example, here , here or here ). Malicious patterns clearly make one doubt in this immediately in a variety of contexts:
- When classifying images, if the set of pixels is minimally changed or the picture is rotated a little, this will hardly prevent a person from placing it in the correct category. Nevertheless, such changes completely cut down the most modern classifiers. If you place objects in an unusual place (for example, sheep in a tree ) it is also easy to make sure that the neural network interprets the scene in a completely different way than the person.
- If you substitute the right words into a text passage, you can seriously confuse the question-answer system , although, from the person’s point of view, the meaning of the text will not change due to such inserts.
- This article on carefully selected text examples shows the limits of Google Translate.
In all three cases, malicious examples help to test the strength of our modern models and underline the situations in which these models act completely differently from what a person would do.
Security
Finally, malicious samples really represent a danger in those areas where machine learning already reaches a certain accuracy on "harmless" material. Just a few years ago, such tasks as image classification were still very poorly performed, so the security problem in this case seemed secondary. In the end, the degree of security of a machine-learning system becomes essential only when this system begins to process “harmless” input sufficiently qualitatively. Otherwise, we still can not trust her predictions.
Now, the accuracy of such classifiers has increased significantly in various subject areas, and deploying them in situations where safety considerations are critical is just a matter of time. If we want to approach this responsibly, then it is important to investigate their properties precisely in the security context. But the security issue needs a holistic approach. It is much easier to fake certain attributes (for example, a set of pixels) than, for example, other sensory modalities, or categorical attributes, or metadata. In the end, while providing security, it is best to rely on precisely such signs that are difficult or even almost impossible to change.
Results (too early to sum up?)
Despite the impressive progress in machine learning that we have seen in recent years, it is necessary to take into account the limits of the capabilities of the tools that we have at our disposal. There are a wide variety of problems (for example, related to honesty, privacy, or feedback effects), and reliability is of utmost concern. Human perception and cognition are resistant to various background environmental disturbances. However, malicious samples demonstrate that neural networks are still very far from comparable sustainability.
So, we are convinced of the importance of studying malicious examples. Their applicability in machine learning is far from being limited to safety issues, but can serve as a diagnostic standard.to evaluate trained models. The approach with the use of malicious samples compares favorably with standard evaluation procedures and static tests in that it reveals potentially non-obvious defects. If we want to understand the reliability of modern machine learning, it is important to investigate the latest achievements from the point of view of the attacker (having correctly picked up malicious samples).
As long as our classifiers fail, even with minimal changes between the training and test distribution, we cannot achieve satisfactory guaranteed reliability. In the end, we strive to create such models that will not only be reliable, but also be consistent with our intuitive ideas about what a “study” task is. Then they will be safe, reliable and convenient to deploy in a variety of environments.